fastai 图像分类
Fastai is a high level deep learning library built on top of PyTorch. Jeremy Howard has recently introduced a newer version of the library along with a very handy, beginner-friendly book and a course. I was pretty surprised at its abstraction level, which helps you to create state-of-the-art models in minutes, without having to worry about the math behind it.
Fastai是建立在PyTorch之上的高级深度学习库。 杰里米·霍华德(Jeremy Howard )最近推出了该库的较新版本,以及一本非常方便,对初学者友好的书和一门课程。 我对它的抽象级别感到非常惊讶,它可以帮助您在几分钟内创建最新模型,而不必担心其背后的数学原理。
This article was written with total beginners in mind, and you would be able to follow it even if you have little coding experience. After reading this article you will be in a position to write a piece of code from scratch which can identify your favorite superhero or even recognize the animal by the sound it makes.
本文是针对初学者的,即使您很少有编码经验,您也可以继续阅读。 阅读本文后,您将可以从头开始编写一段代码,该代码可以识别您喜欢的超级英雄,甚至可以通过发出的声音识别动物。
Here’s a snapshot of the outcome of the mask classifier I’ve trained using little training data, few lines of code, and a few minutes of training on a GCP cluster Click here to setup your own FastAI GPU VM for *free
这是我在GCP集群上使用很少的训练数据,很少的代码行和几分钟的训练就得到的口罩分类器结果的快照。单击此处免费设置自己的FastAI GPU VM

In order to achieve this result firstly, we need to find faces in the image also known as localization, then classify each face and draw a colored bounding box according to the category (green: with_mask, red: no_mask, yellow: mask_worn_improperly) it belongs. Today lets understand the second part of the problem multi-class image classification
为了获得此结果,首先,我们需要在图像中找到人脸,也称为本地化,然后对每个人脸进行分类,并根据其所属的类别(绿色:with_mask,红色:no_mask,黄色:mask_worn_improperly )绘制彩色边框。 。 今天让我们了解问题的第二部分多类图像分类
Project code is available here
项目代码在这里
I will explain some basic concepts of deep learning and computer vision while we write some code. I highly recommend you to run the code line by line on a jupyter notebook as we understand the ideas behind the abstract functions
在编写一些代码时,我将解释一些深度学习和计算机视觉的基本概念。 我强烈建议您在jupyter笔记本上逐行运行代码,因为我们了解抽象函数背后的思想
处理数据(Processing the data)
The library is split up into modules, we primarily have tabular, text, and vision. Our problem for today will involve vision so let’s import all the functions which we are gonna need from the vision library
该库分为多个模块,主要有表格,文本和视觉。 今天我们的问题将涉及视觉,因此让我们从vision库中导入我们需要的all功能
In [1]: from fastai.vision.all import *Just like how we learn to identify objects by observing images our computer to needs data to recognize images. For mask detection I’ve curated a labeled dataset collected from kaggle and other sources, you may download it from here
就像我们通过观察图像学会识别物体一样,我们的计算机需要数据来识别图像。 为了检测遮罩,我整理了从kaggle和其他来源收集的带标签的数据集,您可以从此处下载
We store the path where our dataset resides. Path returns apathlib object which can be used to perform some file operations very easily
我们存储数据集所在的路径。 Path返回一个pathlib对象,该对象可用于非常轻松地执行一些文件操作
In [2]: DATASET_PATH = Path('/home/kavi/datasets')Before we train our model (teach our algorithm to recognize images) we first need to tell it a few things
在训练模型(教我们的算法识别图像)之前,我们首先需要告诉一些事情
- What is the expected input and output? What is the problem domain? 预期的输入和输出是什么? 什么是问题域?
- Where is the data located and how it is labeled? 数据位于何处以及如何标记?
- How much data do we want to keep it aside to evaluate the performance of the model? 我们要保留多少数据以评估模型的性能?
- Do we need to transform the data? If so how? 我们需要转换数据吗? 如果可以,怎么办?
