openGauss持续构筑企业级内核能力,使能行业技术创新
企业级数据库openGauss开源一年以来,社区迅速壮大,生态蓬勃发展,围绕企业级性能、企业级安全、企业级可靠等方面持续加强,并在行业加速落地。目前openGauss成功支撑邮储银行新一代分布式金融核心系统上线,并成功打造同业领先的金融核心系统;帮助中华人寿团险核心系统使用鲲鹏全栈替换,实现性能倍增;openGauss基于鲲鹏4路服务器的中国移动数据库性能测试排名绝对领先。面向未来,openGauss将从国计民生行业数据库应用的最紧迫问题和长远需求出发,不断在核心技术上进行突破,将根扎深,共同打造枝繁叶茂的数据库主流生态。
openGauss面向企业核心业务场景持续创新
推出面向核心业务场景的高可靠特性
金融与运营商在社会经济运行中处于关键基础位置,其核心业务场景,对数据库的性能和稳定性有苛刻的要求。openGauss 将于6月30日发布软硬协同的高可靠特性-RAS故障感知功能,该特性基于鲲鹏最新4路高端服务器和openEuler操作系统,支持在硬件内存发生故障前,及时通知上层OS与数据库,实现数据库故障隔离与快速切换,在核心业务数据库场景业务运行故障无感知,数据安全可控无丢失。

图1: openGauss基于RAS的高可靠原理图:故障隔离、快速切换
推出多款重量级企业级特性,数据库更快、更稳、更强
此外openGauss社区将持续为企业级用户打造高可用、高性能内核,openGauss将在9月30日的版本中,面向开发者和企业用户发布In-place Update存储引擎、基于Paxos协议的DCF高可用组件以及兼顾TP业务和AP业务的HTAP特性。
In-place Update中文意思为原地更新,是相对于openGauss行引擎当前所采用的Append Update(追加更新)模式的升级。追加更新对于业务中的增、删以及HOT UPDATE(即同一个页面内更新)有很好的表现,但对于跨数据页面的非HOT UPDATE场景,垃圾回收不够高效。而原地更新模式将最新版本的“有效数据”和历史版本的“垃圾数据”分离存储:最新版本的“有效数据”存储在数据页面上,单独开辟一段UNDO空间,用于统一管理历史版本的“垃圾数据”,因此数据空间不会由于频繁更新而膨胀,垃圾回收效率更高(参见图2)。同时可实现基于NUMA-Ware架构的高可扩展UNDO子系统以及基于多版本的索引技术。在这种设计思路下,用户可彻底抛弃原有垃圾数据清理机制,从而使整体系统运行更加平稳,适应更多业务场景和工作负载。
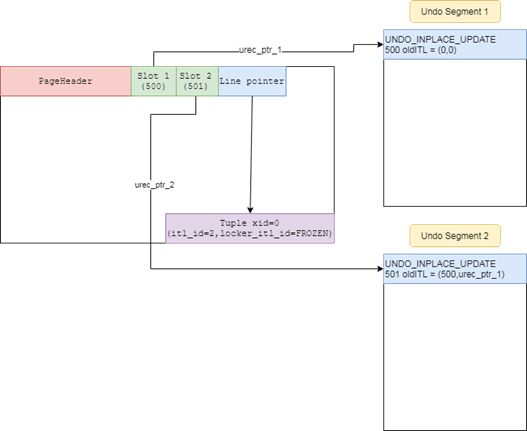
图2: In-place Update数据存储示意图:数据在原page页,undo通过指针单独管理
Paxos是一种强一致、高可用的分布式一致性协议。对于存在宕机风险的分布式系统来说,在不要求可靠的消息传递下可实现数据强一致,且可容忍消息丢失、延迟、乱序及重复。基于多数派机制的Paxos协议保证了2F+1的容错能力,即2F+1个节点的系统最大允许F个节点同时出现故障。更进一步,Paxos协议具备自仲裁,多数派选主及日志复制能力,使得openGauss在保证数据一致性的同时,在高可用方面可进一步得到增强,包括:
(1)通过自仲裁、多数派选主能力摆脱第三方仲裁组件,极大缩短RTO时间,且可预防任何故障下的脑裂双主;
(2)支持节点同步、同异步混合部署的多集群部署模式;
(3)提升主备间节点日志复制效率,提升系统的最大吞吐能力。借助openGauss的DCF高可用组件,用户不仅可以免去系统脑裂的风险,还可以提升系统性能。
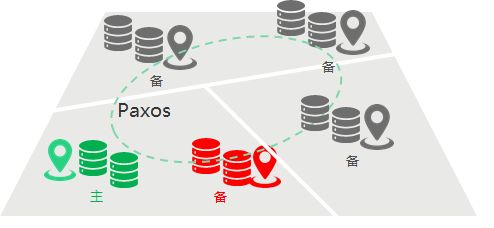
图3: Paxos原理示意图
