论文笔记7:Prioritized Experience Replay
参考资料:
https://www.baidu.com/link?url=Ea9z7rbX4jMNcr01YuTgqiRn2AVofeznnVuNTUdMmZvjqZ_odCdrm13FiahPkyur&wd=&eqid=9dd06a3a00005cfa000000035b2c5e1d
Prioritized Experience Replay (DQN) (Tensorflow) - 强化学习 Reinforcement Learning | 莫烦Python
如有错误请指出,谢谢~
知乎同名:https://www.zhihu.com/people/uuummmmiiii/activities
创新点:在抽取经验池中过往经验样本时,采取按优先级抽取的方法
改进:同上
改进原因:原来随机抽取经验忽略了经验之间的重要程度,实际上如人脑中一定会有更为重要的记忆
带来益处:使得算法更快收敛,效果更好
Abstract
经验回放使得在线强化学习的agent能够记住和重新利用过去的经验,在以往的研究中,过去的经验(transition,经验池中的一条记录,表示为元祖形式,包含state,action,reward,discount factor,next state),只是通过均匀采样来获取。然而这种方法,只要原来有过这个经验,那么就跟别的经验以相同的概率会被再次利用,忽略了这些经验各自的重要程度。
本文我们提出了一种优先回放结构,这种方法可以使重要的经验被回放的概率大,从而使学习变得更有效率。
Introduction
introduction开始介绍了经验回放机制的产生:
1、更新完参数立刻丢掉输入输出的数据:
造成两个问题:这种强相关的更新打破了很多常用的基于随机梯度下降算法的所应该保证的独立同分布特性,容易造成算法不稳定或者发散;放弃了一些在未来有用的需要重放学习的一些稀有经验。
2、1992年提出Experience Replay,解决了这两个问题,并在2013年提出的DQN(Mnih et al.)中应用,原始DQN中只是从经验池中随机取样进行回放利用。经验回放虽然可以减少agent学习所需要的经验数量(输入的data),但会增加计算量与内存,但是增加的计算量与内存对于agent与环境交互而言更cheaper。
Experience replay liberates online learning agents from processing transitions in the exact order they are experienced.
3、这里我们提出如何对经验标记优先级,来使重放比单纯的随机抽样回放更有效。
Prioritized replay further liberates agents from considering transitions with the same frequency that they are experienced.
我们用TD-error来表示优先级的大小。
1、这种方式会丢失多样性,我们用stochasitic prioritization(proportional prioritization和rank-based prioritization)来弥补;
2、这种方式也会引入bias,我们用importance-sample weights来弥补
Prioritized Replay
在利用经验池的时候会有两种选择:一是选择哪些经验进行存储,二是如何进行回放。我们仅研究第二个。分四步逐渐提出我们加入prioritized experience replay的算法。
3.1 A motivate example 一个给我们提供灵感的例子
作者为理解首先介绍了一个人工设置的称为‘Blind Cliffwalk’环境,这个环境体现了在reward很少的时候exploration的困难之处(exploration,个人理解在贪婪算法 -greedy中,以 的概率去探索,exploration,即随机选择动作。以1- 选择最大动作,即利用exploit),为什么探索过程困难?
首先看这个环境的设置:
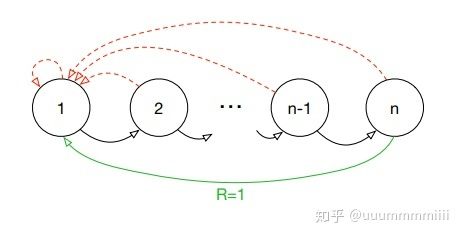
