python---PyMySQL、爬虫
准备数据库
- 安装 mariadb-server
- 启动服务
- 为 root 用户修改密码为 tedu.cn
- 创建名为 tedu1 的数据库【utf8】
[root@localhost ~]# yum -y install gcc
[root@localhost ~]# yum -y install mariadb-server
[root@localhost ~]# systemctl start mariadb
[root@localhost ~]# systemctl enable mariadb
[root@localhost ~]# ss -ntulp | grep mysql
[root@localhost ~]# mysqladmin password tedu.cn # 修改root用户登录密码
[root@localhost ~]# mysql -uroot -p'tedu.cn'
MariaDB [(none)]> CREATE DATABASE tedu1 DEFAULT CHARSET utf8; # 创建数据库tedu1, 指定字符集为utf8【数据库命令不区分大小写】数据库相关操作
数据库相关操作
1. 创建数据库
MariaDB [(none)]> CREATE DATABASE tedu1 CHARSET utf8;
2. 查看数据库
MariaDB [(none)]> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| tedu1 |
+--------------------+
3. 选择数据库
MariaDB [none]> USE tedu1;
4. 查看 tedu1 库有哪些表
MariaDB [tedu1]> SHOW TABLES;
Empty set (0.000 sec) -- 空
5. 给 tedu1 创建表
MariaDB [tedu1]> CREATE TABLE bumen(bumen_id INT,bumen_name VARCHAR(50));
6. 再次查看 tedu1 库有哪些表
MariaDB [tedu1]> SHOW TABLES;
+-----------------+
| Tables_in_tedu1 |
+-----------------+
| bumen |
+-----------------+
7. 向 tedu1 库插入数据
MariaDB [tedu1]> INSERT INTO bumen VALUES(1, "OPS");
MariaDB [tedu1]> INSERT INTO bumen VALUES(2, "DEV");
8. 查看表中数据
MariaDB [tedu1]> SELECT * FROM bumen;
+----------+------------+
| bumen_id | bumen_name |
+----------+------------+
| 1 | OPS |
| 2 | DEV |
+----------+------------+
9. 更新数据
MariaDB [tedu1]> UPDATE bumen SET bumen_name="TEST" WHERE bumen_id=1;
10. 查看表中数据
MariaDB [tedu1]> SELECT * FROM bumen;
+----------+------------+
| bumen_id | bumen_name |
+----------+------------+
| 1 | TEST |
| 2 | DEV |
+----------+------------+
11. 删除数据
MariaDB [tedu1]> DELETE FROM bumen WHERE bumen_name = "DEV";
12. 查看表中数据
MariaDB [tedu1]> SELECT * FROM bumen;
+----------+------------+
| bumen_id | bumen_name |
+----------+------------+
| 1 | TEST |
+----------+------------+
13. 删除表
MariaDB [tedu1]> DROP TABLE bumen;
MariaDB [tedu1]> SHOW TABLES;
Empty set (0.000 sec)
PyMySQL 模块应用
连接数据库
创建连接是访问数据库的第一步
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='tedu.cn',
db='tedu1',
charset='utf8'
)游标
-
游标(cursor)就是游动的标识
-
通俗的说,一条sql取出对应n条结果资源的接口/句柄,就是游标,沿着游标可以一次取出一行
cur = conn.cursor() # 创建游标【对数据库进行增删改查】创建表
