OCR文字识别技术总结(五)
导读:在上一篇文章中我们对文字识别算法理论部分进行详细总结,本篇将继续介绍文字识别CRNN网络实战部分,下面将从CRNN实践代码出发,进一步说明文字识别实战流程,具体分为算法介绍、代码解读、项目实战等几个部分。
本系列目录:
1️⃣OCR系列第一章:OCR文字识别技术总结(一)
2️⃣OCR系列第二章:OCR文字识别技术总结(二)
3️⃣OCR系列第三章:OCR文字识别技术总结(三)
4️⃣OCR系列第四章:OCR文字识别技术总结(四)
5️⃣OCR系列第五章:OCR文字识别技术总结(五)
文本识别实战
一、CRNN网络介绍
✨CRNN论文链接:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
✨CRNN学习博客参考:CRNN文本识别网络详解
CRNN是最早一批采用CNN与RNN结合的方式进行自然场景图片识别的基于深度学习的算法。文中提出的CRNN算法是一种能将特征提取、序列建模和转录整合到统一框架中的新型神经网络架
构。与之前的场景文本识别系统相比,该架构表现出几个不同的特点:
1)与之前的通过部分到整体的算法相比,可以进行端到端的训练,而 不是各个部分单独训练(字的特征部分与标签预测部分等分别进行训练);
2)借用了在自然语言处理模型中序列标注(Sequence Labeling) 任务的思想,将序列标注算法嵌套在现有的深度卷积网络中,组成完整的支持端到端梯度反向传播的算法;
3)在论文设计的实验中,该算法 在IIIT5K、SVT以及ICDAR系列的标准数据集中取得了优于现有算法的结果。
CRNN使用CNN提取图像特征,RNN进行序列推理,配合CTC的不定长字符识别,是文本和语音识别的一个重要模型。
首先,从图中看出模型包括三个部分,分别为卷积层、循环层以及转录层。从下到上依次为:
(1)卷积层。作用是从输入图像中提取特征序列。
(2)循环层。作用是预测从卷积层获取的特征序列的标签(真实值)分布。
(3)转录层。作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。
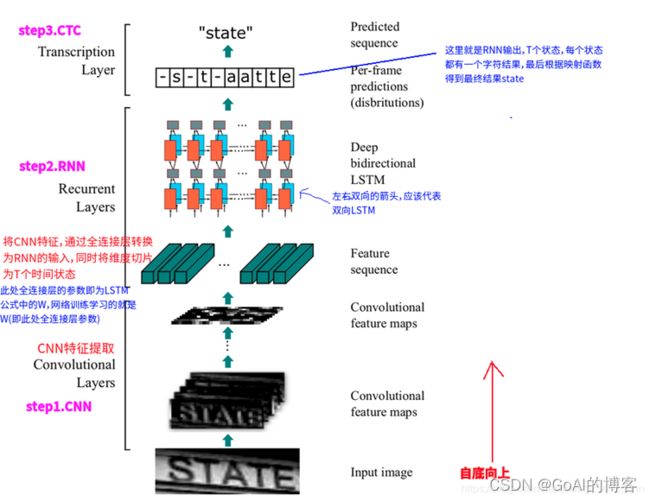
二、推理流程:
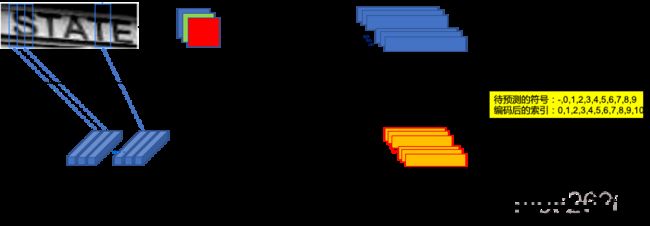
1.首先对图像进行预处理,高度必须为16的倍数(这里为32),将输入图像缩放至:32W3
2.之后利用CNN提取后图像卷积特征,得到的大小为:1 W/4 512
3.以seq_len=W/4, input_size=512送入LSTM,提取序列特征,得到:W/4*n的后验概率矩阵
4最后利用CTC,使标签和输出无需一一对应,也能进行训练。
注:RNN最后的嵌入层的输出维度为我们总共要预测的字符数+1(blank),最后的输出可以认为是一种概率,最后进行解码即可。
三、CRNN构成:
1.卷积层
① 预处理
CRNN对输入图像先做了缩放处理,把所有输入图像缩放到相同高度,默认是32,宽度可任意长。
原因:CRNN模型中的卷积层由一系列的卷积层、池化层、BN层构造而成。就像其他的CNN模型一样,它将输入的图片转化为具有特征信息的特征图,作为后面循环层的输入。首先,为了使提取的特征图尺寸相同,输入的图像要缩放到固定的大小。
由于卷积神经网络中卷积层和最大池化层的存在,使其具有平移不变性的特点。卷积神经网络中的感受野指的是经过卷积层输出的特征图中每个像素对应的原输入图像区域的大小,它与特征图上的像素从左到右,从上到下是一一对应的,如图所示。因此,可以将特征图作为图像特征的表示。
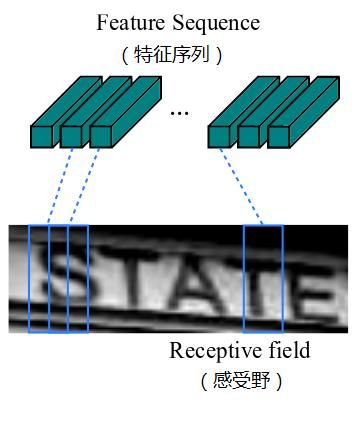
② 卷积运算
CRNN的卷积层具体的网络结构如图所示,它是在VGG网络的基础上改造而成。卷积层对于VGG主要对两个地方进行了改动:
- 将第2层和第3层的MaxPooling的卷积核的大小从 改成了 。
- 第5层和第6层的卷积层后面都添加了一个BN(BatchNormalization)层。因为BN层可以对输入数据进行归一化,加速网络的收敛速度。
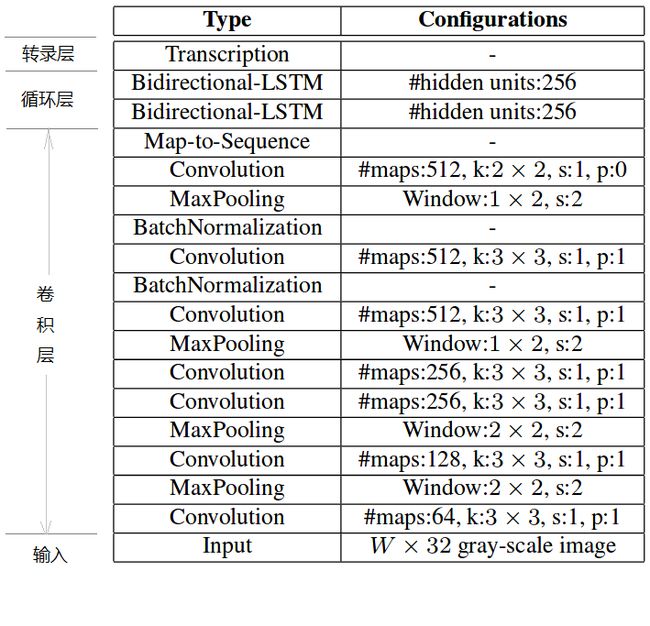
CRNN共包含7层卷积层,2层双向LSTM,输入的图像为灰度图。值得注意的是,网络在对特征降维的时候最大值池化采用的窗口高度固定为2,这就意味着每次池化高度都会减少一半,经过5次池化,高度缩减为1,宽度为原图长度的1/4。因此,序列的长度必须超过图片中单词的长度,这样才能够预测出完整的词语。
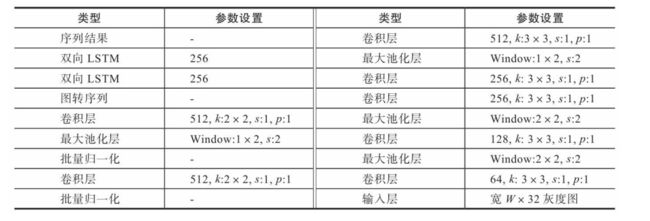
2.循环层
循环层由一个双向LSTM循环神经网络构成,预测特征序列中的每一个特征向量的标签分布。
由于LSTM需要有个时间维度,在本模型中把序列的 width 当作LSTM 的时间 time steps。
其中,“Map-to-Sequence”自定义网络层主要是做循环层误差反馈,与特征序列的转换,作为卷积层和循环层之间连接的桥梁,从而将误差从循环层反馈到卷积层。
3.转录层
转录层是将LSTM网络预测的特征序列的结果进行整合,转换为最终输出的结果。
在CRNN模型中双向LSTM网络层的最后连接上一个CTC模型,从而做到了端对端的识别。所谓CTC模型(Connectionist Temporal Classification,联接时间分类),主要用于解决输入数据与给定标签的对齐问题,可用于执行端到端的训练,输出不定长的序列结果。
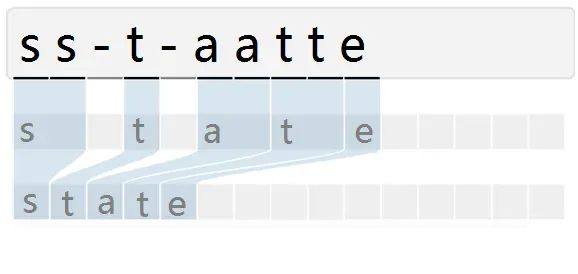
由于输入的自然场景的文字图像,由于字符间隔、图像变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个词,如下图:

而引入CTC就是主要解决这个问题,通过CTC模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次),如下图所示:
四、CRNN代码讲解
CRNN DEMO代码:
注:项目模型参数一般都存储在config文件下,可以按需修改。
(1)数据预处理及制作:
主要是对于labletxt的处理,定义strLabelConverter类,将两者进行转换,encode是将str转化为lable;decod将lable转化为str,decode中用到了ctc中的对应规则。
class strLabelConverter(object):
"""Convert between str and label.
NOTE:
Insert `blank` to the alphabet for CTC.
Args:
alphabet (str): set of the possible characters.
ignore_case (bool, default=True): whether or not to ignore all of the case.
"""
def __init__(self, alphabet, ignore_case=False):
self._ignore_case = ignore_case
if self._ignore_case:
alphabet = alphabet.lower()
self.alphabet = alphabet + '-' # for `-1` index
self.dict = {}
for i, char in enumerate(alphabet):
# NOTE: 0 is reserved for 'blank' required by wrap_ctc
self.dict[char] = i + 1
def encode(self, text):
"""Support batch or single str.
Args:
text (str or list of str): texts to convert.
Returns:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
"""
length = []
result = []
decode_flag = True if type(text[0])==bytes else False
for item in text:
if decode_flag:
item = item.decode('utf-8','strict')
length.append(len(item))
for char in item:
index = self.dict[char]
result.append(index)
text = result
return (torch.IntTensor(text), torch.IntTensor(length))
def decode(self, t, length, raw=False):
"""Decode encoded texts back into strs.
Args:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
Raises:
AssertionError: when the texts and its length does not match.
Returns:
text (str or list of str): texts to convert.
"""
if length.numel() == 1:
length = length[0]
assert t.numel() == length, "text with length: {} does not match declared length: {}".format(t.numel(), length)
if raw:
# ''.join将序列中的元素以指定的字符连接生成一个新的字符串。
return ''.join([self.alphabet[i - 1] for i in t])
else:
char_list = []
for i in range(length):
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i] - 1])
return ''.join(char_list)
else:
# batch mode
assert t.numel() == length.sum(), "texts with length: {} does not match declared length: {}".format(t.numel(), length.sum())
texts = []
index = 0
for i in range(length.numel()):
l = length[i]
texts.append(
self.decode(
t[index:index + l], torch.IntTensor([l]), raw=raw))
index += l
return texts
(2)模型代码解析
CRNN模型解析:首先是定义rnn的类,输入为输出,隐层和输出的特征维数,由一个BiLSTM和一个全连接层组成,方便下一步直接调用。
RNN部分
class BidirectionalLSTM(nn.Module):
# Inputs hidden units Out
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
#seq_len, batch, hidden_size * num_directions
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
RNN部分使用了双向LSTM,隐藏层单元数为256,CRNN采用了两层BiLSTM来组成这个RNN层,RNN层的输出维度将是(s,b,class_num) ,其中class_num为文字类别总数。
下面为参考文章具体解释模型代码,注意代码与上面有出入,但思路是一样的!
http://www.javashuo.com/article/p-bxzirubp-kz.html
值得注意的是:Pytorch里的LSTM单元接受的输入都必须是3维的张量(Tensors).每一维表明的意思不能弄错。第一维体现的是序列(sequence)结构,第二维度体现的是小块(mini-batch)结构,第三位体现的是输入的元素(elements of input)。若是在应用中不适用小块结构,那么能够将输入的张量中该维度设为1,但必需要体现出这个维度。
LSTM的输入
input of shape (seq_len, batch, input_size): tensor containing thefeatures of the input sequence. The input can also be a packed variable length sequence.
input shape(a,b,c)
a:seq_len -> 序列长度
b:batch
c:input_size 输入特征数目
根据LSTM的输入要求,咱们要对CNN的输出作些调整,即把CNN层的输出调整为[seq_len, batch, input_size]形式,下面为具体操做:先使用squeeze函数移除h维度,再使用permute函数调整各维顺序,即从原来[w, b, c]的调整为[seq_len, batch, input_size],具体尺寸为[16,batch,512],调整好以后便可以将该矩阵送入RNN层。
x = self.cnn(x)
b, c, h, w = x.size()
# print(x.size()): b,c,h,w
assert h == 1 # "the height of conv must be 1"
x = x.squeeze(2) # remove h dimension, b *512 * width
x = x.permute(2, 0, 1) # [w, b, c] = [seq_len, batch, input_size]
x = self.rnn(x)
RNN层输出格式以下,由于咱们采用的是双向BiLSTM,因此输出维度将是hidden_unit * 2
Outputs: output, (h_n, c_n)
output of shape (seq_len, batch,num_directions * hidden_size)
h_n of shape (num_layers *num_directions, batch, hidden_size)
c_n (num_layers * num_directions,batch, hidden_size)
而后咱们再经过线性变换操做self.embedding1 = torch.nn.Linear(hidden_unit * 2, 512)是的输出维度再次变为512,继续送入第二个LSTM层。第二个LSTM层后继续接线性操做torch.nn.Linear(hidden_unit * 2, class_num)使得整个RNN层的输出为文字类别总数。
定义整体模型的类:
输入分别为图片的高,config里为32;输入的channel,这里为1;rnn输出特征的维数,就是字母表的大小。作者写了一个convRelu的函数,当i等于0时输入通道为送入图片的通道数,否则为上一层的输出通道数,每层的输出通道在nm中,卷积核大小为3,步长为1,padding为1,使用relu为激活函数。
最终的cnn模型与VGG16基本相同,rnn模型为两个bilstm级联。从cnn得到的特征,以width为seq,batch不变,channel为输入特征维度,来送入rnn,输出为[seq_len, batch, nh]的概率矩阵
class CRNN(nn.Module):
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
ks = [3, 3, 3, 3, 3, 3, 2]
ps = [1, 1, 1, 1, 1, 1, 0]
ss = [1, 1, 1, 1, 1, 1, 1]
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
#i==0成立则nIn = nc,否则nIn = nm[i - 1]
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
convRelu(0)
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x64
convRelu(1)
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x32
convRelu(2, True)
convRelu(3)
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
convRelu(6, True) # 512x1x16
self.cnn = cnn
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
def forward(self, input):
# conv features
conv = self.cnn(input)
b, c, h, w = conv.size()
print(conv.size())
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2) # b *512 * width
conv = conv.permute(2, 0, 1) # [w, b, c]
output = F.log_softmax(self.rnn(conv), dim=2)
return output
参数权重初始化和类的实例化:
def weights_init(m):
#get class name
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
def get_crnn(config):
model = CRNN(config.MODEL.IMAGE_SIZE.H, 1, config.MODEL.NUM_CLASSES + 1, config.MODEL.NUM_HIDDEN)
model.apply(weights_init)
return model
(3)Train
首先定义了一个读取config的函数:argparse是用来从命令行传入参数的,其用法可以参考:https://zhuanlan.zhihu.com/p/56922793
def parse_arg():
parser = argparse.ArgumentParser(description="train crnn")
parser.add_argument('--cfg', help='experiment configuration filename', required=True, type=str)
args = parser.parse_args()
with open(args.cfg, 'r') as f:
# config = yaml.load(f, Loader=yaml.FullLoader)
config = yaml.load(f)
config = edict(config)
config.DATASET.ALPHABETS = alphabets.alphabet
config.MODEL.NUM_CLASSES = len(config.DATASET.ALPHABETS)
return config
创建日志文件:
# create output folder
output_dict = utils.create_log_folder(config, phase='train')
# cudnn
cudnn.benchmark = config.CUDNN.BENCHMARK
cudnn.deterministic = config.CUDNN.DETERMINISTIC
cudnn.enabled = config.CUDNN.ENABLED
# writer dict
writer_dict = {
'writer': SummaryWriter(log_dir=output_dict['tb_dir']),
'train_global_steps': 0,
'valid_global_steps': 0,
}
其他工作:包括模型,损失函数和优化器
1.模型运行在gpu上;
2.损失函数是Pytorch自带的ctc函数。
model = crnn.get_crnn(config)
# get device
if torch.cuda.is_available():
device = torch.device("cuda:{}".format(config.GPUID))
else:
device = torch.device("cpu:0")
model = model.to(device)
# define loss function
criterion = torch.nn.CTCLoss()
3.优化器的初始化
关于优化器的知识可以参考:https://blog.csdn.net/weixin_40170902/article/details/80092628
优化器config里设置为adam,并且利用torch.optim.lr_scheduler来调整学习率,在指定epoch后将lr降低指定倍数,可以参考:https://blog.csdn.net/qyhaill/article/details/103043637
optimizer = utils.get_optimizer(config, model)
if isinstance(config.TRAIN.LR_STEP, list):
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(
optimizer, config.TRAIN.LR_STEP,
config.TRAIN.LR_FACTOR, last_epoch-1
)
else:
lr_scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, config.TRAIN.LR_STEP,
config.TRAIN.LR_FACTOR, last_epoch - 1
)
之后是finetune和resume的选择,以及与训练模型的载入。
fintune讲解:https://zhuanlan.zhihu.com/p/35890660,这里的fintune冻结了cnn,其参数不更新。
if config.TRAIN.FINETUNE.IS_FINETUNE:
model_state_file = config.TRAIN.FINETUNE.FINETUNE_CHECKPOINIT
if model_state_file == '':
print(" => no checkpoint found")
checkpoint = torch.load(model_state_file, map_location='cpu')
if 'state_dict' in checkpoint.keys():
checkpoint = checkpoint['state_dict']
from collections import OrderedDict
model_dict = OrderedDict()
for k, v in checkpoint.items():
if 'cnn' in k:
model_dict[k[4:]] = v
model.cnn.load_state_dict(model_dict)
if config.TRAIN.FINETUNE.FREEZE:
for p in model.cnn.parameters():
p.requires_grad = False
elif config.TRAIN.RESUME.IS_RESUME:
model_state_file = config.TRAIN.RESUME.FILE
if model_state_file == '':
print(" => no checkpoint found")
checkpoint = torch.load(model_state_file, map_location='cpu')
if 'state_dict' in checkpoint.keys():
model.load_state_dict(checkpoint['state_dict'])
last_epoch = checkpoint['epoch']
# optimizer.load_state_dict(checkpoint['optimizer'])
# lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
else:
model.load_state_dict(checkpoint)
之后用写了一个函数用来打印模型参数,这部分也放在后边讲model_info(model)
下面为载入训练集和测试集:参数均从config文件中进行读取,关于数据集之后会更进一步分析。
train_dataset = get_dataset(config)(config, is_train=True)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=config.TRAIN.BATCH_SIZE_PER_GPU,
shuffle=config.TRAIN.SHUFFLE,
num_workers=config.WORKERS,
pin_memory=config.PIN_MEMORY,
)
val_dataset = get_dataset(config)(config, is_train=False)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=config.TEST.BATCH_SIZE_PER_GPU,
shuffle=config.TEST.SHUFFLE,
num_workers=config.WORKERS,
pin_memory=config.PIN_MEMORY,
)
训练部分.
