【深度之眼】【Pytorch打卡第20天】:图像分割
目录
- 一、图像分割分类
- 二、PyTorch-Hub
-
- 常用函数
- 实例演示
- 模型如何分割
- 三、深度学习图像分割模型简介
-
- 1、FCN模型
- 2、UNet
- 3、DeepLab系列——V1
- 4、DeepLab系列——V2
- 5、DeepLab系列——V3
- 6、DeepLab系列——V3+
- 综述
- 训练Unet完成人像抠图(Portrait Matting)
图像分割:将图像每一个像素分类
一、图像分割分类
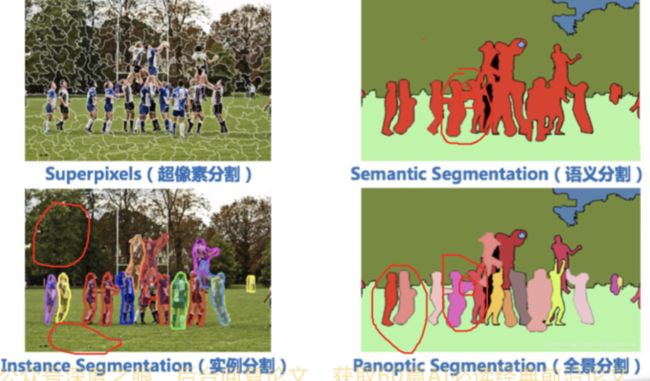
- 超像素分割:少量超像素代替大量 像素,常用于图像预处理
语义分割:逐像素分类,无法区分 个体- 实例分割:对个体目标进行分割, 像素级目标检测
- 全景分割:语义分割结合实例分割
- 超像素分割:少量超像素代替大量像素,常用于图像预处理。下图中,每一个白色的区域都是一个超像素,是由很多像素构成的,通常来说,一个超像素中的像素性质都是非常接近的,例如下面这幅图中的每个超像素中的点颜色都非常接近。超像素分割的意义在于可以用少量的超像素代替大量的超像素,这样可以加快后面的训练速度
- 语义分割:逐像素分类,无法区分个体,语义分割就是我们通常所说的图像分割, 本质上是一个分类任务,相同的类别具有相同的颜色,如下图所示
- 实例分割:对个体目标进行分割, 像素级目标检测;实例分割只对我们感兴趣的对象进行分割,如下图所示,只对人物进行了分割,而对树木和草地都没有进行任何处理
- 全景分割:语义分割结合实例分割,全景分割相当于是语义分割与实例分割结合,既拥有了对每个像素点分类的能力,又拥有了对每个个体进行区分的能力,如下图所示:
答:图像分割由模型与人类配合完成
模型:将数据映射到特征
二、PyTorch-Hub
常用函数
PyTorch-Hub—-PyTorch模型库,有大量模型供开发者调用,下面是Hub常用的三个函数。
torch.hub.load(“pytorch/vision”,‘deeplabv3_resnet101’,pretrained=True)
model=torch.hub.load(github,model,*args,**kwargs)
功能:加载模型
主要参数:
·github: str,项目名。eg: pytorch/vision,
·model: str,模型名。torch.hub.list(github,force_reload=False)列出当前github项目下有什么模型供我们调用。torch.hub.help(github,model,force_reload=False列出模型的参数。
更多参见:https://pytorch.org/hub
实例演示
# -*- coding: utf-8 -*-
"""
# @brief : torch.hub调用deeplab-V3进行图像分割
"""
import os
import time
import torch.nn as nn
import torch
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == "__main__":
# path_img = os.path.join(BASE_DIR, "demo_img1.png")
# path_img = os.path.join(BASE_DIR, "demo_img2.png")
path_img = os.path.join(BASE_DIR, "demo_img3.png")
# config
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 1. load data & model
input_image = Image.open(path_img).convert("RGB")
model = torch.hub.load('pytorch/vision', 'deeplabv3_resnet101', pretrained=True)
model.eval()
# 2. preprocess
input_tensor = preprocess(input_image)
input_bchw = input_tensor.unsqueeze(0)
# 3. to device
if torch.cuda.is_available():
input_bchw = input_bchw.to(device)
model.to(device)
# 4. forward
with torch.no_grad():
tic = time.time()
print("input img tensor shape:{}".format(input_bchw.shape))
output_4d = model(input_bchw)['out']
output = output_4d[0]
print("pass: {:.3f}s use: {}".format(time.time() - tic, device))
print("output img tensor shape:{}".format(output.shape))
output_predictions = output.argmax(0)
# 5. visualization
palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])
colors = torch.as_tensor([i for i in range(21)])[:, None] * palette
colors = (colors % 255).numpy().astype("uint8")
# plot the semantic segmentation predictions of 21 classes in each color
r = Image.fromarray(output_predictions.byte().cpu().numpy()).resize(input_image.size)
r.putpalette(colors)
plt.subplot(121).imshow(r)
plt.subplot(122).imshow(input_image)
plt.show()
# appendix
classes = ['__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
模型如何分割
-
图像分割需要的输入是一张图片,输出也是一张图片,那么对于计算机而言,输入的就一定是一个三维张量,例如(3, 224, 224),表示的就是一个3通道的,大小为224x张图片,输出也应该是一个三维张量,例如(21, 224, 224),这里的21指的是分类的
类别数为21 -
从本质上来说,图像分割模型与图像分类模型都只干了一件事情,那就是将
数据映射到特征,而人类根据自身不同的场景,定义特征的物理意义,解决实际问题,所以模型如何完成图像分割这个过程是由模型与人类配合完成的。 -
图像分割思考:如下图所示,我们将狗的头与猫的身体进行拼接,然后就行分割,可以看到模型将整体视为一只狗,从中可以发现,
模型在进行分割时,头部起到了主要作用,所以不仅仅是考虑了对于每个像素的分类,同时考虑了图像的整体信息。

