脸部关键点检测(数据读取和处理)
参考资料:
数据读取和处理官网教程
对于初学者来说,编程遇到的头一个问题可能就是不知道怎么编写数据读取的代码以输入网络。本文主要讲解的就是编写该部分代码的常见方法和编程思路。内容基本是官方文档的翻译与总结。
数据
下载链接
下载之后保存在data/faces路径下。
里面一共有69张脸部图片,有一个csv文档作为金标准用于保存所有的关键点,每一张脸部图像有68个关键点。
打开csv文件可以看到该文档以表格的形式保存着所有图片的文件名和对应关键点的坐标。

单张图片和标签的读取
在进入正式主题之前,为了理解之后的代码,我们先来看下单张图片和对应标签的读取和可视化。
#--coding:utf-8--
import os
import pandas as pd
from skimage import io
import matplotlib.pyplot as plt
#用pandas库读取csv文件
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 65#行号
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.figure()
show_landmarks(io.imread(os.path.join('data/faces/', img_name)),
landmarks)
plt.show()运行结果:


数据集的读取和处理
Pytorch数据读取的思路大致分为两步。
1、读取并处理数据集获得Dataset的子类。方法可以是自定义子类,也可以直接调用现有的类方法如ImageFolder。
2、调用Dataloader方法分批迭代读取数据
一、Dataset类
torch.utils.data.Dataset是一个抽象类,代表着一个数据集。在读取一个数据集时,我们应该定义一个该类的子类,并重写下列方法:
__len__:返回数据集的大小,有多少张图片
__getitem__:返回索引值对应的样本。从而dataset[i]就能得到对应的样本。
我们将在__init__函数中读取csv文件,而在__getitem__函数中读取图片。这样就不需要读取所有图片占用内存了,而是只在需要的时候读取对应索引的图片即可。
我们数据集的样本将以字典的形式保存{'image':image,'landmarks':landmarks}
数据处理的部分将会封装在transform类中,这个之后讲。
我们来看具体的代码:定义一个数据集并将其实例化,可视化前四个样本。
#--coding:utf-8--
'''
一个数据读取的实例。特征点坐标检测
'''
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].values
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
#实例化一个类,
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
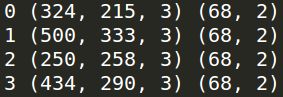
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break运行结果:

二、Transforms
在上面的代码中,我们看到有这么一行 sample = self.transform(sample),这是对样本进行预处理操作。那么这个transform该怎么写呢?
我们通常把transform写成一个类,并实现它的__call__方法。下面以尺度变换,随机裁剪和张量转换三种预处理操作为例讲解该类的实现和调用。
完整代码如下:
#--coding:utf-8--
'''
一个数据读取的实例。特征点坐标检测
'''
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].values
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
#三个数据变换类的定义
class Rescale(object):
"""Rescale the image in a sample to a given size.
对图片和控制点的坐标进行尺度变换。
Args:
output_size (tuple or int): Desired output size. If tuple, output is
matched to output_size. If int, smaller of image edges is matched
to output_size keeping aspect ratio the same.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# h and w are swapped for landmarks because for images,
# x and y axes are axis 1 and 0 respectively
landmarks = landmarks * [new_w / w, new_h / h]
return {'image': img, 'landmarks': landmarks}
class RandomCrop(object):
"""Crop randomly the image in a sample.
图片进行规定尺寸的随机裁剪。控制点的坐标相应平移
Args:
output_size (tuple or int): Desired output size. If int, square crop
is made.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors.
numpy数组到tensor的变化,另外还有维度的变化。
"""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}
#前两个类的应用实例
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# Apply each of the above transforms on sample.
fig = plt.figure()
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/')
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()运行结果:

其中,transforms.Compose函数可以将多个预处理操作集成,是常用的一个函数。
三、DataLoader
数据集的读取和预处理讲解完毕,下面的问题是如何在数据集上进行迭代,一种简单的写法是利用 for i in range(len(dataset))循环迭代。实例代码如下:
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break但是,这种写法忽略了一些问题,如批处理,打乱读取顺序,多线程读取等。而torch.utils.data.DataLoader就提供了以上特性。
我们来看DataLoader的调用示例。接上面三个Transforms类的定义
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=4)
# Helper function to show a batch
def show_landmarks_batch(sample_batched):
"""Show image with landmarks for a batch of samples."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size,
landmarks_batch[i, :, 1].numpy(),
s=10, marker='.', c='r')
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# observe 4th batch and stop.
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.show()
break运行结果:

四、另一种数据集读取方法:ImageFolder
当你做分类任务的时候,你可以把不同类别的图片放在不同的文件夹中,文件夹的名称就是该类的标签,比如这样。

这时候你可以直接用ImageFolder读取图片和标签,而不用再去自定义一个dataset类。实例代码如下:
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',
transform=data_transform)
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,
batch_size=4, shuffle=True,
num_workers=4)参考:
https://blog.csdn.net/m0_37935211/article/details/90246643