七大排序详解
目录
排序的稳定性
七大排序总览
测试类代码
1.1选择排序
1.2双向选择排序
2.1插入排序
2.2折半插入排序
3.冒泡排序
4.希尔排序
5.堆排序
6.归并排序
归并排序的两点优化
归并排序的非递归写法
海量数据的排序处理
7. 快速排序
快速排序的优化
二路快排
三路快排
挖坑法
快排的非递归实现
总结
排序的稳定性
两个相等的数据,如果经过排序后,排序算法能保证其相对位置不发生变化,则我们称该算法是具备稳定性的排序算法。
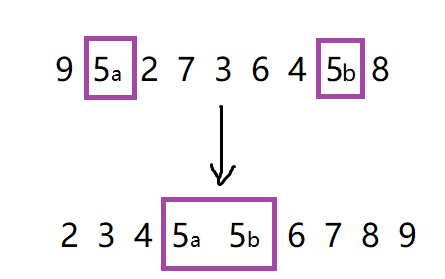
如图中,相同两个5用下标a、b作区分,排序之后a和b的相对位置没有发生改变,这种排序就具有稳定性。
稳定性是很常见的,例如一个网络电商,需要在后台按照订单的金额排序,原订单是按照时间先后排序的,要求排序后时间先后顺序不变如下图,需要使用稳定性的排序算法对订单金额排序,同时保证时间的先后顺序不发生改变。

七大排序总览
| 插入排序 | 直接插入排序 | O(n^2) | 稳定 |
| 希尔排序 | O(n^(1.3~1.5)) | ||
| 选择排序 | 选择排序 | O(n^2) | |
| 堆排序 | O(nlogn) | ||
| 交换排序 | 冒泡排序 | O(n^2) | 稳定 |
| 快速排序 | O(nlogn) | ||
| 归并排序 | O(nlogn) | 稳定 | |
上述都是内部排序:一次性将所有待排序的数据放入内存中进行的排序,是基于元素直接比较的排序。
相应的还有外部排序,顾名思义,就是依赖硬盘(外部存储器)进行的排序算法,常见的有桶排序、基数排序、计数排序,这三种排序的时间复杂度都是O(n),但对于集合的要求非常高,只能在特定的场合下使用
写排序的代码要注意变量是如何定义的,以及未排序区间和已排序区间的定义
测试类代码
在排序中我们测试的数目太小,所以我们创建一个测试类,生成测试数组以及对排序算法进行测试
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.Arrays;
import java.util.concurrent.ThreadLocalRandom;
//排序的辅助类
//生成测试数组以及对排序算法进行测试
public class SortHelper {
//获取一个随机数的对象
private static final ThreadLocalRandom random = ThreadLocalRandom.current();
//生存一个数组大小为n的随机数数组,在[left,right]区间上生成n个随机数
public static int[] generateRandomArray(int n,int left,int right){
int[] arr = new int[n];
for (int i = 0; i < arr.length; i++) {
arr[i] = random.nextInt(left,right);
}
return arr;
}
//生成长度为n的近乎有序的数组
//先生成有序数组,再交换部分数字
//times是交换的次数
public static int[] generatrSoredArray(int n,int times){
int[] arr = new int[n];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
//交换部分元素
for (int i = 0; i < times; i++) {
//生成一个在[0,n]范围内的随机数
int a = random.nextInt(n);
int b = random.nextInt(n);
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
return arr;
}
//生成一个arr的深度拷贝数组
//为了测试不同排序算法的性能,需要在相同的数据集上进行测试
public static int[] arrCopy(int[] arr){
return Arrays.copyOf(arr,arr.length);
}
//测试性能
//借助反射根据传入的方法名称就能调用方法
//传入方法名称和待排序集合
public static void testSort(String sortName,int[] arr){
Class cls = SevenSort.class;
try {
Method method = cls.getDeclaredMethod(sortName,int[].class);