Fastai has this super flexible function called DataBlock which take inputs to the above questions and prepares a template
Fastai具有称为DataBlock超级灵活功能,该功能将输入上述问题并准备模板
In [3]: mask_datablock = DataBlock(
get_items=get_image_files,
get_y=parent_label,
blocks=(ImageBlock, CategoryBlock),
item_tfms=RandomResizedCrop(224, min_scale=0.3),
splitter=RandomSplitter(valid_pct=0.2, seed=100),
batch_tfms=aug_transforms(mult=2)
)get_image_filesfunction grabs all the image file locations recursively in the given path and returns them, this way we tell fastai where toget_itemsget_image_files功能抓住所有的图像文件中给出的路径递归地点和回报他们,这样我们就告诉fastai哪里get_itemsIn our dataset I’ve placed the images in separate folders named according to the category,
parent_labelfunction returns the parent directory of the file according to the path在我们的数据集中,我将图像放置在根据类别命名的单独文件夹中,
parent_label函数根据路径返回文件的父目录
eg : parent_label('/home/kavi/datasets/with_mask/1.jpg') => 'with_mask'
例如: parent_label('/home/kavi/datasets/with_mask/1.jpg') =>' with_mask'
You may write your own function according to how your data is labeled
您可以根据数据的标签方式编写自己的函数
After knowing the file paths of the input images and target labels we need to preprocess the data based on the type of problem. Sample pre-processing steps for images includes creating images from file paths using
Pillowand converting them into a tensor在了解了输入图像和目标标签的文件路径之后,我们需要根据问题的类型对数据进行预处理。 图像的示例预处理步骤包括使用
Pillow从文件路径创建图像并将其转换为张量
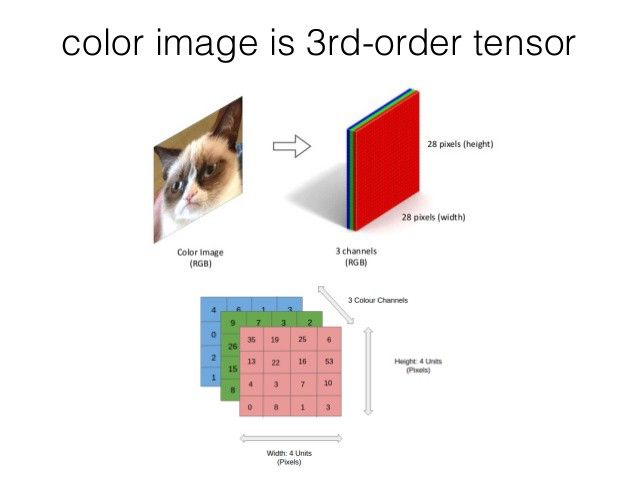
如何在我们的PC中显示图像?(How an image is represented in our PC?)
Every image is a matrix of pixel intensities. Each value ranges from 0 –255. 0 being the darkest and 255 being the brightest intensity of respective channel
每个图像都是像素强度的矩阵。 每个值的范围是0 –255。 0为最暗,255为最亮
A color image is a 3 layered matrix / 3rd order tensor. Each layer comprises Red, Green, Blue intensities whereas a black and white picture is a 1-D matrix
彩色图像是3层矩阵/ 3阶张量。 每层包括R ed, G reen, B lue强度,而黑白图片是一维矩阵
We pass a tuple (input_transformation, output_transformation) of type TransformBlock to blocks In our problem we need to predict a category for an image hence we pass (ImageBlock, CategoryBlock) If suppose you want to predict the age of a person based on his picture you would need to pass (ImageBlock, RegressionBlock)
我们将TransformBlock类型的元组(input_transformation, output_transformation)传递给blocks在我们的问题中,我们需要预测图像的类别,因此我们传递(ImageBlock, CategoryBlock)如果假设您要根据某人的图片预测其年龄,需要通过(ImageBlock, RegressionBlock)
Deep learning models work best when all the images are of the same size, also they learn quicker when the resolution is lower. We will tell how to rescale the images by passing a suitable resize function to
item_tfmsand this function will be applied to each image当所有图像的大小相同时,深度学习模型的效果最佳,而在分辨率较低时,深度学习模型的学习速度也会更快。 我们将通过将适当的调整大小函数传递给
item_tfms来说明如何调整图像的缩放item_tfms并且此函数将应用于每个图像

Fastai provides various resizing methods: Crop, Pad or Squish. Each of them is somewhat problematic. Sometimes we might even end up losing some critical information just like in the third image after the center crop
Fastai提供了各种调整大小的方法:裁切,填充或挤压。 他们每个人都有些问题。 有时我们甚至可能会丢失一些关键信息,就像中心裁剪后的第三张图片一样
We can use RandomResizedCrop to overcome this issue. Here we randomly select a part of the picture and train the model for a couple of epochs (One complete pass through all the images in the dataset) covering most regions of every picture. min_scale determines how much of the image to select at minimum each time.
