OCR文本检测-DBnet论文阅读笔记
文章目录
- 前言
- 摘要(Abstract)
- 1. 介绍(Introduction)
- 2. 相关工作(Related Work)
- 3. 方法(Methodology)
-
- 3.1 二值化(Binarization)
-
- 3.1 标准二值化
- 3.2 可微分二值化
- 3.2 自适应阈值(Adaptive threshold)
- 3.3 可变形卷积(Deformable convolution)
- 3.4 标签生成(Label generation)
- 3.5 优化(Optimization)
- 4. 实验(Experiments)
-
- 4.1 数据集(Datasets)
- 4.2 实现细节(Implementation details)
- 4.3 消融研究(Ablation study)
- 4.4 和之前方法比较(Comparisons with previous methods)
- 4.4 局限性(Limitation)
- 完结
前言
在项目中测试过EAST文本检测模型后,发现效果不太好,在搜索了现有文本检测模型后,都说DBnet模型比较优,而且像PaddleOCR, EasyOCR等比较成熟的OCR文本检测与识别工具都有使用,所以今天开始学习这个模型并做下笔记,方便以后复习。
论文:Real-time Scene Text Detection with Differentiable Binarization
提示:以下是本篇文章正文内容,下面案例可供参考
摘要(Abstract)
最近,基于分割的场景文本检测方法非常流行,主要是因为分割的结果可以更准确地描述如弯曲文字这种任意形状的文本。然而,二值化的后处理过程对于基于分割的文本检测是很重要的,它将基于分割方法产生的概率图转变为文本框(或称为文本区域)。
论文提出可微分二值化的方法(Differentiable Binarization, DB),在基于分割的文本检测网络中 DB 实现了二值化处理。基于 DB 模块的分割网络可以自适应设置二值化阈值,不仅简化了后处理过程,也提升了文本检测的性能。
论文在5个benchmark 数据集上进行性能验证,在检测准确性和检测速度上获得SOTA(state-of-the-art)。
实验结果:
在MSRA-TD500数据集上,网络backbone = ResNet-18, F-score=82.8, 62 FPS(frames per second)
1. 介绍(Introduction)
近年来,由于图像或视频理解,可视化搜索,自动驾驶,盲人辅助等广泛应用,场景图像中文本阅读成为比较活跃的研究领域。
作为场景文本阅读的一个关键部分-场景文本检测,它的主要任务是定位文本框或者每一个文本实例区域,由于场景文本一般具有不同尺度和形状,比如水平的,多方向和弯曲文本,这些因素的存在让文本检测任务面临挑战。基于分割的场景文本检测备受关注,这种方法可以检测出任意形状的文本,这主要受益于这一方法是在像素级(pixel-level)进行预测并输出结果。然而,大多数基于分割的方法都要进行后处理(post processing),这主要是将像素级预测结果分组到要检测的文本实例中,这将在推理过程中带来额外的时间消耗,比如PSENet和Pixel embedding。