# 建立部门表,员工表,工资表
# 定义创建departments【部门表】sql命令
create_dep = '''CREATE TABLE departments(
dep_id INT, dep_name VARCHAR (50),
PRIMARY KEY(dep_id)
)'''
cur.execute(create_dep) # 执行sql语句create_dep插入数据
对数据库表做修改操作,必须要 commit
#向部门表中插入数据
insert_dep = 'INSERT INTO departments VALUES (%s, %s)' # 定义插入数据的变量,%s为占位符
cur.execute(insert_dep, (1, '人事部')) # 执行sql语句insert_dep, 插入一条记录
cur.executemany( # executemany(), 执行sql语句insert_dep, 同时插入多条记录
insert_dep,
[(2, '运维部'), (3, '开发部'), (4, '测试部'), (5, '财务部'), (6, '市场部')]
)
conn.commit()查询数据
可以取出表中一条、多条或全部记录
sql4 = "SELECT * FROM departments"
cur.execute(sql4)
result = cur.fetchone()
print(result)
result2 = cur.fetchmany(2)
print(result2)
result3 = cur.fetchall()
print(result3)修改数据
通过 update 修改某一字段的值
# 更新部门表【departments】中的数据
update_dep = 'UPDATE departments SET dep_name=%s WHERE dep_name=%s'
cur.execute(update_dep, ('人力资源部', '人事部'))
conn.commit()
删除记录
通过 delete 删除记录
#删除部门表【departments】中的id为6的数据
del_dep = 'DELETE FROM departments WHERE dep_id=%s'
cur.execute(del_dep, (6,))
conn.commit()import pymysql
# 1. 建立连接
conn = pymysql.connect(
host ="127.0.0.1",port=3306,user="root",
passwd="tedu.cn",db="dc",charset="utf8"
# MariaDB [(none)]> create database dc charset utf8;
)
# 2. 创建游标 - 执行数据库操作的介质
cur = conn.cursor()
# 3.1 创建表
#create_bumen = "create table bumen(bumen_id INT ,bumen_naem VARCHAR(50))"
#cur.execute(create_bumen)
# 3.2 添加数据
# insert_bumen = "insert into bumen values (%s,%s);"
# #cur.execute(insert_bumen,(1,"OPS"))
# cur.executemany(
# insert_bumen,[(2,"DEV"),(3,"TEST"),(4,"UI"),(5,"MARKET")]
# )
# 3.3 查询数据
select_bumen = "select * from bumen;"
cur.execute(select_bumen)
dc1 = cur.fetchone() # 抓取单条数据
print("dc1:",dc1)
dc2 = cur.fetchmany(2) # 接着上次的位置向下抓取两条数据
print("dc2:",dc2)
dc3 = cur.fetchall() # 抓取剩余的所有属家
print("dc3:",dc3)
# 4. 提交事物并关闭资源
conn.commit() # 提交事物
cur.close()
conn.close()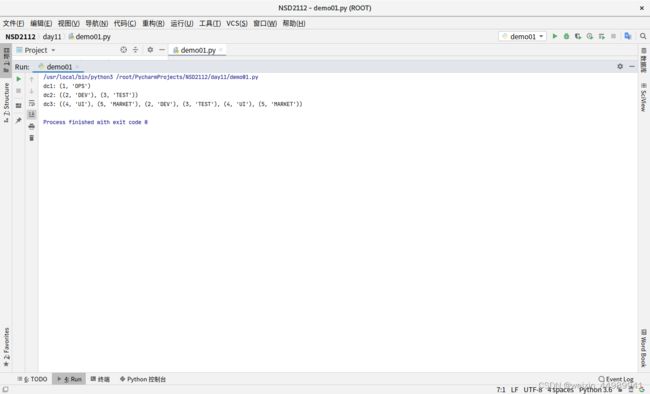
# 3.4 修改数据
update_bumen = "UPDATE bumen SET bumen_naem= %s WHERE bumen_id= %s;"
cur.execute(update_bumen,("SALES", 4))
# 3.5 删除数据
delete_bumen = "delete from bumen WHERE bumen_id=%s;"
cur.execute(delete_bumen,(5,))
练习 :员工表 (EMPLOYEE) 相关操作
需求:
- 员工表有 FIRST_NAME VARCHAR(20),LAST_NAME VARCHAR(20),AGE INT,SEX VARCHAR(1),INCOME FLOAT字段
- 使用 PyMySQL 创建该表
- 使用 PyMySQL 添加以下三条数据
- 'Mac', 'A', 20, 'M', 20000
- 'Tom', 'B', 20, 'F', 30000
- 'Bob', 'C', 20, 'M', 40000
- 使用 PyMySQL 查询所有用户信息,并打印结果
- 将 FIRST_NAME 为 Mac 的用户工资改成 10000
- 删除 FIRST_NAME 为 Tom 的用户信息
# 需求: 在 dc数据库中进行操作
#
# 员工表(EMPLOYEE)有 FIRST_NAME VARCHAR(20),LAST_NAME VARCHAR(20),AGE INT,SEX VARCHAR(1),INCOME FLOAT字段
# create table EMPLOYEE(
# FIRST_NAME VARCHAR(20),LAST_NAME VARCHAR(20),
# AGE INT,SEX VARCHAR(1),INCOME FLOAT
# )
# 使用 PyMySQL 创建该表
# 使用 PyMySQL 添加以下三条数据
# 'Mac', 'A', 20, 'M', 20000
# 'Tom', 'B', 20, 'F', 30000
# 'Bob', 'C', 20, 'M', 40000
# 使用 PyMySQL 查询所有用户信息,并打印结果
# 将 FIRST_NAME 为 Mac 的用户工资改成 10000
# 删除 FIRST_NAME 为 Tom 的用户信息
import pymysql
# 1. 创建连接
conn = pymysql.connect(
host ="127.0.0.1",port=3306,user="root",
passwd="tedu.cn",db="dc",charset="utf8"
# MariaDB [(none)]> create database dc charset utf8;
)
# 2. 创建游标
cur = conn.cursor()
# 3.1 创建表
# sql01= """create table EMPLOYEE(FIRST_NAME VARCHAR(20),LAST_NAME VARCHAR(20),
# AGE INT,SEX VARCHAR(1),INCOME FLOAT
# )"""
# cur.execute(sql01)
# 3.2 插入数据
# insert_EMPLOYEE = "insert into EMPLOYEE values (%s,%s,%s,%s,%s);"
# cur.executemany(
# insert_EMPLOYEE,[('Mac', 'A', 20, 'M', 20000),('Tom', 'B', 20, 'F', 30000),('Bob', 'C', 20, 'M', 40000)]
# )
# 3.3 查询所有
# select_EMPLOYEE = "select * from EMPLOYEE ;"
# cur.execute(select_EMPLOYEE)
# dc = cur.fetchall()
# print("dc:",dc)
# 3.4 修改
sql = 'UPDATE EMPLOYEE SET INCOME=%s WHERE FIRST_NAME=%s'
cur.execute(sql, (10000, 'Mac'))
# 3.5 删除
delete_EMPOLYEE = "delete from EMPLOYEE WHERE FIRST_NAME=%s;"
cur.execute(delete_EMPOLYEE,("Tom",))
# 4. 提交事务关闭资源
conn.commit() # 提交事物
cur.close()
conn.close()requests 模块
requests 简介
-
requests 是用 Python 语言编写的、优雅而简单的 HTTP 库
-
requests 内部采用来 urillib3
-
requests 使用起来肯定会比 urillib3 更简单便捷
-
requests 需要单独安装
GET 和 POST
- 通过 requests 发送一个 GET 请求,需要在 URL 里请求的参数可通过 params 传递
- 与 GET 不同的是,POST 请求新增了一个可选参数 data,需要通过 POST 请求传递 body 里的数据可以通过 data 传递
requests 发送 GET 请求
案例 1:处理文本数据
[root@localhost xxx]# pip3 install requests # 安装requests软件包
# 使用requests处理文本数据,使用text查看【get】
[root@localhost xxx]# python3
>>> import requests # 导入requests模块
>>> url = 'http://www.163.com' # 声明变量,定义要操作的网页
