梯度与梯度下降法
本文主要使用markdown进行编辑的。
- 概述
- 导数
- 导数与偏导数
- 导数与方向导数
- 导数与梯度
- 梯度下降
- Momentum optimization
- NAG
- AdaGrad
- RMSprop
- Adam
- 学习速率
- 代码示例
- 参考文献
概述
在讲述梯度下降算法之前,我们先需要了解一下导数(derivative)、偏导数(partial derivative)和方向导数(directional derivative),然后我们看看梯度下降法(Gradient Descent),了解为什么在优化问题中使用梯度下降法来优化目标函数。
导数
一张关于导数和微分的图:
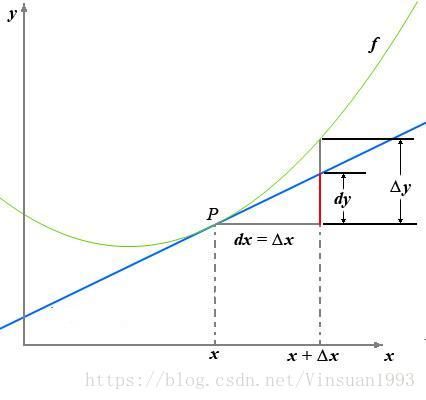
导数定义如下:
反映的是函数y=f(x)在某一点处沿x轴正方向的变化率。再强调一遍,是函数f(x)在x轴上某一点处沿着x轴正方向的变化率/变化趋势。直观地看,也就是在x轴上某一点处,如果f’(x)>0,说明f(x)的函数值在x点沿x轴正方向是趋于增加的;如果f’(x)<0,说明f(x)的函数值在x点沿x轴正方向是趋于减少的。
这里补充上图中的Δy、dy等符号的意义及关系如下:
Δx:x的变化量;
dx:x的变化量Δx趋于0时,则记作微元dx;
Δy:Δy=f(x0+Δx)-f(x0),是函数的增量;
dy:dy=f’(x0)dx,是切线的增量;
当Δx→0时,dy与Δy都是无穷小,dy是Δy的主部,即Δy=dy+o(Δx).
导数与偏导数
偏导数的定义如下:
可以看到,导数与偏导数本质是一致的,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。直观地说,偏导数也就是函数在某一点上沿坐标轴正方向的的变化率。
区别在于:
导数,指的是一元函数中,函数y=f(x)在某一点处沿x轴正方向的变化率;
偏导数,指的是多元函数中,函数 y=f(x1,x2,...,xn) y = f ( x 1 , x 2 , . . . , x n ) 在某一点处沿某一坐标轴 (x1,x2,...,xn) ( x 1 , x 2 , . . . , x n ) 正方向的变化率。
导数与方向导数
方向导数的定义如下:
在前面导数和偏导数的定义中,均是沿坐标轴正方向讨论函数的变化率。那么当我们讨论函数沿任意方向的变化率时,也就引出了方向导数的定义,即:某一点在某一趋近方向上的导数值。
通俗的解释是:
我们不仅要知道函数在坐标轴正方向上的变化率(即偏导数),而且还要设法求得函数在其他特定方向上的变化率。而方向导数就是函数在其他特定方向上的变化率。
导数与梯度
梯度的定义如下:
梯度的提出只为回答一个问题:
函数在变量空间的某一点处,沿着哪一个方向有最大的变化率?
梯度定义如下:
函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
这里注意三点:
1)梯度是一个向量,即有方向有大小;
2)梯度的方向是最大方向导数的方向;
3)梯度的值(这里指的是模,值有点歧义)是某方向上最大方向导数(的值,导数本身就是值)
补充:
现在,我们可以来换一个角度看这个问题:从某点出发,沿着所有的路径我们往下滑,当都在 Z 方向上下降了同样的高度(比如 1),最陡的那条路径,在 X-Y 平面上的投影一定是最短的。(不然为甚叫做最陡?)
