目标检测系列5——yolov4原理与实现
YOLO的前3个版本都是Redmon的作品,YOLOv4的作者变了
YOLOv4是一个综合多种技巧的大杂烩,YOLOv4的论文包含太多知识了,可以说是面试宝典,一定要把YOLOv4的论文搞懂了,哪怕花一个月,慢慢来。整篇论文就是一个综述,跟综述不同的是,里面有作者的实验,并实现了模型。
V4 中,作者做了很多实验,把近几年的一些方法加入yolo中,最终取得了 效果和速度的提升。通过了解yolov4,我们可以很好的知道近几年有哪些方法被提出来.
做科研就是要这样,广泛阅读了解最新技术,进行总结,一步一步进行实验,提出自己的新想法,尝试尝试再尝试,得到优秀模型或方法结果。
前提
在了解YOLOv4之前,强烈要求先了解YOLOv1和YOLOv2,YOLOv3
YOLOv1:
https://blog.csdn.net/xiaotiig/article/details/111772945
YOLOv2:
https://blog.csdn.net/xiaotiig/article/details/111834918
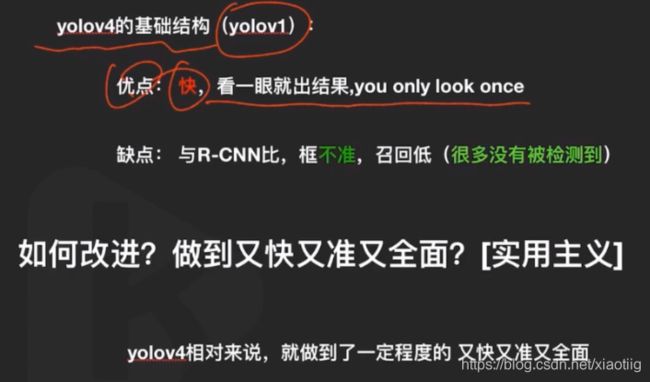

有一个基准,在这个基准上做回归。

上面的改进措施是YOLOv2相对于v1的改进策略,不是YOLOv4
YOLOv3:
https://blog.csdn.net/xiaotiig/article/details/111885102
v3的一些回顾:
- backbone:darknet53
- anchor boxes
- batch normalization
- multi-scale (test544)
- 取消了pooling层,改用卷积核步长进行降采样
- logistics代替softmax
YOLOv4
- 前提
- 1 YOLOv4效果
- 2 改进策略
-
- 2.1 总体思路
- 2.2 Bag of freebies
-
- 2.2.1 马赛克数据增强(Mosaic)
- 2.2.2 DropBlock regularization
- 2.2.3 Class label smoothing
- 2.2.4 CIoU
- 2.2.5DIoU-NMS
- 2.2.6 CmBN
- 2.2.7 Self—Adversarial Training(自对抗训练)
- 2.2.8 Eliminate grid sensitivity(网格消除敏感)
- 2.2.9 Cosine annealing scheduler(模拟余弦退火)
- 2.3 Bag of specials
-
- 2.3.1 Mish activation
- 2.3.2 CSP
- 2.3.3 SPP
- 2.3.4 SAM
- 2.3.5 PAN
- 2.4 Selection of architecture(主干网络选择)
- 2.5 Additional improvements
- 3 YOLOv4 架构
- 4 代码实现
- 参考资料
1 YOLOv4效果

2 改进策略
2.1 总体思路
先在整体上设计的网络的几个部分,来回替换,然后局部再用各种优化技巧。宏观和微观相结合来进行改进,就是一般的实验思路,用到的技术很新,很有代表性。
网络分为4个部分,每个部分有哪些优化策略,来回试
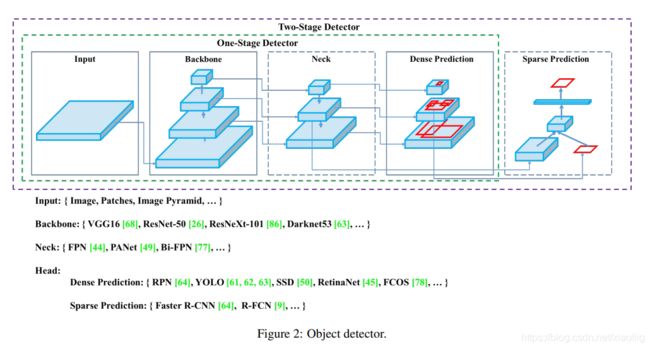


上面是一些优化技巧
Dense Prediction:是直接根据像素点产生框
- Weighted-Residual-Connections
- Cross-Stage-Partial-connections
- Cross mini-Batch Normalization
- Self-adversarial-training
- Mish activation
- Mosaic data augmentation
- DropBlock regularization
- CIoU loss
等
2.2 Bag of freebies
改变培训策略,或者只会增加培训成本的方法,对测试不影响。
不会增加额外的推理时间等而可以改进模型