long start = System.nanoTime();
method.invoke(null,arr);
long end = System.nanoTime();
//如果数组有序
if (isSorted(arr)){
System.out.println(sortName+"排序结束,共耗时:"+(end-start)/1000000.0 + "ms");
}
}catch (NoSuchMethodException e){
e.printStackTrace();
}catch (InvocationTargetException e){
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
//判断数组是否有序
public static boolean isSorted(int[] arr){
for (int i = 0; i < arr.length - 1; i++) {
if(arr[i] > arr[i+1]){
System.out.println("sort error");
return false;
}
}
return true;
}
}
1.1选择排序
每次从无序区间中选择一个最大或最小值,存放在无序区间的最前或最后的位置,直到所有的元素都排序完为止
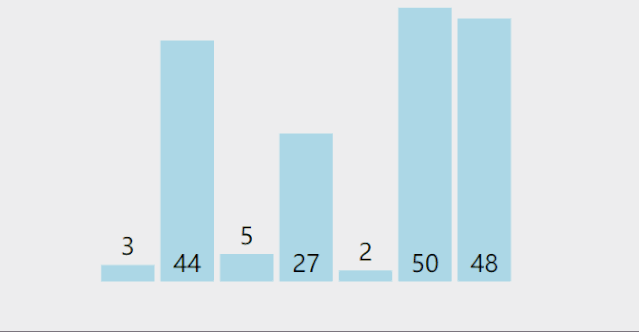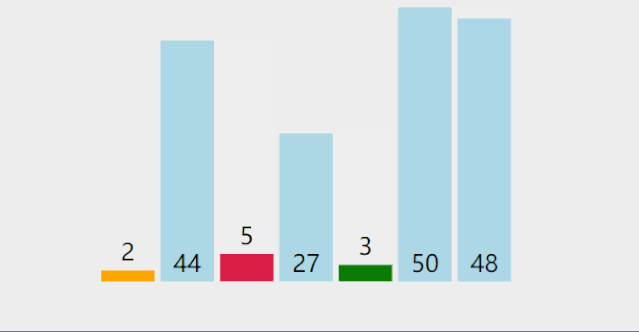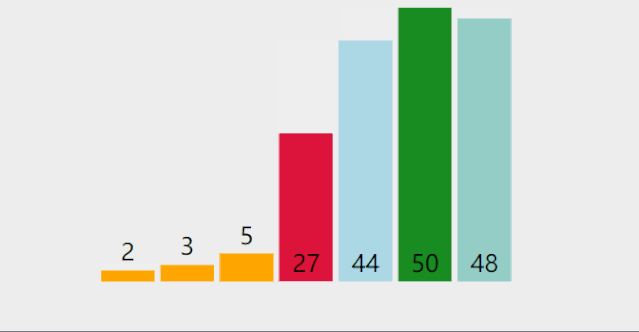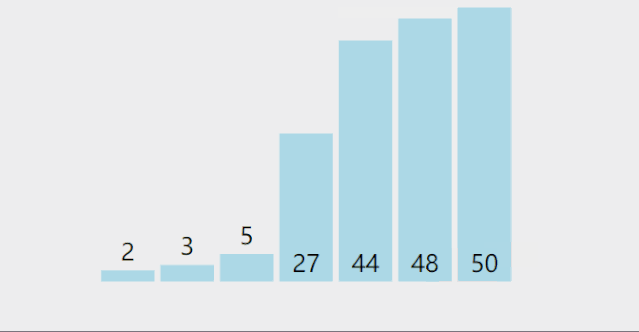
为什么选择排序不具有稳定性呢?

如图,经过第二次排序,5a和5b的先后顺序就发生了改变,因此选择排序是一个不稳定的排序算法。
选择排序代码实现:
//选择排序
public static void selectionSort(int[] arr){
//最开始,无序区间为[0...n],有序区间[]
for (int i = 0; i < arr.length; i++) {
//min存储当前的最小值
//先默认第一个元素就是最小值
int min = i;
for (int j = i+1; j < arr.length ; j++) {
if(arr[j] < arr[min]){
min = j;
}
}
//此时min索引对应的一定对应的最小值索引,换到无序区间前面
swap(arr,i,min);
}
}
private static void swap(int[] arr,int i, int min) {
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
public static void main(String[] args) {
int[] arr = {9,5,2,7,5,4,3,6};
selectionSort(arr);
System.out.println(Arrays.toString(arr));
}
//输出:[2, 3, 4, 5, 5, 6, 7, 9]代码测试:
//测试类
public class SortTest {
public static void main(String[] args) {
int n = 50000;
int[] arr = SortHelper.generateRandomArray(n, 0, Integer.MAX_VALUE);
SortHelper.testSort("selectionSort",arr);
}
}
//输出:selectionSort排序结束,共耗时:1191.947799ms1.2双向选择排序
一次排序过程同时选出最大值和最小值
代码实现:
//双向选择排序
public static void selectionSortOP(int[] arr){
int left = 0;
int right = arr.length -1;
//left = right,无序区间只剩下一个元素,整个数组已经有序
while (left <= right){
int min = left;
int max = left;
for (int i = left+1; i <= right; i++) {
if(arr[i] < arr[min]){
min = i;
}
if(arr[i] > arr[max]){
max = i;
