面试官:zookeeper集群的leader挂了怎么办
某天程序员小白参加面试:
几番苦战之后,面试进入白热化阶段。面试官大开大合,小白见招拆招。一时之间,难解难分,两人对拆数十回合不分胜负。说时迟,那时快,小白的左手像火焰一般炙热,右手像冰霜一样寒冷…

面试官:我看你简历上写了熟悉zookeeper,你项目里用zookeeper干什么了?
小白:主要用来做dubbo的注册中心、分布式锁以及统一配置等
面试官:那你熟悉zookeeper集群模型吗?
小白:zookeeper集群是一主多从的模型,节点分成三种角色:leader、follower和observer。leader负责写、follower和observer负责读。
(小白内心:面试官接下来该问我follower和observer的区别了)
面试官:你说zookeeper是一主多从,那么主挂掉了怎么办(单点故障)?
(小白内心:我勒个擦,怎么不按套路出牌。记得redis主从复制模型中,master挂掉之后是靠sentinel自动完成故障转移的。zookeeper好像没有sentinel…不过这可难不倒我)
小白:我们系统的zookeeper非常稳定,leader不会挂
面试官:

前置阅读
- zookeeper从入门到放弃
可靠性
从zookeeper官网上的描述可以知道,zookeeper自称是高可用的,像这种自带高可用的中间件可不多见。zookeeper一主多从的模型,leader只有一个,注定会成为单点故障。
leader挂了不可怕,可怕的是没有leader。古代皇帝驾崩之后,大臣通常会说这样一句话:国不可一日无君,然后劝太子早承大统。
zookeeper的做法也是一样,就是尽最快的速度,从存活的follower中选出一个新leader。那么现在问题来了,皇帝驾崩之前往往已经立了太子,或者由嫡长子自动继承。但是对zookeeper来说,不可能提前选好下一个预备leader,并且follower之间也没有嫡庶之分,换言之,每个follower的身份都是平等的。
zookeeper采用了ZAB算法来解决选举的问题。
ZAB
ZAB(Zookeeper Atomic Broadcast,zookeeper原子广播),ZAB协议用来保证zookeeper各个节点之间数据的一致性。
ZAB协议包括如下特点:
- follower节点上所有的写请求都转发给leader
- 写操作严格有序
- ZooKeeper使用改编的两阶段提交协议来保证各个节点的事务一致性
两阶段提交
二阶段提交(英语:Two-phase Commit)是指在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法。通常,二阶段提交也被称为是一种协议(Protocol)。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为: 参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
两阶段提交就是把提交分成2个阶段。预提交阶段和提交阶段
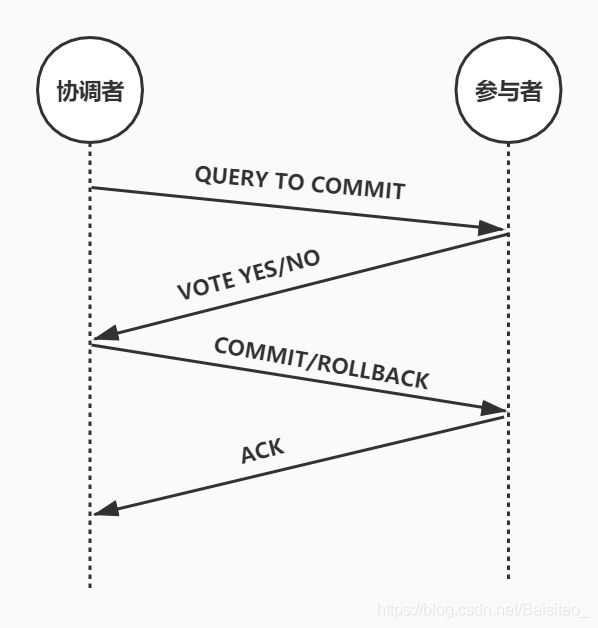
整个提交过程分为4个步骤
- 协调者询问所有的参与者是不是可以提交了
- 参与者回复
yes or no - 协调者收到所有的
yes之后执行commit否则执行rollback - 参与者执行完成后回复
ACK
zookeeper采用的是改编过的两阶段提交,就是在第三步的时候,不需要所有的参与者回复yes,只需要超过半数(刚好半数也不行)的参与者回复yes。之所以是超过半数而不是所有参与者回复yes,是为了避免少量的参与者出现单点故障或者网络波动导致协调者长时间收不到回复。
zookeeper集群的状态分为两种:正常状态和异常状态。也就是有leader(能提供服务)和没有leader(进入选举)
广播模式
广播模式就是指zookeeper正常工作的模式。正常情况下,一个写入命令会经过如下步骤被执行