数据扩充:
1、光度畸变:调整图像的亮度、对比度、色调、饱和度和噪声
2、几何畸变:加入随机缩放、剪切、翻转和反旋转
模拟对象遮挡:
1、random erase,CutOut:可以随机选择图像中的矩形区域,并填充一 个随机的或互补的零值
2、hide-and-seek、grid mask:随机或均匀地选择图像中的多个矩形区 域,并将其全部替换为0
feature map:
DropOut、DropConnect和DropBlock。
结合多幅图像进行数据扩充:
MixUp、CutMix
Style Transfer GAN
解决类别不平衡:
hard negative example mining (只适用两阶段)
online hard example mining (只适用两阶段)
focal loss
label smoothing
bbox:
1、IoU_loss
2、GIoU_loss
3、DIoU_loss
4、CIoU_loss
YOLOv4 - use:
CutMix and Mosaic data augmentation、DropBlock regularization、 Class label smoothing、CIoU-loss、CmBN、Self-Adversarial Training、 Eliminate grid sensitivity、Using multiple anchors for a single ground truth、Cosine annealing scheduler、Optimal hyperparameters、Random training shapes。
2.2.1 马赛克数据增强(Mosaic)


将4张图片放在一张图像上,按像素比例赋予类别值
2.2.2 DropBlock regularization

不是简单的随机Dropout,而是让它一小块区域整体Dropout
2.2.3 Class label smoothing

2.2.4 CIoU
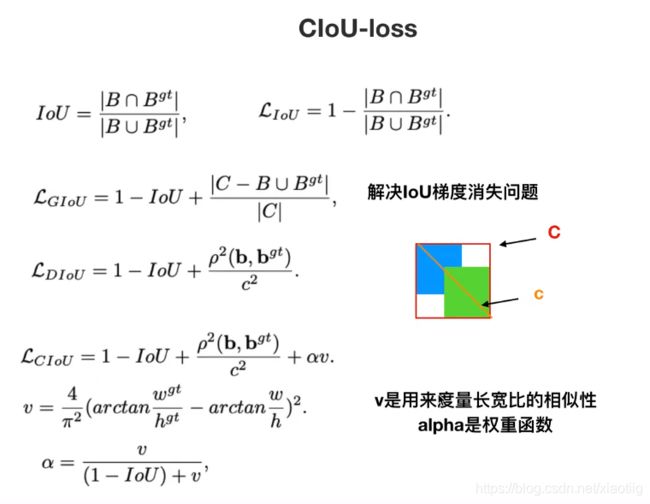
2.2.5DIoU-NMS

2.2.6 CmBN

CmBN是单独的一篇论文,就是解决小批次情况下训练的问题,当硬件不够的时候,比如gpu当批次量大于10就爆了的情况下,只能用小批次来训练。
2.2.7 Self—Adversarial Training(自对抗训练)

2.2.8 Eliminate grid sensitivity(网格消除敏感)
在v3中也讲到过,就是因为sigmoid函数取不到边界,导致回归框达不到检测的边界,×一个大于1.0的因子
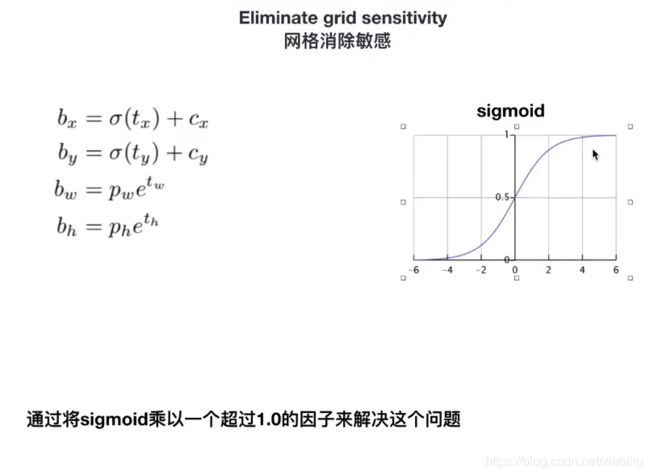
2.2.9 Cosine annealing scheduler(模拟余弦退火)
改善学习率的一种方法
2.3 Bag of specials
![]()
enhance receptive field:SPP,ASPP,RFB
attention module:
1、Squeeze-and-Excitation (SE):可以改善resnet50在分类任务上提高 1%精度,但是会增加GPU推理时间10%。
2、Spatial Attention Module (SAM):可以改善resnet50在分类任务上提 高0.5%精度,并且不增加GPU推理时间。
feature integration:
早期使用skip connection、hyper-column。随着FPN等多尺度方法的流 行,提出了许多融合不同特征金字塔的轻量级模型。SFAM、ASFF、BiFPN。 SFAM的主要思想是利用SE模块对多尺度拼接的特征图进行信道级配重权。 ASFF使用softmax作为点向水平重加权,然后添加不同尺度的特征映射。 BiFPN提出了多输入加权剩余连接来执行按比例加权的水平重加权,然后加入不 同比例的特征映射。
activation function:
ReLU解决了tanh和sigmoid的梯度消失问题。 LReLU , PReLU , ReLU6 ,SELU, Swish , hard-Swish , Mish 其中 Swish和Mish都是连续可微的函数。
post-processing method
nms:c·p
soft-nms:解决对象的遮挡问题
DIoU nms:将中心点分布信息添加到BBox筛选过程中
YOLOv4 - use:
Mish activation、CSP、MiWRC、SPP-block、SAM、PAN、DIoU-NMS
2.3.1 Mish activation