}
}
//此时min索引指向无序数组最小值,将它和left交换
swap(arr,min,left);
if (left == max){
//最大值已经被换到min位置
max = min;
}
swap(arr,max,right);
left += 1;
right -= 1;
}
}
//测试
public static void main(String[] args) {
int n = 50000;
int[] arr = SortHelper.generateRandomArray(n, 0, Integer.MAX_VALUE);
int[] arrCopy1 = SortHelper.arrCopy(arr);
//测试选择排序
SortHelper.testSort("selectionSort",arr);
//双向选择排序
SortHelper.testSort("selectionSortOP",arrCopy1);
}
//输出:
selectionSort排序结束,共耗时:1210.855ms
selectionSortOP排序结束,共耗时:1379.9959ms2.1插入排序
将集合分为两个区间:已排序区间和待排序区间,每次从待排序区间中取第一个元素插入到已排序区间中
插入排序和选择排序最大的不同在于插入排序当前遍历的元素 > 前驱元素时,就可以提前结束内层循环。在极端场景下,当集合是一个完全有序的集合时,插入排序内层循环一次都不需要走,时间复杂度变为O(n),所以插入排序经常用作高阶排序算法的优化手段之一
代码实现:
//插入排序
//每次从无序区间拿出第一个值插入到已排序区间值中的合适位置
public static void insertionSort(int[] arr){
//默认第一个元素有序,所以i从 1 开始
for (int i = 1; i < arr.length; i++) {
//待排序区间第一个元素是arr[i]
//从待排序区间的第一个元素向前看,找到合适的插入位置
for (int j = i; j > 0 ; j--) {
//arr[j-1]是已排序区间的最后一个元素
if(arr[j] >= arr[j-1]){
//此时说明arr[j] 已经有序
break;
}else {
swap(arr,j,j-1);
}
}
}
}
上述代码的内循环也可简化成:
for (int j = i; j > 0 && arr[j] > arr[j +1]; j--) {
swap(arr,j,j-1);
}2.2折半插入排序
因为插入排序中,每次都是在有序区间中选择插入位置,因此我们可以使用二分查找来定位元素的插入位置
我们知道,int的数据范围[-2^15~2^15-1]的建议使用int mid = left + ((right-left)>>1);因为当left和right的值很大时,二者相加就可能超出表示范围,所以不建议使用int mid = (right+left)>>1
//折半插入排序
public static void insertionSortBS(int[] arr){
for (int i = 1; i < arr.length; i++) {
int val = arr[i];
int left = 0;
int right = i;
while (left < right){
int mid = left + ((right-left)>>1);
if (val < arr[mid]){
right = mid;
}else {
//此时val >= arr[mid]
left = mid + 1;
}
}
//搬移left到i的元素
for (int j = i; j > left ; j--) {
//后一个元素等于前一个元素
arr[j] = arr[j-1];
}
//left就是val插入的位置
arr[left] = val;
}
}3.冒泡排序
在无序区间,通过相邻数的比较,将最大的数冒泡到无序区间的最后,持续这个过程,直到数组整体有序。也就是说每遍历一遍,就能找个一个最大值放到末尾,所以每次遍历的区间可以减少一个
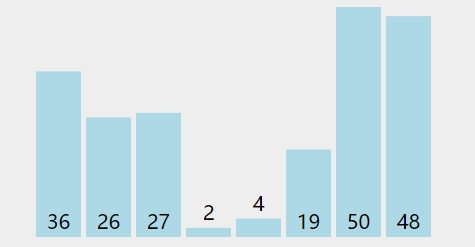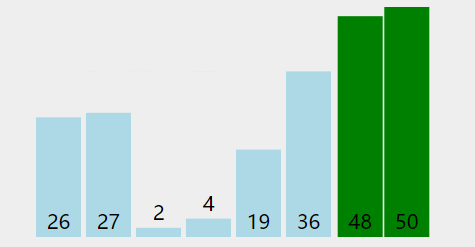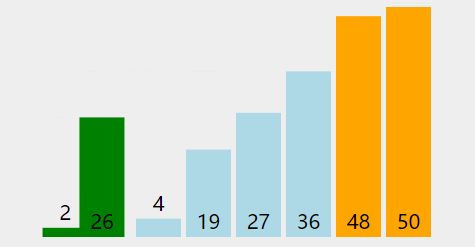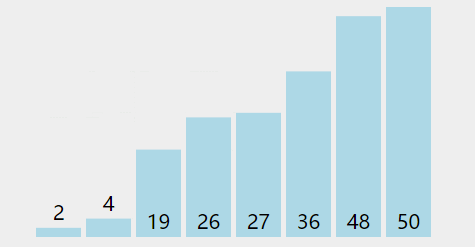
代码实现:
//冒泡排序
public static void bubbleSort(int[] arr){