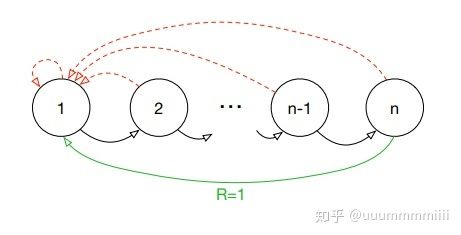
agent只有两个动作,即right和wrong,每个环节episode中以agent采取wrong行动作为terminal,并且只有当不断采取right动作,从而有过n个状态后才会得到reward为1,剩下全部为0;上面红虚线均表示结束该episode,绿线表示在n状态下采取wrong行动会终止episode并且会得到奖赏1
因为在随即采取行动的时候,得到奖励的概率很低是 ,因此对于一系列的transition,最相关的transition,即少量的成功信息,隐藏在大量的失败信息中。正如一个宝宝学习走路,在学会走路之前会不断摔倒摔倒。
这样会使得在探索过程中一直会有失败出现。
作者用这个环境比较两种agent:第一个agent采取随机抽取过去经验的方式进行Q-learning,第二个agent调用oracle去进行优先级抽取,oracle可以使得在当前状态下最大限度减少全局误差(这里的oracle感觉不太像所说的数据库,但我具体又没查出来是什么,但作者后面说用oracle方法抽取实际上是不现实的。如果这里是oracle数据库,那么可能是在库中存储数据时会有优先级的从高到低排序,每次选出优先级最高的batch数目就可以了,实际中不现实可能是因为算法中要自动实现经验池的存放,用这个数据库可能不太容易调用或者是工作量消耗比较大,但是算是对于优先级排序比较准确的方法。如有错误请指出。。。)
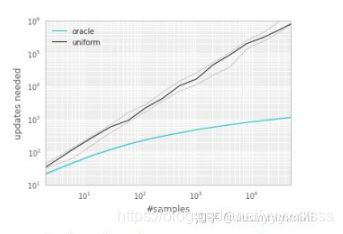
作者经过实验,优先级排序用的是TD-error来进行衡量:
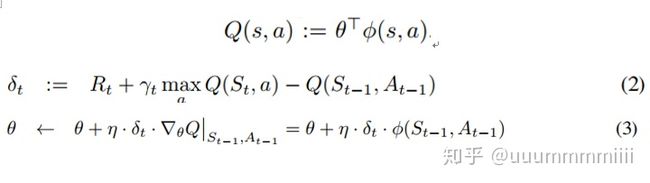
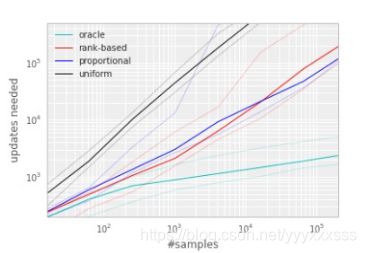
作者得到如下效果曲线,发现用优先级进行抽取与随机抽取之间到达收敛需要的更新次数相差的gap很大,激励了作者去寻找如何进行有优先级的回放:
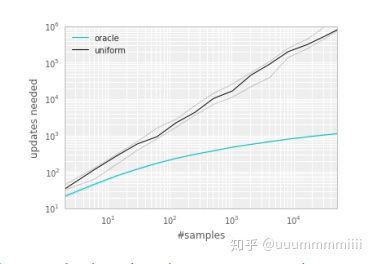
3.2 Prioritizing with TD-error 用来说明TD-error来表示优先级的效果
如何衡量每个transition的重要程度是优先回放机制的中心,一种理想的机制是在当前状态下,按agent从transitions中学习的次数,但这实际不好获得。更合理的是去计算每个transition的TD-error,这个值表示当前Q值与目标Q值有多大的差距(作者形容为surprising,按莫烦老师所说即Q现实 - Q估计,如果TD-error越大, 就代表我们的预测精度还有很多上升空间, 那么这个样本就越需要被学习, 也就是优先级p越高。)
用TD-error来衡量更加适合增量的,在线的RL算法,如Sarsa,Q-learning,因为这些在Q值更新上已经有计算TD-error的部分:
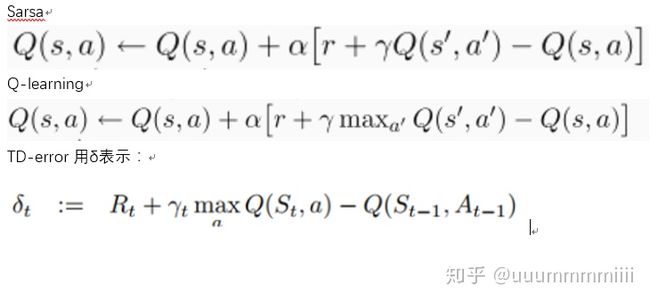
但是当reward有noisy的时候,TD-error来估计优先级也很poor。
为了说明TD-error发挥的潜在effectiveness,我们在'Blind Cliffwalk'环境下比较了随机抽取方式和基于greedy TD-error prioritization算法的oracle抽取方式(对于Q-learning)。
greedy TD-error prioritization算法在经验池中存储了每个transition最后encounter的TD-error,用这种方式,将会以TD-error的绝对值最大的进行回放。这里如果当一个新的transition到来时,我们不知道它的TD-error,那么就把这个transition的TD-error值设置为最大,这样可以保证所有的经验都会被至少回放一次。这种方法效果笔随机抽取(uniform)效果好。
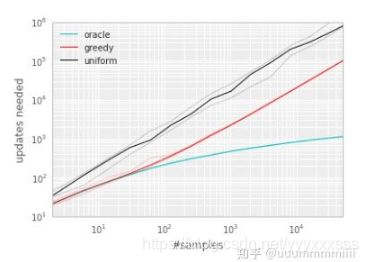
实现方法:经验池容量为N,我们用二进制堆数据结构(binary heap data structure)来存储优先级序列。这样找到找到最高优先级的transition的复杂度是O(1),更新优先级的复杂度 为O(logN)