2.3.2 CSP

2.3.3 SPP

2.3.4 SAM

2.3.5 PAN

2.4 Selection of architecture(主干网络选择)
在ILSVRC2012 (ImageNet)数据集上的分类任务,CSPResNext50要比CSPDarknet53好得多。然而,在COCO数据集上的检测任务,CSP+Darknet53比CSPResNext50更好。
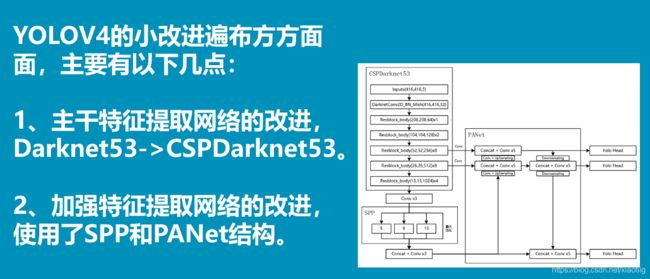
backbone:CSP+Darknet53
additional module:SPP
neck:PANet
head:YOLOv3 (anchor based)
2.5 Additional improvements
为了使检测器更适合于单GPU上的训练,做了如下补充设计和改进:
1、引入了一种新的数据增强方法Mosaic和自对抗训练(SAT)
2、在应用遗传算法的同时选择最优超参数
3、修改了一些现有的方法,如:SAM,PAN,CmBN
3 YOLOv4 架构
Backbone: CSPDarknet53
Neck: SPP [25], PAN
Head: YOLOv3
另外加了各种技巧
当输入是416x416时,特征结构如下:

当输入是608x608时,特征结构如下:
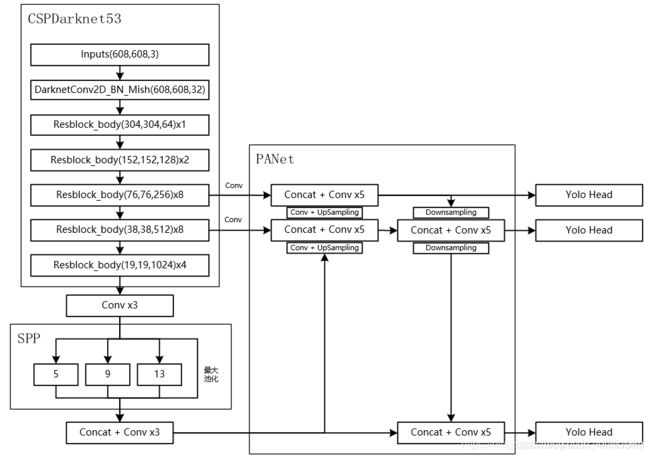
这里可以对比一下YOLOv3和YOLOv4结构的区别,加了spp增强特征提取网络。
4 代码实现
参考资料
参考资料:
本文大部分来自下面的资料:
视频:
https://www.bilibili.com/video/BV1aK4y1k73n?from=search&seid=6802850024063399555
https://www.bilibili.com/video/BV1LZ4y1W7Ve?from=search&seid=2530366646981018850
文章:
这两篇文章没有细讲,但是脉络比较清晰
https://zhuanlan.zhihu.com/p/136172670
https://blog.csdn.net/baobei0112/article/details/105831613/
再加一篇:
https://blog.csdn.net/weixin_44791964/article/details/106533581
上面写的有点乱和浅:
具体还是需要多看论文,几篇涉及到的论文:
链接: https://pan.baidu.com/s/1kAPXvusLpYB1gFVLH9E_LQ 提取码: wvaj
代码:
https://www.bilibili.com/video/BV1LZ4y1W7Ve?from=search&seid=2530366646981018850