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length-1-i; j++) {
if(arr[j] > arr[j+1]){
swap(arr,j+1,j);
}
}
}
}
4.希尔排序
又叫缩小增量排序,该排序的步骤如下:
- 先选定一个整数记为gap,(gap一般都选取数组长度的1/2或者1/3)
- 将待排序的数组先按照gap分组,不同组之间内部使用插入排序
- 排序之后,再将gap除以2或者除以3
- 重复上述步骤,直到gap = 1。
下图就是希尔排序的过程,可以看到数组越来越近乎有序 ,在代码实现过程中,我们没有将数组显示的按组拆分,但是思路是一致的。当前元素和前一个gap步的元素比较,若往前没有相同步数的元素就跳出内循环,执行下一个元素。

代码实现:
//希尔排序
public static void shellSort(int[] arr){
int gap = arr.length >>1;
while (gap > 1){
//预处理阶段
insertionSortByGap(arr,gap);
gap = gap >>1;
}
//此时gap = 1,只需将全集合来一次插入排序即可
insertionSort(arr);
}
//按照gap分组进行插入排序
private static void insertionSortByGap(int[] arr, int gap) {
//i是当前正在扫描的元素,我们只需要看和i相同步数的元素是否需要调整
for (int i = gap; i < arr.length; i++) {
//不断向前扫描相同gap的元素
//j-gap从j位置开始向前还有相同步数的元素
for (int j = i; j -gap >= 0 && arr[j] < arr[j-gap] ; j-=gap) {
swap(arr,j,j-gap);
}
}
}5.堆排序
排序思想;将数组堆化,调整为最大堆,再次遍历这个最大堆,进行交换操作,把当前堆的最大值交换到最终位置,堆排序是一个稳定的nlogN级别的排序。
以最大堆为例,要得到一个降序数组,就得得创建一个和当前数组大小相同的堆,然后依次取出最大值直到堆为空,而无法在原数组上进行排序,它的空间复杂度为 O( N ) ,而我们使用堆排序就在原地进行排序。
代码实现:
public static void heapSort(int[] arr){
//1.先将数组进行heapify操作,调整为最大堆
//从最后一个非叶子节点开始进行siftDown操作
for (int i = (arr.length-1-1)/2;i >=0; i--) {
siftDown(arr,i,arr.length);
}
//此时数组就已经调整为了最大堆
for (int i = arr.length-1;i > 0;i--) {
//将堆顶元素换到末尾
swap(arr,0,i);
//对换过来的元素进行下沉操作
siftDown(arr,0,i);
}
}
// 元素下沉操作,i是当前要下沉的索引
private static void siftDown(int[] arr, int i, int length) {
while (2 *i +1 arr[j]){
j = j + 1;
}
//j就是左右子树的最大值
if (arr[i] > arr[j]){
//下沉结束
break;
}else {
swap(arr,i,j);
i = j;
}
}
} 6.归并排序
第一阶段:将原数组不断拆分,一直拆分到每个子数组只有一个元素(归的过程)
第二阶段:将相邻两个数组合并为一个有序数组,直到整个数组有序(并的过程)
下图为合并过程,i指向左侧小数组的开始索引,j表示右侧小数组的开始索引,当其中一个数组为空后,就将另一个数组剩下的元素搬移到arr中。此时我们就得到了一个有序的合并后的数组。
在这里我们为何要创建临时数组呢,因为在合并过程中,小元素要覆盖大元素,为了防止元素的丢失而创建临时数组
 代码实现:
代码实现:
//归并排序
public static void mergeSort(int[] arr){
mergeSortInternal(arr,0,arr.length-1);
}
//将数组的[l,r]区间进行归并排序
public static void mergeSortInternal(int[] arr, int l, int r) {
if(l >= r){
//当前数组只剩下一位元素,结束归过程
return;
}
int mid = l + ((r-l)>>1);
//将数组拆成左右两个小区间
mergeSortInternal(arr,l,mid);
mergeSortInternal(arr,mid+1,r);
merge(arr, l, mid, r);
}
//合并两个子数组,arr[l,mid]和arr[mid+1,r]
public static void merge(int[] arr, int l, int mid, int r) {
//现创建一个新的临时数组
int[] aux = new int[r-l+1];
//将arr的值拷贝到aux
for (int j = 0; j < aux.length; j++) {
//arr第一个元素索引是l,所以aux索引比arr的差了l个单位
aux[j] = arr[j + l];
}
//i就是左侧小数组的开始索引
int i = l;
//j就是右侧小数组的开始索引
int j =mid + 1;
//k表示当前正在合并的原数组的下标
for (int k = l; k <= r; k++) {
if(i > mid){
//左侧区间已经处理完毕
arr[k] = aux[j -l];
j ++;
}else if (j > r){
//右侧区间已经处理完毕
arr[k] = aux[i -l];
i ++;
}else if (aux[i - l] <= aux[j - l]){
arr[k] = aux[i - l];
i ++;
}else {
arr[k] = aux[j - l];
j ++;
}
}
} ![]() 要知道,归并排序是具有稳定性的排序算法,同时它的时间复杂度也是稳定的 nlog(N),也就是说,它不会退化为O(n^2)。
要知道,归并排序是具有稳定性的排序算法,同时它的时间复杂度也是稳定的 nlog(N),也就是说,它不会退化为O(n^2)。
nlog(N)是如何得来的呢?首先,递归拆分的过程就类型一个树结构,递归的深度就是拆分数组所用的时间,也就是树的高度logN;最后我们合并两个子数组的过程就是数组的遍历,时间复杂度就是O(n)。
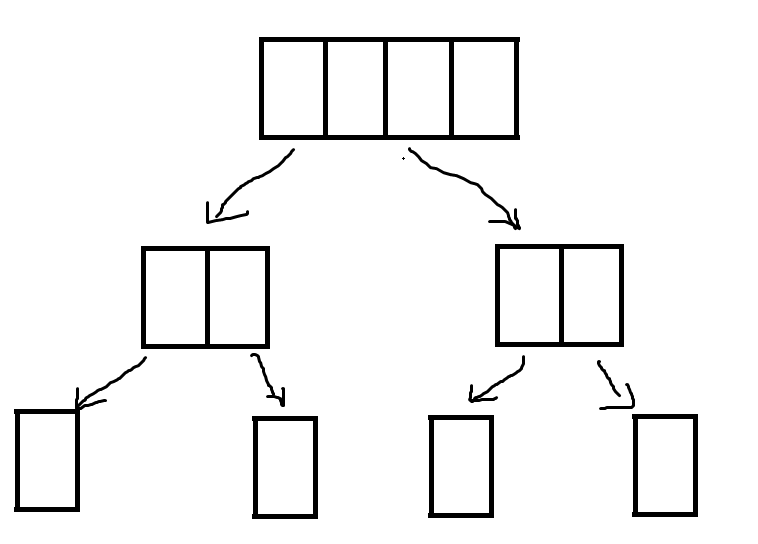

归并排序的两点优化
1.当左右两个子区间走完子函数后,左右两个区间已经有序了,如果这时左数组最后一个元素小于或等于右数组第一个元素,就说明整个区间就已经有序了,不需要再执行merge去排序。

2.在小区间上我们可以使用插入排序来优化,没必要一直拆分到只有一个元素,一般来说小于15个元素使用插入排序,这样可以减少递归次数
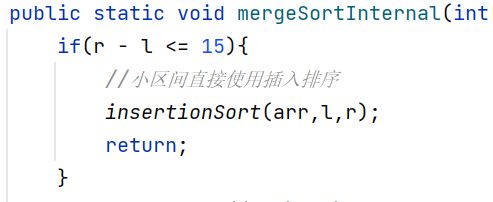
//在arr[l..r]区间上使用插入排序
private static void insertionSort(int[] arr, int l, int r) {
for (int i = l+1; i <= r; i++) {
for (int j = i; j >l && arr[j] < arr[j-1] ; j--) {
swap(arr,j,j-1);
}
}
}
归并排序的非递归写法
归并的核心就是先将整个数组拆分为只有一个元素的集合,合并时先将每个元素只有一个元素的集合开始合并,一直到整个数组合并完。
代码实现:
//归并排序的非递归写法
public static void mergeSortNonRecursion(int[] arr){
//最外层的循环表示每次合并的子数组的元素个数
for (int sz = 1; sz <= arr.length; sz += sz) {
//i表示每次合并的开始索引
//i + sz 就是右区间的开始索引,它 < arr.length说明还存在右区间
for (int i = 0; i + sz < arr.length; i += sz + sz) {
merge(arr,i,i+sz-1,Math.min(i+sz+sz-1,arr.length-1));
}
}
}可以看到迭代的写法和递归的思想是相反的,迭代是自底向上的,每次合并2个元素再每次合并4个、8个...
海量数据的排序处理
首先我们要知道外部排序的概念:排序过程需要在磁盘等外部存储进行的排序
假设现在待排序的数据有100G,但是内存却只有1G,如何排序这100G的数据呢?
因为内存中因为无法把所有数据全部放下,所以需要外部排序,归并排序是最常用的外部排序,步骤如下:
- 先将这100G的数据分别存储在200个文件中,文件存储在硬盘中,所以能存下这些文件。此时每个文件都是0.5
