基于语音的疲劳度检测算法研究
基于语音的疲劳度检测算法研究
摘 要
疲劳是一种自然现象,是人体的一种自我调节和保护功能。检测疲劳状态对于当今社会从事各行各业都有积极意义。本课题提出了一种基于语音特征参数和概率神经网络的语音疲劳度识别模型。通过训练不同时段的语音样本来构成语音源库,并建立综合识别系统。实验结果表明本方法能够反应其当时的疲劳程度,MFCC参数融入了人耳的听觉特性,故从测试结果来看,其优于LPCC参数。
关键词:语音、疲劳度、线性预测倒谱系数、梅尔频率倒谱系数、概率神经网络
Research of Detecting Fatigue Arithmetic in Speech
ABSTRACT
Fatigue is a natural phenomenon which is the human body a kind of self-regulation and protection. Detection of fatigue states has positive significance in all occupation in today's society. This issue presents a feature-based parameters and the probabilistic neural network speech recognition model to detecting fatigue. Through training at different times of voice samples to form the voice source and to establish a comprehensive identification system. Experimental results show that this method can reflect its degree of fatigue at the time, MFCC parameters of the human ear into the auditory characteristics, and therefore the results from the test point of view, it's better than the LPCC parameters.
KEYWODRS: Speech、Fatique、LPCC、MFCC、PNN
第一章 引言
第1.1节 本课题研究背景
疲劳是一种自然现象,是人体的一种自我调节和保护功能。有资料表明,高速公路发生的交通事故中,有一半以上由于长时间疲劳驾驶或所见目标单调使司机注意力不集中、甚至打瞌睡等原因造成的。为减少这方面的事故,疲劳度测试就具有十分重要的意义。疲劳也往往成为脑与心脏疾病的诱因,如通过简单的方法实时检测自己的身体状态,对于预防疾病,减少人为的事故也具有积极的意义。
疲劳度的检测方法可以概括为客观和主观两个方面。国内主要采取主观评测的方法,主要依据自我活动记录表、睡眠情况记录表、个人行为记录表等来测评被试者的疲劳程度,虽然主观评价方法使用简单,但很难量化疲劳的等级和程度,又因各人的理解有明显的差异,其结果往往不能令人满意。
国外则主要采取客观测评的方法,有基于行为特征的检测的视网膜检测、头部位置检测、视线方向检测等和基于生理参数的检测的脑电图信号检测、心电图信号检测、脉搏跳动检测、唾液检测、其它生理信号检测等。这些方法虽然说能从一定程度上了解人的疲劳状态,但是对每个人疲劳的心理、生理属性还不是特别清楚,疲劳状态下的变化规律很难总结归纳。目前大多数检测算法因其检测条件的限制和复杂环境的影响,检测效果不能完全令人满意。性价比是亟待解决的一个问题,如果成本太大则难以广泛应用。
通过声音判断人的疲劳程度是一种更为简便快捷的疲劳度检测方式,能够在不影响正常工作下面,让被检测者对着麦克风说话,将其语音集入电脑,再通过声波的变化进行计算,得到测算值。
第1.2节 方案简介
通过声音检测,可以很方便可以很方便地了解大脑的疲劳水平。这对于诸如驾驶员等长时间处于紧张状态的人员来说,意义更加重大。
本课题采用方法如下:
1、通过语音采集得到原始数据参数,通过录音笔进行录制,组员每人每天分别在白天10点,晚上10点,白天4点,晚上4点,录下语音,录制的语音以wave格式保存。
