一、MySQL事务
1、事务的概念
(1)事务是一种机制、一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这组数据库命令要么都执行,要么都不执行。
(2)事务是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元。
(3)事务适用于多用户同时操作的数据库系统的场景,如银行、保险公司及证券交易系统等等。 (4)事务通过事务的整体性以保证数据的一致性。
2、事务的 ACID 特点
注:ACID,是指在可靠数据库管理系统 (DBMS) 中,事务 (transaction) 应该具有的四个特性:原子性 (Atomicity) 、一致性 (Consistency )、隔离性 (Isolation) 、持久性 (Durability) 。这是可靠数据库所应具备的几个特性。
(1)原子性:指事务是一个不可再分割的工作单位,事务中的操作要么都发生,要么都不发生。 a、事务是一个完整的操作,事务的各元素是不可分的。
b、事务中的所有元素必须作为一个整体提交或回滚。
c、如果事务中的任何元素失败,则整个事务将失败。
(2)一致性:指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
a、当事务完成时,数据必须处于一致状态。
b、在事务开始前,数据库中存储的数据处于一致状态。
c、在正在进行的事务中,数据可能处于不一致的状态。
d、当事务成功完成时,数据必须再次回到已知的一致状态。
(3)隔离性:指在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。 对数据进行修改的所有并发事务是彼此隔离的,表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。 修改数据的事务可在另一个使用相同数据的事务开始之前访问这些数据,或者在另一-个使用相同数据的事务结束之后访问这些数据。
(4)持久性:在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
a、指不管系统是否发生故障,事务处理的结果都是永久的。
b、一旦事务被提交,事务的效果会被永久地保留在数据库中。
总结:在事务管理中,原子性是基础,隔离性是手段,一致性是目的,持久性是结果。
3、事物之间的互相影响
(1)、脏读:一个事务读取了另一个事务未提交的数据,而这个数据是有可能回滚的。
(2)、不可重复读:一个事务内两个相同的查询却返回了不同数据。这是由于查询时系统中其他事务修改的提交而引起的。
(3)、幻读:一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,另一个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。 那么,操作前一个事务的用户会发现表中还有没有修改的数据行,就好象发生了幻觉一样。
(4)、丢失更新:两个事务同时读取同一条记录,A先修改记录,B也修改记录 (B不知道A修改过),B提交数据后B的修改结果覆盖了A的修改结果。
二、Mysql及事务隔离级别
(1) 、read uncommitted:读取尚未提交的数据,不解决脏读
(2)、 read committed:读取己经提交的数据,可以解决脏读
(3)、 repeatable read:重读读取,可以解决脏读和不可重复读-------------mysql默认
(4)、 serializable:串行化,可以解决脏读不可重复读和虚读----------------相当于锁表 注:mysql 默认的事务处理级别是 repeatable read,而 Oracle 和 SQL Server 是 read committed
1、查询全局事务隔离级别
show global variables like '%isolation%'; 或 select @@global.tx_isolation;

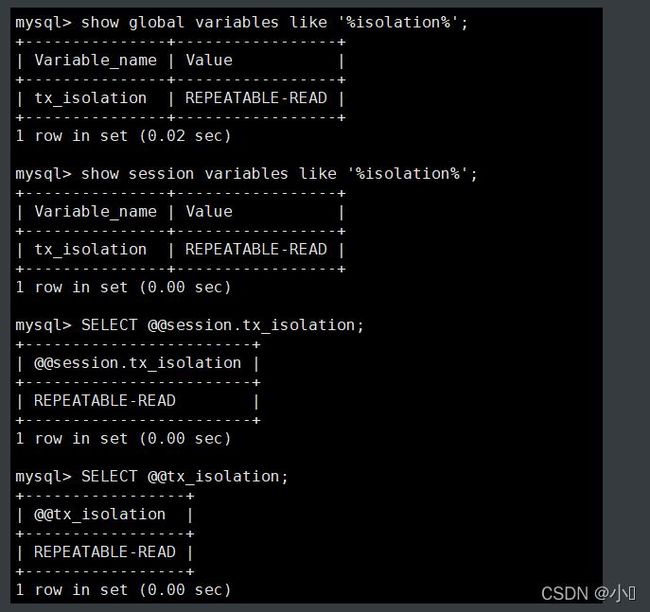
2、查询会话事务隔离级别
show session variables like '%isolation%'; SELECT @@session.tx_isolation; SELECT @@tx_isolation;
3、设置全局事务隔离级别
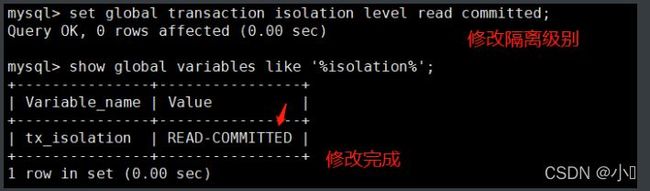
set global transaction isolation level read committed; show global variables like '%isolation%';
4、设置会话事务隔离级别
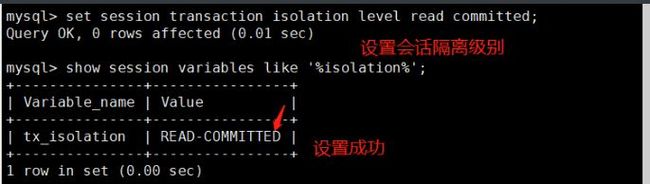
set session transaction isolation level read committed; show session variables like '%isolation%';
三、事务控制语句
1、相关语句
begin; 开启事务
commit; 提交事务,使已对数据库进行的所有修改变为永久性的
rollback; 回滚事务,撤销正在进行的所有未提交的修改
savepoint s1; 建立回滚点,s1为回滚点名称,一个事务中可以有多个
rollback to s1; 回滚到s1回滚点
2、案例
①、创建表
create database school;
use school;
create table Fmoney(
id int(10) primary key not null,
name varchar(20),
money decimal(5,2));
insert into Fmoney values ('1','srs1','100');
insert into Fmoney values ('2','srs2','200');
select * from Fmoney;

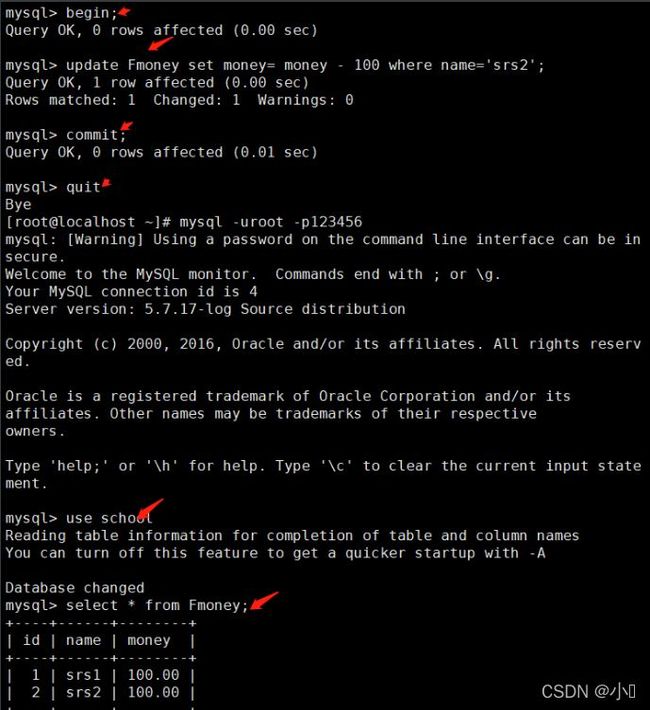
②、测试提交事务
begin; update Fmoney set money= money - 100 where name='srs2'; commit; quit mysql -u root -p use school; select * from Fmoney;
③、测试回滚事务
begin; update Fmoney set money= money + 100 where name='srs2'; select * from Fmoney; rollback; select * from Fmoney;

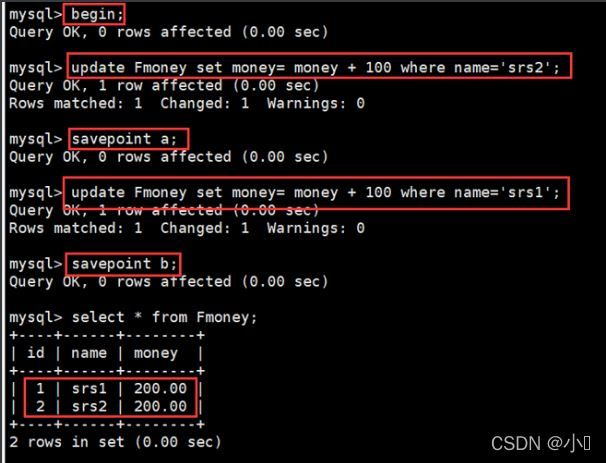
④、测试多点回滚
begin;
update Fmoney set money= money + 100 where name='srs2';
select * from Fmoney;
savepoint a;
update Fmoney set money= money + 100 where name='srs1';
select * from Fmoney;
savepoint b;
insert into Fmoney values ('3','srs3','300');
select * from Fmoney;
rollback to b;
select * from Fmoney;