- 分别将这200个文件依次读取到内存中,使用任何一个内部排序算法对其排序,此时就可以得到200个已经有序的文件
- 分别对这200个文件进行 merge 操作,这200个小文件已经有序,每次取出这些文件的第一个元素放到内存中,内部排序取出的这200个元素,然后写回大文件的第一行。重复上述流程,直到200个文件的所有内容全部写回大文件即可
7. 快速排序
快排的时间复杂度为 nlog(N),其中,n就是数组的遍历,logN就是递归函数的调用次数(类似树结构)。
- 从待排序区间选择一个数,作为基准值(pivot),通常选择数组第一个元素;
- 遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值大的(可以包含相等的)放到基准值的右边;
- 采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度 == 1,代表已经有序,或者小区间 的长度 == 0,代表没有数据。
下图是遍历一次的过程,可以看到遍历完之后,左边都小于基准值,右边都大于基准值
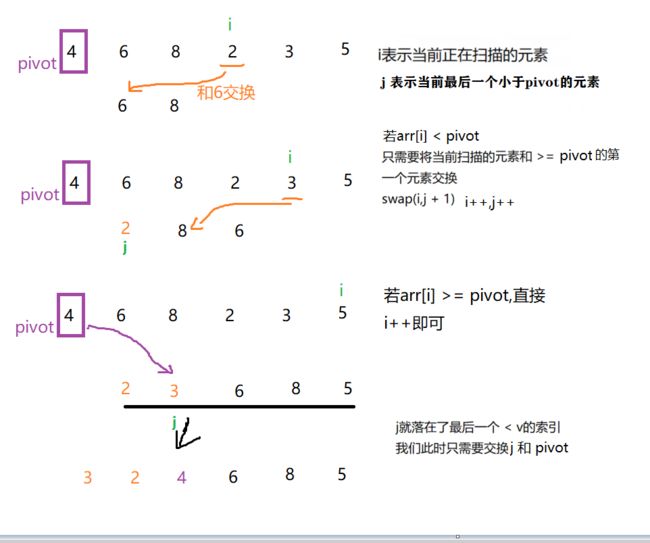
代码实现:
//快速排序
public static void quickSort(int[] arr){
quickSortInternal(arr,0,arr.length-1);
}
//在arr[l...r]区间进行快速排序
private static void quickSortInternal(int[] arr, int l, int r) {
if(l >= r){
return;
}
//先获取分区点
int p = partition(arr,l,r);
//递归在左右子区间重复
quickSortInternal(arr,l,p-1);
quickSortInternal(arr,p+1,r);
}
//在arr[l..r]区间上的分区函数,返回分区点的索引
private static int partition(int[] arr, int l, int r) {
//基准值
int v = arr[l];
int j = l;
for (int i = l+1; i <= r; i++) {
if(arr[i] < v){
swap(arr,j+1,i);
j++;
}
}
//将基准值和最后一个小于v的元素交换
swap(arr,l,j);
return j;
}
快速排序的优化
1.和归并排序一样,在小区间上我们可以使用插入排序来优化
2.关于基准值的选择,我们默认选择第一个元素,但是,当数组接近有序时,快排就退化为O(N^2),而且很容易栈溢出。
在极端情况下,若数组完全有序,选择第一个元素作为基准值,就会使左右分区严重不平衡,这就使二叉树退化为单支树。所以我们就可以使用随机选择的方法来确定基准值
何为栈溢出呢?一般来说,JVM的栈的深度大概在1万左右,就是调用次数大概在一万次。所以栈溢出就是JVM调用函数的次数超过了默认的深度
下面是随机选择基准值的代码:

3.几数取中法,一般是三数取中。在arr[left] 、arr[mid] 、arr[right]中选一个中间值作为基准值。该方法和随机选择的方法都是为了避免分区严重不平衡的问题
4.在有大量重复元素的情况下,快排依然会退化。极端情况下当所有元素都相等时,分区后没有小于基准值的数,所有元素都在右子区间,又出现了分区严重不平衡的情况,此时二叉树又退化成了单支树。这时我们就使用二路快排和三路快排来优化
二路快排
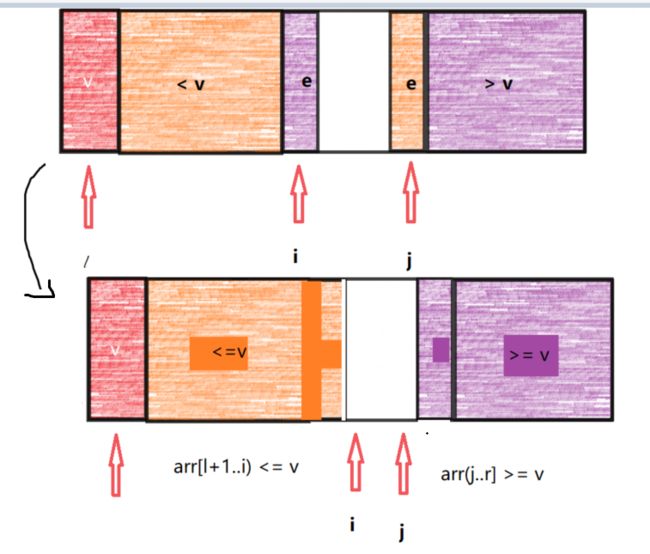
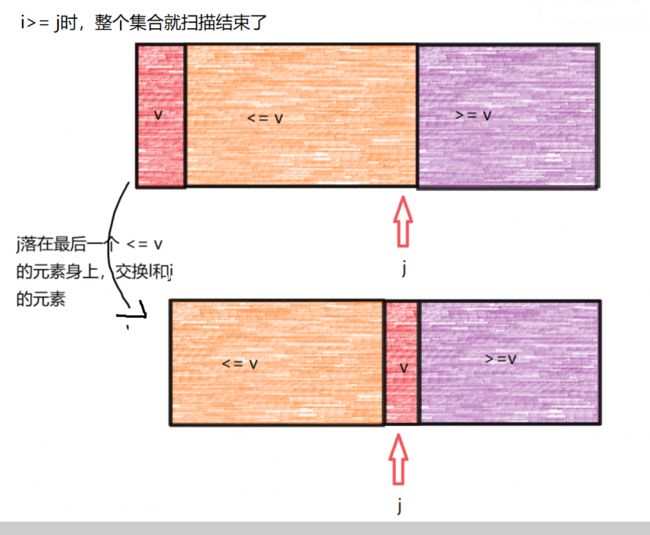
将相等的元素均分到左右两个子区间
- 我们现在使用两个变量 i和 j,i从前向后扫描碰到第一个arr[i] >= v的元素停止,j从后向前扫描碰到第一个arr[j] <= v的元素停止
- 交换 i和 j对应的元素,这样就可以把相等元素平均到左右两个子区间。
 代码实现:
代码实现:
//二路快排
public static void quickSort2(int[] arr){
quickSortInternal2(arr,0,arr.length-1);
}
private static void quickSortInternal2(int[] arr, int l, int r) {
if(r - l <= 15){
insertionSort(arr,l,r);
return;
}