梯度下降
梯度下降算法(Gradient Descent)是神经网络模型训练最常用的优化算法。
梯度下降算法背后的原理:目标函数 J(θ) J ( θ ) 关于参数 θ θ 的梯度将是目标函数上升最快的方向。对于最小化优化问题,只需要将参数沿着梯度相反的方向前进一个步长,就可以实现目标函数的下降。即给定一个与参数 θ θ 有关的目标函数 J(θ) J ( θ ) , 求使得 J 最小的参数 θ θ .我们把这个步长又称为学习速率 η η 。参数更新公式如下:
其中 ∇θJ(θ) ∇ θ J ( θ ) 是参数的梯度,根据计算目标函数 J(θ) J ( θ ) 采用数据量的不同,梯度下降算法又可以分为批量梯度下降算法(Batch Gradient Descent),随机梯度下降算法(Stochastic GradientDescent)和小批量梯度下降算法(Mini-batch Gradient Descent)。对于批量梯度下降算法,其 J(θ) J ( θ ) 是在整个训练集上计算的,如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。随机梯度下降算法是另外一个极端, J(θ) J ( θ ) 是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。小批量梯度下降算法是折中方案,选取训练集中一个小批量样本计算 J(θ) J ( θ ) ,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
Momentum optimization
冲量梯度下降算法是BorisPolyak在1964年提出的,其基于这样一个物理事实:将一个小球从山顶滚下,其初始速率很慢,但在加速度作用下速率很快增加,并最终由于阻力的存在达到一个稳定速率。对于冲量梯度下降算法,其更新方程如下:
可以看到,参数更新时不仅考虑当前梯度值,而且加上了一个积累项(冲量),但多了一个超参 γ γ ,一般取接近1的值如0.9。相比原始梯度下降算法,冲量梯度下降算法有助于加速收敛。当梯度与冲量方向一致时,冲量项会增加,而相反时,冲量项减少,因此冲量梯度下降算法可以减少训练的震荡过程。
NAG
NAG算法全称Nesterov Accelerated Gradient,是YuriiNesterov在1983年提出的对冲量梯度下降算法的改进版本,其速度更快。其变化之处在于计算“超前梯度”更新冲量项,具体公式如下:
既然参数要沿着 γ⋅m γ ⋅ m 更新,不妨计算未来位置 θ−γ⋅m θ − γ ⋅ m 的梯度,然后合并两项作为最终的更新项,其具体效果如图所示,可以看到一定的加速效果。
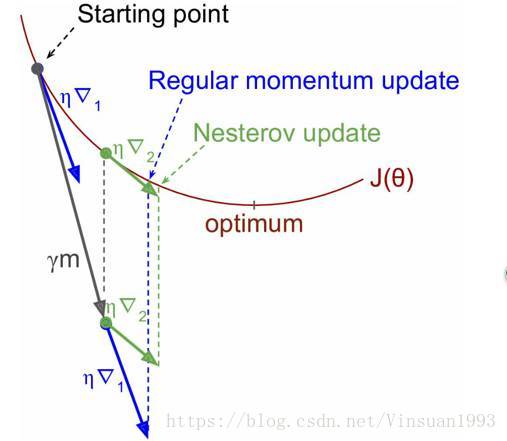
图1 NAG效果图
AdaGrad
AdaGrad是Duchi在2011年提出的一种学习速率自适应的梯度下降算法。在训练迭代过程,其学习速率是逐渐衰减的,经常更新的参数其学习速率衰减更快,这是一种自适应算法。其更新过程如下:
其中是梯度平方的积累量,在进行参数更新时,学习速率要除以这个积累量的平方根,其中加上一个很小值是为了防止除0的出现。由于是该项逐渐增加的,那么学习速率是衰减的。考虑如图所示的情况,目标函数在两个方向的坡度不一样,如果是原始的梯度下降算法,在接近坡底时收敛速度比较慢。而当采用AdaGrad,这种情况可以被改观。由于比较陡的方向梯度比较大,其学习速率将衰减得更快,这有利于参数沿着更接近坡底的方向移动,从而加速收敛。
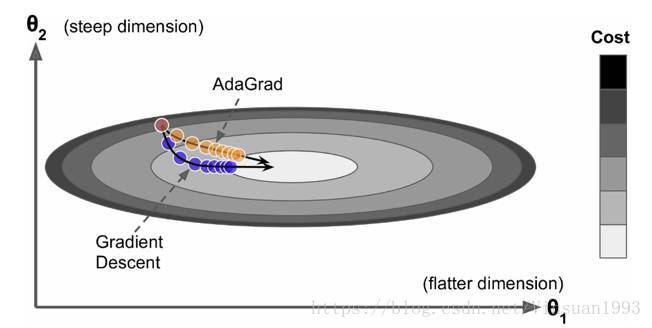
前面说到AdaGrad其学习速率实际上是不断衰减的,这会导致一个很大的问题,就是训练后期学习速率很小,导致训练过早停止,因此在实际中AdaGrad一般不会被采用,下面的算法将改进这一致命缺陷。
RMSprop
RMSprop是Hinton在他的课程上讲到的,其算是对Adagrad算法的改进,主要是解决学习速率过快衰减的问题。其实思路很简单,类似Momentum思想,引入一个超参数,在积累梯度平方项进行衰减:
可以认为仅仅对距离时间较近的梯度进行积累,其中一般取值0.9,其实这样就是一个指数衰减的均值项,减少了出现的爆炸情况,因此有助于避免学习速率很快下降的问题。同时Hinton也建议学习速率设置为0.001。RMSprop是属于一种比较好的优化算法了。
Adam
