Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(2)——使用Keras构建神经网络
-
- 0 前言
- 1. Keras 简介与安装
- 2. Keras 构建神经网络初体验
- 3. 训练香草神经网络
-
- 3.1 香草神经网络与 MNIST 数据集介绍
- 3.2 训练神经网络步骤回顾
- 3.3 使用 Keras 构建神经网络模型
- 3.4 关键步骤总结
- 小结
- 系列链接
0 前言
在《神经网络基础》中,我们学习了如何从零开始构建了一个神经网络,更具体的说,我们编写了执行正向传播和反向向传播的函数。 在本节中,我们将使用 Keras 库构建神经网络,该库提供了很多实用工具,可以简化构建复杂神经网络的过程。
1. Keras 简介与安装
Keras 是用 Python 编写的高级神经网络 API,它的核心思想在于实现快速实验,它能够在 TensorFlow,CNTK 或 Theano 之上运行,因此为了使用 Keras 首先需要安装 TensorFlow,CNTK 或 Theano 库作为后端。本文使用 Tensorflow,因此需要首先使用如下命令安装 Tensorflow:
$ pip install tensorflow-gpu
最好安装与 GPU 兼容的版本,因为当神经网络在 GPU 上训练时,它们的运行速度会大大提高。更加详细的安装教程可以参考《tensorflow-gpu安装》。
完成 tensorflow 的安装后,可以按以下方式安装 keras:
$ pip install keras
2. Keras 构建神经网络初体验
在本部分中,学习如何使用 Keras 创建神经网络模型,我们使用与《神经网络基础》中相同的简单数据集,将模型定义如下:
- 输入连接到具有三个节点的隐藏层
- 隐藏层连接到输出,输出层有一个节点
- 定义数据集,导入相关库:
import keras
import numpy as np
x = np.array([[1], [2], [3], [7]])
y = np.array([[3], [6], [9], [21]])
- 实例化一个可以顺序计算的神经网络模型,可以在其中堆叠添加多个网络层,计算过程按网络层的堆叠顺序进行。
Sequential方法能够构建顺序计算模型:
model = keras.models.Sequential()
- 向模型添加一个
Dense层(全连接层)。Dense层用于模型中各个层之间的全连接(上一层的每个节点与本层的每个节点间都有连接),Dense层的工作方式与我们在《神经网络基础》中相同使用的隐藏层完全相同。在以下代码中,我们将输入层连接到隐藏层:
model.add(Dense(3, activation='relu', input_shape=(1,)))
在使用前面的代码初始化的 Dense 层中,需要确保为模型提供输入形状(由于这是第一个全连接层,因此需要指定模型期望的接受的数据形状)。隐藏层中有三个节点,并且在隐藏层中使用的激活函数是ReLU函数。
- 将隐藏层连接到输出层:
model.add(keras.layers.Dense(1, activation='linear'))
在此 Dense 层中,我们无需指定输入形状,因为模型可以从上一层推断出输入形状。输出层具有一个节点,并使用线性激活函数。
可以将模型概要信息 (model summary) 可视化输出:
model.summary()
可以看到模型概要信息如下所示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 3) 6
_________________________________________________________________
dense_1 (Dense) (None, 1) 4
=================================================================
Total params: 10
Trainable params: 10
Non-trainable params: 0
_________________________________________________________________
从模型概要信息可以看到,从输入层到隐藏层的连接中总共有六个参数(三个权重和三个偏置项),另外,使用三个权重和一个偏置项将隐藏层连接到输出层。
- 编译模型。首先,需要定义损失函数和优化器,以及优化器相对应的学习率:
from keras.optimizers import SGD
sgd = SGD(lr=0.01)
上述代码指定优化器是随机梯度下降,学习率为 0.01。将预定义的优化器及其相应的学习率、损失函数作为参数传递给 compile 方法编译模型:
model.compile(optimizer=sgd,loss='mean_squared_error')
- 拟合模型。更新权重,以优化模型:
model.fit(x, y, epochs=1, batch_size = 4, verbose=1)