3、使用 set 设置控制事务
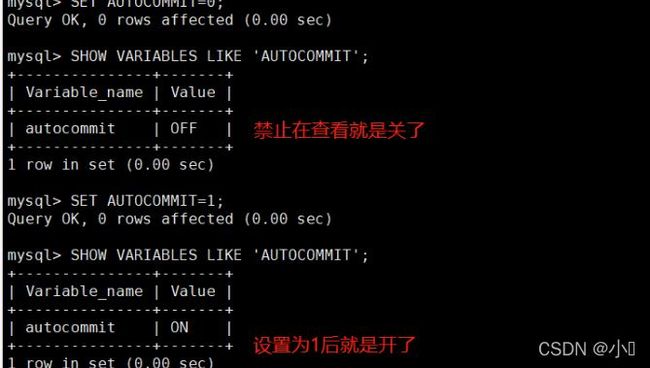
SET AUTOCOMMIT=0; #禁止自动提交 SET AUTOCOMMIT=1; #开启自动提交,Mysql默认为1 SHOW VARIABLES LIKE 'AUTOCOMMIT'; #查看Mysql中的AUTOCOMMIT值
如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback|commit;当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin; commit|rollback; 都是独立的事务。
四、MySQL 存储引擎
1、存储引擎概念介绍
(1)MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平,并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎。
(2)存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式
(3)MySQL 常用的存储引擎有: a、MylSAM b、InnoDB
(4)MySQL数据库中的组件,负责执行实际的数据I/O操作
(5)MySQL系统中,存储引擎处于文件系统之.上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储。
2、查看系统支持的存储引擎
show engines;

3、查看表使用的存储引擎
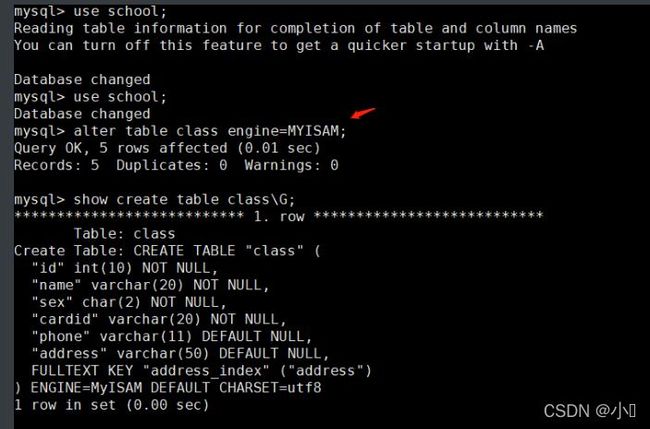
(1)方法一:直接查看 show table status from 库名 where name='表名'\G; 例: show table status from school where name='class'\G; (2)方法二:进入数据库查看 use 库名; show create table 表名\G; 例: use school; show create table class\G;

4、修改存储引擎
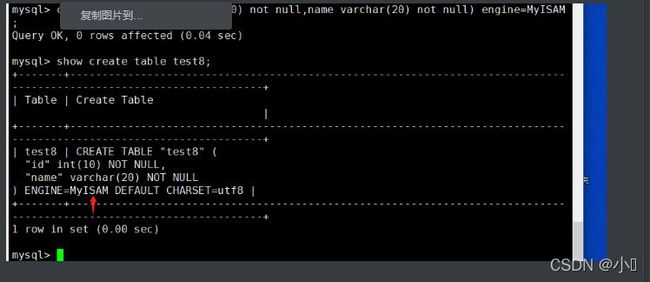
(1) 方法一:通过 alter table 修改 use 库名; alter table 表名 engine=MyISAM; 例: use school; alter table class engine=MYISAM; (2)方法二:通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务 注意:此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更。 vim /etc/my.cnf ...... [mysqld] ...... default-storage-engine=INNODB systemctl restart mysql.service (3)方法三:通过 create table 创建表时指定存储引擎 use 库名; create table 表名(字段1 数据类型,...) engine=MyISAM; 例: mysql -u root -p use school; create table test7(id int(10) not null,name varchar(20) not null) engine=MyISAM;

到此这篇关于深入理解mysql事务与存储引擎的文章就介绍到这了,更多相关mysql事务与存储引擎内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!