YOLOX训练自己的数据集(VOC)
代码 :GitHub
论文 :arxiv
参考: 训练coco格式数据
文章解析
https://www.zhihu.com/question/473350307
https://zhuanlan.zhihu.com/p/392221567
我还没看懂 simOTA T-T
- 安装 yolox
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -U pip && pip3 install -r requirements.txt
pip3 install -v -e .
- 安装apex
git clone https://github.com/NVIDIA/apex
cd apex
# RTX3090 ,CUDA11.1安装的时候需要将 apex/setup.py中的
def check_cuda_torch_binary_vs_bare_metal(cuda_dir):
return # 也就是这里直接进行返回,不进行下面的操作,否则无法安装成。
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
- 安装pycocotools.
pip3 install cython;
pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
- 准备数据集 格式为voc
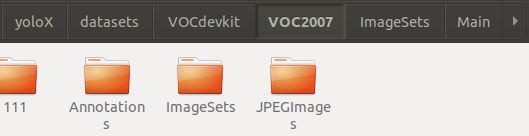
a. Annotations放xml文件
b. JPEGImages放图片文件
c. 生成 ImageSets文件夹
import os
import random
random.seed(0)
xmlfilepath=r'./VOCdevkit/VOC2007/Annotations'
saveBasePath=r"./VOCdevkit/VOC2007/ImageSets/Main/"
#----------------------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# train_percent不需要修改
#----------------------------------------------------------------------#
trainval_percent=0.8
train_percent=1
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
- 直接以exps/example/yolox_voc/yolox_voc_s.py 这个文件为模板,在这里改动就好了。改动地方
# 1.改变类别数量
self.num_classes = 5
self.depth = 0.33
self.width = 0.50 # 这两个控制网络层数和卷积数量
self.input_size = (640, 640) # 默认输入是640*640,想要更改其他信息,可以对照yolox_base将里面的信息在这重写即可
# 2. 改变训练数据集的位置
dataset = VOCDetection(
data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"), # 这里
image_sets=[('2007', 'trainval')], #这里
# 3. 改变测试集的位置
def get_eval_loader(self, batch_size, is_distributed, testdev=False):
from yolox.data import VOCDetection, ValTransform
valdataset = VOCDetection(
data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"), # 这里
image_sets=[('2007', 'test')],
img_size=self.test_size,
preproc=ValTransform(
rgb_means=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
),
)
# 4 更改类别名
yolox/data/datasets/voc_classes.py 下改为自己的类别
开始训练
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 0 -b 16 -o
-d : 指定GPU号
-b : batch 数量
6. 结果保存在YOLOX_outputs中

可能是图片比较少的缘故吧,mAP没有看到明显的提升。之前用v4训练和这个差不多。
测试
# demo.py
#开头需要 引入voc类别
from yolox.data.datasets import VOC_CLASSES
# yolox/data/datasets/__init__.py 里需要也加入 voc类别
from .voc_classes import VOC_CLASSES
predictor = Predictor(model, exp, VOC_CLASSES, trt_file, decoder, args.device)
# Predictor 默认类别是COCO_CLASSES
测试命令:
python tools/demo.py image -n yolox-s -c checkpoints/yolox_s.pth --path assets/***.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu
注意:本次由于直接在yolox_voc_s.py这个文件上进行了更改,所以 -n yolox-s 这里yolox-s的配置要和yolox_voc_s.py这个里面的配置保持一致,或者可以自己定义一个网络Exp
其中各参数含义为:
-n 后为模型名称:yolox-s,对应yolox_s.py。
-c后为权重文件路径:YOLOX/yolos_m.pth。
–path后为images or video的路径
–save_result:来保存图片/视频的推断结果
–conf CONF: test conf
–nms NMS: test nms threshold
–tsize TSIZE: test img size
在本次训练中,由于yolox_voc_s.py这个文件里的配置是yolox-tiny网络,所以测试命令如下:
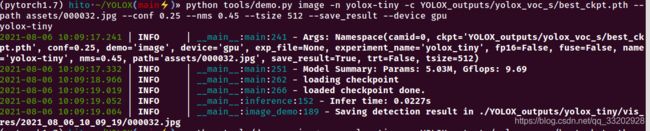
python tools/demo.py image -n yolox-tiny -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth --path assets/000032.jpg --conf 0.25 --nms 0.45 --tsize 512 --save_result --device gpu
测试输出如下: