python-模拟创建jiracase和steps
整体实现
-
excel设计用例
-
校验用例文件格式
- 从excel读取用例数据
- 创建用例
- 用例内添加步骤
代码特殊处理
- excel读取时去除空行
- 步骤、测试数据、期望结果等列表字段,允许仅有一行
用例模版设计
- 文件格式:xls
- 固定字段顺序:项目、标题、等级、模块、标签、步骤、测试数据、期望结果
- 字段特殊要求:标签、步骤、测试数据、期望结果字段的内容,通过换行符切换,且三个字段的行数必须一一对应
代码
用例文件校验check_excel.py
import xlrd
from xlutils.copy import copy
class check:
def __init__(self, path, casesheet,beginnum):
self.path = path
self.casesheet = casesheet
self.beginnum=beginnum
def check_caselist(self):
wookbook = xlrd.open_workbook(self.path,formatting_info=True)
#获取用例所在的工作表
casesheet = wookbook.sheet_by_name(self.casesheet)
#复制一份用来记录校验结果,保证不影响源用例文件
wbook = copy(wookbook)
#副本内创建工作表"result"
result = wbook.add_sheet('result')
#创建一个工作表写对比结果
# 获取行数
nRows = casesheet.nrows
ncols = casesheet.ncols
ture=0
false=0
for x in range(1,nRows):
#行列表
row_case=[]
for y in range(self.beginnum,ncols):
data=casesheet.cell(x,y).value
ls=data.split('\n')
num=len(ls)
row_case.append(ls)
result.write(x, y, label=num)
if len(row_case[0])==len(row_case[1])==len(row_case[2]):
result.write(x, ncols, label='ture')
#统计行数一样的case数量
ture=ture+1
else:
result.write(x, ncols, label='false')
#统计行数不一样的case数量
false=false+1
new_file="check_"+self.path
wbook.save(new_file)
print(f"全部校验完成:总数={nRows-1},ture={ture},false={false}")
if __name__ == '__main__':
#用例文件地址
path = r'testcase.xls'
#用例数据所在的工作表名称
sheename = 'Sheet1'
#需要校验的起始列号-要求步骤、数据、期望三列
beginnum=4
a = check(path, sheename,beginnum)
a.check_caselist()
校验结果:
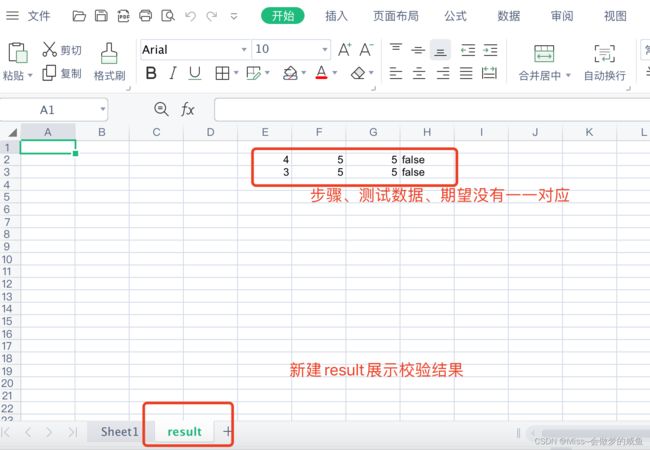
读取excel:
import xlrd
class read_data():
def __init__(self,path,sheetname):
self.path=path
self.sheetname=sheetname
def get_caselist(self):
# path= r'filems_文件生命周期.xls'
wookbook = xlrd.open_workbook(self.path,formatting_info=True)
sheetname=wookbook.sheet_names()
sheet1=wookbook.sheet_by_name(self.sheetname)
#获取行数
nRows=sheet1.nrows
ncols=sheet1.ncols
#获取单元格所在的数据
caselist=[]
for x in range(1,nRows):
row_case=[]
for y in range(0,ncols):
data=sheet1.cell(x,y).value
if y in (4, 5, 6,7):
if '\n' in str(data):
print('当前data数据:')
print(data)
ls=data.split('\n')
#去除空列表
if len(list(filter(None,ls))):
row_case.append(ls)
else:
row_case.append(str(data))
else:
row_case.append(data)
# 去除空列表
if len(list(filter(None,row_case))):
caselist.append(row_case)
print("用例集合》》》")
print(len(caselist))
print(caselist)
return caselist
if __name__ == '__main__':
path = r'test2022.xls'
sheename='Sheet1'
a=read_data(path,sheename)
a.get_caselist()创建用例
from jira import JIRA
import requests
class create_issue():
def __init__(self,username,password):
self.username=username
self.password=password
def create_case(self,id,summary,priority_name,module_name,labels):
jira = JIRA(server='https://jira.********.com/', auth=(self.username, self.password))
#获取当前的登录用户信息
user=jira.current_user()
#获取项目信息
