Python OpenCV 裁剪身份证正反面

银行业务经常采集的身份证复印件如上图所示,有时候进行某项深度学习业务时,比如文字识别之类,可能需要把身份证的正反面裁剪下来作为训练样本,裁剪demo代码如下所示:
1、灰度转换 锐化:
对图像进行灰度转换,转换成灰度图像;
对图像进行了两次锐化操作,增强图像的高频分量,增强图像细节边缘和轮廓,增强灰度反差,便于后期对目标的识别和处理。
def gray_and_fliter(img, image_name='1.jpg', save_path='./'): # 转为灰度图并滤波,后面两个参数调试用
"""
将图片灰度化,并锐化滤波
:param img: 输入RGB图片
:param image_name: 输入图片名称,测试时使用
:param save_path: 滤波结果保存路径,测试时使用
:return: 灰度化、滤波后图片
"""
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图片
img_blurred = cv2.filter2D(img_gray, -1,kernel=np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32)) #对图像进行滤波,是锐化操作
img_blurred = cv2.filter2D(img_blurred, -1, kernel=np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32))
return img_blurred
图像锐化与图像平滑是相反的操作,锐化是通过增强高频分量来减少图像中的模糊,增强图像细节边缘和轮廓,增强灰度反差,便于后期对目标的识别和处理。锐化处理在增强图像边缘的同时也增加了图像的噪声。方法通常有微分法和高通滤波法。
微分法:
1)梯度法
2)罗伯特梯度算子法
3)拉普拉斯算子法
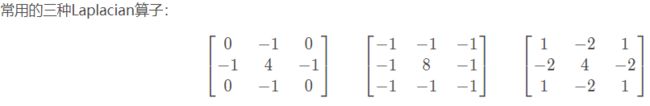
高通滤波法:

2、图像边缘提取 形态学关开操作 形态学腐蚀膨胀操作
经过一系列操作后,得到二值化图像
def gradient_and_binary(img_blurred, image_name='1.jpg', save_path='./'): # 将灰度图二值化,后面两个参数调试用
"""
求取梯度,二值化
:param img_blurred: 滤波后的图片
:param image_name: 图片名,测试用
:param save_path: 保存路径,测试用
:return: 二值化后的图片
"""
gradX = cv2.Sobel(img_blurred, ddepth=cv2.CV_32F, dx=1, dy=0) # sobel算子,计算梯度, 也可以用canny算子替代
gradY = cv2.Sobel(img_blurred, ddepth=cv2.CV_32F, dx=0, dy=1)
img_gradient = cv2.subtract(gradX, gradY) #使用减法作图像融合?
#img_gradient = cv2.addWeighted(gradX,2, gradY,2,0)
img_gradient = cv2.convertScaleAbs(img_gradient) #用convertScaleAbs()函数将其转回原来的uint8形式
# 这里改进成自适应阈值,貌似没用
img_binary = cv2.adaptiveThreshold(img_gradient, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 3, -3)
cv2.imshow("img_binary", img_binary)
# 这里调整了kernel大小(减小),腐蚀膨胀次数后(增大),出错的概率大幅减小
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
img_closed = cv2.morphologyEx(img_binary, cv2.MORPH_CLOSE, kernel) #形态学关操作
mg_closed = cv2.morphologyEx(img_closed, cv2.MORPH_OPEN, kernel) #形态学开操作
img_closed = cv2.erode(mg_closed, None, iterations=9) #腐蚀
img_closed = cv2.dilate(img_closed, None, iterations=9) # 膨胀
return img_closed3、在二值化图像找到身份证的 正面区域 和 反面区域(涉及到仿射变换矩阵)
1)找出轮廓
2)刷选出2个最大的轮廓,找到轮廓对应的最小外接矩形,使用boxPoints获得矩形的4个角点坐标
3)确定4个角点坐标的位置关系,左上,左下,右上,右下(src)
4) 把4个角点坐标的位置关系移动到零坐标开始位置(dst)
5) 确定 src 到 dst的投影变换矩阵
cv2.getPerspectiveTransform(src, dst)
def find_bbox(img, img_closed): # 寻找身份证正反面区域
"""
根据二值化结果判定并裁剪出身份证正反面区域
:param img: 原始RGB图片
:param img_closed: 二值化后的图片
:return: 身份证正反面区域
"""
(contours, _) = cv2.findContours(img_closed.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # 求出框的个数
# 这里opencv如果版本不对(4.0或以上)会报错,只需把(contours, _)改成 (_, contours, _)
contours = sorted(contours, key=cv2.contourArea, reverse=True) # 按照面积大小排序
countours_res = []
for i in range(0, len(contours)):
area = cv2.contourArea(contours[i]) # 计算面积
if (area <= 0.4 * img.shape[0] * img.shape[1]) and (area >= 0.05 * img.shape[0] * img.shape[1]):
# 人为设定,身份证正反面框的大小不会超过整张图片大小的0.4,不会小于0.05(这个参数随便设置的)
rect = cv2.minAreaRect(contours[i]) # 最小外接矩,返回值有中心点坐标,矩形宽高,倾斜角度三个参数
box = cv2.boxPoints(rect) #将rect使用boxPoints进行提取矩形的4个角点
left_down, right_down, left_up, right_up = point_judge([int(rect[0][0]), int(rect[0][1])], box)
src = np.float32([left_down, right_down, left_up, right_up]) # 这里注意必须对应
dst = np.float32([[0, 0], [int(max(rect[1][0], rect[1][1])), 0], [0, int(min(rect[1][0], rect[1][1]))],
[int(max(rect[1][0], rect[1][1])),
int(min(rect[1][0], rect[1][1]))]]) # rect中的宽高不清楚是个怎么机制,但是对于身份证,肯定是宽大于高,因此加个判定
m = cv2.getPerspectiveTransform(src, dst) # 得到投影变换矩阵
result = cv2.warpPerspective(img, m, (int(max(rect[1][0], rect[1][1])), int(min(rect[1][0], rect[1][1]))),
flags=cv2.INTER_CUBIC) # 投影变换
countours_res.append(result)
return countours_res # 返回身份证区域4、对身份证的正反区域进行分割
1)如果出现分割异常,如下图所示,则需要把中间粘连的部分分割

def find_cut_line(img_closed_original): # 对于正反面粘连情况的处理,求取最小点作为中线
"""
根据规则,强行将粘连的区域切分
:param img_closed_original: 二值化图片
:return: 处理后的二值化图片
"""
img_closed = img_closed_original.copy()
img_closed = img_closed // 250
#print(img_closed.shape)
width_sum = img_closed.sum(axis=1) # 沿宽度方向求和,统计宽度方向白点个数
start_region_flag = 0
start_region_index = 0 # 身份证起始点高度值
end_region_index = 0 # 身份证结束点高度值
for i in range(img_closed_original.shape[0]): # 1000是原始图片高度值,当然, 这里也可以用 img_closed_original.shape[0]替代
if start_region_flag == 0 and width_sum[i] > 330:
start_region_flag = 1
start_region_index = i # 判定第一个白点个数大于330的是身份证区域的起始点
if width_sum[i] > 330:
end_region_index = i # 只要白点个数大于330,便认为是身份证区域,更新结束点
# 身份证区域中白点最少的高度值,认为这是正反面的交点
# argsort函数中,只取width_sum中判定区域开始和结束的部分,因此结果要加上开始点的高度值
min_line_position = start_region_index + np.argsort(width_sum[start_region_index:end_region_index])[0]
img_closed_original[min_line_position][:] = 0
for i in range(1, 11): # 参数可变,分割10个点
temp_line_position = start_region_index + np.argsort(width_sum[start_region_index:end_region_index])[i]
if abs(temp_line_position - min_line_position) < 30: # 限定范围,在最小点距离【-30, 30】的区域内
img_closed_original[temp_line_position][:] = 0 # 强制变为0
return img_closed_original
完整代码如下了:
# -*- coding: utf-8 -*-
# @Time :
# @Author :
# @Reference : None
# @File : cut_twist_join.py
# @IDE : PyCharm Community Edition
"""
将身份证正反面从原始图片中切分出来。
需要的参数有:
1.图片所在路径。
输出结果为:
切分后的身份证正反面图片。
"""
import os
import cv2
import numpy as np
def point_judge(center, bbox):
"""
用于将矩形框的边界按顺序排列
:param center: 矩形中心的坐标[x, y]
:param bbox: 矩形顶点坐标[[x1, y1], [x2, y2], [x3, y3], [x4, y4]]
:return: 矩形顶点坐标,依次是 左下, 右下, 左上, 右上
"""
left = []
right = []
for i in range(4):
if bbox[i][0] > center[0]: # 只要是x坐标比中心点坐标大,一定是右边
right.append(bbox[i])
else:
left.append(bbox[i])