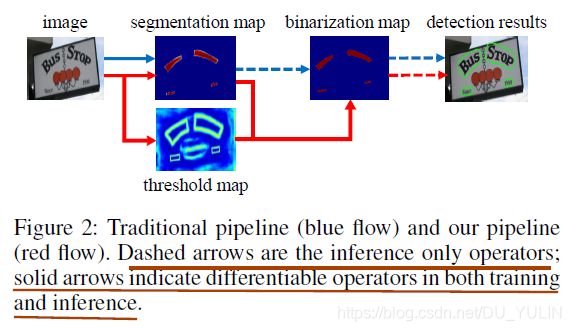
大多数文本检测模型都使用相似的后处理流水线,如图Fig.2所示(蓝色箭头)。
- 使用固定阈值将基于分割模型的输出结果-概率特征图进行阈值分割,生成二值图;
- 应用一些如聚类的启发式方法将像素分组到文本实例中。
如Fig.2 蓝色虚线所示,二值化过程仅存在于推理阶段,不包含在训练过程中。论文则将二值化方法加入到训练阶段进行联合优化(个人认为,将二值化过程加入训练过程中,是将二值化结果作为梯度更新的依据,这样使训练出来的网络预测结果更准确)。按照这种方法,图像中每个位置的阈值都可以被预测,用这个预测的阈值能够更准确地区分图像中地文本像素于非文本像素。然而,标准地二值化方法是不可微地(不可进行梯度更新),论文在基于分割地训练网络中应用可微的二值化近似函数(DB)。
论文的主要贡献是提出了可微分的DB模块,将二值化成为CNN网络中end-to-end 可训练的这样一个过程。论文通过将一个简单的语义分割网络与DB模块组合在一起,提出了一个性能鲁棒,运行速度快的场景文本检测器。
和之前基于分割的SOTA方法相比,论文提出的检测器有如下几点明显优势:
- 在5个场景文本benchmark数据集上有更好的性能,包括水平,多方向和弯曲文本;
- 比之前的方法更快,因为DB模块极大简化了后处理过程;
- 当使用轻量级backbone时,DB也能很好地工作,比如ResNet-18;
- 因为DB模块可以在推理阶段被移除并且不影响性能,因此在测试时没有多余的内存或时间消耗。
2. 相关工作(Related Work)
场景文本检测模型大致分为两类:基于回归的方法和基于分割的方法。
基于回归的方法:
基于回归方法的模型都是直接回归计算出包含文本实例的包围框(文本框),比如TextBoxes, TextBoxes++, DMPNet等都属于这一类模型。基于回归的方法通常偏爱简单的后处理方法比如非极大值抑制(NMS)。但是,这类方法通常在表示非常规形状文本的包围框上精度受限,比如弯曲文本。
基于分割的方法:
基于分割的方法通常是结合像素级预测(pixel-level)和后处理算法来获得包围框。
2016年 Zhang等人使用语义分割和基于最大稳定极值区域(MSER)算法进行多方向文本检测;…(这里省略其它模型和方法); PSENet和SAE为分割结果提出新的后处理算法,这导致推理速度更慢。然而,论文通过将二值化过程融入训练阶段,不仅提升了分割的性能(更好的分割结果),而且没有导致推理速度变慢。(个人认为,论文输出的概率图或二值图可直接判断像素是否为文本像素,不需要应用一些启发式方法来分组文本像素,不过还要通过后续阅读来确认)。
快速场景文本检测方法聚焦于精度和推理速度这两方面。TextBoxes, TextBoxes++,SegLink, RRD这些模型沿用了SSD检测框架实现了快速文本检测;EAST应用PVANet提高了检测速度。但是上述大部分模型无法处理非常规形状文本,比如弯曲文本。和之前快速场景文本检测器相比,论文提出的方法不仅运行速度快(推理速度)而且可以检测任意形状的文本实例。
3. 方法(Methodology)
论文提出的模型架构如图Fig.3所示:
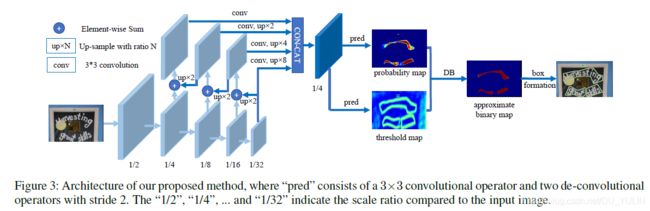
模型运行过程如下所示:
- 将输入图像输入到模型backbone:特征金字塔模型;
- 金字塔模型每层输出的特征图都经过上采样得到相同宽高的特征图,然后将金字塔模型所有经过上采样后的特征图按照通道方向拼接产生特征图 F F F;
- 特征图 F F F被用来预测输出概率图 P P P和阈值图 T T T。
- 通过 P P P和 F F F可以计算出近似二值图 B ^ \hat{B} B^;
在模型训练阶段,对概率图,阈值图和近似二值图进行监督(supervision),并且概率图和近似二值图使用相同的监督(个人理解,这里的监督想要表达的应该是计算梯度值或者说是损失值)。
在模型推理阶段,可以让近似二值特征图或者概率特征图经过一个生成文本框的模块(box formulation boxes)来获得包围框。(这个生成文本框的模块要做哪些工作,这是影响推理速度的关键)
3.1 二值化(Binarization)
3.1 标准二值化
对分割网络输出的概率特征图 P ∈ R H × W P\in R^{H\times W} P∈RH×W,其中 H H H表示特征图的高度, W W W表示特征图的宽度。通常二值化过程如下公式所示:
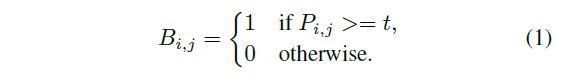
其中, t t t表示预先定义的阈值, ( i , j ) (i,j) (i,j)表示特征图中像素的坐标。
3.2 可微分二值化
从公式(1)可以知道,标准二值化是不可微分的(阶跃函数,非线性函数),因此无法直接将二值化过程加入到分割网络中进行训练。为了解决这一问题,论文提出一种近似阶跃函数的二值化方法:

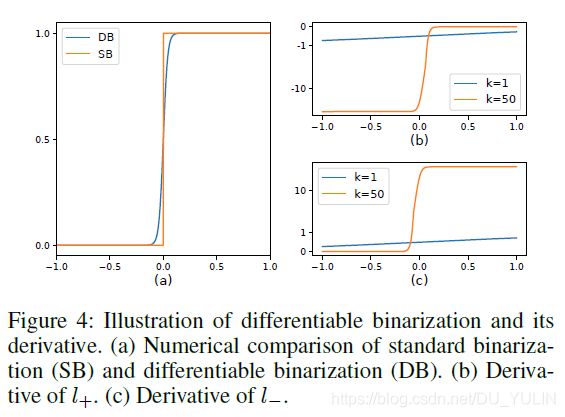
公式(2)中, B ^ \hat{B} B^表示近似二值图, T T T表示分割网络预测的阈值图, k k k表示放大因子,根据经验一般设为50。该近似阶跃函数性能近似阶跃函数,但是可微分,如图Fig.4所示。因此,可以在训练网络中进行优化。
该可微的二值化过程不仅能够帮助找出背景中的文本区域,也能分割出紧密结合的文本实例,Fig.7列出了一些例子。

借助梯度反向传播来解释为什么DB模块可以提高检测性能。这里以二值交叉熵损失为例。这里DB函数定义为 f ( x ) = 1 1 + e − k x f(x)=\frac{1}{1+e^{-kx}} f(x)=1+e−kx1, 其中 x = P i , j − T i , j x=P_{i,j}-T_{i,j} x=Pi,j−Ti,j, l + l_{+} l+表示正样本(文本)损失值, l − l_{-} l−表示负样本(非文本)损失值,计算公式如下所示:
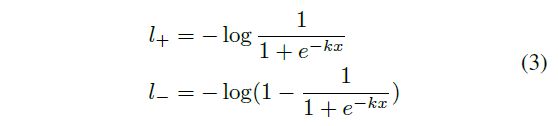
应用链式法则求得损失值的微分:

损失函数梯度值如图Fig.4所示。从微分结果可以看出:
(1)梯度值随着 k k k的增大而增大;
(2)梯度值的增大对于大多数的错误预测区域意义重大( L + : x < 0 L_{+}: x<0 L+:x<0, L − : x > 0 L_{-}: x>0 L−:x>0),因此利用该损失函数的优化策略对生成更有区分性的预测结果有帮助。
而且,从 x = P i , j − T i , j x=P_{i,j}-T_{i,j} x=Pi,j−Ti,j看出,用于区分文本区域与非文本区域的概率特征图 P P P的梯度受阈值图 T T T的影响并需要重新调整。(不理解:这句话要表达什么?)
3.2 自适应阈值(Adaptive threshold)
从外观上来看,Fig.3上阈值图与2018年 Xue, Lu和Zhan提出的文本边界特征图(text border map)相似,然而阈值图的动机和用途与其相比却不同。Fig.6展示了有或没有监督的阈值图可视化结果。阈值图能够用来突出显示文本边界区域即便是没有监督的阈值图也有相同的作用。因此,在阈值图上应用类边界监督能够获得更好的结果。后面实验章节进行了监督的消融研究。论文的阈值图用来作为二值化的阈值,而上文提到的文本边界特征图则是用来分割文本实例。

3.3 可变形卷积(Deformable convolution)
可变形卷积可为模型提供一种灵活的(flexible)感受野,它对于具有比较极端纵横比的文本实例是及其有好处的。论文将这种卷积应用于所有的 3 × 3 3\times3 3×3的卷积层,ResNet-18或ResNet-50中的conv3, conv4和conv5中。(这里,可能看源码会比较好)。
3.4 标签生成(Label generation)
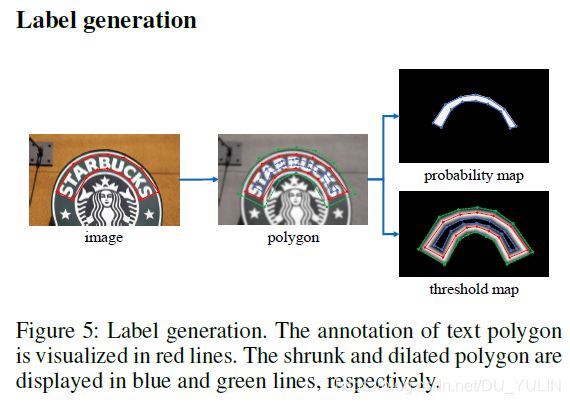
论文中概率图标签生成策略是受到PSENet中的启发。给一个文本图像,每一个文本区域的多边形由分割几何表示:
![]()
公式中 n n n表示多边形顶点数,不同的数据集有不同的顶点数,比如在ICDAR2015数据集有4个顶点,在CTW1500数据集则有16个。使用一种叫做Vatti clipping的算法来收缩多边形区域( G G G,Fig.5中红线区域)到Fig.5中蓝线区域( G s G_{s} Gs),即文本区域。收缩的偏移量 D D D是通过多边形区域 G G G的周长 L L L和面积 A A A计算而来:
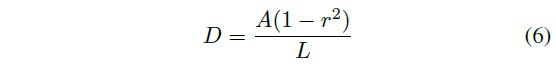
公式中, r r r表示收缩比例,经验值为0.4。
相似的处理过程,可以为阈值图生成标签。首先将多边形区域 G G G膨胀到 G d G_{d} Gd,即Fig.5中绿线区域,使用的膨胀偏移量也是 D D D。论文将 G s G_{s} Gs和 G d G_{d} Gd的间隙作为文本区域的边界,然后阈值图的标签可通过计算这个间隙边界到 G G G最小距离来确定。
3.5 优化(Optimization)
损失函数 L L L可表示为概率图损失 L s L_{s} Ls,二值图损失 L b L_{b} Lb和阈值图损失 L t L_{t} Lt这三者的加权和:
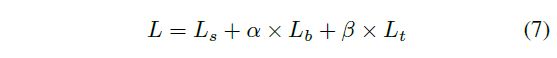
公式中,根据经验值, α = 1.0 \alpha=1.0 α=1.0, β = 10 \beta=10 β=10。
对二值图和概率图损失函数论文使用二值交叉熵(binary cross-entropy, BCE)。为了解决正负样本不平衡的问题,在BCE中使用困难样本挖掘的方法(hard negative mining)- 对困难负样本采样(负样本多于正样本)。

公式中 S l S_{l} Sl表示样本集合,该集合中正负样本比率为 1 : 3 1:3 1:3。
论文中阈值图的损失函数是所有膨胀文本多边形 G d G_{d} Gd内预测值于标签值间 L 1 L1 L1距离和表示。

这里 R d R_{d} Rd表示膨胀文本区域 G d G_{d} Gd内所有像素点索引集合, y ∗ y^{*} y∗表示阈值图的标签值。
在推理阶段,既可以用概率图也可以用近似二值图来生成文本框,它们输出的结果几乎完全相同。但是出于效率的考量,论文使用了概率图并且删除了二值化的过程。由概率图产生文本框的过程主要分为三步:
(1)由常量阈值( 0.2 0.2 0.2)对概率图进行二值化,得到二值化特征图;
(2)从二值化特征图中获得连接的文本区域,即收缩的文本区域 G s G_{s} Gs;
(3)用Vatti clipping算法中的一个偏移量 D ′ D^{'} D′对收缩的文本区域进行膨胀,即生成标签文本时 G → G s G\rightarrow G_{s} G→Gs的逆过程。 D ′ D^{'} D′可由下式计算:

公式中, A ′ A^{'} A′表示收缩文本区域的面积, L ′ L^{'} L′表示收缩文本区域的周长, r ′ = 1.5 r^{'}=1.5 r′=1.5。
(从这里看出,论文的推理阶段框确实移除了基于启发式聚类方法生成文本框,个人认为这是推理速度提高的关键点)。
4. 实验(Experiments)
4.1 数据集(Datasets)
SynthText: 合成数据集,包括 800 k 800k 800k图像,由 8 k 8k 8k背景图像合成,这个数据集被用于预训练;
MLT-2017:多种语言数据集。包含 7200 7200 7200张训练图像, 1800 1800 1800张验证图像, 9000 9000 9000张测试图像。论文使用该训练集和验证集进行微调。
ICDAR 2015: 包含 1000 1000 1000张训练图像, 500 500 500张测试图像,由谷歌眼镜拍摄获得,分辨率为 720 × 1280 720\times1280 720×1280。文本实例的标签为单词级别。
MSRA-TD500: 包含中英文的多语言数据集,有 300 300 300张训练图像和 200 200 200张测试图像。文本标签为文本行级别。借鉴之前的经验,论文加入了从HUST-TR400数据集中的 400 400 400张训练图像。
CTW1500:主要包含弯曲文本的数据集,由 1000 1000 1000张训练图像和 500 500 500张测试图像组成,文本标签是文本行级别的。
Total-Text:包含各种形状的文本,比如水平的,多方向的以及弯曲的文本,由 1255 1255 1255张训练图像和 300 300 300张测试图像,文本标签是单词级别的。
4.2 实现细节(Implementation details)
首先在SynthText数据集进行预训练并迭代 100 k 100k 100k。然后在想要训练的数据集上进行微调, e p o c h = 1200 epoch=1200 epoch=1200;训练的 b a t c h s i z e = 16 batch size=16 batchsize=16;使用多项式学习率调整策略,即当前迭代学习率:初始学习率 ∗ ( 1 − i t e r m a x _ i t e r ) p o w e r *(1-\frac{iter}{max\_iter})^{power} ∗(1−max_iteriter)power。论文中初始学习率为 0.007 0.007 0.007, p o w e r = 0.9 power=0.9 power=0.9。权重衰减值为 0.0001 0.0001 0.0001,动量值为 m o m e n t u m = 0.9 momentum=0.9 momentum=0.9。 m a x _ i t e r max\_iter max_iter表示最大迭代次数,根据最大 e p o c h s epochs epochs计算。
训练数据增强操作包括:
(1)随机旋转,旋转角度范围: ( − 1 0 ∘ , 1 0 ∘ ) (-10^{\circ},10^{\circ}) (−10∘,10∘);
(2)随机裁剪;
(3)随机翻转;
为了更好的训练效率,所有的图像的分辨率要调整到 640 × 640 640\times640 640×640。
在推理阶段,要保证测试图像的纵横比,根据数据集设置合理的图像高度来调整输入图像。论文推理速度是在 b a t c h s i z e = 1 batch size=1 batchsize=1,单个1080ti GPU,单线程测试。推理时间消耗包括网络前向运行和后处理两类,并且后处理时间大约占总时间的 30 % 30\% 30%。
4.3 消融研究(Ablation study)
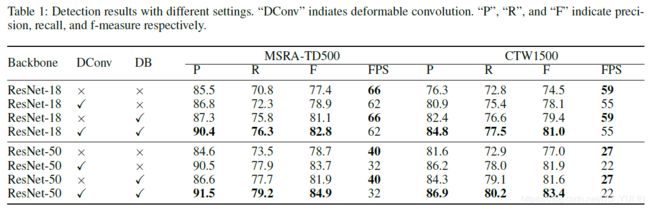
在MSRA-TD500数据集和CTW1500数据集进行论文提出的DB模块,可变形卷积(deformable convolution)和不同的backbones有效性研究,如Tab.1所示。
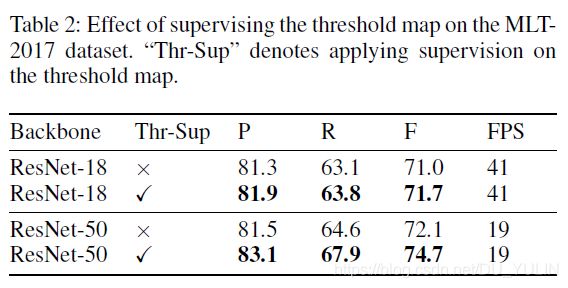
论文还进行了对阈值图监督的研究,结果如Tab.2所示:
4.4 和之前方法比较(Comparisons with previous methods)
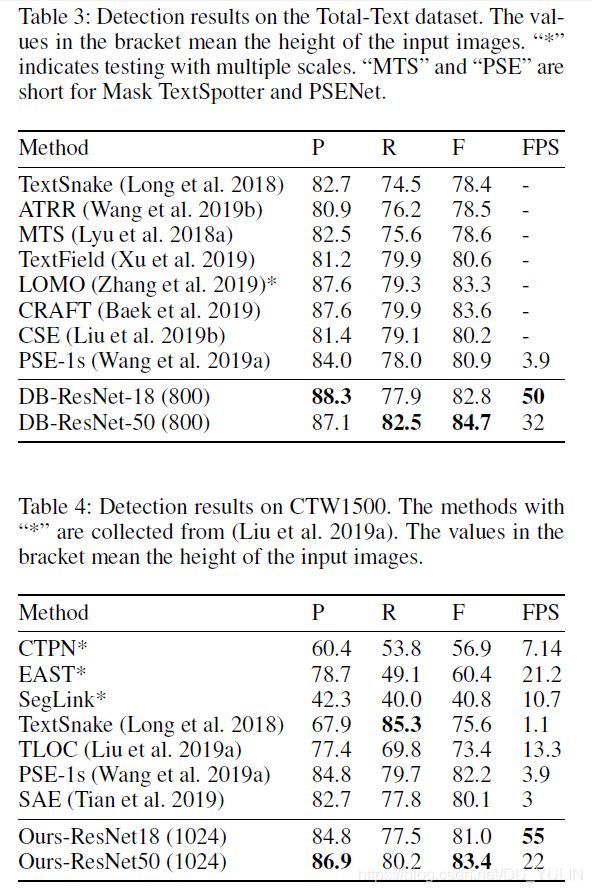
弯曲文本检测:在Total-Text和CTW1500数据集上验证论文方法的形状鲁棒性,结果如表Tab.3 和Tab.4所示:
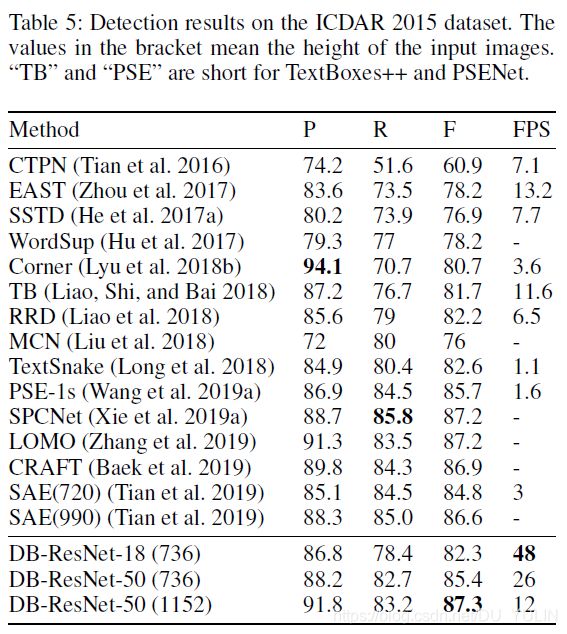
多方向文本检测: 数据集 ICDAR2015包含多方向文本,有很多小的,低分辨率的文本实例,检测结果如Tab.5所示。
多语言文本检测:论文提出的方法对多语言文本检测也是很鲁棒的,如Tab.6和Tab.7所示。
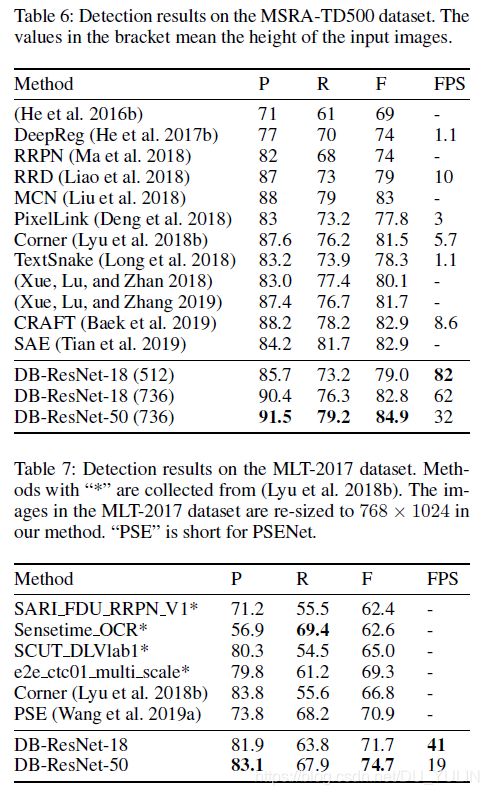
4.4 局限性(Limitation)
论文方法无法处理文本嵌套问题(text inside text),即一个文本位于另一个文本的里面。这是基于分割方法的场景文本检测器的“通病”。
完结
到这里,论文阅读就结束了,但还是有些不确定的地方,比如推理速度比之前方法更快,论文中解释的不是很清楚,这需要阅读其它方法的论文和本论文源码来进一步确认。当然,如果有同学能够解答,万分感谢了!