三、深度学习图像分割模型简介
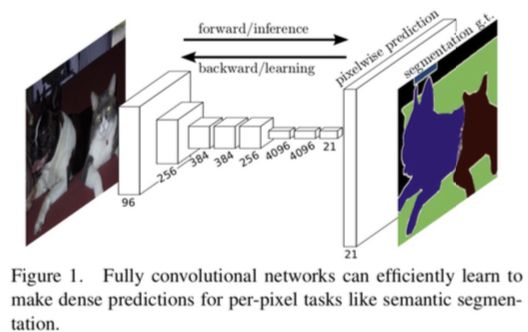
1、FCN模型
FCN是2014年提出的模型,最大的特点是全部利用卷积层实现了图像的分割,相较于Resnet,FCN并没有全连接层,这样提高了模型的适用范围,可以用于不同尺寸大小图片的分割任务。
参考论文:《Fully Convolutional Networks for Semantic Segmentation 》
2、UNet
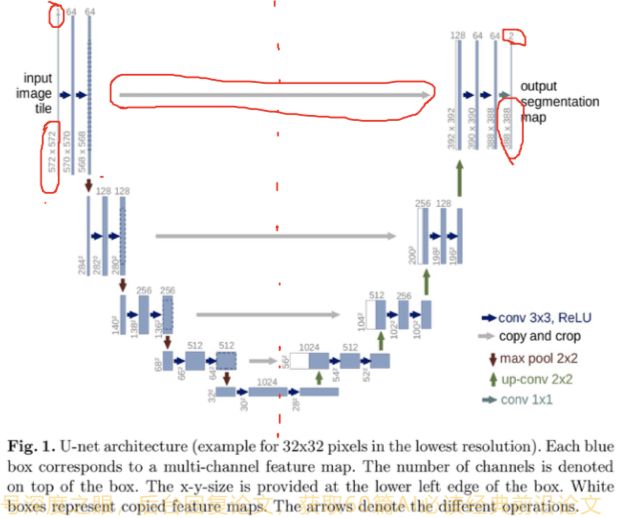
Unet是一个经典的图像分割网络,最先用于医学图像的分割,医学图像的最大特点就是样本量小,而Unet可以在样本量小的情况下取得一个比较好的分割效果,这就是Unet的强大之处。
结构基础–编码器与解码器的特征融合
网友对Unet及改进做了合集:https://github.com/shawnbit/unet-family
文献:《U-Net:Convolutional Networks for Biomedical Image Segmentation》
从图中可以看出,Unet的名字由于网络的形状像一个U,因此称之为Unet,通常我们可以把Unet从中间分开,
左边为编码器,右边为解码器,Unet最大的特点是图中灰色的箭头,表示可以将编码器的特征可以传到解码器进行特征融合。
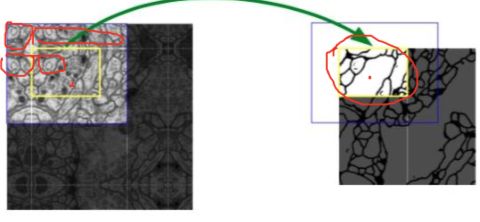
注意看上面的模型,输入shape是:572x572,1个channel(灰度图,只有一个channel),输出是388x388,2个channel(只做了2分类所以只有2个channel),为什么输入和输出不一样大呢,因为最早Unet是用来做细胞分割的,如下图所示:
其中,蓝色框是输入,黄色框是输出。注意看左图中,对黄框的边界一圈是做了镜像的padding。同时这个模型也说明了,做图像分割,输入和输出是可以不一样大的。
3、DeepLab系列——V1
DeepLab系列现在有4个:V1/V2/V3/V3+。这里看V1
- 主要特点:
孔洞卷积:借助孔洞卷积,增大感受野CRF:采用CRF进行mask后处理
文献:《DeepLabv1 Semantic image segmentation with deep convolutional nets and fully connected CRFs》