- leader从客户端或者follower那里收到一个写请求
- leader生成一个新的事务并为这个事务生成一个唯一的
Zxid, - leader将这个事务发送给所有的follows节点
- follower节点将收到的事务请求加入到历史队列(history queue)中,并发送ack给leader
- 当leader收到大多数follower(超过法定数量)的ack消息,leader会发送commit请求
- 当follower收到commit请求时,会判断该事务的
Zxid是不是比历史队列中的任何事务的Zxid都小,如果是则commit,如果不是则等待比它更小的事务的commit
恢复模式
当leader故障之后,zookeeper集群进入无主模式,此时zookeeper集群不能对外提供服务,必须选出一个新的leader完成数据一致后才能重新对外提供服务。zookeeper官方宣称集群可以在200毫秒内选出一个新leader。
正常模式下的几个步骤,每个步骤都有可能因为leader故障而中断。但是恢复过程只与leader有没有commit有关。
首先看前三个步骤,只做了一件事,把事务发送出去。
如果事务没有发出去,所有follower都没有收到这个事务,leader故障了。所有的follower都不知道这个事务的存在,根据心跳检测机制,follower发现leader故障,重新选出一个leader。会根据每个节点Zxid来选择,谁的Zxid最大,表示谁的数据最新,自然会被选举成新的leader。如果Zxid都一样,表示在follower故障之前,所有的follower节点数据完全一致,此时选择myid最大的节点成为新的leader,因为有一个固定的选举标准会加快选举流程。新的leader选出来之后,所有节点的数据本身就是一致的,此时就可以对外提供服务。
假设新的leader选出来之后,原来的leader又恢复了,此时原来的leader会自动成为follower,之前的事务即使重新发送给新的leader,因为新的leader已经开启了新的纪元,而原先的leader中Zxid还是旧的纪元,自然会被丢弃。并且该节点的Zxid也会更新成新的纪元。
纪元的意思就是标识当前leader是第几任leader,相当于改朝换代时候的年号。
如果在leader故障之前已经commit,zookeeper依然会根据Zxid或者myid选出数据最新的那个follower作为新的leader。新leader与follower建立FIFO的队列, 先将自身有而follower缺失的事务发送给它,再将这些事务的commit命令发送给 follower,这便保证了所有的follower都保存了所有的事务、所有的follower都处理了所有的消息。
ZAB 协议确保那些已经在 Leader 提交的事务最终会被所有服务器提交。
ZAB 协议确保丢弃那些只在 Leader 提出/复制,但没有提交的事务。
总结
本文单单从zookeeper的角度解释了主从模式的数据一致性,而没有写paxos和ZAB算法中的一些概念。因为paxos算法确实难以理解,网上关于paxos算法的讲解也多如黄河之沙。并且关于paxos和zab,不同的人有不同的见解。若有兴趣,可自行查阅,博主就不误人子弟了。
参考
- https://zh.wikipedia.org/zh-hans/二阶段提交
- https://mp.weixin.qq.com/s/AE_2U5tUjEZSYoLovlcU6g
- https://zookeeper.apache.org/doc/r3.4.11/zookeeperInternals.html
扩展阅读
- https://zh.wikipedia.org/zh-cn/Paxos算法
- https://www.douban.com/note/208430424/
- https://www.bilibili.com/video/BV1TW411M7Fx