if right[0][1] > right[1][1]: # 如果y点坐标大,则是右上
right_down = right[1]
right_up = right[0]
else:
right_down = right[0]
right_up = right[1]
if left[0][1] > left[1][1]: # 如果y点坐标大,则是左上
left_down = left[1]
left_up = left[0]
else:
left_down = left[0]
left_up = left[1]
return left_down, right_down, left_up, right_up
def gray_and_fliter(img, image_name='1.jpg', save_path='./'): # 转为灰度图并滤波,后面两个参数调试用
"""
将图片灰度化,并滤波
:param img: 输入RGB图片
:param image_name: 输入图片名称,测试时使用
:param save_path: 滤波结果保存路径,测试时使用
:return: 灰度化、滤波后图片
"""
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图片
img_blurred = cv2.filter2D(img_gray, -1,kernel=np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32)) #对图像进行滤波,是锐化操作
img_blurred = cv2.filter2D(img_blurred, -1, kernel=np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32))
return img_blurred
def gradient_and_binary(img_blurred, image_name='1.jpg', save_path='./'): # 将灰度图二值化,后面两个参数调试用
"""
求取梯度,二值化
:param img_blurred: 滤波后的图片
:param image_name: 图片名,测试用
:param save_path: 保存路径,测试用
:return: 二值化后的图片
"""
gradX = cv2.Sobel(img_blurred, ddepth=cv2.CV_32F, dx=1, dy=0) # sobel算子,计算梯度, 也可以用canny算子替代
gradY = cv2.Sobel(img_blurred, ddepth=cv2.CV_32F, dx=0, dy=1)
img_gradient = cv2.subtract(gradX, gradY) #使用减法作图像融合?
#img_gradient = cv2.addWeighted(gradX,2, gradY,2,0)
img_gradient = cv2.convertScaleAbs(img_gradient) #用convertScaleAbs()函数将其转回原来的uint8形式
# 这里改进成自适应阈值,貌似没用
img_binary = cv2.adaptiveThreshold(img_gradient, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 3, -3)
cv2.imshow("img_binary", img_binary)
# 这里调整了kernel大小(减小),腐蚀膨胀次数后(增大),出错的概率大幅减小
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
img_closed = cv2.morphologyEx(img_binary, cv2.MORPH_CLOSE, kernel) #形态学关操作
mg_closed = cv2.morphologyEx(img_closed, cv2.MORPH_OPEN, kernel) #形态学开操作
img_closed = cv2.erode(mg_closed, None, iterations=9) #腐蚀
img_closed = cv2.dilate(img_closed, None, iterations=9) # 膨胀
return img_closed
def find_bbox(img, img_closed): # 寻找身份证正反面区域
"""
根据二值化结果判定并裁剪出身份证正反面区域
:param img: 原始RGB图片
:param img_closed: 二值化后的图片
:return: 身份证正反面区域
"""
(contours, _) = cv2.findContours(img_closed.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # 求出框的个数
# 这里opencv如果版本不对(4.0或以上)会报错,只需把(contours, _)改成 (_, contours, _)
contours = sorted(contours, key=cv2.contourArea, reverse=True) # 按照面积大小排序
countours_res = []
for i in range(0, len(contours)):
area = cv2.contourArea(contours[i]) # 计算面积
if (area <= 0.4 * img.shape[0] * img.shape[1]) and (area >= 0.05 * img.shape[0] * img.shape[1]):
# 人为设定,身份证正反面框的大小不会超过整张图片大小的0.4,不会小于0.05(这个参数随便设置的)
rect = cv2.minAreaRect(contours[i]) # 最小外接矩,返回值有中心点坐标,矩形宽高,倾斜角度三个参数
box = cv2.boxPoints(rect) #将rect使用boxPoints进行提取矩形的4个角点
left_down, right_down, left_up, right_up = point_judge([int(rect[0][0]), int(rect[0][1])], box)
