[飞桨机器学习]逻辑回归(六种梯度下降方式)
[飞桨机器学习]逻辑回归(六种梯度下降方式)
一、简介
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 w‘x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即y =w‘x+b,而logistic回归则通过函数L将w‘x+b对应一个隐状态p,p =L(w‘x+b),然后根据p 与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。
二、理论推导
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第1张图片](http://img.e-com-net.com/image/info8/39843f8e04764f35b568c3f7aaff0943.jpg)
使用逻辑回归进行分类,就是要找到绿色这样的分界线,使其能够尽可能地对样本进行正确分类,也就是能够尽可能地将两种样本分隔开来。因此我们可以构造这样一个函数,来对样本集进行分隔:
z ( x ( i ) ) = θ 0 + θ 1 x 1 ( i ) + θ 2 x 2 ( i ) + . . . + θ n x n ( i ) z(x^{(i)}) = \theta_0 + \theta_1 x^{(i)}_1 + \theta_2 x^{(i)}_2 + ... + \theta_n x^{(i)}_n z(x(i))=θ0+θ1x1(i)+θ2x2(i)+...+θnxn(i)
其中 i=1,2,…m,表示第 i个样本, n 表示特征数,当 z ( x ( i ) ) > 0 z(x^{(i)}) > 0 z(x(i))>0 时,对应着样本点位于分界线上方,可将其分为"1"类;当 z ( x ( i ) ) < 0 z(x^{(i)}) < 0 z(x(i))<0 时 ,样本点位于分界线下方,将其分为“0”类。
逻辑回归作为分类算法,它的输出是0/1。那么如何将输出值转换成0/1呢?
这就需要一个新的函数——sigmoid 函数
sigmoid 函数
sigmoid 函数定义如下:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
其函数图像为:
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第2张图片](http://img.e-com-net.com/image/info8/0e315e3aa73d4e339c64a52261240710.jpg)
由函数图像可以看出, sigmoid函数可以很好地将 (−∞,∞) 内的数映射到 (0,1) 上。
因此我们可以认为g(z)>= 0.5时为“1”类,反之为“0”类
y = { 1 , if g ( z ) ≥ 0.5 0 , otherwise y = \begin{cases} 1, & \text {if $g(z) \geq 0.5$ } \\ 0, & \text{otherwise} \end{cases} y={1,0,if g(z)≥0.5 otherwise
二项逻辑斯蒂回归模型(binomial logistic regression model)是一种分类模型,由条件概率分布 p(Y|X)表示,形式为参数化的逻辑斯谛分布。这里,随机变量 X 取值为实数,随机变量 Y 取值为 1或0。可通过监督学习的方法来估计模型参数。
二项逻辑斯谛回归模型是如下的条件概率分布:
p ( Y = 1 ∣ x ) = e θ T x 1 + e θ T x p(Y=1|x) = \frac{e^{\theta^Tx}}{1+e^{\theta^Tx}} p(Y=1∣x)=1+eθTxeθTx
p ( Y = 0 ∣ x ) = 1 1 + e θ T x p(Y=0|x) = \frac{1}{1+e^{\theta^Tx}} p(Y=0∣x)=1+eθTx1
其中, x∈Rn 是输入, Y∈{0,1} 是输出, θ 是参数。
对于 Y=1 :
p ( Y = 1 ∣ x ) = e θ T x 1 + e θ T x p(Y=1|x) = \frac{e^{\theta^Tx}}{1+e^{\theta^Tx}} p(Y=1∣x)=1+eθTxeθTx
而 e θ T x ≠ 0 e^{\theta^Tx} \neq 0 eθTx=0,故:
p ( Y = 1 ∣ x ) = 1 1 + e − θ T x p(Y=1|x) = \frac{1}{1+e^{-\theta^Tx}} p(Y=1∣x)=1+e−θTx1
即逻辑回归模型函数:
h θ ( x ( i ) ) = 1 1 + e − θ T x ( i ) h_\theta(x^{(i)}) = \frac{1}{1+e^{-\theta^Tx^{(i)}}} hθ(x(i))=1+e−θTx(i)1
表示为分类结果为“1”的概率
逻辑回归函数
分类边界:
z ( x ( i ) ) = θ 0 + θ 1 x 1 ( i ) + θ 2 x 2 ( i ) = θ T x ( i ) z(x^{(i)}) = \theta_0 + \theta_1 x^{(i)}_1 + \theta_2 x^{(i)}_2 = \theta^T x^{(i)} z(x(i))=θ0+θ1x1(i)+θ2x2(i)=θTx(i)
其中,$ \theta =[θ_0 θ_1 θ_2 ⋮ θ_n ]$
$ x^{(i)} = \begin{bmatrix} x^{(i)}_0 \ x^{(i)}_1 \ x^{(i)}_2 \ \vdots \ x^{(i)}_n \ \end{bmatrix} $
而 x(i)0=1是偏置项, n 表示特征数,i=1,2,…,m 表示样本数。
sigmoid函数 :
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
则***逻辑回归模型函数***为
h θ ( x ( i ) ) = g ( z ) = g ( θ T x ( i ) ) = 1 1 + e − θ T x i h_\theta(x^{(i)}) = g(z) = g( \theta^T x^{(i)} ) = \frac{1}{1+e^{-\theta^T x^{i}}} hθ(x(i))=g(z)=g(θTx(i))=1+e−θTxi1
我们可以对于新样本 $ x^{new} = [x^{new}1, x{new}*2,…,x{new}n]^T 进行输入,得到函数值进行输入,得到函数值 h\theta(x^{new}) ,根据 h\theta(x^{new}) $ 与0.5的比较来将新样本进行分类。
代价函数
使用 sigmoid 函数求解出来的值为类1的后验估计 p(y=1|x,θ),故我们可以得到:
p ( y = 1 ∣ x , θ ) = h θ ( θ T x ) p(y=1|x,\theta) = h_\theta(\theta^T x) p(y=1∣x,θ)=hθ(θTx)
则
p ( y = 0 ∣ x , θ ) = 1 − h θ ( θ T x ) p(y=0|x,\theta) = 1- h_\theta(\theta^T x) p(y=0∣x,θ)=1−hθ(θTx)
其中 p(y=1|x,θ)表示样本分类为 y=1 的概率,而 p(y=0|x,θ) 表示样本分类为 y=0的概率。针对以上二式,我们可将其整理为:
p ( y ∣ x , θ ) = p ( y = 1 ∣ x , θ ) y p ( y = 0 ∣ x , θ ) ( 1 − y ) = h θ ( θ T x ) y ( 1 − h θ ( θ T x ) ) ( 1 − y ) p(y|x,\theta)=p(y=1|x,\theta)^y p(y=0|x,\theta)^{(1-y)} = h_\theta(\theta^T x)^y (1- h_\theta(\theta^T x))^{(1-y)} p(y∣x,θ)=p(y=1∣x,θ)yp(y=0∣x,θ)(1−y)=hθ(θTx)y(1−hθ(θTx))(1−y)
我们可以得到其似然函数为:
L ( θ ) = ∏ i = 1 m p ( y ( i ) ∣ x ( i ) , θ ) = ∏ i = 1 m [ h θ ( θ T x ( i ) ) y ( i ) ( 1 − h θ ( θ T x ( i ) ) ) 1 − y ( i ) ] L(\theta) = \prod^m_{i=1} p(y^{(i)}|x^{(i)},\theta) = \prod ^m_{i=1}[ h_\theta(\theta^T x^{(i)})^{y^{(i)}} (1- h_\theta(\theta^T x^{(i)}))^{1-y^{(i)}}] L(θ)=i=1∏mp(y(i)∣x(i),θ)=i=1∏m[hθ(θTx(i))y(i)(1−hθ(θTx(i)))1−y(i)]
对数似然函数为:
log L ( θ ) = ∑ i = 1 m [ y ( i ) log h θ ( θ T x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( θ T x ( i ) ) ) ] \log L(\theta) = \sum_{i=1}^m [y^{(i)} \log{h_\theta(\theta^T x^{(i)})} +(1-y^{(i)}) \log{(1- h_\theta(\theta^T x^{(i)}))}] logL(θ)=i=1∑m[y(i)loghθ(θTx(i))+(1−y(i))log(1−hθ(θTx(i)))]
于是,我们便得到了代价函数,我们可以对求 logL(θ)logL(θ) 的最大值来求得参数 θθ 的值。为了便于计算,将代价函数做了以下改变:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log h θ ( θ T x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( θ T x ( i ) ) ) ] J(\theta) = - \frac{1}{m} \sum_{i=1}^m [y^{(i)} \log{h_\theta(\theta^T x^{(i)})} + (1-y^{(i)}) \log{(1- h_\theta(\theta^T x^{(i)}))}] J(θ)=−m1i=1∑m[y(i)loghθ(θTx(i))+(1−y(i))log(1−hθ(θTx(i)))]
此时,我们只需对 J(θ)求最小值,便得可以得到参数 θ。
三、优化算法
梯度下降
梯度下降法过程为: θ j : = θ j − α Δ J ( θ ) Δ θ j \theta_j := \theta_j - \alpha \frac{\Delta J(\theta)}{\Delta \theta_j} θj:=θj−αΔθjΔJ(θ)
求解梯度:
![]()
而
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第3张图片](http://img.e-com-net.com/image/info8/8cd905b0915e4b16b2615bc44d6742d3.jpg)
我们又知道:
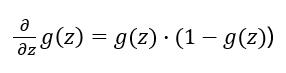
那么:
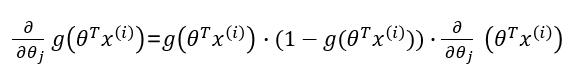
因此有:
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第4张图片](http://img.e-com-net.com/image/info8/50b8f4a817df44d6afe1436a9c533a2d.jpg)
综上:
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第5张图片](http://img.e-com-net.com/image/info8/f4f04ac25ca24e9e86ae02f9a04fb920.jpg)
随机梯度下降法
随机梯度下降是每次迭代使用一个样本来对参数进行更新。
即![]()
伪代码:
repeat{
for i=1,…,m{
θ j : = θ j − α 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j := \theta_j -\alpha \frac{1}{m}(h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)} θj:=θj−αm1(hθ(x(i))−y(i))xj(i)
(for j =0,1)
}
}
优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
牛顿法
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
步骤:
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ’ (x0)(这里f ’ 表示函数 f 的导数)。然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
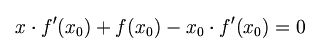
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:

已经证明,如果f ’ 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ’ (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。下图为一个牛顿法执行过程的例子。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第6张图片](http://img.e-com-net.com/image/info8/e4f373cbb58842f7a7ecb10993cc3067.gif)
而在逻辑回归中牛顿法更新方式为:
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第7张图片](http://img.e-com-net.com/image/info8/a2ba019b49ab48a3a269d579306459f8.jpg)
本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第8张图片](http://img.e-com-net.com/image/info8/da108205e8374ce7b1ead2b3188fedf0.jpg)
红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。Hessian矩阵也存在不可逆的情况
拟牛顿法
牛顿法中的Hesse矩阵H在稠密时求逆计算量大,也有可能没有逆(Hesse矩阵非正定)。拟牛顿法提出,用不含二阶导数的矩阵 Ut 替代牛顿法中的 Ht−1,然后沿搜索方向 −Utgt 做一维搜索。根据不同的 Ut 构造方法有不同的拟牛顿法。
拟牛顿条件
牛顿法的搜索方向是 d ( t ) = − H t − 1 g t d^{(t)}=-H_t^{-1}g_t d(t)=−Ht−1gt
为了不算二阶导及其逆矩阵,设法构造一个矩阵 U,用它来逼近 H−1
现在为了方便推导,假设 f(x) 是二次函数,于是 Hesse 矩阵 H 是常数阵,任意两点 x(t)和 x(t+1)处的梯度之差是:
▽ f ( x ( t + 1 ) ) − ▽ f ( x ( t ) ) = H ⋅ ( x ( t + 1 ) − x ( t ) ) \bigtriangledown f(x^{(t+1)}) - \bigtriangledown f(x^{(t)}) = H\cdot (x^{(t+1)}-x^{(t)}) ▽f(x(t+1))−▽f(x(t))=H⋅(x(t+1)−x(t))
等价于
x ( t + 1 ) − x ( t ) = H − 1 ⋅ [ ▽ f ( x ( t + 1 ) ) − ▽ f ( x ( t ) ) ] x^{(t+1)}-x^{(t)} = H^{-1}\cdot [\bigtriangledown f(x^{(t+1)}) - \bigtriangledown f(x^{(t)})] x(t+1)−x(t)=H−1⋅[▽f(x(t+1))−▽f(x(t))]
那么对非二次型的情况,也仿照这种形式,要求近似矩阵 U 满足类似的关系:
x ( t + 1 ) − x ( t ) = U t + 1 ⋅ [ ▽ f ( x ( t + 1 ) ) − ▽ f ( x ( t ) ) ] x^{(t+1)}-x^{(t)}=U_{t+1}\cdot [\bigtriangledown f(x^{(t+1)})-\bigtriangledown f(x^{(t)})] x(t+1)−x(t)=Ut+1⋅[▽f(x(t+1))−▽f(x(t))]
或者写成
Δ x t = U t + 1 ⋅ Δ g t \Delta x_t=U_{t+1}\cdot \Delta g_t Δxt=Ut+1⋅Δgt
BFGS算法是最流行的拟牛顿算法。
BFGS算法(Broyden-Fletcher-Goldfarb-Shanno)
自适应梯度算法(Adagrad)
在实际应用中,各参数的重要性肯定是不同的,所以对于不同的参数要进行动态调整,采取不同的学习率,让目标函数能够更快地收敛。
将每一个参数的每一次迭代的梯度取平方,然后累加并开方得到 r,最后用全局学习率除以 r,作为学习率的动态更新。
令 α 表示全局学习率,r 为梯度累积变量,初始值为 0。
- 单独计算每一个参数在当前位置的梯度。
g = ∂ L ( w ) ∂ w i g=\frac{∂L(w)}{∂w_i} g=∂wi∂L(w)
-
累积平方梯度,一般来说 g 是一个向量,而向量的平方通常写为 gTg
r = r + g 2 或 r = r + g T g r=r+g^2 或r=r+g^Tg r=r+g2或r=r+gTg -
更新参数
w = w − α r g w=w-\frac{\alpha}{\sqrt{r}}g w=w−rαg
上述式子存在一个问题,r 在计算过程中有可能变为 0,在代码中分母为零通常都会报错,因此我们需要想办法让分母不为零,同时不会影响到参数的更新。
我们可以在分母上加一个极小的常数 σ,因为取值极小,即使开方后仍然不会影响参数的更新。通常,σ 大约设置为 10 的 -7 次方。
w = w − α σ + r g w=w-\frac{\alpha}{\sigma+\sqrt{r}}g w=w−σ+rαg
AdaDelta算法
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。
特点:
- 训练初中期,加速效果不错,很快
- 训练后期,反复在局部最小值附近抖动

RMSProp
因为Adagrad算法会出现提前停止的现象,所以在RMSProp算法中解决了这个问题,它采用指数加权平均的思想,只将最近的梯度进行累加计算平方。
s t = γ s t − 1 + ( 1 − γ ) ▽ θ J ( θ ) ∗ ▽ θ J ( θ ) s_{t} = \gamma s_{t-1} + (1 - \gamma)\bigtriangledown_\theta J(\theta) * \bigtriangledown_\theta J(\theta) st=γst−1+(1−γ)▽θJ(θ)∗▽θJ(θ)
θ = θ − η s t + ϵ ∗ ▽ θ J ( θ ) \theta = \theta - \frac{\eta}{\sqrt{s_{t} + \epsilon}} * \bigtriangledown_\theta J(\theta) θ=θ−st+ϵη∗▽θJ(θ)
Adam
Adam算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即alpha)更新所有的权重,学习率在训练过程中并不会改变。而Adam通过随机梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
![[飞桨机器学习]逻辑回归(六种梯度下降方式)_第9张图片](http://img.e-com-net.com/image/info8/1334e2368ecb4395a797589dddb6ed10.jpg)
四、代码实现
导入包
import math
import csv
import numpy as np
读取数据
def loaddata(filename):
label = []
with open(filename, 'r') as f:
lines = csv.reader(f)
data = list(lines)
for i in range(len(data)):
del(data[i][0])
for j in range(len(data[i])):
data[i][j] = float(data[i][j])
label.append(data[i][-1])
del(data[i][-1])
return np.array(data), np.array(label)
代价函数
def J(theta, X, Y, theLambda=0):
m, n = X.shape
h = sigmoid(np.dot(X, theta))
J = (-1.0/m)*(np.dot(np.log(h).T, Y)+np.dot(np.log(1-h).T, 1-Y)) + (theLambda/(2.0*m))*np.sum(np.square(theta[1:]))
return J.flatten()[0]
sigmod函数
def sigmoid(x):
return 1.0/(1 + np.exp(-x))
随机梯度下降
def gradient_sgd(X, Y, alpha=0.01, epsilon=0.00001, maxloop=1000, theLambda=0.0):
m, n = X.shape
theta = np.zeros((n, 1))
cost = J(theta, X, Y)
costs = [cost]
thetas = [theta]
# 随机梯度下降
count = 0
flag = False
while count < maxloop:
if flag:
break
for i in range(m):
h = sigmoid(np.dot(X[i].reshape((1, n)), theta))
theta = theta - alpha * (
(1.0 / m) * X[i].reshape((n, 1)) * (h - Y[i]) + (theLambda / m) * np.r_[[[0]], theta[1:]])
thetas.append(theta)
cost = J(theta, X, Y, theLambda)
costs.append(cost)
if abs(costs[-1] - costs[-2]) < epsilon:
flag = True
break
count += 1
if count % 100 == 0:
print("cost:", cost)
return thetas, costs, count
牛顿法
def gradient_newton(X, Y, epsilon=0.00001, maxloop=1000, theLambda=0.0):
m, n = X.shape
theta = np.zeros((n, 1))
cost = J(theta, X, Y)
costs = [cost]
thetas = [theta]
count = 0
while count < maxloop:
delta_J = 0.0
H = 0.0
for i in range(m):
h = sigmoid(np.dot(X[i].reshape((1, n)), theta))
delta_J += X[i] * (h - Y[i])
H += h.T * (1 - h) * X[i] * X[i].T
delta_J /= m
H /= m
print(H, delta_J)
theta = theta - 1.0 / H * delta_J
thetas.append(theta)
cost = J(theta, X, Y, theLambda)
costs.append(cost)
if abs(costs[-1] - costs[-2]) < epsilon:
break
count += 1
if count % 100 == 0:
print("cost:", cost)
return thetas, costs, count
Adagrad
def gradient_adagrad(X, Y, alpha=0.01, sigma=1e-7, epsilon=0.00001, maxloop=1000, theLambda=0.0):
m, n = X.shape
theta = np.zeros((n, 1))
r = [[0.0] for _ in range(n)]
cost = J(theta, X, Y)
costs = [cost]
thetas = [theta]
count = 0
flag = False
while count < maxloop:
if flag:
break
for i in range(m):
h = sigmoid(np.dot(X[i].reshape((1, n)), theta))
grad = (1.0 / m) * X[i].reshape((n, 1)) * (h - Y[i])
for j in range(n):
r[j].append(grad[j]**2+r[j][-1])
theta[j] = theta[j] - alpha * grad[j] / (sigma + math.sqrt(r[j][-1]))
thetas.append(theta)
cost = J(theta, X, Y, theLambda)
costs.append(cost)
if abs(costs[-1] - costs[-2]) < epsilon:
flag = True
break
count += 1
if count % 100 == 0:
print("cost:", cost)
return thetas, costs, count
Adadelta
def gradient_adadelta(X, Y, rho=0.01, alpha=0.01, sigma=1e-7, epsilon=0.00001, maxloop=1000, theLambda=0.0):
m, n = X.shape
theta = np.zeros((n, 1))
r = [[0.0] for _ in range(n)]
deltax = [[0.0] for _ in range(n)]
deltax_ = [[1.0] for _ in range(n)]
cost = J(theta, X, Y)
costs = [cost]
thetas = [theta]
count = 0
flag = False
while count < maxloop:
if flag:
break
for i in range(m):
h = sigmoid(np.dot(X[i].reshape((1, n)), theta))
grad = (1.0 / m) * X[i].reshape((n, 1)) * (h - Y[i])
for j in range(n):
r[j].append((1-rho) * grad[j]**2 + rho * r[j][-1])
deltax[j].append(- (math.sqrt(deltax_[j][-1] / sigma + r[j][-1]))*alpha)
theta[j] = theta[j] + deltax[j][-1]
deltax_[j].append((1-rho)*deltax[j][-1]**2+rho*deltax_[j][-1])
# print(deltax)
# print(deltax_)
thetas.append(theta)
cost = J(theta, X, Y, theLambda)
costs.append(cost)
if abs(costs[-1] - costs[-2]) < epsilon:
flag = True
break
count += 1
if count % 100 == 0:
print("cost:", cost)
return thetas, costs, count
RMSProp
def gradient_RMSProp(X, Y, rho=0.01, alpha=0.01, sigma=1e-7, epsilon=0.00001, maxloop=1000, theLambda=0.0):
m, n = X.shape
theta = np.zeros((n, 1))
r = [[0.0] for _ in range(n)]
cost = J(theta, X, Y)
costs = [cost]
thetas = [theta]
count = 0
flag = False
while count < maxloop:
if flag:
break
for i in range(m):
h = sigmoid(np.dot(X[i].reshape((1, n)), theta))
grad = (1.0 / m) * X[i].reshape((n, 1)) * (h - Y[i])