utils.strLabelConverter是ctc部分,是将数据集中lable和字符lable的相互转化,解析之后有两个重要函数function.train和function.validate,分别用来训练和测试最后保存模型,这里只保存模型的参数。
converter = utils.strLabelConverter(config.DATASET.ALPHABETS)
for epoch in range(last_epoch, config.TRAIN.END_EPOCH):
function.train(config, train_loader, train_dataset, converter, model, criterion, optimizer, device, epoch, writer_dict, output_dict)
lr_scheduler.step()
acc = function.validate(config, val_loader, val_dataset, converter, model, criterion, device, epoch, writer_dict, output_dict)
is_best = acc > best_acc
best_acc = max(acc, best_acc)
print("is best:", is_best)
print("best acc is:", best_acc)
# save checkpoint
torch.save(
{
"state_dict": model.state_dict(),
"epoch": epoch + 1,
# "optimizer": optimizer.state_dict(),
# "lr_scheduler": lr_scheduler.state_dict(),
"best_acc": best_acc,
}, os.path.join(output_dict['chs_dir'], "checkpoint_{}_acc_{:.4f}.pth".format(epoch, acc))
)
下面来解析function.train:
enumerate()用于将可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,inp指输入图片,idx指其标签。
这个函数主要分为计算时间,计算inferernce也就是模型输出,计算loss以及更新参数。
值得注意的是在计算ctcloss时要先计算inferernce的长度(batch*seq)和label的长度(一个batch总的lable长度)
def train(config, train_loader, dataset, converter, model, criterion, optimizer, device, epoch, writer_dict=None, output_dict=None):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
model.train()
end = time.time()
for i, (inp, idx) in enumerate(train_loader):
# measure data time
data_time.update(time.time() - end)
labels = utils.get_batch_label(dataset, idx)
inp = inp.to(device)
# inference
preds = model(inp).cpu()
# compute loss
batch_size = inp.size(0)
text, length = converter.encode(labels) # length = 一个batch中的总字符长度, text = 一个batch中的字符所对应的下标
preds_size = torch.IntTensor([preds.size(0)] * batch_size) # timestep * batchsize
loss = criterion(preds, text, preds_size, length)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.update(loss.item(), inp.size(0))
batch_time.update(time.time()-end)
if i % config.PRINT_FREQ == 0:
msg = 'Epoch: [{0}][{1}/{2}]\t' \
'Time {batch_time.val:.3f}s ({batch_time.avg:.3f}s)\t' \
'Speed {speed:.1f} samples/s\t' \
'Data {data_time.val:.3f}s ({data_time.avg:.3f}s)\t' \
'Loss {loss.val:.5f} ({loss.avg:.5f})\t'.format(
epoch, i, len(train_loader), batch_time=batch_time,
speed=inp.size(0)/batch_time.val,
data_time=data_time, loss=losses)
print(msg)
if writer_dict:
writer = writer_dict['writer']
global_steps = writer_dict['train_global_steps']
writer.add_scalar('train_loss', losses.avg, global_steps)
writer_dict['train_global_steps'] = global_steps + 1
end = time.time()
五、CRNN验证码识别实战
使用的数据集介绍:
本次研究文本识别应用的数据采用开源验证码数据集,共10000张验证码图片,其中训练集8000张,测试集2000张,验证码数据集由随机阿拉伯数字“0-9”与英文字母组成,位数随机。数据集展示如图所示。

实战代码及数据集链接后续补充!
1.模型训练
在模型训练阶段,本文利用深度学习Pytorch框架中的nn模块及自带CTC损失函数进行网络搭建,针对数据集进行处理后,化分好训练集与测试集,根据上述概率分布向量和相应的文本标签得到损失函数,从而训练神经网络模型。具体实验流程如图所示:

1.1训练环境
本次实验环境基于python3.7进行,具体训练环境如表所示:
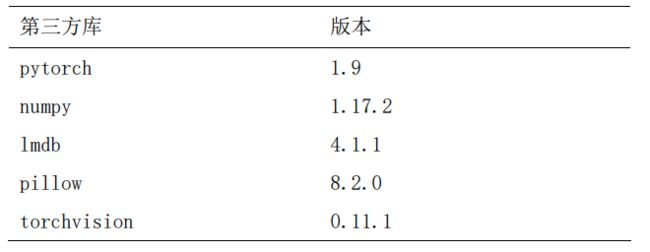
1.2训练参数
数据集文件共10000张图片,训练集为8000张图片,测试集为随机抽出的2000张图片。CRNN需要保持输入图像尺寸比例,默认输入图像高度32,宽度可根据具体情况自行调整,batchsize大小设为32,可以根据特定数据集进行更改。
设置分类词典包含数字及英文字母,优化器使用adam,初始学习率LR为0.001,LSTM隐藏层数256。使用GPU环境对数据集进行75轮训练,每25轮进行记录损失值与准确度,保存最终训练模型。
2.训练过程与结果
2.1训练过程:
在模型训练过程中,首先使用标准的CNN网络提取文本图像的特征,再利用BLSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层(CTC)进行预测得到文本序列。其具体模型训练流程为:
- 将输入图像统一缩放至32W3。
- 利用CNN提取后图像卷积特征,得到的大小为:1W/4512。
- 通过上述输入到LSTM提取序列特征,得到W/4*n后验概率矩阵。
- 利用CTC损失,实现标签和输出一一对应,进行训练。
2.2训练结果
在本次模型训练过程中,经过多次参数调整,最终经过75轮次数训练,损失值为0.0011,准确度达到近90%,模型表现良好。其最终训练结果如表2所示:
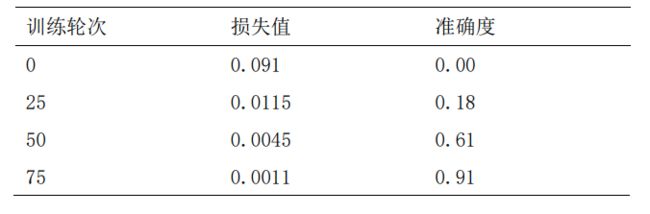
3.结论
总结:本文基于深度学习CRNN网络实现了验证码数据集识别应用,CRNN网络结合CNN+LSTM+CTC的优势,使用反向传播来进行权重调整。首先用 CNN提取图像的卷积特征,不需要手动设计特征,利用BLSTM和CTC学习到文本图像中的上下文关系,从而有效提升文本识别准确率,使得模型更加鲁棒。经过多次数据集及参数调整,经过本次实验结果表明,CRNN网络适合用于验证码数据集训练。
针对模型改进方面,利用CTC网络结构能够实现端对端的不定长识别输出的特点,数据集选择方面可以进一步选择不定长的中英文数据集或者其他语言转换进行训练与预测,另外,在CRNN模型方面后期可以进一步引入Attention注意力机制,采取Decoder与Encoder结合方法实现文本识别。
实战项目推荐:
1.基于CRNN的文本字符交易验证码识别–Paddle实战
https://blog.csdn.net/qq_36816848/article/details/123167158
2…中英文文字检测与识别项目(CTPN+CRNN+CTC):
https://mp.weixin.qq.com/s/XFrgmdEz1d9vg6U0hYr7Qw