python -- (列表、元组、字典、集合) --(二)
列表
列表是一个线性的集合,它允许用户在任何位置插入、删除、访问和替换元素。
列表实现是基于数组或基于链表结构的。当使用列表迭代器的时候,双链表结构比单链表结构更快。
有序的列表是元素总是按照升序或者降序排列的元素。
Python中list是用下边的C语言的结构来表示的。ob_item是用来保存元素的指针数组,allocated是ob_item预先分配的内存总容量。
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
Append 追加
arguments: list object, new element
returns: 0 if OK, -1 if not
app1:
n = size of list
call list_resize() to resize the list to size n+1 = 0 + 1 = 1
list[n] = list[0] = new element
return 0
arguments: list object, new size
returns: 0 if OK, -1 if not
list_resize:
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6) = 3
new_allocated += newsize = 3 + 1 = 4
resize ob_item (list of pointers) to size new_allocated
return 0
内部调用app1()函数,list_resize()会申请多余的空间以避免调用多次list_resize()函数,list增长的模型是:0, 4, 8, 16, 25, 35, 46, 58, 72, 88, …
注:list并不直接保存元素,保存元素的指针,这也是同一个list中可以同时存放多种类型元素的根本原因。
Insert 插入
arguments: list object, where, new element
returns: 0 if OK, -1 if not
ins1:
resize list to size n+1 = 5 -> 4 more slots will be allocated
starting at the last element up to the offset where, right shift each element
set new element at offset where
return 0
Pop
调用listpop(),list_resize在函数listpop()内部被调用,如果这时ob_size(译者注:弹出元素后)小于allocated(译者注:已经申请的内存空间)的一半。这时申请的内存空间将会缩小。
arguments: list object
returns: element popped
listpop:
if list empty:
return null
resize list with size 5 - 1 = 4. 4 is not less than 8/2 so no shrinkage
set list object size to 4
return last element
Remove
arguments: list object, element to remove
returns none if OK, null if not
listremove:
loop through each list element:
if correct element:
slice list between element's slot and element's slot + 1
return none
return null
切开list和删除元素,调用了list_ass_slice()(译者注:在上文slice list between element’s slot and element’s slot + 1被调用),来看下list_ass_slice()是如何工作的。在这里,低位为1 高位为2(译者注:传入的参数)
arguments: list object, low offset, high offset
returns: 0 if OK
list_ass_slice:
copy integer 5 to recycle list to dereference it
shift elements from slot 2 to slot 1
resize list to 5 slots
return 0
操作时间复杂度

参考链接
Python中list实现
Python中list实现(英文原文)
元组
python 的内建对象除了 list 这个可变的数据结构,还有 tuple 这个不可变的数据结构,不可变的意思是这个 tuple 的长度在创建的时候就是恒定的,不能增加/删除元素,但是 tuple 里面存储的对象却可以是可变的
memory layout 如下所示
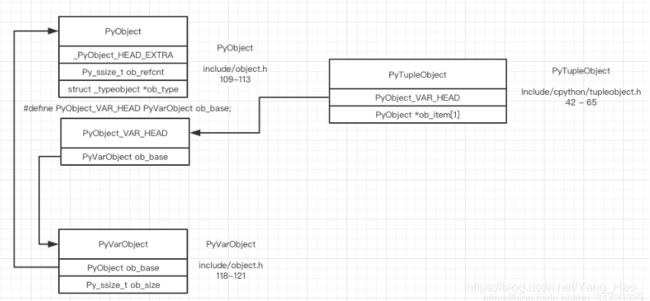
我们可以看到,PyTupleObject 只存储了两个对象,分别是:
PyObject_VAR_HEAD: cpython中容器对象的头部
ob_item: 一个长度为 1 的存储内容为 PyObject * 的数组
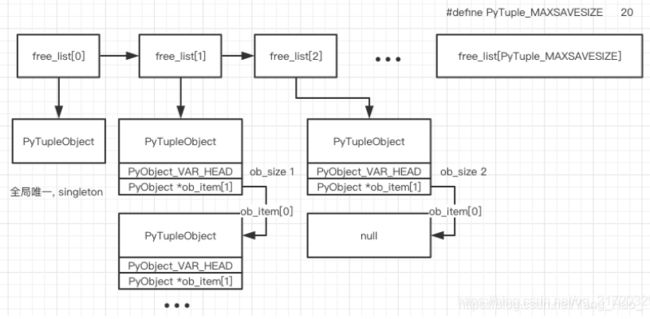
free_list