fit 方法需要接收一个输入 x 和相应的实际值 y,epochs 代表训练数据集的次数,batch_size 代表每次更新权重的迭代中训练的数据量大小,verbose 指定训练过程中的输出信息,可以包含有关训练和测试数据集上损失值以及模型训练的进度等信息。
- 提取权重值。权重值的相关信息是通过调用模型的
weights属性获得的:
model.weights
获得的权重相关信息如下:
[<tf.Variable 'dense/kernel:0' shape=(1, 3) dtype=float32, numpy=array([[1.1533519 , 1.2411805 , 0.39152434]], dtype=float32)>,
<tf.Variable 'dense/bias:0' shape=(3,) dtype=float32, numpy=array([ 0.03425962, -0.05432956, -0.1607531 ], dtype=float32)>,
<tf.Variable 'dense_1/kernel:0' shape=(3, 1) dtype=float32, numpy=array([[1.2210085 ], [1.2086679 ],[0.21541257]], dtype=float32)>,
<tf.Variable 'dense_1/bias:0' shape=(1,) dtype=float32, numpy=array([0.09131978], dtype=float32)>]
从前面的输出中,可以看到首先打印的权重属于 dense_1 层中的三个权重和三个偏置项,然后是 dense_2 层的三个权重和一个偏置项。其中包括权重的尺寸、数据类型以及参数的具体值等。我们也可以仅提取这些权重的值:
print(model.get_weights())
权重以数组列表的形式显示,其中每个数组对应于 model.weights 输出中的相应项:
[array([[1.1533519 , 1.2411805 , 0.39152434]], dtype=float32), array([ 0.03425962, -0.05432956, -0.1607531 ], dtype=float32), array([[1.2210085 ],
[1.2086679 ],
[0.21541257]], dtype=float32), array([0.09131978], dtype=float32)]
- 使用
predict方法来预测一组新输入的输出:
x1 = [[5], [6]]
output = model.predict(x1)
print(output)
x1 是保存新测试集值的变量,我们需要为其预测输出值。与 fit 方法类似,predict 方法接受数组作为其输入。代码的输出如下:
[[14.996691]
[17.989458]]
当训练多个 epoch 时,网络的输出将与预期的输出 (15, 18) 十分接近。
3. 训练香草神经网络
我们已经学习了神经网络的基础概念,同时也了解了如何使用 keras 库构建神经网络模型,本节我们将更进一步,通过实现一个实用模型来一窥神经网络的强大性能。
3.1 香草神经网络与 MNIST 数据集介绍
通过在输入和输出之间堆叠多个全连接层的网络称为多层感知机,有时会被通俗的称之为香草神经网络(即原始神经网络)。为了了解如何训练香草神经网络,我们将训练模型预测 MNIST 数据集中的数字标签,MNIST 数据集是十分常用的数据集,数据集由来自 250 个不同人手写的数字构成,其中训练集包含 60000 张图片,测试集包含 10000 张图片,每个图片都有其标签,图片大小为 28*28。
3.2 训练神经网络步骤回顾
训练神经网络的步骤可以总结如下:
- 导入相关的库和数据集
- 预处理标签数据(将它们转换为独热编码),以便可以利用标签数据执行优化:
- 最小化分类交叉熵损失
- 创建训练和测试数据集:
- 基于训练数据集创建模型
- 训练时,模型不使用测试数据集:因此,测试数据集的准确性能够衡量模型在正式使用时的性能表现情况,因为投入使用后,模型会遇到训练时不曾见到的数据
- 初始化模型
- 定义模型架构:
- 指定隐藏层数
- 指定隐藏层中的节点数
- 指定要在隐藏层中执行的激活函数
- 指定要最小化的损失函数
- 指定将损失函数降至最低的优化器
- 拟合模型:
- 设定批大小 (
batch size) 以更新权重 - 设定回合 (
epoch) 数
- 设定批大小 (
- 测试模型:
- 使用测试集验证模型,否则需要将数据集拆分为训练集和验证集——将数据集的最后x%视为测试数据
- 计算测试数据集的准确率和损失值
- 检查在每个
epoch内损失值和准确率的变化情况,有利于训练时了解模型情况
在下一节中,使用以上训练流程,利用 Keras 建立神经网络模型。
3.3 使用 Keras 构建神经网络模型
- 导入相关的包和数据集,并可视化数据集以了解数据情况:
from keras.datasets import mnist
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.utils import np_utils