>>> r = requests.get(url) # 请求,获取网页内容,赋值给变量r
>>> r.text # 查看网页内容,因为是文本类型的,采用text查看
import requests
# GET(获取数据--》查询数据) | POST(写请求)
url = "https://www.tmooc.cn/advanced/"
dc1 = requests.get(url) # 服务端响应的数据
print(dc1.text)
案例 2:处理图片视频音频等数据
>>> url2 = 'http://pic1.win4000.com/wallpaper/6/58f065330709a.jpg' # 声明变量,定义查看的图片
>>> r2 = requests.get(url2) # 请求,获取bytes类型的图片数据,赋值给变量r
>>> r2.content # 查看图片内容,因为是图片类型的,采用content查看
>>> with open('/tmp/aaa.jpg', 'wb') as fobj: # 将图片数据保存在文件aaa.jpg中
... fobj.write(r2.content)
[root@localhost xxx]# eog /tmp/aaa.jpg #在终端使用eog打开图片aaa.jpgimport requests
# https://blog.csdn.net/csdnnews/article/details/124020463?spm=1000.2115.3001.5926
url = "https://img-blog.csdnimg.cn/4e31725902b54f168b128478084ce618.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQ1NETui1hOiurw==,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center"
dc1 = requests.get(url)
#print(dc1.content) # 查看图片内容,因为是图片类型,采用content 查看
# 将图片下载到本地
fw = open("/opt/aaa.jpg",mode="wb")
fw.write(dc1.content) # 将图片写入本地文件
fw.close()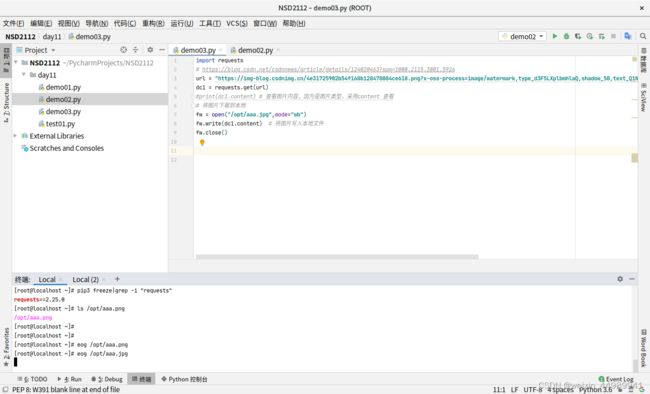
设定头部
- 用户也可以自己设定请求头
- 获取网站的【User-Agent】请求头信息

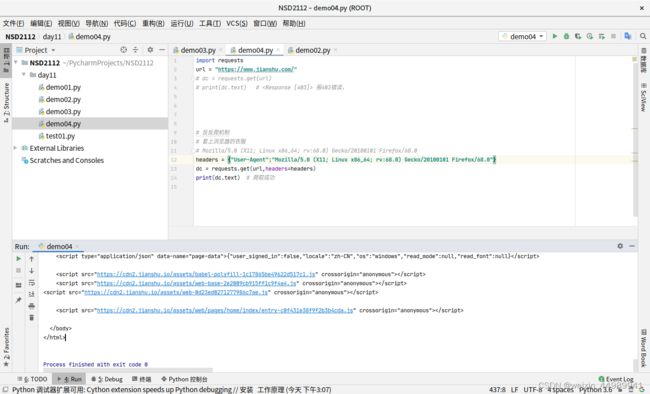
import requests
url = "https://www.jianshu.com/"
# dc = requests.get(url)
# print(dc.text) # 报403错误,
# 反反爬机制
# 套上浏览器的衣服
# Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0
headers = {"User-Agent":"Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0"}
dc = requests.get(url,headers=headers)
print(dc.text) # 爬取成功
JSON
概念
JSON 是一种轻量级的数据交换格式。
理解
数据交换格式那么多,为啥还要学个 JSON?
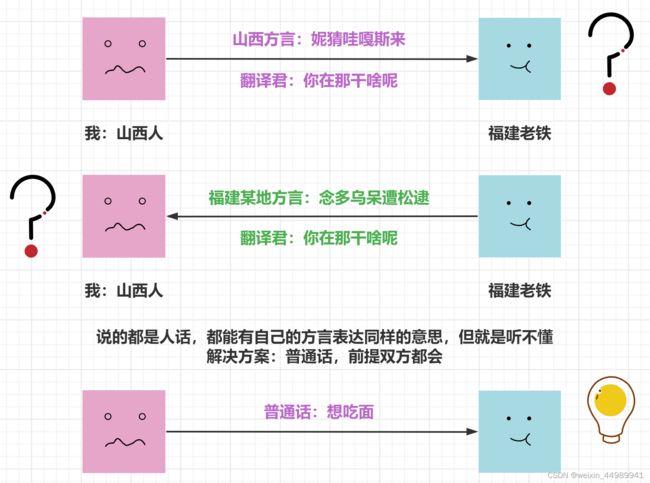
数据交换格式是不同平台、语言中进行数据传递的通用格式。比如 Python 和 Java 之间要对话,你直接传递给 Java 一个 dict 或 list 吗?Java 会问,这是什么鬼?虽然它也有字典和列表数据类型,但两种字典不是一个“物种”,根本无法相互理解。这个时候就需要用 Json 这种交换格式了,Python 和 Java 都能理解 Json。那么别的语言为什么能理解 Json 呢?因为这些语言都内置或提供了 Json 处理模块,比如 Python 的 json 模块。
基本用法
JSON格式: 在各种语言中,都可以被读取,被用作不同语言的中间转换语言【类似翻译器】
主要结构
-
“键/值” 对的集合;python 中主要对应 字典
-
值的有序列表;在大部分语言中,它被理解为 数组
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
常用函数
-
loads 方法:对编码后的 json 对象进行 decode 解密,得到原始数据,需要使用的 json.loads() 函数
-
**dumps 方法:**可以将原始数据转换为 json 格式
[root@localhost xxx]# python3
>>> import json # 导入json模块
>>> adict = {'user': 'tom', 'age': 20} # 定义字典adict