3.3 stochasitic prioritization 为解决采用TD-error丧失多样性的问题
greedy TD-error prioritization算法有几个问题:
1、为了避免由于扫描整个经验池带来的昂贵代价,只会更新被重放的transition的TD-error值,这样会造成:第一次见到过的一个有很小的TD-error的transition存放到经验池后,在很长时间都不会被回放
2、TD-error对于噪声很敏感,容易将源于噪声的估计误差加入。
3、这个算法专注于经验的一小部分,TD-error减小慢,特别是在使用函数近似(Function approximation,有linear函数估计,例如线性回归,以权重作为参数;有non-linear函数估计,例如NN),高的TD-error由于重放频繁会使得丧失多样性造成过拟合。
(为什么丧失多样性造成过拟合:对于DQN,回放就是把经验池中取出的transition中的s状态输入到Q-network中,next state 输入到target Q-network中,然后进行一系列计算loss,反向传播更新网络参数,如果一直重复这一条信息输入,那么我对于训练网络过程来说精度会很高,而当测试的时候,输入别的状态就会使测试精度降低,即过拟合)
为了解决这些问题:
作者引入了一种stochastic sampling的方法,这种方法是一种介于纯greedy prioritization算法与原始uniform random sampling算法之间的一种方法。
用这种方式,我们可以保证transition被抽取的概率是按优先级单调的,同时保证对于低优先级的transition不会出现0概率抽取可能。具体的,抽取标号为i的transition的概率定义为:

 这里pi是transition i 的优先级,均大于0,α是一个决定我们要使用多少 ISweight 的影响, 如果 alpha = 0, 我们就没使用到任何 Importance Sampling.就是uniform random sampling
这里pi是transition i 的优先级,均大于0,α是一个决定我们要使用多少 ISweight 的影响, 如果 alpha = 0, 我们就没使用到任何 Importance Sampling.就是uniform random sampling
对于pi这个优先级值的定义,作者提出了两种变体:
第一种 proportional prioritization ,这里的pi= + ,是一个很小的正常数为了使有一些TD-error为0 的特殊边缘例子也能够被抽取。
第二种 rank-based prioritization ,这里pi= ,这里的rank(i)是按照排序时transition i的等级。(这时P将成为幂律分布)
对于这两种变体,P都关于是单调的,对于第二种变体由于对异常值不敏感,可能更具有鲁棒性。但是经过试验,这两种变体都可以加速算法收敛:
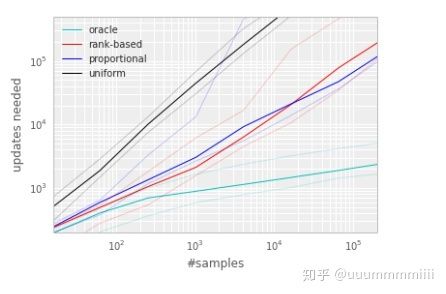
实验实现:
为了有效地从P分布中取样,复杂性不能依赖于经验池的容量N。
第一种变体 proportional prioritization 实现:(来自莫烦老师,见上面参考文献链接)
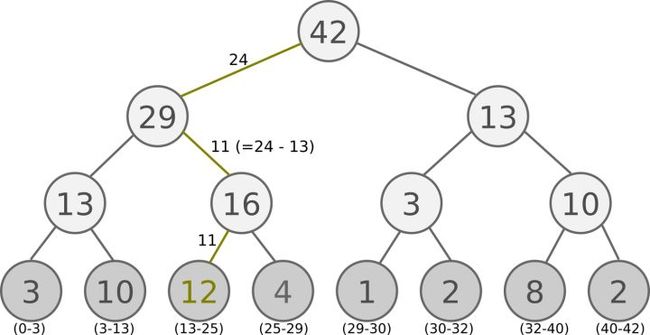
利用一种更有效的更新和取样实现方式:基于‘sum-tree’的数据结构,SumTree 是一种树形结构, 每片树叶存储每个样本的优先级p, 每个树枝节点只有两个分叉, 节点的值是两个分叉的合, 所以 SumTree 的顶端就是所有p的合. 正如下面图片(来自Jaromír Janisch), 最下面一层树叶存储样本的p, 叶子上一层最左边的 13 = 3 + 10, 按这个规律相加, 顶层的 root 就是全部p的合。
抽样时, 我们会将p的总合 除以 batch size, 分成 batch size 那么多区间(n= )如果将所有 node 的 priority 加起来是42的话, 我们如果抽6个样本, 这时的区间拥有的 priority 可能是这样.