2、采用语音信号的基本参数来对疲劳语音特征进行研究,主要包括LPCC、MFCC等,发现对疲劳度影响最大的特征。
3、采用基于贝叶斯决策理论的概率神经网络来进行模式识别,对特征进行训练,随后对未知语音信号进行模式识别,得到所需概率参数。
4、系统的各种算法由MATLAB编程实现,完成了特征参数的提取和训练工作,建立疲劳度检测系统。
5、完成分析测试报告,提出进一步改进方案。
第二章 语音信号识别的理论基础
第2.1节 语音信号产生的声学基础
图2.1是人类语音通信过程中几个重要的环节,从说话人的想法开始到听话人的理解,需要经过说话和听话两个人语义和语法的处理、音位的编码和解码过程,此外最重要的就是人类发声器官和听觉器官的机理。只有深入研究这两个方面,才能建立反映真实情况的物理模型和数字模型。
图2.1 人类语音通信过程
人发声过程如图2.2所示。人通过口、鼻吸气,使自己的肺叶充满空气,肺是胸腔内一团有弹性的海绵状物质,可以存储空气。当人发声时,肺部的空气被压缩,经气管到喉部。声带是位于喉咙中间的两条白色韧带,一般声带的长度为10mm-14mm。当发声时,气流穿过两条声带间的缝隙,声带自然闭合靠拢,成水平状;当气流被阻断时,声带间就产生缝隙,从而产生一股准周期的脉冲,使声带产生振动。当激励源不是声带的脉冲,而由空气湍流产生的情况下,发出的音就称为“清音”,这时激励源类似于白噪声,最后通过声道的气流通过口唇或者鼻腔向外发出。
图2.2 语音产生的物理模型
第2.2节 语音信号产生的数字模型
为了简化问题,根据语音产生器官的组织结构,结合信号处理理论,提出了如图2.3所示的语音信号产生的数字模型。
图2.3 语音产生的数字模型
如图所示,语音信号的数字模型分为激励模型、声道模型、辐射模型三个部分。
1、激励模型
激励模型表示发音器官中的声门子系统,包括负责产生气流的肺和气管以及产生振动的声带,分清音和浊音两种情况。
发浊音时,气流冲击声带产生振动,使声门处形成准周期性的脉冲串,并用它去激励声道。此时的脉冲波类似于斜三角形的脉冲,其声门脉冲模型为:
其中
和
取值接近于1,模型极点靠近单位圆,相当于一个低通滤波器。
发清音时,声带松弛而不振动,空气湍流通过声门直接进入声道,这时激励信号就可以简化为随机白噪声,实际中可以用均值为0、均方差为1的白色分布序列来表示。
2、声道模型
对于声道的建模,经典的语音信号处理技术主要有两种观点,一是把声道看成是由多个不同截面积的管子串联而成的系统,导出“声管模型”;二是把声道视为一个谐振腔,导出“共振峰模型”。
现在应用最广泛的声道模型是离散化的声管模型, 把声道看成是由多个不同截面积的管子串联而成的系统。假设在一个“短时”期间声道形状无变化时,而且声波在声道内是沿管轴无损传播的平面波。则由P个短管组成的声道模型的传递函数可以表示为一个P阶的全极点函数:
其中P为全极点滤波器的阶数,
=1,
为声道模型参数,它随着调音运动在一定限制内不断变化。一般而言P的取值范围为8-12,每一对极点对应着一个共振峰,
决定了声道系统的频率特性。一般而言在10ms-30ms范围内认为这些声道参数保持不变,这也是语音信号短时分析的理论依据之一。
3、辐射模型
声道的终端是口和唇,从声道输出的是速度波,而语音信号是声压波,两者的倒比称为辐射阻抗,可以用它来表示口唇的辐射效应。研究证明,辐射模型可以简化为:
r取值约等于1,
类似一个一阶的高通滤波器。
语音信号的系统传递函数
就可以用声门激励系统、声道系统和辐射系统传递函数的乘积表示。
其中激励函数
分为发浊音和清音两种情况。
第2.3节 语音信号的预处理
在对语音信号进行各种后续处理之前,为了防止混叠失真和噪声干扰,必须用一个低通滤波器进行防混叠滤波,滤除高于1/2采样率的信号成分。
由于语音信号的平均功率谱受口鼻辐射的影响,需要对信号进行高频提升(6db/倍频),便于进行频谱分析和声道函数分析,因而需要将信号进行预加重处理。
预加重滤波器形式为:
,
取值范围为0.93-0.97之间。预加重后的语音信号还能有效滤除低频干扰,尤其是50Hz的工频干扰,同时还能达到消除直流漂移、抑制随机噪声和提升清音部分能量的效果。当语音信号在分析处理之后需要语音合成的时候,还需要进行去加重处理以恢复原来的语音信号。
预加重滤波器的幅频响应如图2.4所示。
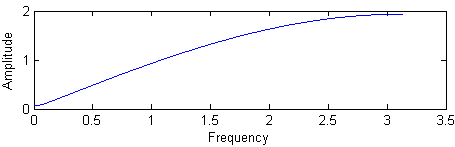
图2.4 预加重滤波器的幅频响应
分帧的时候会采取0-50%重叠的方式,前一帧与后一帧之间交叠的部分称为帧移,有了帧移的话,帧与帧之间就能够平滑过渡,如图2.5所示。
图2.5 分帧示意图
随后对取出的一帧信号
进行加窗
处理,即
,在加窗的时候,不同的窗口和窗长的选择将影响到语音信号分析结果,窗函数
通常有矩形窗(Rectangle)和汉明窗(Hamming)两种。
矩形窗的表达式为:
汉明窗的表达式为:
汉明窗可以有效地克服频谱泄露现象,所以在处理中一般都选择汉明窗。
第2.4节 语音信号的时域分析
语音信号的时域特征参数直接从时域信号计算得到,反应了语音信号时域波形的特征,如短时能量、短时平均幅值、短时过零率、短时自相关系数和短时平均幅度差等。
1、语音信号的短时能量
表达式为:
2、语音信号的短时平均幅值
表达式为:
3、语音信号的短时平均过零率
表达式为:
当发浊音时,能量集中在低频段,而当发清音时能量多数集中在高频段,短时平均过零率可以从一定程度上表示频率的高低,因此在浊音段有较低的过零率,在清音段有较高的过零率,据此就可以初步判断清浊音。
图2.6为某语音信号的时域波形图、短时能量和短时过零率。
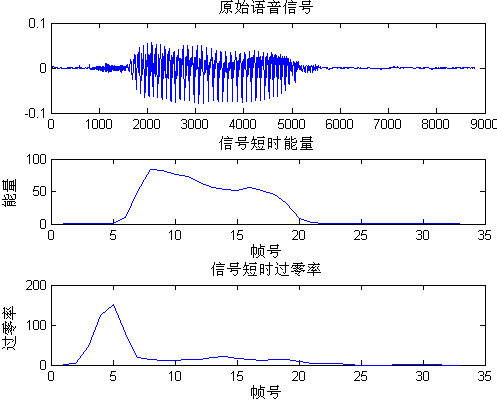
图2.6 语音9的波形图、短时能量和过零率
如图所示,信号短时能量在信号浊音段比较突出,而过零率在清音段比较突出。在孤立词识别过程中,必须对一连串语音进行分割,以确定一个词的语音信号,所以要找出一个词的起点和终点。需要对语音进行端点检测。
在实际应用中正是利用信号的这两种特点来进行端点检测,用的比较多的是一种双门限的方法。
图2.7为图2.6语音采用以上算法的端点检测结果,可以看出上述算法能准确找到语音的起始点和终点。
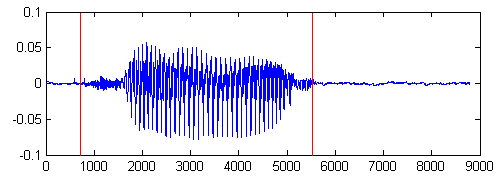
图2.7 语音9的波形图及端点检测
第三章 语音疲劳度的特征参数提取方案
第3.1节 LPCC特征参数
线性预测分析技术由维纳在1947年首次提出,其基本思想是:语音的当前样点值都可以用若干过去的样点值来线性表示。各加权系数值的确定原则是要保证误差的最小均方值要最小。设预测值为
,则
其中P为预测阶数,
为加权系数,即LPCC系数。
预测误差
用来表示真实值与预测值之间的差异。
此时定义
为预测误差滤波器。
可以发现,
与
互为逆滤波器。这正表明线性预测模型能够用来表示声道模型,而线性预测系数
恰能够反映出声道特性,从而能够用于语音识别。
本课题中采用的是自相关,从表中可以看出自相关虽然由于加窗而引入误差,从而对精度有一定影响,但它的计算量最小且稳定性能够得到保证,是一种简单高效的算法,具体算法(Levinson-Durbin算法)如下:
从以上推导可以看出LPCC系数能够用于模拟全极点声道模型,但同时存在一个问题,那就是在实际中从原始语音中获取LPCC系数时,它既包含所需要的声道信息,但同时无法避免混杂了语音信号产生过程中的激励信息。
而倒谱分析正好能够解决这一问题,提高参数的稳定性。所谓倒谱就是利用同态处理方法,对语音信号求离散傅里叶变换(DFT),然后取绝对值的对数进行反变换(IDFT)得到的,如图3.1所示。
图3.1 语音倒谱参数提取过程
第3.2节 MFCC特征参数
LPCC模型是基于声道模型而提出的,因此参数的稳定性取决于语音的平稳性和鲁棒性。而MFCC参数是将人耳的听觉特性和语音的产生机制相结合而产生的一组特征参数。
人耳具有一些特殊的功能,正是这些特殊的功能能够使人耳在嘈杂的环境中还能够正常的分辨出各种语音,其中耳蜗起了关键的作用。耳蜗实质上相当于一个滤波器组,滤波的作用是在对数频率上进行的,在1KHz以下为线性尺度,而在1KHz以上则为对数尺度,这就意味着人耳对低频信号更加敏感。而语音信息大多数都集中在低频部分,高频部分绝大多数都是外界噪声的影响,总之突出了低频信息有利于屏蔽噪声的干扰,提取稳定性很高的语音特征参数。
根据这一原理,从心理学实验得到了类似于耳蜗作用的一组滤波器,这就是Mel滤波器组。Mel频率和线性频率的转换关系和图示如下:
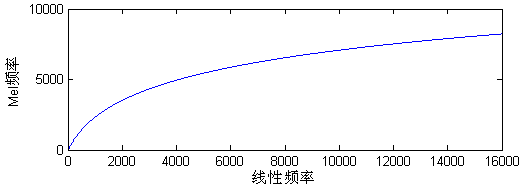
图3.2 线性频率和Mel频率比较
如图所示,对频率轴划分不均匀是MFCC区别于LPCC的主要特点,将频率变换到Mel域后,Mel带通滤波器组的中心频率是按照Mel频率刻度均匀分布,如图3.3所示,每个滤波器的三角形的两个底点分别是相邻两个滤波器的中心频率。设通带内共有M的滤波器组,则每个滤波器
,
的求解方法为:
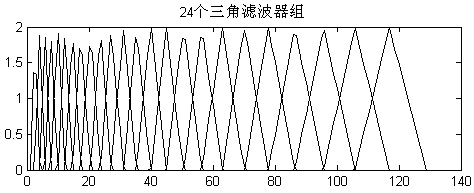
图3.3 Mel滤波器组(M=24)
在实际应用中,MFCC系数计算示意图如图3.4所示,具体计算过程如下:
图3.4 MFCC计算示意图
第四章 概率神经网络
概率神经网络(Probabilistic Neural Network)是由D.F.Specht博士在1990年提出,是径向基函数网络的变形,适合用于解决分类问题。概率神经网络的结构如图4.1所示。第
个结点的输出为 :
式中
称为径向基函数或者特性函数,一般为高斯函数。图中的模块
表示竞争传递函数,其功能是找出其输入矢量
中各元素的最大值,并且使与最大值对应的神经元输出为1,其它类别的神经元的输出为0。这样网络得到的分类结果能够达到最大的正确概率:
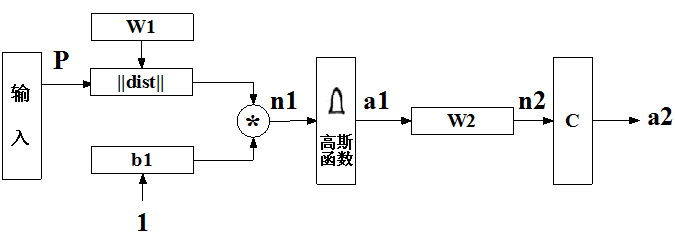
图4.1 概率神经网络结构图
概率神经网络的设计思想主要是基于贝叶斯决策理论。它采用贝叶斯规则来估计后验类别概率
,即未知向量
属于所有可能类别
的概率。由贝叶斯规则可以知道,该概率与先验概率
和概率密度函数
的乘积成正比。
先验概率
为未知向量属于每个类别
的比例,一般来说可用训练集中每个类别样本出现频率来估计:
概率密度函数
由下式表示:
其中
是属于类别
的第
个训练样本,
是类别
中训练样本的数量,
是平滑参数,
是各样本的维数。
PNN的训练就是完成以下工作:产生一个特征节点,把这个特征节点和目标类的求和节点连接起来,并且把输入向量赋值给权向量。可以推导出,在N个类别的问题中,要创建N个求和节点,每一个对应一个目标类。
第五章 实验方案及结果讨论
第5.1节 实验语音信号的录制
语音信号通过一个麦克风,用录音设备录制获得,语音采集通过Cooledit软件完成,录制的语音以wave格式保存。语音信号的特性是11025Hz,16bit,单声道。
以元音[a:]和[o:]作为实验对象,每个数字语音分别在上午4:00、10:00和下午4:00、10:00四个时段各录制40个,共320个数字语音作为实验的数据源。
第5.2节 实验方案
实验流程图由图5.1所示。将预处理的语音信号分别提取 LPCC和MFCC参数,先从每个语音的前10个样本中提取参考模板,疲劳强度从低到高为1-5级,如图5.2所示,然后放入神经网络进行训练,随后把320个语音样本输入神经网络进行测试,得到实验结果。
图5.1 实验流程图
图5.2 疲劳强度示意图
第5.3节 实验结果与讨论
一、采用LPCC参数实验结果
采用LPCC参数和PNN结合方式的实验结果如图5.3、5.4所示,实验参数如表5.1、5.2所示。
图5.3 LPCC法测试元音[a:]结果图
图5.4 LPCC法测试元音[o:]结果图
表5.1 LPCC法测试元音[a:]数据
| 测试样本 | 预期结果 | 实验均值 | 相对误差 | 方差 |
| 凌晨四点 | 5 | 3.6641 | -0.2672 | 0.4348 |
| 上午十点 | 1 | 1.381 | -0.5397 | 0.1219 |
| 下午四点 | 2 | 1.9902 | -0.0049 | 0.1785 |
| 晚上十点 | 4 | 2.4051 | -0.3987 | 0.3766 |
表5.2 LPCC法测试元音[o:]数据
| 测试样本 | 预期结果 | 实验均值 | 相对误差 | 方差 |
| 凌晨四点 | 5 | 4.5269 | -0.0946 | 0.1525 |
| 上午十点 | 1 | 1.0198 | -0.6601 | 0.0124 |
| 下午四点 | 2 | 2 | 0 | 0 |
| 晚上十点 | 4 | 4.0025 | 0.000625 | 0.00025 |
二、采用MFCC参数实验结果
采用MFCC参数和PNN结合方式的实验结果如图5.5、5.6所示,实验参数如表5.3、5.4所示。
图5.5 MFCC法测试元音[a:]结果图
图5.6 MFCC法测试元音[o:]结果图
表5.3 MFCC法测试元音[a:]数据
| 测试样本 | 预期结果 | 实验均值 | 相对误差 | 方差 |
| 凌晨四点 | 5 | 4.7151 | -0.057 | 0.1768 |
| 上午十点 | 1 | 1.2393 | 0.2393 | 0.2588 |
| 下午四点 | 2 | 1.9683 | -0.0158 | 0.1515 |
| 晚上十点 | 4 | 3.9014 | -0.0247 | 0.4467 |
表5.4 MFCC法测试元音[o:]数据
| 测试样本 | 预期结果 | 实验均值 | 相对误差 | 方差 |
| 凌晨四点 | 5 | 4.8149 | -0.037 | 0.094 |
| 上午十点 | 1 | 1.0435 | 0.0435 | 0.0076 |
| 下午四点 | 2 | 2 | 0 | 0 |
| 晚上十点 | 4 | 4.0143 | 0.0036 | 0.0023 |
三、讨论
从以上实验结果中可以看出,通过概率神经网络的计算,四个时段录制的同一个语音存在一定的区分度,能够反应其当时的疲劳程度,MFCC参数融入了人耳的听觉特性,故从测试结果来看,其结果优于LPCC参数,并且[o:]音的结果比[a:]更好。
第六章 总结与展望
本课题主要采用两种典型的语音特征参数LPCC和MFCC和概率神经网络的方法对两个基本元音[a:]和[o:]进行测试,从测试结果来看,元音[o:]相对于[a:]识别结果更优,对于实际测试的准确率保证更占优势,同时MFCC方法相对于LPCC方法,各项指标更有利于提高识别准确率。
对于今后进一步工作的思考,主要从以下几个方面进行思考:1、与频谱图结合,从图像上寻找区分度;2、结合语音基音、共振峰等多种各种参数进行综合判别;3、进行所有元音的测试,找到最利于判别的发音和词组;4、优化概率神经网络,使之更为适应疲劳度检测;5、隐马尔科夫模型HMM的介入。
附录(主要程序)
clear all
display('开始计算参考模板......');
pause(1);
directoryname='speech/a/';
fname1='AM4/';
fname2='AM10/';
fname3='PM4/';
fname4='PM10/';
for i=1:10
fname = sprintf('%d.wav',i);
x = wavread([directoryname,fname1,fname]);
x = vad(x);
m = mfcc(x);
test(1,i).mfcc = m;
end
display('提取凌晨4点MFCC参数成功,开始计算参考模板......');
pause(1);
for i=1:10
for j=1:10
a(i,j)=dtw(test(1,i).mfcc,test(1,j).mfcc);
end
end
[d j]=min(sum(a,2));
x=wavread([directoryname,fname1,num2str(j),'.wav']);
wavwrite(x,'speech/aref2/AM4/1.wav');
display(['经计算,第' num2str(j) '个语音适合为参考模板,并写入参考模板库']);
pause(1);
for i=1:10
fname = sprintf('%d.wav',i);
x = wavread([directoryname,fname2,fname]);
x = vad(x);
m = mfcc(x);
test(2,i).mfcc = m;
end
display('提取上午十点MFCC参数成功,开始计算参考模板......');
pause(1);
for i=1:10
for j=1:10
a(i,j)=dtw(test(2,i).mfcc,test(2,j).mfcc);
end
end
[d j]=min(sum(a,2));
x=wavread([directoryname,fname2,num2str(j),'.wav']);
wavwrite(x,'speech/aref2/AM10/1.wav');
display(['经计算,第' num2str(j) '个语音适合为参考模板,并写入参考模板库']);