>>> data = json.dumps(adict) # dumps(),将字典转换为json格式【字符串类型】,赋值给变量data
>>> data # 查看变量的内容,字符串
>>> type(data) # 查看变量data的数据类型,为字符串类型
>>> jdata = json.loads(data) # l将json格式【字符串类型】转换为字典,赋值给变量jdata
>>> jdata # 查看变量data的值,字典
>>> type(jdata) # 查看jdata的数据类型,为字典类型
import json
userdb = {"name": "zs","age": 18}
data_json = json.dumps(userdb)
print("data_json:",data_json) # data_json: {"name": "zs", "age": 18}
print("data_json_type:",type(data_json)) # data_json_type:
# json --> dict
json_str01 = '{"name": "lisi", "age": 18, "score": 100 }'
data = json.loads(json_str01) # json --> dict
print(data["name"],data["age"],data["score"]) # lisi 18 100
print("data:",type(data)) # data: 案例 :处理 json 格式的数据
天气预报查询
- 搜索 中国天气网 城市代码查询, 查询城市代码
- 城市天气情况接口
- 实况天气获取: http://www.weather.com.cn/data/sk/城市代码.html
- 城市信息获取:http://www.weather.com.cn/data/cityinfo/城市代码.html
- 详细指数获取:http://www.weather.com.cn/data/zs/城市代码.html
# 案例 3:处理 json 格式的数据
# 天气预报查询
# 搜索 中国天气网 城市代码查询, 查询城市代码
# 城市天气情况接口
# 实况天气获取:http://www.weather.com.cn/data/sk/城市代码.html
# 城市信息获取:http://www.weather.com.cn/data/cityinfo/城市代码.html
# 详细指数获取:http://www.weather.com.cn/data/zs/城市代码.html
import requests
url = "http://www.weather.com.cn/data/sk/101042600.html"
dc = requests.get(url)
# dc.json(): 已经将json数据转换成字典格式的数据, 返回python字典
print(dc.encoding) # 查看编码方式 ISO-8859-1
dc.encoding = "utf8" # 修改编码方式
print(dc.encoding) # 查看编码方式 utf8
dict01 = dc.json()
dc = dict01["weatherinfo"]
print(dc["temp"], dc["city"])
# {'weatherinfo': # dc = dict01["weatherinfo"] dc["temp"]
# {'city': '大足',
# 'cityid': '101042600',
# 'temp': '19.1',
# 'WD': '东风',
# 'WS': '小于3级',
# 'SD': '93%',
# 'AP': '962.3hPa',
# 'njd': '暂无实况',
# 'WSE': '<3',
# 'time': '17:00',
# 'sm': '1.3',
# 'isRadar': '1',
# 'Radar': 'JC_RADAR_AZ9230_JB'}
# }
请求参数
- 当访问一个 URL 时,我们经常需要发送一些查询的字段作为过滤信息,例如:httpbin.com/get?key=val,这里的 key=val 就是限定返回条件的参数键值对
- 当利用 python 的 requests 去发送一个需要包含这些参数键值对时,可以将它们传给params
# https://www.baidu.com/s? wd=aaa
import requests
url = "https://www.baidu.com/s?"
dc = {"wd":"pythontest"}
headers = {"User-Agent":"Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0"}
dc1 = requests.get(url,params=dc,headers=headers)
print(dc1.text)