和 dict 还有 list 一样,为了提高效率,避免频繁的调用系统函数 free 和 malloc 向操作系统申请和释放空间,在文件:
Objects/tupleobject.c 中第 28 行定义了一个 free_list:
static PyTupleObject *free_list[PyTuple_MAXSAVESIZE];
所有申请过的,小于一定大小的 tuple,在释放的时候会被放进这个 free_list 中以供下次使用,如下图所示
-
free_list[0] 用于存储长度为 0 的 tuple 对象,整个解释器的生命周期里面只有一个长度为 0 的 tuple 对象实例
-
free_list[1] 用于存储长度为 1 的 tuple 对象,可以通过 tuple 对象的 ob_item[0] 指针遍历到下一个长度为 1 的 tuple 对象
-
free_list[2] 用于存储长度为 2 的 tuple 对象,上图画的 free_list[2] 中只有一个对象
-
free_list 每一格最多能存储 PyTuple_MAXFREELIST 个 tuple 链表长度,这里定义的是 2000
参考
Python 元组底层源码分析
字典
字典是通过散列表或说哈希表实现的。
字典也被称为关联数组,还称为哈希数组等。也就是说,字典也是一个数组,但数组的索引是键经过哈希函数处理后得到的散列值,哈希函数的目的是使键均匀地分布在数组中,并且可以在内存中以O(1)的时间复杂度进行寻址,从而实现快速查找和修改。哈希表中哈希函数的设计困难在于将数据均匀分布在哈希表中,从而尽量减少哈希碰撞和冲突。由于不同的键可能具有相同的哈希值,即可能出现冲突,高级的哈希函数能够使冲突数目最小化。
通常情况下建立哈希表的具体过程如下:
- 数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
- 数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。
哈希函数就是一个映射,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的哈希函数值都落在表长允许的范围之内即可。本质上看哈希函数不可能做成一个一对一的映射关系,其本质是一个多对一的映射,这也就引出了一个概念–哈希冲突或者说哈希碰撞。哈希碰撞是不可避免的,但是一个好的哈希函数的设计需要尽量避免哈希碰撞。
常见的哈希碰撞解决方法:
- 开放寻址法(open addressing)
- 再哈希法
- 链地址法
- 公共溢出区
- 装填因子α
字典是一种可变、无序容器数据结构。元素以键值对存在,键值唯一。它的特点搜索速度很快:数据量增加10000倍,搜索时间增加不到2倍;当数据量很大的时候,字典的搜索速度要比列表快成百上千倍。
通过哈希函数计算键对象name的哈希值,对数组长度取余hash(hashable)%k,因为哈希值最右3位110为十进制6,则查看数组索引6对应的bucket是否为空,如果为空则将键值对放入,否则(哈希冲突)左移三位即000,查看索引0是否为空,循环直至找到空的bucket。
Python会根据哈希数组的拥挤程度对其扩容。“扩容”指的是:创造更大的数组,这时候会对已经存在的键值对重新进行哈希取余运算保存到其它位置;一般接近 2/3 时,数组就会扩容。扩容后,偏移量的数字个数增加,如数组长度扩容到16时,可以用最右边4位数字作为偏移量。
计算键对象name的哈希值,然后比较哈希数组对应索引内的bucket是否为空,为空返回None,否则计算这个bucket的键对象的哈希值,然后与name哈希值比较,相等则返回值对象,否则继续左移计算哈希值。
注意:
1.键必须为可哈希的,如数字、元组、字符串;自定义对象需要满足支持hash、支持通过__eq__()方法检测相等性、若a == b为真,则hash(a) == hash(b)也为真。
- Python中所有不可变的内置类型都是可哈希的。
- 可变类型(如列表,字典和集合)就是不可哈希的,因此不能作为字典的键。
2.字典的内存开销很大,以空间换时间。
3.键查询速度很快,列表查询是按顺序一个个遍历,字典则是一步到位。
4.往字典里面添加新键可能导致扩容,导致哈希数组中键的次序变化。因此,不要在遍历字典的同时进行字典的修改。
参考
Python 字典底层原理
Python 字典底层实现
集合
字典和集合能如此高效,和它们内部的数据结构密不可分。不同于其他数据结构,字典和集合的内部结构都是一张哈希表:
- 对于字典而言,这张表存储了哈希值(hash)、键和值这 3 个元素。
- 而对集合来说,哈希表内只存储单一的元素。
集合去重机制
Python内部使用集合set可以对可迭代对象进行去重。在Python内部是调用了__hash__和__eq__方法。
- 调用两个对象的__hash__方法。如果返回值不同,则说明两个对象不重复。
- 如果__hash__方法的返回值相同,则调用两个对象的__eq__方法。如果返回值不同,则说明两个对象不重复。如果相同,则两个对象重复
---------------------------------------------------END-----------------------------------------------
---------------------------------------------------END-----------------------------------------------