src = np.float32([left_down, right_down, left_up, right_up]) # 这里注意必须对应
dst = np.float32([[0, 0], [int(max(rect[1][0], rect[1][1])), 0], [0, int(min(rect[1][0], rect[1][1]))],
[int(max(rect[1][0], rect[1][1])),
int(min(rect[1][0], rect[1][1]))]]) # rect中的宽高不清楚是个怎么机制,但是对于身份证,肯定是宽大于高,因此加个判定
m = cv2.getPerspectiveTransform(src, dst) # 得到投影变换矩阵
result = cv2.warpPerspective(img, m, (int(max(rect[1][0], rect[1][1])), int(min(rect[1][0], rect[1][1]))),
flags=cv2.INTER_CUBIC) # 投影变换
countours_res.append(result)
return countours_res # 返回身份证区域
def find_cut_line(img_closed_original): # 对于正反面粘连情况的处理,求取最小点作为中线
"""
根据规则,强行将粘连的区域切分
:param img_closed_original: 二值化图片
:return: 处理后的二值化图片
"""
img_closed = img_closed_original.copy()
img_closed = img_closed // 250
#print(img_closed.shape)
width_sum = img_closed.sum(axis=1) # 沿宽度方向求和,统计宽度方向白点个数
start_region_flag = 0
start_region_index = 0 # 身份证起始点高度值
end_region_index = 0 # 身份证结束点高度值
for i in range(img_closed_original.shape[0]): # 1000是原始图片高度值,当然, 这里也可以用 img_closed_original.shape[0]替代
if start_region_flag == 0 and width_sum[i] > 330:
start_region_flag = 1
start_region_index = i # 判定第一个白点个数大于330的是身份证区域的起始点
if width_sum[i] > 330:
end_region_index = i # 只要白点个数大于330,便认为是身份证区域,更新结束点
# 身份证区域中白点最少的高度值,认为这是正反面的交点
# argsort函数中,只取width_sum中判定区域开始和结束的部分,因此结果要加上开始点的高度值
min_line_position = start_region_index + np.argsort(width_sum[start_region_index:end_region_index])[0]
img_closed_original[min_line_position][:] = 0
for i in range(1, 11): # 参数可变,分割10个点
temp_line_position = start_region_index + np.argsort(width_sum[start_region_index:end_region_index])[i]
if abs(temp_line_position - min_line_position) < 30: # 限定范围,在最小点距离【-30, 30】的区域内
img_closed_original[temp_line_position][:] = 0 # 强制变为0
return img_closed_original
def cut_part_img(img, cut_percent):
"""
# 从宽度和高度两个方向,裁剪身份证边缘
:param img: 身份证区域
:param cut_percent: 裁剪的比例
:return: 裁剪后的身份证区域
"""
height, width, _ = img.shape
height_num = int(height * cut_percent) # 需要裁剪的高度值
h_start = 0 + height_num // 2 # 左右等比例切分
h_end = height - height_num // 2 - 1
width_num = int(width * cut_percent) # 需要裁剪的宽度值
w_start = 0 + width_num // 2
w_end = width - width_num // 2 - 1
return img[h_start:h_end, w_start:w_end] # 返回裁剪后的图片
def preprocess_cut_one_img(img_path, img_name, save_path='./save_imgs/', problem_path='./problem_save/'): # 处理一张图片
"""
裁剪出一张图片中的身份证正反面区域
:param img_path: 图片所在路径
:param img_name: 图片名称
:param save_path: 结果保存路径 测试用
:param problem_path: 出错图片中间结果保存 测试用
:return: 身份证正反面图片
"""
img_path_name = os.path.join(img_path, img_name)
if not os.path.exists(img_path_name): # 判断图片是否存在
print('img {name} is not exits'.format(name=img_path_name))
return 1, [] # 图片不存在,直接返回,报错加一
img = cv2.imread(img_path_name) # 读取图片
img_blurred = gray_and_fliter(img, img_name) # 灰度化并滤波
img_t = cv2.filter2D(img, -1, kernel=np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32))
cv2.imshow("img_t",img_t)
# 对图像进行锐化
img_binary = gradient_and_binary(img_blurred) # 梯度加上二值化
cv2.imshow("img_binary", img_binary)
res_bbox = find_bbox(img_t, img_binary) # 切分正反面
if len(res_bbox) != 2: # 异常处理
print('Error happened when cut img {name}, try exception cut program '.format(name=img_path_name))
# cv2.imwrite(os.path.join(problem_path, img_name.split('.')[0] + '_blurred.jpg'), img_blurred)
# cv2.imwrite(os.path.join(problem_path, img_name.split('.')[0] + '_binary.jpg'), img_binary)
# cv2.imwrite(os.path.join(problem_path, img_name), img) # 调试用,保存中间处理结果
img_binary = find_cut_line(img_binary) # 强制分割正反面
cv2.imshow("img_binary1", img_binary)
res_bbox = find_bbox(img_t, img_binary)
if len(res_bbox) != 2: # 纠正失败
print('Failed to cut img {name}, exception program end'.format(name=img_path_name))
return 1, None
else: # 纠正成功
print('Correctly cut img {name}, exception program end'.format(name=img_path_name))
return 0, res_bbox
else: # 裁剪过程正常
# cv2.imwrite(os.path.join(save_path, img_name.split('.')[0] + '_0.jpg'), cut_part_img(res_bbox[0], 0.0))
# cv2.imwrite(os.path.join(save_path, img_name.split('.')[0] + '_1.jpg'), cut_part_img(res_bbox[1], 0.0))
# cv2.imwrite(os.path.join(save_path, img_name.split('.')[0] + '_original.jpg'), img)
return 0, res_bbox
def process_img(img_path, save_path, problem_path):
"""
切分一个目录下的所有图片
:param img_path: 图片所在路径
:param save_path: 结果保存路径
:param problem_path: 问题图片保存路径
:return: None
"""
if not os.path.exists(img_path): # 判断图片路径是否存在
print('img path {name} is not exits, program break.'.format(name=img_path))
return
if not os.path.exists(save_path): # 保存路径不存在,则创建路径
os.makedirs(save_path)
if not os.path.exists(problem_path): # 保存路径不存在,则创建路径
os.makedirs(problem_path)
img_names = os.listdir(img_path)
error_count = 0
error_names = []
for img_name in img_names:
error_temp, res_bbox = preprocess_cut_one_img(img_path, img_name, save_path, problem_path)
error_count += error_temp
if error_temp == 0:
cv2.imwrite(os.path.join(save_path, img_name.split('.')[0] + '_0.jpg'), cut_part_img(res_bbox[0], 0.0))
cv2.imwrite(os.path.join(save_path, img_name.split('.')[0] + '_1.jpg'), cut_part_img(res_bbox[1], 0.0))
else:
error_names.append(img_name)
print('total error number is: ', error_count)
print('error images mame :')
for error_img_name in error_names:
print(error_img_name)
return
if __name__ == '__main__':
origin_img_path = './origin_imgs/'
cutted_save_path = './result_imgs/'
cut_problem_path = './problem_imgs/'
process_img(img_path=origin_img_path, save_path=cutted_save_path, problem_path=cut_problem_path)
cv2.waitKey(0)