pro = jira.project(id)
#提取项目id
proj_id=pro.id
print(proj_id)
issue_dict = {
# 项目id
'project': {'id': proj_id},
# 问题标题
'summary': summary,
# 问题类型
'issuetype': {'id': '10100'},
#用例优先级等级
'priority': {'name': priority_name},
#模块
'components':[{'name':module_name}],
# 问题标签
'labels': labels,
# 报告者
'reporter': {"name": user},
# 经办人
'assignee': {"name": user}
}
new_issue = jira.create_issue(fields=issue_dict)
# pro_key=new_issue.key
caseid=new_issue.id
# print("当前用例编号是:",pro_key)
print("当前用例id是:",caseid)
return caseid
def get_cookie(self):
url = "https://jira.********.com/login.jsp"
pyload = {
"os_username": self.username,
"os_password": self.password,
}
res = requests.post(url=url, data=pyload, allow_redirects=False)
content = str(res.headers)
org = eval(content)
# print(org)
post_cookie = org["Set-Cookie"]
# 获取resp_headers的cookie信息
print("post请求的cookie信息:")
print(post_cookie)
return post_cookie
def creat_step(self,caseid,cookie,stepDetails,testData,expectedResult):
header = {
'cookie': cookie
}
#获取步骤列表
pyload = [{
"testCaseIssueId": caseid,
"stepDetails": stepDetails,
"expectedResult": expectedResult,
"testData": testData
}]
for data in pyload:
url = 'https://jira.**********/qtm/latest/teststep?'
res = requests.post(url, json=data, headers=header)
print(res.text)
if __name__ == '__main__':
username='jira用户名'
password='jira密码'
id='项目id'
summary='测试用例执行0402-new'
priority_name='优先级级别'
module_name='模块名称'
labels=['版本号']
a=create_issue(username,password)
caseid=a.create_case(id,summary,priority_name,module_name,labels)
cookie=a.get_cookie()
a.creat_step(caseid,cookie,'oo1','oo2','003')
执行自动化创建
from read_csv import read_data
from jira_client import create_issue
import time
def create_caselist():
print("读取表格:")
file = read_data(path, sheename)
#获取用例列表
caselist=file.get_caselist()
#获取用例长度
rnum=len(caselist)
a=create_issue(username,password)
for x in range(0,rnum):
case=caselist[x]
id=case[0]
summary=case[1]
priority_name=case[2]
module_name=case[3]
labels=list(case[4])
len_stepDetails = len(list(case[5]))
len_testData = len(list(case[6]))
len_expectedResult = len(list(case[7]))
caseid = a.create_case(id, summary, priority_name,module_name, labels)
cookie=a.get_cookie()
if len_stepDetails==len_testData==len_expectedResult:
# print("当前步骤长度-----------")
print(len_stepDetails)
for i in range(len_stepDetails):
stepDetails=case[5][i]
testData=case[6][i]
expectedResult=case[7][i]
a.creat_step(caseid, cookie,stepDetails,testData,expectedResult)
# print('当前用例步骤添加完毕!')
print("用例创建完成")
if __name__ == '__main__':
#开始时间
t=int(time.time())
print('开始--------------')
#用例文件地址
path = r'test2022.xls'
sheename = '用例所在工作表的名称'
username = 'jira用户名'
password = 'jira密码'
id=''
create_caselist()
#结束时间
t1=int(time.time())
#耗时
print('结束--------------')
print('当前耗时:',t1-t)