我们可以使用RandomResizedCrop来解决此问题。 在这里,我们随机选择图片的一部分,并训练几个涵盖每个图片大部分区域的时期(一次完整遍历数据集中的所有图片)的模型。 min_scale决定每次至少选择多少图像。

RandomResizedCrop(224, min_scale=0.3) RandomResizedCrop(224, min_scale=0.3)调整图像大小
A model accuracy assessment on the training dataset would result in a biassed score and may lead to poor performance on unseen data. We need to tell our
DataBlockAPI to set aside some of the pre-processed data to evaluate the performance of the model. The data which the algorithm sees is called training data and the data kept aside is called validation data. Often the datasets will have validation set defined, but in our case we don't have one so we need to pass a split function tosplitter在训练数据集上进行模型准确性评估将导致分数出现偏差,并可能导致看不见的数据表现不佳。 我们需要告诉我们的
DataBlockAPI预留一些预处理数据以评估模型的性能。 算法看到的数据称为训练数据,保留的数据称为验证数据。 通常,数据集会定义验证集,但是在我们的情况下,我们没有验证集,因此我们需要将split函数传递给splitter
Fastai has a couple of split functions, lets use RandomSplitter for today’s problem valid_pct will determine what fraction of training data needs to set aside and seed will make sure that the same random images are set aside always
Fastai有几个分割函数,让我们使用RandomSplitter解决今天的问题valid_pct将确定需要保留训练数据的哪一部分, seed将确保始终保留相同的随机图像
Having a diverse data set is crucial to the performance of any deep learning model. So what do you do if you don’t have the appropriate amount of data? We generate new data based on existing data this process is called data augmentation
拥有多样化的数据集对于任何深度学习模型的性能至关重要。 那么,如果没有足够的数据量该怎么办? 我们根据现有数据生成新数据,此过程称为数据扩充
Data augmentation refers to creating random variations of our input data, such that they appear different, but do not actually change the meaning of the data. — Fastbook
数据扩充是指创建输入数据的随机变体,以使它们看起来有所不同,但实际上并没有改变数据的含义。 —快速手册

The above images are generated from a single picture of teddy. In the real world, we often have to make predictions on unseen data, the model will perform poorly if it just memorizes the training data (overfitting), rather it should understand the data. Augmenting the data is proven helpful in improving the performance of the models in many cases
以上图像是从一张泰迪熊的图片生成的。 在现实世界中,我们经常需要对看不见的数据进行预测,如果该模型仅记住训练数据(过拟合),而该模型应该理解该数据,则该模型的性能将很差。 在许多情况下,增强数据被证明有助于提高模型的性能
In fastai we have a predefined function aug_transforms which performs some default image transforms such as flipping, altering the brightness, skewing, and few others. We pass this function to batch_tfms and the interesting thing to note is that these transforms are performed on a GPU (if available)
在fastai中,我们有一个预定义的函数aug_transforms ,它执行一些默认的图像转换,例如翻转,更改亮度,倾斜等。 我们将此函数传递给batch_tfms ,值得注意的是这些转换是在GPU上执行的(如果有的话)
DataBlock holds the list instructions which will be performed on our dataset. This acts as a blueprint to create a DataLoader which takes our dataset path and apply the pre-processing transforms on the images as defined by the DataBlock object and load them into a GPU. After loading the data batch_tfms will be applied on the batch. The default batch size is 64, you may increase/decrease based on your GPU memory by passing bs=n to dataloders function
DataBlock包含将在我们的数据集上执行的列表指令。 这充当创建DataLoader的蓝图,该DataLoader采取我们的数据集路径,并对DataBlock对象定义的图像进行预处理转换,然后将其加载到GPU中。 加载后,数据batch_tfms将应用于该批处理。 默认批处理大小为64,您可以通过将bs=n传递给dataloders函数来基于GPU内存增加/减少
Tip:
!nvidia-smicommand can be executed in your notebook anytime to know your GPU usage details. You may restart the kernel to free the memory提示:
!nvidia-smi命令可以随时在笔记本中执行以了解您的GPU使用情况详细信息。 您可以重新启动内核以释放内存
In[10]: dls = mask_datablock.dataloaders(DATASET_PATH)dls is a dataloader object which holds training and validation data. You may have a look at our transformed data using dls.show_batch()
dls是一个数据加载器对象,其中包含训练和验证数据。 您可以使用dls.show_batch()查看我们转换后的数据
训练我们的面罩分类器模型(Training our mask-classifier model)
A model is a set of values also known as weights that can be used to identify patterns. Pattern recognition is everywhere, in living beings it's a cognitive process that happens in the brain without us being consciously aware of it. Much as how we learn to recognize colors, objects, and letters as a child by staring at them. Training a model is determining the right set of weights which can solve a particular problem, in our case to classify an image into 3 categories: with_mask, without_mask, mask_weared_incorrect
模型是一组值,也称为权重,可用于识别模式。 模式识别无处不在,在生物中,这是大脑中发生的一种认知过程,而我们没有意识地意识到它。 就像我们如何通过凝视它们来学习如何识别颜色,物体和字母一样。 训练模型是确定可以解决特定问题的正确权重集,在我们的案例中,将图像分为三类: with_mask,without_mask,mask_weared_incorrect
如何快速训练模型? (How to train models quickly?)
As a grown-up adult, we can learn to recognize objects almost instantly this is because we have been learning patterns all the way since we were born. Initially, we have learned to recognize colors, then simple objects like balls, flowers. Later after few years, we were able to recognize persons and other complex objects. Similarly in machine learning, we have pre-trained models that have been trained to solve a similar problem and can be modified to solve our problem
作为成年人,我们几乎可以立即学会识别物体,这是因为自出生以来我们就一直在学习模式。 最初,我们学会了识别颜色,然后识别诸如球,花之类的简单对象。 几年后,我们得以识别人和其他复杂物体。 同样地,在机器学习中,我们已经预训练了模型,这些模型已经过训练以解决类似的问题,并且可以进行修改以解决我们的问题
Using a pretrained model for a task different to what it was originally trained for is known as transfer learning — Fastbook
使用预训练模型任务不同的是什么它最初训练被称为迁移学习- Fastbook
resnet34 is one such model trained on the ImageNet dataset which contains around 1.3 million images and can classify into 1000’s of image categories. In our problem, we have only 3 categories so we use the initial layers that are useful to recognize basic patterns such as lines, corners, simple shapes and then retrain on the final layers
resnet34是在ImageNet数据集上训练的一种这样的模型,其中包含约130万张图像,并且可以分类为1000幅图像类别。 在我们的问题中,我们只有3个类别,因此我们使用初始层,这些初始层可用于识别基本模式(例如线,角,简单形状),然后在最终层上进行重新训练
In[11]: learn = cnn_learner(dls, resnet34, metrics=error_rate)Fastai offers a cnn_learner function that is particularly useful in the training of computer vision models. Which takes DataLoader object dls, pre-trained model resnet34 (here 34 mean we have 34 layers), and a metric error_rate which calculates the percentage of images that are classified incorrectly on validation data
Fastai提供了一个cnn_learner函数,该函数在计算机视觉模型的训练中特别有用。 它使用DataLoader对象dls ,经过预训练的模型resnet34 (此处34表示我们具有34层)和度量error_rate ,该度量计算在验证数据上未正确分类的图像的百分比
A metric is a function that measures the quality of the model’s predictions using the validation set — Fastbook
度量标准是一项使用验证集测量模型预测质量的功能-Fastbook
转移学习如何工作? (How does transfer learning work?)