pause(1);
for i=1:10
fname = sprintf('%d.wav',i);
x = wavread([directoryname,fname3,fname]);
x = vad(x);
m = mfcc(x);
test(3,i).mfcc = m;
end
display('提取下午四点MFCC参数成功,开始计算参考模板......');
pause(1);
[d j]=min(sum(a,2));
x=wavread([directoryname,fname3,num2str(j),'.wav']);
wavwrite(x,'speech/aref2/PM4/1.wav');
display(['经计算,第' num2str(j) '个语音适合为参考模板,并写入参考模板库']);
pause(1);
for i=1:10
fname = sprintf('%d.wav',i);
x = wavread([directoryname,fname4,fname]);
x = vad(x);
m = mfcc(x);
test(4,i).mfcc = m;
end
display('提取晚上十点MFCC参数成功,开始计算参考模板......');
pause(1);
for i=1:10
for j=1:10
a(i,j)=dtw(test(4,i).mfcc,test(4,j).mfcc);
end
end
[d j]=min(sum(a,2));
x=wavread([directoryname,fname4,num2str(j),'.wav']);
wavwrite(x,'speech/aref2/PM10/1.wav');
display(['经计算,第' num2str(j) '个语音适合为参考模板,并写入参考模板库']);
pause(1);
display('计算完毕');
参考文献
[1] Rabiner L R, Juang B H, Fundamental of Speech Recognition, Prentic Hall Internation,1993
[2] G.M.Lloyd,M.L.Wang, T.L.Paez. Minimisation of decision errors in a probabilistic neural networks for change point detection in mechanical systems. Mechaanical Systems and Signal Procing,1999,13(6):943-954
[3] B.H.Juang,The past present and future of speech processing, IEEE Signal Processing Magazine,1998
[4] SPECHT D F. Probabilistic neural networks. Neural Networks,1990,3(2):109-118
[5] Huang D S, The pattern recognition system theory based on the neural networks.Beijing Publishing House of Electronic Industry,1996,119-137
[6] Jarek Krajewski, Rainer Wieland, and Anton Batliner, An Acoustic Framework for Detecting Fatigue in speech Based Human-Computer-Interaction. Springer-Verlag Berlin Heidelberg ,2008,,54-61
[7] H.P. Greeley, E. Friets, and J.P. Wilson,T Detecting Fatigue From Voice Using Speech Recognition ,Symposium on Signal Processing and Information Technology IEEE,2006,567-571