4、DeepLab系列——V2
- 主要特点:
ASPP(Atrous spatial pyramid pooling):解决多尺度问题
文献:《DeepLab-Semantic Image Segmentation with Deep Convolutional Nets,Atrous Convolution,and Fully Connected CRFs》
从图中可以看到,对于一个输入,采用了不同尺度(金字塔pyramid )的池化,4个池化的kernel都是3*3的,但是每个池化的感受野完全不同。注意看下面的颜色和上面的颜色是一一对应的。

ASPP(Atrous spatial pyramid pooling ):解决多尺度问题,这种带空洞的金字塔池化思路非常有用,如上图所示,对于同一个输入的 feature map ,采用了四种3×3的卷积核进行特征提取,但是这四种卷积核的感受野是不同的,这就完成了对同一 feature map 的多尺度特征提取。
5、DeepLab系列——V3
- 主要特点:
- 孔洞卷积的串行
- ASPP的并行
以上两个特点相当于对V1和V2两个模型中的特点进行了改进。
文献:《DeepLabv3-Rethinking Atrous Convolution for Semantic Image Segmentation》
下面是四种方法,第一个是图像金字塔;第二个是Unet;第三个是DeepLabV1的空洞卷积,第四个是DeepLabV2的金字塔池化。DeepLabV3就是针对第三个和第四个进行的优化。

主要特点是:
-
孔洞卷积的串行:下面的图片的下半部分是孔洞卷积的串行示意图(画圈圈的那里),上半部分是传统的卷积,可以看出空洞卷积保持了输出的分辨率。

-
ASPP的并行:如下图所示,ASPP的并行示意图,并行结果concat起来,然后经过1*1的卷积操作得到结果。

6、DeepLab系列——V3+
- 主要特点:deeplabv3基础上加上
Encoder-Decoder思想
文献:《DeepLabv3-Rethinking Atrous Convolution for Semantic Image Segmentation》
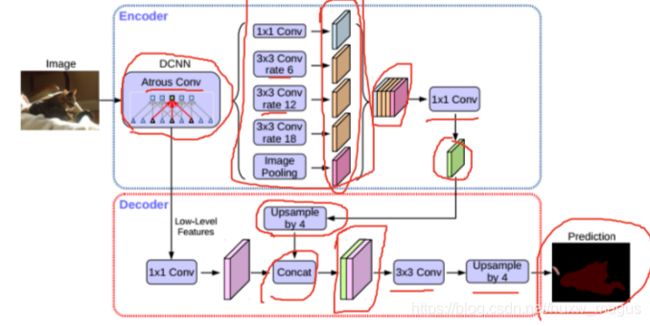
模型结构如下图,上下分别是编码和解码器。解码器中的DCNN是V1中的空洞卷积,然后接V3中的并行ASPP,可以看到使用了不同rate的特征(注意颜色)得到结果后concat起来,经过1x1的卷积,得到一个输出的特征图(编码)。
解码器中将上面得到的绿色的东西(就是编码特征图,编码器得出的结果就叫这个)先进行4倍的上采样。然后和前面的结果进concat,然后经过3x3的卷积,再进行4倍的上采样,得到最后的Prediction。
综述
综述文献:《Deep Semantic Segmentation of Natural and Medical Images: A Review. 2019》
github图像分割资源:
https://github.com/shawnbit/unet-family
https://github.com/yassouali/pytorch_segmentation

训练Unet完成人像抠图(Portrait Matting)
数据来源:https://github.com/PetroWu/AutoPortraitMatting