for j in range(n):
r[j].append((1 - rho)*grad[j]**2+rho*r[j][-1])
theta[j] = theta[j] - alpha * grad[j] / (sigma + math.sqrt(r[j][-1]))
thetas.append(theta)
cost = J(theta, X, Y, theLambda)
costs.append(cost)
if abs(costs[-1] - costs[-2]) < epsilon:
print(costs)
flag = True
break
count += 1
if count % 100 == 0:
print("cost:", cost)
return thetas, costs, count
Adam
def gradient_adam(X, Y, rho1=0.9, rho2=0.999, alpha=0.01, sigma=1e-7, epsilon=0.00001, maxloop=1000, theLambda=0.0):
m, n = X.shape
theta = np.zeros((n, 1))
s = [[0.0] for _ in range(n)]
r = [[0.0] for _ in range(n)]
cost = J(theta, X, Y)
costs = [cost]
thetas = [theta]
count = 0
flag = False
while count < maxloop:
if flag:
break
for i in range(m):
h = sigmoid(np.dot(X[i].reshape((1, n)), theta))
grad = (1.0 / m) * X[i].reshape((n, 1)) * (h - Y[i])
for j in range(n):
r[j].append((1 - rho2)*grad[j]**2+rho2*r[j][-1])
s[j].append((1 - rho1)*grad[j]+rho1*r[j][-1])
theta[j] = theta[j] - alpha * (s[j][-1]/(1-rho1**2))/(math.sqrt(r[j][-1]/(1-rho2**2))+sigma)
thetas.append(theta)
cost = J(theta, X, Y, theLambda)
costs.append(cost)
if abs(costs[-1] - costs[-2]) < epsilon:
print(costs)
flag = True
break
count += 1
if count % 100 == 0:
print("cost:", cost)
return thetas, costs, count
主程序
if __name__ == '__main__':
train_data, train_label = loaddata('data/data43561/pima_train.csv')
test_data, test_label = loaddata('data/data43561/pima_test.csv')
# print(train_data)
# print(train_label)
m = train_data.shape[0]
# print(m)
X = np.concatenate((np.ones((m, 1)), train_data), axis=1)
# print(X)
thetas, costs, iterationCount = gradient_sgd(X, train_label, 0.05, 0.00000001, 100)
# thetas, costs, iterationCount = gradient_newton(X, train_label, 0.00000001, 10000)
# thetas, costs, iterationCount = gradient_adagrad(X, train_label, 0.05, 1e-7, 0.000000000000001, 10000)
# thetas, costs, iterationCount = gradient_adadelta(X, train_label, 0.9999999999, 1e-5, 1e-7, 0.000000000000001, 10000)
# thetas, costs, iterationCount = gradient_RMSProp(X, train_label, 0.9, 1e-5, 1e-7, 0.000000000000001, 10000)
# thetas, costs, iterationCount = gradient_adam(X, train_label, 0.9, 0.99, 0.001, 1e-7, 0.000000000000001, 10000)
print(costs[-1], iterationCount)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:4: RuntimeWarning: divide by zero encountered in log
after removing the cwd from sys.path.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:26: RuntimeWarning: invalid value encountered in double_scalars
cost: 0.7724120224525658
0.7724120224525658 100
运行代码请点击:https://aistudio.baidu.com/aistudio/projectdetail/625618?shared=1