[0-7], [7-14], [14-21], [21-28], [28-35], [35-42]
然后在每个区间里随机选取一个数. 比如在区间[21-28]里选到了24, 就按照这个 24 从最顶上的42开始向下搜索. 首先看到最顶上42下面有两个 child nodes, 拿着手中的24对比左边的 child29, 如果 左边的 child 比自己手中的值大, 那我们就走左边这条路, 接着再对比29下面的左边那个点13, 这时, 手中的 24 比13大, 那我们就走右边的路, 并且将手中的值根据13修改一下, 变成 24-13 = 11. 接着拿着 11 和13左下角的12比, 结果12比 11 大, 那我们就选 12 当做这次选到的 priority, 并且也选择 12 对应的数据.
第二种变体 rank-based prioritization 实现:
我们可以用一个分段线性函数来近似累积密度函数,k段的概率是相等的。分段边界可以预先计算出来(因为只与N和alpha有关系)。在运行时,我们选择一个片段,然后在这个片段中的所有transition中均匀地采样。选k为minibatch的大小,从每一个片段中选出一个transition——这是一种分层抽样,可以平衡minibatch。
我们选择以数组为基础的二进制堆结构实现的优先队列中存储转换。然后,堆数组近似代替排序数组,为防止堆变得不平衡,我们不是在每N步进行一次排序,这是对二进制堆的非常规使用,但是我们对较小环境的测试表明,与使用完全排序的阵列相比,学习是不受影响的。这可能是由于最后看到的TD-error仅仅是代表一个transition的有用性和我们对随机优先级抽样的使用。在运行过程中,为避免对抽样分布的分区过度重计算,我们做了一个小改进。我们为N的值重用了相同的分区,这些值是紧密联系在一起的,并且不经常更新α和β。我们对 rank-based prioritization 验证时发现增加2%-4%的运行时间,并且可以忽略额外的内存使用。这点可以有很多方面的改进去解决,例如,使用更高效的堆实现,但是对于我们的实验来说已经足够好了。
总结:这一节中出现的进行transition回放的方式:
1、不进行优先级排序,然后采用原始的uniform 抽取(uniform random sampling)
2、调用oracle进行优先级排序,然后再抽取优先级高的transition进行回放
3、调用基于‘greedy TD-error prioritization’算法的oracle进行排序,然后再抽取优先级高的transition进行回放。
(这里的‘greedy TD-error prioritization’算法就是指按照 TD-error的绝对值大小值进行排序,用二进制堆数据结构从上到下按优先级高低进行排序)
4、 第一种变体 proportional prioritization,用sumtree结构(更常用),与普通的二进制堆结构不同,每个节点是其子节点的和
5、 第二种变体 rank-based prioritization ,基于二进制堆结构用优先队列直接存储各个transition
3.4 Annealing the bias(为减少bias提出解决方法)
随机更新对期望值的估计依赖于与预期相同的分布相对应的更新。优先重放机制引入了bias,它以一种不受控制的方式改变了这个分布,因此改变收敛结果(即使策略和状态分布是固定的)。我们可以通过引入importance-sample weights来弥补:
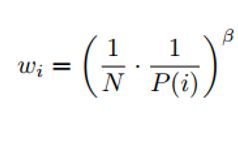
这完全补偿了当β=1时非均匀概率P(i)。这些权重可以通过使用 而不是 来加入到Q-network更新中。
Importance sampling的影响:
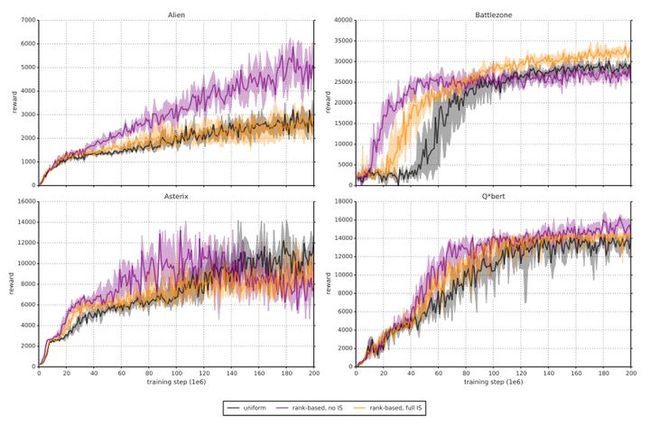
在典型的强化学习场景中,更新的无偏性在训练结束接近收敛时是最重要的,因为由于策略、状态分布和引导目标的改变,有bias会高度不稳定,与未修正的优先重放相比,Importance sampling使学习变得不那么具有侵略性,一方面导致了较慢的初始学习,另一方面又降低了过早收敛的风险,有时甚至是更好的最终结果。与uniform重放相比,修正的优先级排序平均表现更好。
最终我们得到算法:
