【Pytorch神经网络理论篇】 35 GaitSet模型:步态识别思路+水平金字塔池化+三元损失
1 步态识别思路
1.1 步态识别的本质
步态特征的距离匹配,对人在多拍摄角度、多行走条件下进行特征提取,得到基于个体的步态特征,再用该特征与其他个体进行比较,从而识别出该个体的具体身份。

1.2 步态识别的主体思路
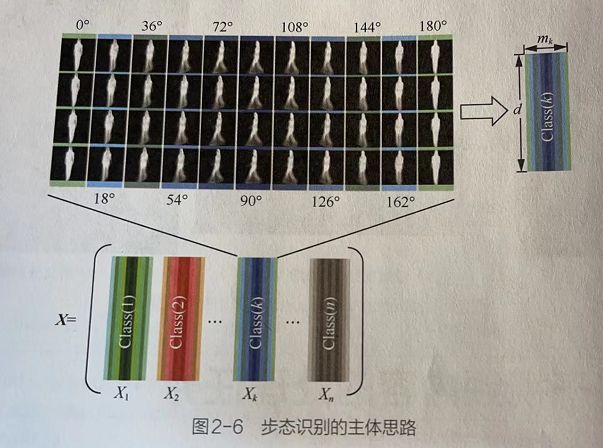
1.2.1 神经网络的角度看待步态识别的数据集
在步态识别中,需要将一组图片作为一个样本。
从神经网络的角度来看,步态识别的组图片也只是在代表图片[H,W,C]的基础之上,多出一个张数的维度而已。
1.2.2 步态识别模型的数据处理的三种方式
整体处理:将输入数据当作一个完整的3D图片数据,来计算输入数据在三维空间里所表现的整体特征。如对整体的输入数据做3D卷积。
分散处理:将输入数据当作由多张图片组成的序列数据,先对单张图片进行特征处理,再对序列数据特征进行处理。在分散处理的过程中,又可以分为重视序列顺序关系(如基于惯性的步态识别)和不重视序列顺序关系两种做法。
混合处理:先对单张图片进行基于人形特征的预处理(如提取人形轮廓数据、人的姿态数据),再将预处理后的数据当作原始输入,进行二次处理(可以使用整体处理或分散处理)。混合处理模式更为细致,也更为灵活。
1.2 CASIA-B数据集
CASIA-B是使用最广泛的步态数据集, 包含124人的RGB和轮廓形式的多视角步态数据。从11个不同的视角进行采集,范围从0到180度,增量为18度。该数据集考虑了三种不同的行走条件,即正常行走(NM)、穿外套行走(CL)和携包行走(BG),每个人每个视角分别有6、2和2个步态序列。
CASIA-B最常用的测试协议是受试者无关协议,该协议使用前74名受试者的数据进行训练,其余50名受试者进行测试。然后将测试数据拆分为一个注册集,其中包括NM步态数据中的前四个步态序列,验证集由其余序列组成,即每个受试者每个视角的剩余2个NM、2个CL和2个BG序列,结果主要针对所有视角报告。
2 GaitSet模型
GaitSet模型属于混合处理方式,该模型的二次处理部分使用了分散处理。
2.1 预处理
GaitSet模型的预处理部分,需要对视频中抽离的图片进行基于人物识别的语义分割,得到基于人形的黑白轮廓图,如图所示。
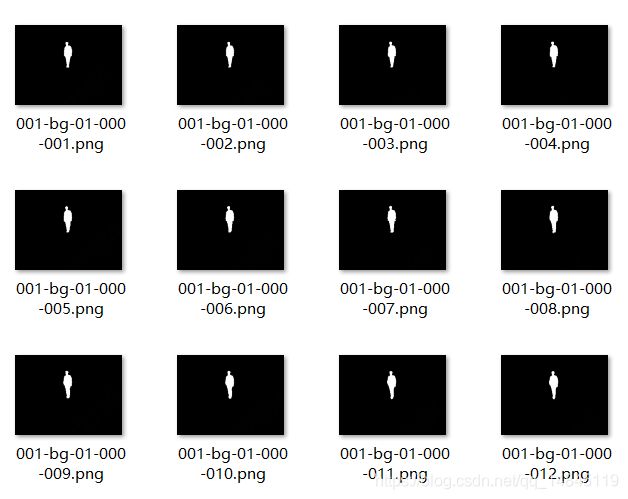
2.1.1 轮廓图的优点
通过将轮廓图看作单通道图片,实现基于人的多帧图片被当作多通道图片进行处理,即其形状可以描述为[批次个数,帧数,高度,宽度] 与RGB状为[批次个数,通道数,高度,宽度]相似。
2.2 特征处理
2.2.1 GitSet模型分散处理
GitSet模型采用分散处理,对每一张图片计算特征,再对多个特征做聚合处理。
2.2.2 GitSet模型分散处理的核心部分
①多层全流程管线(Multlayer Global Pipeline,MGP)是一个类似FPN结构的网络模型,通过两个分支进行下采样处理,并在每次下采样之后进行特征融合。
②水平金字塔池化(HorizontalPyramid Matching,HPM)按照不同的水平尺度对特征数据进行池化,并将池化结果汇集起来,从而丰富数据的鉴别特征。
2.2.3 GitSet模型分散处理的训练
在训练时,将模型计算出的特征用三元损失(Triplet Loss)进行优化,使其计算出的特征与同类别特征距离更近,与非同类别特征距离更远。
在使用时,具体步骤如下。
(1)对人物视频进行抽帧采样。
(2)对采样数据进行处理,生成轮廓图。
(3)将多张轮廓图输入模型得到特征。
(4)将该特征与数据库中已有的特征进行比较,找到与其距离最近的特征,从而识别出人物身份。
3 完整GitSet模型流程图
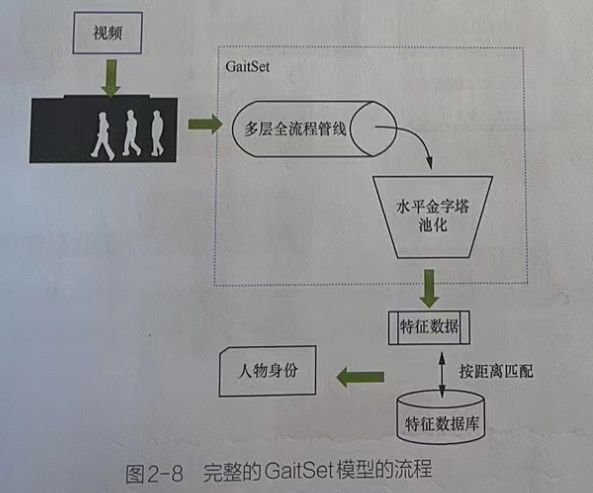
4 多层全流程管线
主要分为两个分支:一个是主分支,另一个是辅助分支。
4.1 主分支
主分支用于对从视频分离出来的多帧数据,基于全部图片的特征进行处理。
采用两次卷积+一次下采样的操作进行特征计算与降维处理。
4.2 辅助分支
辅助分支用于对从视频分离出来的多帧数据,某于帧的特征进行处理。
辅助分支与主分支的处理同步,并对每次下采样后的数据讲行特征提取,将提取后的帧特征融合到主分支的特征处理结果里。
4.3 多层全流程管线处理流程图
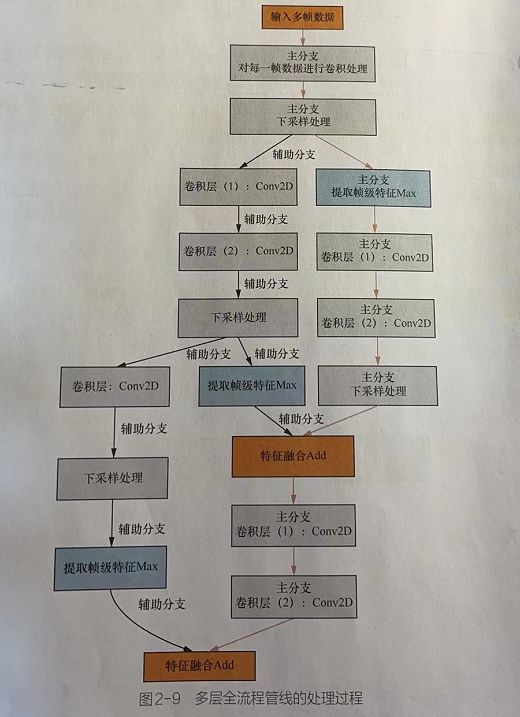
(1)在主分支中,对每一帧数据进行卷积外理。
(2)在主分支中,对卷积处理的结果进行下采样处理。
(3)将下采样结果分为两份,一份用于主分支,另一份用干辅助分支。
(4)在主分支中,对下采样结果进行基于帖特征的提取。
(5)在主分支中,对第(4)步的结果做卷积损作。
(6)在辅助分支中,继续对下采样结果做卷积操作。
(7)在辅助分支的卷积操作之后,进行一次下采样,并对下采样结果讲行基于特征的提取。
(8)在主分支中,也同步做一次下采样。
(9)将第(6)和(7)步的结果融合起来。
(10)继续重复第(5)~(9)步的步骤。重复次数与网络规模和输入尺寸右关其中第(4) 和(7) 步基于帧的特征提取部分使用了多特征集合池化(Set Pool in a)方法。经过测试发现直接使用取最天值池化的方法效果更好,而且该方法更为简单。
第(9) 步融合特征的方式使用的是直接相加, 也可以用cat函数将其拼接在一起, 在本例中,使用的是简单相加。
卷积神经网络的不同层能够识别不同的特征,通过深层卷积的组合,可以增大模型在图片中的理解区域。同时在主管道中,融合了从不同层提取的帧级特征,使得模型计算的特征中含有更丰富的整体特征。
5 水平金字塔池化
水平金字塔池化是来自行人再识别(Person Re-l dentification) 任务中的一种技术。它充分地利用了行人的不同局部空间信息,使得在重要部件丢失的情况下,仍能正确识别出候选行人, 增强了行人识别的健壮性(参见arXiv网站上编号为“1811.06186”的论文)。
5.1 行人再识别任务
行人再识别任务是从图片或者视频序列中找到特定行人的任务。
该任务属于图像检索任务中的一种,常常与行人检测、行人跟踪任务一起被应用在智能视频监控、智能安保等领域。
5.2 HPM模型的做法和原理
5.2.1 HPM模型的做法
将图片按照不同的水平尺度分成多个部分, 然后将每个部分的全局平均池化和全局最大池化特征融合到一起。
5.2.2 HPM模型的结构
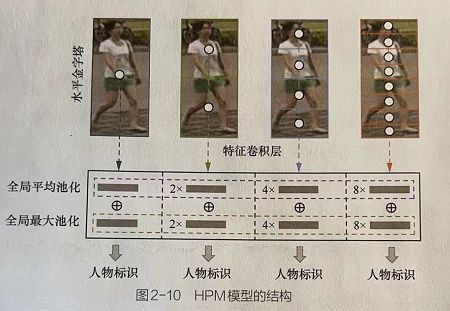
这种做法相当于引入了多尺度的局部信息互助作用来缓解不对齐引起的离群值问题。其中每个局部的信息通过全局平均池化与全局最大池化策略结合得到的融合特征更具有判别能力。
全局平均池化:可以感知空间条的全局信息,并将背景上下文考虑进去。
全局最大池化:实现提取最具判别性的信息并忽略无关信息(如背景、衣服等)。
5.2.3 HPM模型在步态识别实例的作用
使用HPM模型作为整个网络的最后部分, 对全连接层的特征进行优化,提升了特征的整体鉴别性。
6 三元损失
三元损失是根据3张图片组成的三元组计算而得的损失 ,常用于基于样本特征进行匹配的模型中,如人脸识别、步态识别、行人再识别等任务的模型中。
6.1 三元损失算法图解
在每次提取特征时,同步输入与该样本相同类别和不同类别的两个样本。利用监督学习使该样本特征与相同类别的样本特征间的差异越来越小,与不同类别的样本特征间的差异越来越大。
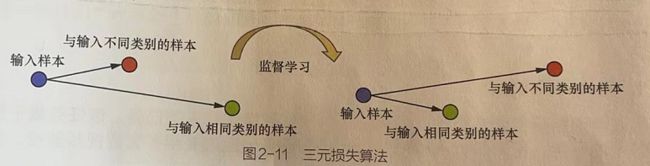
如上图所示,通过监督学习,可以让输入样本经过网络计算之后的特征与相同类别的样本特征距离更近,与不同类别的样本特征距离更远。
三元损失训练的模型,最终将使相同类别的特征会更加相似,解决样本特征指向不明确的问题。
6.2 三元损失的使用
在使用三元损失时,常会直接将一批次的输入数据进行内部两两交叉,并从中分出正向样本(类内距离)和负向样本(类间距离)。这种方式可以保证与其他损失计算的接口统一,而又不需要额处开发选取正/负样本的功能。
6.2.1 三元损失中的间隔margin

6.2.2 三元损失的模式hard与full
full模式(默认): 对所有的正向样本和负向样本进行损失值的计算。
hard模式:只对最小的正向样本和最大的负向样本进行损失值的计算, 目的在于优化特征并使其指向偏离最大的样本,运算量会更小。