YOLO v5 训练最好结果的技巧
来自:Tips for Best Training Results - YOLOv5 Documentation
Tips for Best Training Results
训练最好结果的技巧
Hello! This guide explains how to produce the best mAP and training results with YOLOv5 .
Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement.
If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your project/name directory, typically yolov5/runs/train/exp.
We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below.
怎么使用 YOLO v5 训练最好的 mAP 和 训练结果。大多数情况下,只要你的数据集是足够大的,并且标注良好,就可以在不改变模型或者训练设置的情况下获得良好的结果。如果一开始你没有得到好的结果,你可以采取一些步骤来改进,但是我们总是建议用户在考虑任何更改之前先进行所有默认设置的训练。这有助于建立性能 baseline 和发现需要改进的地方。
如果你对你的训练结果有疑问,我们建议你提供尽可能多的信息,如果你希望得到有用的回应,包括结果图(train losses, val losses, P, R, mAP) ,PR curve, confusion matrix, training mosaics, test results 和 dataset statistics images such as labels.png。所有这些都位于您的 project/name 目录中,通常是 yolov5/runs/train/exp 。
Dataset
-
Images per class. ≥1.5k images per class
-
Instances per class. ≥10k instances (labeled objects) per class total
-
Image variety. Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.
-
Label consistency. All instances of all classes in all images must be labelled. Partial labelling will not work.
-
Label accuracy. Labels must closely enclose each object. No space should exist between an object and it's bounding box. No objects should be missing a label.
-
Background images. Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total).
数据集
-
每类的图片:每类 => 1.5k张图像
-
每类的实例:每类全部的实例(标注的目标) => 10k
-
图像多样性:必须是部署环境的代表。对于真实世界的用例,我们推荐一天中不同时间、不同季节、不同天气、不同灯光、不同角度、不同来源的图片(从网上搜集、本地收集、不同的相机)等等。
-
标签的一致性:所有图像中所有类的所有实例都必须标记。部分标记不起作用。
-
标签的准确性:标签必须紧密地包围每个目标。目标和它的bounding box之间不应该有空间。任何目标都不应该缺少标签。
-
背景图像:背景图像是没有添加目标的图像,这些图像添加到数据集中是为了减少False Positives (FP)。我们建议约0-10% 的背景图像,以帮助降低FPs (作为参考,COCO 有1000个背景图像,占总数的1% )。
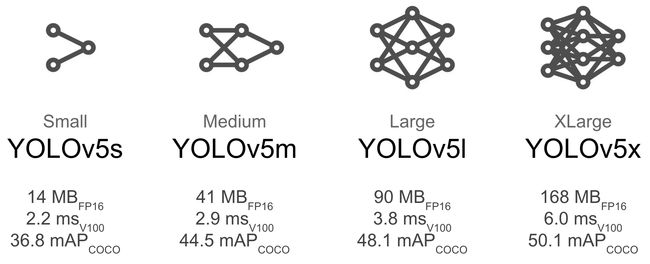
Model Selection
Larger models like YOLOv5x and YOLOv5x6 will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For mobile deployments we recommend YOLOv5s/m, for cloud deployments we recommend YOLOv5l/x. See our README table for a full comparison of all models.
像 YOLOv5x 和 yolov5x6 这样的大型模型在几乎所有情况下都会产生更好的效果,但是有更多的参数,需要更多的 CUDA 内存来训练,并且运行速度更慢。对于移动部署,我们推荐 YOLOv5s/m,对于云部署,我们推荐 YOLOv5l/x。有关所有模型的完整比较,请参见我们的 README 表。
-
Start from Pretrained weights. Recommended for small to medium sized datasets (i.e. VOC, VisDrone, GlobalWheat). Pass the name of the model to the
--weightsargument. Models download automatically from the latest YOLOv5 release. -
从预训练的权重开始。推荐用于中小型数据集(即 VOC,VisDrone,GlobalWheat)。将模型的名称传递给 --weights 参数。模型自动从最新 yolov5发行版 下载。
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt-
Start from Scratch. Recommended for large datasets (i.e. COCO, Objects365, OIv6). Pass the model architecture yaml you are interested in, along with an empty
--weights ''argument: -
从零开始。建议用于大型数据集(即 COCO,Objects365,OIv6)。传递你感兴趣的模型架构 yaml 和一个空的 --weights '' 参数:
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yamlTraining Settings
Before modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
-
Epochs. Start with 300 epochs. If this overfits early then you can reduce epochs. If overfitting does not occur after 300 epochs, train longer, i.e. 600, 1200 etc epochs.
-
Image size. COCO trains at native resolution of
--img 640, though due to the high amount of small objects in the dataset it can benefit from training at higher resolutions such as--img 1280. If there are many small objects then custom datasets will benefit from training at native or higher resolution. Best inference results are obtained at the same--imgas the training was run at, i.e. if you train at--img 1280you should also test and detect at--img 1280. -
Batch size. Use the largest
--batch-sizethat your hardware allows for. Small batch sizes produce poor batchnorm statistics and should be avoided. -
Hyperparameters. Default hyperparameters are in hyp.scratch.yaml. We recommend you train with default hyperparameters first before thinking of modifying any. In general, increasing augmentation hyperparameters will reduce and delay overfitting, allowing for longer trainings and higher final mAP. Reduction in loss component gain hyperparameters like
hyp['obj']will help reduce overfitting in those specific loss components. For an automated method of optimizing these hyperparameters, see our Hyperparameter Evolution Tutorial.
在修改任何内容之前,首先使用默认设置进行训练,以建立性能baseline。可以在 train.pyargparser 中找到 train.py 设置的完整列表。
-
Epochs. 从300个epochs开始。如果过早过拟合,那么你可以减少epochs。如果在300个epochs之后没有发生过拟合,那么训练时间要长一些,比如600、1200个epochs等等。
-
图像大小。COCO 以 --img 640 的native分辨率进行训练,但由于数据集中的小对象数量很多,它可以从高分辨率的训练中获益,比如 --img 1280。如果有许多小对象,那么自定义数据集将受益于native或更高分辨率的训练。最佳推理结果的获得与训练时使用的相同 -- img,也就是说,如果您在 -- img 1280进行训练,那么您也应该在 -- img 1280进行测试和检测。
-
Batch size. 使用硬件允许的最大 --batch-size 。小的 batch sizes 会产生较差的batchnorm statistics,应该避免使用。
-
Hyperparameters. 默认hyperparameters 是 hyp.scratch.yaml。我们建议您首先使用默认的超参数进行训练,然后再考虑修改任何超参数。一般来说,增加增强超参数将减少和延迟过拟合,允许更长的训练和更高的最终 mAP。减少loss components增益超参数,如 hyp['obj'],将有助于减少特定loss components的过拟合。有关优化这些超参数的自动化方法,请参见我们的Hyperparameter Evolution Tutorial.。
Further Reading
If you'd like to know more a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: http://karpathy.github.io/2019/04/25/recipe/
如果你想知道更多的关于训练神经网络的秘诀,可以从 Karpathy 的《训练神经网络的秘诀》开始,这本书对训练有很好的想法,可以广泛应用于所有机器学习领域: http://Karpathy.github.io/2019/04/25/Recipe/