Adam全称Adaptive moment estimation,是Kingma等在2015年提出的一种新的优化算法,其结合了Momentum和RMSprop算法的思想。相比Momentum算法,其学习速率是自适应的,而相比RMSprop,其增加了冲量项。所以,Adam是两者的结合体。
学习速率
前面也说过学习速率的问题,对于梯度下降算法,这应该是一个最重要的超参数。如果学习速率设置得非常大,那么训练可能不会收敛,就直接发散了;如果设置的比较小,虽然可以收敛,但是训练时间可能无法接受;如果设置的稍微高一些,训练速度会很快,但是当接近最优点会发生震荡,甚至无法稳定。不同学习速率的选择影响可能非常大,如图3所示。
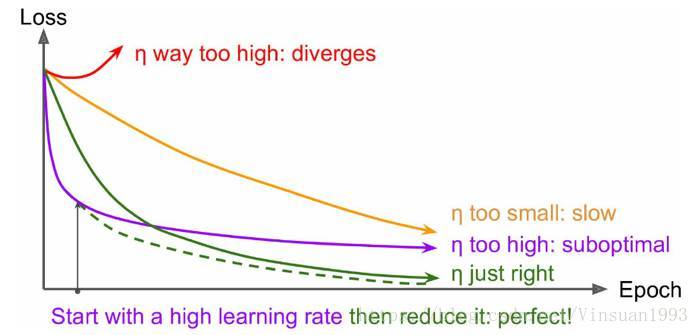
不同学习速率的训练效果
理想的学习速率是:刚开始设置较大,有很快的收敛速度,然后慢慢衰减,保证稳定到达最优点。所以,前面的很多算法都是学习速率自适应的。除此之外,还可以手动实现这样一个自适应过程,如实现学习速率指数式衰减:
代码示例
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('Agg')
%matplotlib inline
import random as random
import numpy as np
import csvx_data = [ 338., 333., 328. , 207. , 226. , 25. , 179. , 60. , 208., 606.]
y_data = [ 640. , 633. , 619. , 393. , 428. , 27. , 193. , 66. , 226. , 1591.]x = np.arange(-200,-100,1) #bias
y = np.arange(-5,5,0.1) #weight
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] - b - w*x_data[n])**2
Z[j][i] = Z[j][i]/len(x_data)# ydata = b + w * xdata
b = -120 # initial b
w = -4 # initial w
lr = 1 # learning rate
iteration = 100000
b_lr = 0.0
w_lr = 0.0
# Store initial values for plotting.
b_history = [b]
w_history = [w]
# Iterations
for i in range(iteration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0*(y_data[n] - b - w*x_data[n])*1.0
w_grad = w_grad - 2.0*(y_data[n] - b - w*x_data[n])*x_data[n]
b_lr = b_lr + b_grad**2
w_lr = w_lr + w_grad**2
# Update parameters.
b = b - lr/np.sqrt(b_lr) * b_grad
w = w - lr/np.sqrt(w_lr) * w_grad
# Store parameters for plotting
b_history.append(b)
w_history.append(w)
# plot the figure
plt.contourf(x,y,Z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, markeredgewidth=3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200,-100)
plt.ylim(-5,5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()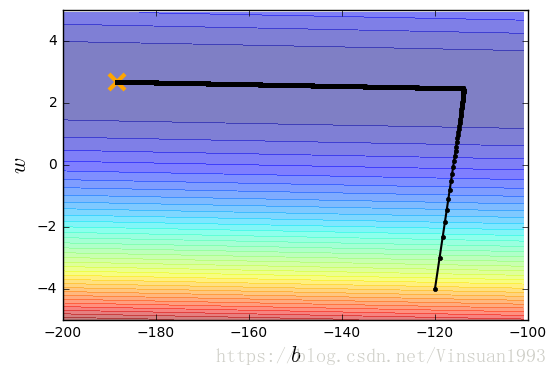
参考文献
- [机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
- 方向导数与梯度
- 方向导数与梯度
- 一文看懂常用的梯度下降算法
- ML Lecture 1: Regression - Demo