HTAP代表了一类数据库应用场景,核心思想在基于一套内核提供TP和AP的混合负载能力,而混合负载的两个核心要素是性能和资源控制。从性能维度,openGauss将基于现有的能力进一步挖掘系统并行执行能力(如SMP),提升CPU利用率(如动态编译执行),实现内存内计算(如内存引擎),这些不同引擎或能力支撑openGauss从容应对不同的负载请求。而资源控制方面通过资源管理流机制实现不同负载间的资源隔离,即彼此间互不影响且资源足够,该方法让各自负载在满足SLA的基础上,有非常好的实时性。HTAP实现了单个系统的多业务负载处理能力,一套数据底座,应对两套业务模型,省去数据迁移的代价。
图4: HTAP即能进行事物处理,又能进行分析处理
openGauss除了在内核能力上不断推出新特性,同时在社区和生态建设上,携手伙伴一起打造面向分布式场景的高竞争力解决方案。
openGauss通过ShardingSphere分布式中间件,实现线性扩展,最高可达6400数据分片,可以满足业务不断增长的数据规模要求;结合业务流量,可以灵活平滑进行数据节点的扩缩容,智能读写分离,实现分布式数据库的自动负载均衡。而标准化镜像机制确保多环境一致性交付,不仅能够支持多云场景,还能有效降低企业对平台的依赖性。同时这套分布式方案,还能支持强有力的集群管理、运维能力以及多地多中心灵活部署。
共建、共享、共治,打造数据库主流生态
生态是开源库数据库成功的关键因素,openGauss一直就秉持共建、共享、共治的生态策略,携手产业链伙伴,最终实现生态共赢。openGauss不仅代码开源,还通过开源社区运营,让业界的开发者、伙伴能公开透明的参与进来,通过技术委员会、SIG组的形式广泛汇聚业界的技术专家,为openGauss发展提供源源不断的智力支持和思想输入。当前,openGauss社区理事会正在筹备中,预计于下半年成立,是openGauss开源社区主要治理机构。

图5: 100+企业加入openGauss社区
开源近一年,openGauss得到业界伙伴的强烈的响应和支持,已有6家数据库企业基于openGauss发布商业发行版,下半年会有更多新的企业发布商业发行版。目前,民生银行、中国电信云公司、深信服等30多家企业级用户已加入社区,并在多个关键特性上积极贡献。openGauss还与行业解决方案软件伙伴紧密合作,针对行业场景的特点,联合推出对应解决方案:与深信服推出高性能安全数据库一体化方案、联合SharingSphere社区推出全栈开源的分布式中间件解决方案、联合头部厂商面向降本增效场景推出存算分离方案等,相关联合解决方案均已在行业核心场景实现商用落地。
智能基座、产教融合,为产业界提供丰沛的人才
创新之道,唯在得人。得人只要,必广其途以储之。高校是人才培养的根据地,是人才发展的未来。openGauss联合高校,通过产、学、研、用,打通人才体系建设,通过基础理论对接产业和市场需求构建知识体系,从理论到实践到应用相结合,构建良性人才生态,激发产业持续活力。
目前清华、北大、复旦等50余所著名高校已开设openGauss课程,覆盖数万名学生,另有超过30所院校已确定将在年内开课,未来一年,预计将有超过200所院校在教学中使用openGauss,真正实现产教融合。目前,openGauss已进入全国计算机等级考试。
openGauss逐渐成为数据科学的学术创新平台,清华大学、北京航空航天大学、西北工业大学、西安电子科技大学等数十所高校,均已基于openGauss进行创新型基础研究工作,如AI-native的数据库技术、面向新硬件(ARM多核、TPU/GPU、RDMA、NVM/SCM等)新型数据库技术、云数据库架构研究、面向行业数字化转型的数据及隐私保护、面向嵌入式设备场景的数据库系统等方向研究。
从基础研究、高校合作到产业创新,openGauss社区汇聚高校、产业界的智慧和力量,共同开展数据库基础软件创新突破。openGauss持续聚焦数据库根技术,以开源协作创新,为业界带来持续领先的数据库技术与产品;以开放繁盛生态,联合产业链上下游伙伴,让openGauss落地千行百业,助力客户加速数字化转型,共促产业发展和生态繁荣。