int p = partition2(arr,l,r);
quickSortInternal2(arr,l,p-1);
quickSortInternal2(arr,p+1,r);
}
private static int partition2(int[] arr, int l, int r) {
int randomIndex = random.nextInt(l,r);
swap(arr,l,randomIndex);
int v = arr[l];
// arr[l + 1..i) <= v
// [l + 1..l + 1) = 0
int i = l + 1;
// arr(j..r] >= v
// (r...r] = 0
int j = r;
while (true) {
// i从前向后扫描,碰到第一个 >= v的元素停止
while (i <= j && arr[i] < v) {
i ++;
}
// j从后向前扫描,碰到第一个 <= v的元素停止
while (i <= j && arr[j] > v) {
j --;
}
if (i >= j) {
break;
}
swap(arr,i,j);
i ++;
j --;
}
// j落在最后一个 <= v的元素身上
swap(arr,l,j);
return j;
}
三路快排
在一次分区函数的操作中,将所有相等的元素都放在最终位置,只需要在小于v和大于v的子区间上进行快排,所有相等的元素就不再处理了。
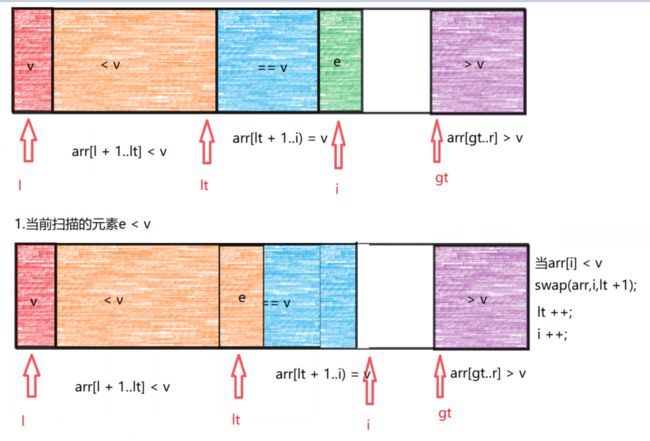
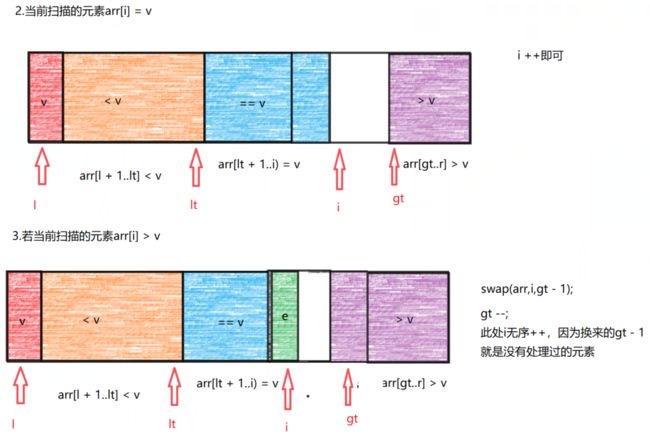

代码实现:
//三路快排
public static void quickSort3(int[] arr){
quickSortInternal3(arr,0,arr.length-1);
}
private static void quickSortInternal3(int[] arr, int l, int r) {
if (r - l <= 15) {
insertionSort(arr,l,r);
return;
}
int randomIndex = random.nextInt(l,r);
swap(arr,l,randomIndex);
int v = arr[l];
// 这些变量的取值,一定是满足区间的定义,最开始的时候,所有区间都是空
// arr[l + 1..lt] < v
// lt是指向最后一个 v
// gt是第一个 > v的元素
int gt = r + 1;
// i从前向后扫描和gt重合时,所有元素就处理完毕
while (i < gt) {
if (arr[i] < v) {
// arr[l + 1..lt] < v
// arr[lt + 1..i) == v
swap(arr,i,lt + 1);
i ++;
lt ++;
}else if (arr[i] > v) {
// 交换到gt - 1
swap(arr,i,gt - 1);
gt --;
// 此处i不++,交换来的gt - 1还没有处理
}else {
// 此时arr[i] = v
i ++;
}
}
// lt落在最后一个 < v的索引处
swap(arr,l,lt);
// arr[l..lt - 1] < v
quickSortInternal3(arr,l,lt - 1);
// arr[gt..r] > v
quickSortInternal3(arr,gt,r);
} 挖坑法
基本思路和交换一致,只是不再进行交换,而是进行赋值,但要注意挖坑法必须要先从后向前扫描
再从前向后扫描。因为在最开始我们存储了基准值的数,这样不会发生值丢失。
代码实现:
//挖坑法
private static int partition4(int[] array, int left, int right) {
int i = left;
int j = right;
int pivot = array[left];
while (i < j) {
while (i < j && array[j] >= pivot) {
j--;
}
array[i] = array[j];
while (i < j && array[i] <= pivot) {
i++;
}
array[j] = array[i];
}
array[i] = pivot;
return i;
}
快排的非递归实现
我们借助栈来实现,使用队列也是一样的,本质就是将递归的过程用栈代替了。
代码实现:
//借助栈来实现非递归分治快排
public static void quickSortNonRecursion(int[] arr){
Deque stack = new ArrayDeque<>();
// 栈中保存当前集合的开始位置和终止位置
int l = 0;
int r = arr.length - 1;
stack.push(r);
stack.push(l);
while (!stack.isEmpty()) {
// 栈不为空时,说明子区间还没有处理完毕
int left = stack.pop();
int right = stack.pop();
if (left >= right) {
// 区间只有一个元素
continue;
}
int p = partition(arr,left,right);
// 依次将右区间的开始和结束位置入栈
stack.push(right);
stack.push(p + 1);
// 再将左侧区间的开始和结束位置入栈
stack.push(p - 1);
stack.push(left);
}
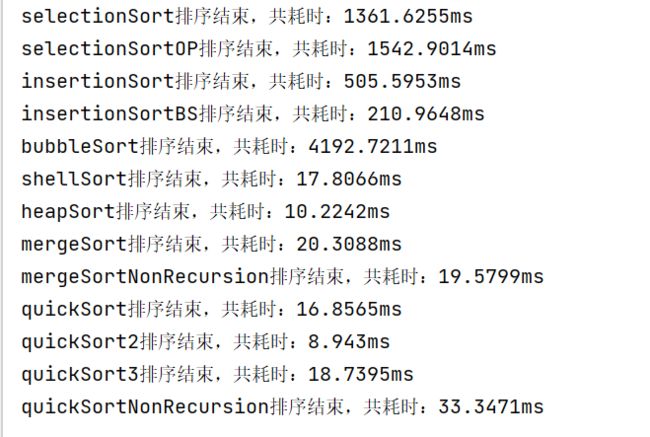
} 总结
//测试类
public class SortTest {
public static void main(String[] args) {
int n = 50000;
int[] arr = SortHelper.generateRandomArray(n, 0, Integer.MAX_VALUE);
int[] arrCopy1 = SortHelper.arrCopy(arr);
int[] arrCopy2 = SortHelper.arrCopy(arr);
int[] arrCopy3 = SortHelper.arrCopy(arr);
int[] arrCopy4 = SortHelper.arrCopy(arr);
int[] arrCopy5 = SortHelper.arrCopy(arr);
int[] arrCopy6 = SortHelper.arrCopy(arr);
int[] arrCopy7 = SortHelper.arrCopy(arr);
int[] arrCopy8 = SortHelper.arrCopy(arr);
int[] arrCopy9 = SortHelper.arrCopy(arr);
int[] arrCopy10 = SortHelper.arrCopy(arr);
int[] arrCopy11 = SortHelper.arrCopy(arr);
int[] arrCopy12 = SortHelper.arrCopy(arr);
int[] arrCopy13 = SortHelper.arrCopy(arr);
int[] arrCopy14 = SortHelper.arrCopy(arr);
//测试选择排序
SortHelper.testSort("selectionSort",arr);
//双向选择排序
SortHelper.testSort("selectionSortOP",arrCopy1);
//插入排序
SortHelper.testSort("insertionSort",arrCopy2 );
//折半插入排序
SortHelper.testSort("insertionSortBS",arrCopy3 );
//冒泡排序
SortHelper.testSort("bubbleSort",arrCopy4 );
//希尔排序
SortHelper.testSort("shellSort",arrCopy5);
//堆排序
SortHelper.testSort("heapSort",arrCopy6);
//归并排序
SortHelper.testSort("mergeSort",arrCopy7);
//非递归的归并排序
SortHelper.testSort("mergeSortNonRecursion",arrCopy8);
//快速排序
SortHelper.testSort("quickSort",arrCopy9);
//二路快排
SortHelper.testSort("quickSort2",arrCopy10);
//三路快排
SortHelper.testSort("quickSort3",arrCopy11);
//非递归的快排
SortHelper.testSort("quickSortNonRecursion",arrCopy12);
}
}