Initially, we replace the final layer of our pretrained model with one or more new layers with randomized weights this part is known as head. We update the weights of the head using the back-propagation algorithm which we will learn in a different article
最初,我们用一个或多个具有随机权重的新层替换预训练模型的最后一层,这部分被称为头部。 我们使用反向传播算法更新头部的权重,我们将在另一篇文章中学习
Fastai provides a method fine_tune which performs the task of tuning the pre-trained model to solve our specific problem using the data we have curated
Fastai提供了fine_tune方法,该方法执行调整预训练模型的任务,以使用我们fine_tune的数据解决我们的特定问题
In[12]: learn.fine_tune(4)
We pass a number to fine_tune which tells how many epochs (the number of times we fully go through the dataset) you need to train. This is something you need to play with, there is no hard and fast rule. It depends on your problem, dataset, and the time you want to spend on training. You may run the function multiple times with different epochs
我们将一个数字传递给fine_tune ,它告诉您需要训练多少个时期(我们完全遍历数据集的次数)。 这是您需要玩的东西,没有硬性规定。 这取决于您的问题,数据集以及您想花在培训上的时间。 您可以在不同的时期多次运行该函数
Tips from Jeremy and my learnings:
杰里米的秘诀和我的经验:
Training for large no of epochs can lead to overfitting, which may lead to poor performance on unseen data. If the validation loss continues to increase in consecutive epochs it means that our model is memorizing the training data and we need to stop training
大量培训可能会导致过度拟合,这可能会导致看不见数据的性能下降。 如果验证损失在连续的时期内继续增加,则意味着我们的模型正在存储训练数据,我们需要停止训练
We can improve performance by training the model with different resolutions. Eg. Train with 224x224 and later with 112x112 pixel images
我们可以通过训练具有不同分辨率的模型来提高性能。 例如。 使用224x224进行训练,然后使用112x112像素图像进行训练
Data augmentation will help prevent overfitting to some extent
数据扩充将在一定程度上帮助防止过度拟合
使用推理模型(Using the Model for Inference)
Now we have our trained mask classifier which can classify whether a person is wearing a mask properly, improperly, or not wearing a mask from the picture of his face. We can export this model and use it to predict the class elsewhere
现在,我们有了训练有素的面罩分类器,该分类器可以根据人的脸部图片对一个人是否正确,不正确地戴着口罩或是否未佩戴面罩进行分类。 我们可以导出此模型,并用它来预测其他地方的类
In[13]: learn.export()
In[14]: learn.predict('path/to/your/image.jpg')We can load this model using load_learner('path/to/model/export.pkl')
我们可以使用load_learner('path/to/model/export.pkl')加载此模型

I went on to make a REST API exposing this model to the internet and with the help of my friends: Vaishnavi and Jaswanth, made a web application which takes an input image and draws bounding boxes according to the category the face belongs and also the count of face categories. Please feel free to drop your feedback there which will help improve the model. The web app is live at https://findmask.ml
我继续制作一个REST API,并在朋友们的帮助下将该模型暴露给了互联网: Vaishnavi和Jaswanth ,制作了一个Web应用程序,该应用程序可以输入输入图像,并根据面部所属的类别以及计数来绘制边界框。的面Kong类别。 请随时在此处放下您的反馈意见,这将有助于改进模型。 该Web应用程序位于https://findmask.ml上
Article on how did I build a Deep Learning REST API is coming soon :)
即将发布有关如何构建深度学习REST API的文章:)
结论 (Conclusion)
Now you are in spot to build your image classifier, you may also use this technique to classify sounds by converting them into spectrograms or any suitable image form. If you are starting to learn deep-learning I highly recommend you to take the fastai v2 course and join the study group organised by Sanyam Bhutani and MLT where we read and discuss each chapter of Fastbook everyweek.
现在您已经可以构建图像分类器,您还可以使用此技术将声音转换为声谱图或任何合适的图像形式,从而对声音进行分类。 如果您开始学习深度学习,我强烈建议您参加fastai v2课程,并加入Sanyam Bhutani和MLT组织的研究小组,我们每周阅读和讨论Fastbook的每一章。
Feel free to reach me for any feedback or if you are facing any issue, happy to help. I’m active at Twitter and LinkedIn
请随时与我联系,以获取任何反馈,或者如果您遇到任何问题,请随时与我们联系。 我活跃于Twitter和LinkedIn
相关有趣的文章 (Related Interesting Articles)
https://muellerzr.github.io/fastblog/
https://muellerzr.github.io/fastblog/
https://towardsdatascience.com/10-new-things-i-learnt-from-fast-ai-v3-4d79c1f07e33
https://towardsdatascience.com/10-new-things-i-learnt-from-fast-ai-v3-4d79c1f07e33
我的其他故事 (My Other Stories)
SQLAlchemy — Python Tutorial
SQLAlchemy — Python教程
How to protect your internet identity?
如何保护您的互联网身份?
翻译自: https://towardsdatascience.com/build-any-deep-learning-image-classifier-under-15-lines-of-code-using-fastai-v2-123c81c13b
fastai 图像分类