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = mnist.load_data()
在前面的代码中,导入相关的 Keras 方法和 MNIST 数据集。
MNIST数据集中图像的形状为28 x 28,绘制数据集中的一些图像,以更好的了解数据集:
plt.subplot(221)
plt.imshow(x_train[0], cmap='gray')
plt.subplot(222)
plt.imshow(x_train[1], cmap='gray')
plt.subplot(223)
plt.imshow(x_test[0], cmap='gray')
plt.subplot(224)
plt.imshow(x_test[1], cmap='gray')
plt.show()
下图显示了以上代码的输出:

- 展平
28 x 28图像,以便将输入变换为一维的 784 个像素值,并将其馈送至Dense层中。此外,需要将标签变换为独热编码。此步骤是数据集准备过程中的关键:
num_pixels = x_train.shape[1] * x_train.shape[2]
x_train = x_train.reshape(-1, num_pixels).astype('float32')
x_test = x_test.reshape(-1, num_pixels).astype('float32')
在上示代码中,使用 reshape 方法对输入数据集进行形状变换,np.reshape() 将给定形状的数组转换为不同的形状。在此示例中,x_train 数组具有 x_train.shape[0] 个数据点(图像),每个图像中都有 x_train.shape[1] 行和 x_train.shape[2] 列, 我们将其形状变换为具有 x_train.shape[0] 个数据,每个数据具有 x_train.shape [1] * x_train.shape[2] 个值的数组。
接下来,我们将标签数据编码为独热向量:
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
我们简单了解下独热编码的工作原理。假设有一数据集的可能标签为 {apple,orange,banana,lemon,pear},如果我们将相应的标签转换为独热编码,则如下所示:
| 类别 | 索引0 | 索引1 | 索引2 | 索引3 | 索引4 |
|---|---|---|---|---|---|
| apple | 1 | 0 | 0 | 0 | 0 |
| orange | 0 | 1 | 0 | 0 | 0 |
| banana | 0 | 0 | 1 | 0 | 0 |
| lemon | 0 | 0 | 0 | 1 | 0 |
| pear | 0 | 0 | 0 | 0 | 1 |
每个独热向量含有 n n n 个数值,其中 n n n 为可能的标签数,且仅有标签对应的索引处的值为 1 外,其他所有值均为 0。如上所示,apple 的独热编码可以表示为 [1, 0, 0, 0, 0]。在 Keras 中,使用 to_categorical 方法执行标签的独热编码,该方法找出数据集中唯一标签的数量,然后将标签转换为独热向量。
- 用具有 1000 个节点的隐藏层构建神经网络:
model = Sequential()
model.add(Dense(1000, input_dim=num_pixels, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
输入具有 28×28=784 个值,这些值与隐藏层中的 1000 个节点单元相连,指定激活函数为 ReLU。最后,隐藏层连接到具有 num_classes=10 个值的输出 (有十个可能的图像标签,因此 to_categorical 方法创建的独热向量有 10 列),在输出的之前使用 softmax 激活函数,以便获得图像的类别概率。
- 上述模型架构信息可视化如下所示:
model.summary()
架构信息输出如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1000) 785000
_________________________________________________________________
dense_1 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
_________________________________________________________________
在上述体系结构中,第一层的参数数量为 785000,因为 784 个输入单元连接到 1000 个隐藏层单元,因此在隐藏层中包括 784 * 1000 权重值加 1000 个偏置值,总共 785000 个参数。类似地,输出层有10个输出,分别连接到 1000 个隐藏层,从而产生 1000 * 10 个权重和 10 个偏置(总共 10010 个参数)。输出层有 10 个节点单位,因为输出中有 10 个可能的标签,输出层为我们提供了给定输入图像的属于每个类别的概率值,例如第一节点单元表示图像属于 0 的概率,第二个单元表示图像属于 1 的概率,以此类推。
