(超详细) Gradient Descent(梯度下降)和Back propagation(反向传播)的关系
想快速了解反向传播和梯度下降可以直接看最后的总结。
Gradient Descent(梯度下降)
1. 是什么?
- 梯度下降是用来找出参数w,使得损失函数L(w)最小。
2. 梯度下降法是怎么实现的?
- 先随机选一个初始的参数θ(参数包括权值w,偏差b(bias)等)
- 计算微分:对每一个未知的参数,都去计算它对L的微分,然后把它们集合起来就是一个向量,用∇ L(θ)表示(它是一个向量)。这个∇就代表了Gradient。

- 接下来更新参数。右边的η是学习率。θ上标 0 代表它是一个随机选的参数,把这个
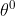 减掉 η 乘上微分的值,得到
减掉 η 乘上微分的值,得到 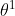 ,代表 θ 更新过一次的结果。
,代表 θ 更新过一次的结果。
- 一直持续更新参数,直到找到适合的参数为止。
Back propagation(反向传播)
背景引入:初步了解完梯度下降之后,我们来说说反向传播。我们在神经网络和逻辑回归中所用的梯度下降法本质是没有什么差别的。但是,最大的问题是,在神经网络中,我们有非常多的参数,所以会导致∇ L(θ)向量很长,那么我们如果有效的计算这个∇ L(θ)呢?这就是反向传播要做的事情。所以反向传播也是梯度下降,只不过它是一个比较有效率的演算法。它可以有效的把∇ L(θ)向量计算出来。
一些概念
- 损失函数:定义在单个训练样本上,单指一个样本的误差
- 代价函数:定义在整个训练样本上,即所有样本的误差的平均值。
- 总体损失函数:定义在整个训练样本上,即所有样本误差的总和。也是我们反向传播需要最小化的值。
分析
![]() 就是预测值和实际值的差。预测值
就是预测值和实际值的差。预测值![]() 是把训练值代入神经网络里面得出的。
是把训练值代入神经网络里面得出的。

下图是反向传播的目标(很重要):
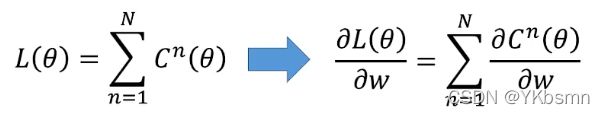
L(θ)就是神经网络的总体损失函数,由于L(θ)是所有损失之和,因此我们只需要求出其中一个损失函数的偏微分,最后再求和即可。所以只需要求出每个样本的损失函数C(θ)的偏微分,也就是 。
。
下面先对一个神经元进行分析(求∂C/∂w)。

那么怎么计算 ∂C/∂w 呢?可以通过链式法则来分开计算。即 ![]() 。而这两个偏导数分别通过Forward pass 和 Backward pass计算出来。
。而这两个偏导数分别通过Forward pass 和 Backward pass计算出来。
1、Forward pass:计算所有参数的 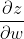
- 顺推法是非常简单的,由上图易知
 。我们已知输入是x1,根据公式,w1对z的微分,其实就是我们的输入x1。
。我们已知输入是x1,根据公式,w1对z的微分,其实就是我们的输入x1。
2、Backword pass:计算所有激活函数的输入z的 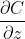
最困难的地方来了,Backword pass!!希望小伙伴们集中精神看,先上图:

先说前提:假设神经元function是sigmoid,所以a=σ(z)。假设蓝色神经元的下一层红色神经元只有两个(方便理解)。
(1)分析:
- 首先还是通过链式法则来分解
 。(式子 1-1)
。(式子 1-1) - z' = a *
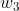 + value。
+ value。 -
z'' = a *
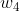 + value。
+ value。
由a=σ(z),所以∂a/∂z其实就是σ'(z),也就是对sigmoid函数做偏微分,这个很好计算。关键还是计算 ∂C/∂a。那么怎么计算呢?
由上图以及分析可知a通过z'和z''去影响c。所以 。通过上面分析的z'和z'',很容易算出 ∂z'/∂a =
。通过上面分析的z'和z'',很容易算出 ∂z'/∂a = ![]() 。同理可以求出 ∂z''/∂a =
。同理可以求出 ∂z''/∂a = ![]() 。
。
所以难点是求 ∂C/∂z' 和 ∂C/z'' 。现在我们还不知道 ∂C/∂z' 和 ∂C/z'' ,我们先假设已经知道(后面再进行讨论),把这些值代入到上面的(式子1-1)中,就可以得出 ∂C/∂z:

总体梳理一下:我们的目标是想求∂C/∂z。而σ'(z)、w3和w4都很容易求出,所以最后的难点是在于求∂C/∂z' 和 ∂C/z'' 。(简单说就是求出∂C/∂z' 和 ∂C/z'',就能求出∂C/∂z)
(2)从另外一个角度去看待上面的式子 ∂C/∂z(很重要,也是反向传播的核心思想所在):

假设∂C/∂z' 和 ∂C/z''是已知的,那么把它们两作为输入,三角形神经元可以理解为乘法运算电路,其放大系数为σ′(z)。
注意这里的σ′(z)是常数,因为在foward pass的时候已经计算出z的值了 ,所以在给定z的情况下,这个σ′(z)就是一个常数。这个神经元和我们之前的sigmoid神经元不一样,它并不是把输入值通过非线性函数进行转换,而是把输入值直接乘σ′(z)而得到输出值,这里的神经元用三角形表示(之前的用圆形表示)。
ok,那么现在问题就只剩下计算∂C/∂z' 和 ∂C/z''这两项?
(3)我们现在假设两种不同的情况:
Case 1:已经到达输出层

先假设几个前提:假设红色的两个神经元已经是输出层了,已经计算出来y1和y2了。
怎么计算 ∂C/∂z' ?
- 用链式法则如上图所示分解成两个计算。
- 计算 ∂y1/∂z' 。y1其实就是 σ′(z),所以 ∂y1/∂z' 其实就是对sigmoid函数求偏微分。
- 计算 ∂C/∂y1。这个就看你的cost function(代价函数)怎么定义,即预测值和实际值之间如何评估,可以是cross entropy(交叉熵),可以是mean square error(均方误差),总之它也是可以计算出来的。
计算 ∂C/∂z'' 也是同理。
总体梳理一下,如果是case1这种情况,计算∂C/∂z' 是轻而易举的。
Case 2:未达到输出层
因为后面还有很多layers,那么需要一直套娃,直到到达输出层为止。

解释一下为什么需要一直计算下去:由前面的分析可知,我们只要算出 ∂C/∂![]() 和 ∂C/∂
和 ∂C/∂![]() ,就能得出
,就能得出![]() 和
和![]() ;原理和上面一样。
;原理和上面一样。![]()
但是如果绿色的神经元不是输出层,那么这个∂C/∂![]() 我们无法直接算出来,需要下一层的微分来反向计算出∂C/∂
我们无法直接算出来,需要下一层的微分来反向计算出∂C/∂![]() ;而下一层若不是输出层,它也需要再下一层的偏微分反向推出来,所以就一直套娃直到最后一层。
;而下一层若不是输出层,它也需要再下一层的偏微分反向推出来,所以就一直套娃直到最后一层。
这么看,如果我们有十层神经元,那么需要从第一层展开到最后一层,是不是感觉很恐怖,但其实我们实际上不是这么做的。(我们换个思路,从最后的输出层往回走!!)
举个栗子

本来,我们要计算z1的偏微分,我们需要计算z3和z4的偏微分,想要知道z3的偏微分,我们又需要计算z5和z6的偏微分。这样做就显得效率很低,那么我们换一种思路!!

换一种思路:反过来我们先算z5和z6的偏微分,那么就可以得出z3和z4的偏微分,然后就可以得出z1和z2的偏微分。(可能有些小伙伴会有疑惑z5和z6怎么逆推出z3和z4的偏微分?在前面(2)的换一种角度看式子里有解释清楚,即![]() )
)
梳理一下,我们本来是建立一个正向的神经网络,里面的激活函数都是sigmoid函数。那现在我们backfoward pass就是建立一个反向的神经网络,它的激活函数需要先通过forward pass算出z,然后得到σ′(z)之后才算得出来。这个反向的神经网络的输入就是z5和z6的偏微分,其它其实和一般的神经网络一样。输出就是∂C/∂Zi。
最后总结:

- Foward pass负责计算 ∂Z/∂w,Backward pass负责计算 ∂C/∂z。
- 然后两者相乘得到 ∂C/∂w。
好了,最后的最后,回归到问题的初始:
1、反向传播是用来有效的计算∇ L(θ)向量,而L(θ)又取决于求∂C/∂w。而 ∂C/∂w 通过foward pass和Backward pass计算出来。
2、梯度下降通过反向传播计算出∇ L(θ)之后,接下来更新参数
,使得损失函数L(
资料参考:李宏毅老师的机器学习!!
如有错误,欢迎指正嘿嘿。