- 编译模型如下:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
因为目标值是包含多个类别的独热编码矢量,所以损失函数是多分类交叉熵损失。此外,我们使用 Adam 优化器来最小化损失函数,在训练模型时,监测准确率 (accuracy,可以简写为 acc) 指标。
- 拟合模型,如下所示:
history = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=50,
batch_size=64,
verbose=1)
上述代码中,我们指定了模型要拟合的输入(x_train)和输出(y_train);指定测试数据集的输入和输出,模型将不会使用测试数据集来训练权重,但是,它可以用于观察训练数据集和测试数据集之间的损失值和准确率有何不同。
- 提取不同epoch的训练和测试损失以及准确率指标:
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
epochs = range(1, len(val_loss_values) + 1)
在拟合模型时,history 变量会在训练和测试数据集的每个 epoch 中存储与模型相对应的准确率和损失值,我们将这些值提取存储在列表中,以便绘制在训练数据集和测试数据集中准确率和损失的变化。
- 可视化不同epoch的训练和测试损失以及准确性:
plt.subplot(211)
plt.plot(epochs, loss_values, marker='x', label='Traing loss')
plt.plot(epochs, val_loss_values, marker='o', label='Test loss')
plt.title('Training and test loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(212)
plt.plot(epochs, acc_values, marker='x', label='Training accuracy')
plt.plot(epochs, val_acc_values, marker='o', label='Test accuracy')
plt.title('Training and test accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
前面的代码运行输入如下图所示,其中第一幅图显示了随着 epoch 数的增加训练和测试的损失值,第二幅图显示了随着 epoch 数的增加训练和测试的准确率:
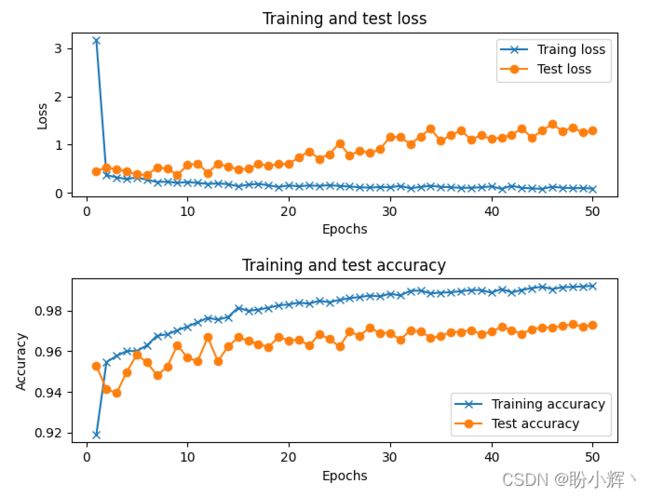
最终模型的准确率约为97%。
- 此外,我们也可以手动计算最终模型在测试集上的准确率:
preds = model.predict(x_test)
correct = 0
for i in range(len(x_test)):
pred = np.argmax(preds[i], axis=0)
act = np.argmax(y_test[i], axis=0)
if (pred == act):
correct += 1
else:
continue
accuracy = correct / len(x_test)
print('Test accuracy: {:.4f}%'.format(accuracy*100))
在以上代码中,使用模型的 predict 方法计算给定输入(此处为 x_test )的预测输出值。然后,我们循环所有测试集的预测结果,使用 argmax 计算具有最高概率值的索引。同时,对测试数据集的真实标签值执行相同的操作。在测试数据集的预测值和真实值中,最高概率值的索引相同表示预测正确,在测试数据集中正确预测的数量除以测试数据集的数据总量即为模型的准确率。
3.4 关键步骤总结
训练原始神经网络代码中执行的关键步骤如下:
- 展平输入数据集,使用
reshape方法将每个像素视为一个输入层的节点变量 - 对标签值进行独热编码,使用
np_utils中的to_categorical方法将标签转换为独热向量 - 使用
Sequential堆叠网络层来构建具有隐藏层的神经网络 - 使用
model.compile方法对神经网络进行了编译,以最大程度地减少多分类交叉熵损失 - 使用
model.fit方法根据训练数据集拟合模型 - 提取了存储在
history中的所有epoch的训练和测试的损失和准确率 - 使用
model.predict方法输出测试数据集中图片对应每个类别的概率 - 遍历了测试数据集中的所有图像,根据概率值最高索引确定图片类别
- 最后,计算了准确率(预测类别与图像的实际类别相匹配的个数)
小结
在本文中,我们使用 keras 库构建了简单的神经网络模型以了解 keras 库的基本用法,然后进一步构建了原始神经网络用于识别 MNIST 手写数字数据集,对于模型训练的流程和其中的关键步骤进行了详细的总结和介绍。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解