mysql学习笔记记录
1.分享 1 个小技巧:
在定义数据类型时,如果确定是整数,就用 INT;如果是小数,一定用定点数类型 DECIMAL;如果是字符串,只要不是主键,就用 TEXT;如果是日期与时间,就用 DATETIME
2.运行这个语句之后,一个跟 demo.importhead 有相同表结构的空表 demo.importheadhist,就被创建出来了。
CREATE TABLE demo.importheadhist
LIKE demo.importhead;3.
CREATE TABLE
(
字段名 字段类型 PRIMARY KEY
);
CREATE TABLE
(
字段名 字段类型 NOT NULL
);
CREATE TABLE
(
字段名 字段类型 UNIQUE
);
CREATE TABLE
(
字段名 字段类型 DEFAULT 值
);
-- 这里要注意自增类型的条件,字段类型必须是整数类型。
CREATE TABLE
(
字段名 字段类型 AUTO_INCREMENT
);
-- 在一个已经存在的表基础上,创建一个新表
CREATE TABLE demo.importheadhist LIKE demo.importhead;
-- 修改表的相关语句
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 数据类型;
ALTER TABLE 表名 ADD COLUMN 字段名 字段类型 FIRST|AFTER 字段名;
ALTER TABLE 表名 MODIFY 字段名 字段类型 FIRST|AFTER 字段名;4.指定存储引擎
ALTER TABLE 表名 ENGINE=INNODB;5. 请你写一个 SQL 语句,将表 demo.goodsmaster 中的字段“salesprice”改成不能重复,并且不能为空。
ALTER TABLE demo.goodsmaster
CHANGE COLUMN salesprice salesprice DECIMAL(10,2) NOT NULL UNIQUE;6. 查询语句的语法结构:
SELECT *|字段列表
FROM 数据源
WHERE 条件
GROUP BY 字段
HAVING 条件
ORDER BY 字段
LIMIT 起始点,行数7.
INSERT INTO 表名 [(字段名 [,字段名] ...)] VALUES (值的列表);
INSERT INTO 表名 (字段名)
SELECT 字段名或值
FROM 表名
WHERE 条件
DELETE FROM 表名
WHERE 条件
UPDATE 表名
SET 字段名=值
WHERE 条件
SELECT *|字段列表
FROM 数据源
WHERE 条件
GROUP BY 字段
HAVING 条件
ORDER BY 字段
LIMIT 起始点,行数8.假设用户有 2 个各自独立的门店,分别有自己的系统。现在需要引入连锁经营的模式,把 2 个店用一套系统统一管理。那么首先遇到的问题就是,需要进行数据整合。下面我们就以商品信息表为例,来说明如何通过使用“ON DUPLICATE”关键字,把两个门店的商品信息数据整合到一起。
假设门店 A 的商品信息表是“demo.goodsmaster”,代码如下:
mysql> SELECT *
-> FROM demo.goodsmaster;
+------------+---------+-----------+---------------+------+------------+
| itemnumber | barcode | goodsname | specification | unit | salesprice |
+------------+---------+-----------+---------------+------+------------+
| 1 | 0001 | 书 | 16开 | 本 | 89.00 |
| 2 | 0002 | 笔 | 10支装 | 包 | 5.00 |
| 3 | 0003 | 橡皮 | NULL | 个 | 3.00 |
+------------+---------+-----------+---------------+------+------------+
3 rows in set (0.00 sec)门店 B 的商品信息表是“demo.goodsmaster1”:
mysql> SELECT *
-> FROM demo.goodsmaster1;
+------------+---------+-----------+---------------+------+------------+
| itemnumber | barcode | goodsname | specification | unit | salesprice |
+------------+---------+-----------+---------------+------+------------+
| 1 | 0001 | 教科书 | NULL | NULL | 89.00 |
| 4 | 0004 | 馒头 | | | 1.50 |
+------------+---------+-----------+---------------+------+------------+
2 rows in set (0.00 sec)假设我们要把门店 B 的商品数据,插入到门店 A 的商品表中去,如果有重复的商品编号,就用门店 B 的条码,替换门店 A 的条码,用门店 B 的商品名称,替换门店 A 的商品名称;如果没有重复的编号,就直接把门店 B 的商品数据插入到门店 A 的商品表中。这个操作,就可以用下面的 SQL 语句实现:
INSERT INTO demo.goodsmaster
SELECT *
FROM demo.goodsmaster1 as a
ON DUPLICATE KEY UPDATE barcode = a.barcode,goodsname=a.goodsname;
-- 运行结果如下
mysql> SELECT *
-> FROM demo.goodsmaster;
+------------+---------+-----------+---------------+------+------------+
| itemnumber | barcode | goodsname | specification | unit | salesprice |
+------------+---------+-----------+---------------+------+------------+
| 1 | 0001 | 教科书 | 16开 | 本 | 89.00 |
| 2 | 0002 | 笔 | 10支装 | 包 | 5.00 |
| 3 | 0003 | 橡皮 | NULL | 个 | 3.00 |
| 4 | 0004 | 馒头 | | | 1.50 |
+------------+---------+-----------+---------------+------+------------+
4 rows in set (0.00 sec)9. 我想请你思考一个问题:商品表 demo.goodsmaster 中,字段“itemnumber”是主键,而且满足自增约束,如果我删除了一条记录,再次插入数据的时候,就会出现字段“itemnumber”的值不连续的情况。请你想一想,如何插入数据,才能防止这种情况的发生呢?
答案:添加商品表中记录的时候,可以判断一下,如果发现itemnumber不连续,可以通过显式指定itemnumber值的办法插入数据,而不是省略itemnumber让它自增。
ALTER TABLE demo.goodsmaster AUTO_INCREMENT=断点数值
10.如果我想把销售流水表 demo.trans 中,所有单位是“包”的商品的价格改成原来价格的 80%,该怎么实现呢?
UPDATE demo.trans AS a, demo.goodsmaster AS b SET price = price * 0.8 WHERE a.itemnumber = b.itemnumber AND b.unit = '包'
11.外键约束和关联查询
-- 定义外键约束:
CREATE TABLE 从表名
(
字段 字段类型
....
CONSTRAINT 外键约束名称
FOREIGN KEY (字段名) REFERENCES 主表名 (字段名称)
);
ALTER TABLE 从表名 ADD CONSTRAINT 约束名 FOREIGN KEY 字段名 REFERENCES 主表名 (字段名);
-- 连接查询
SELECT 字段名
FROM 表名 AS a
JOIN 表名 AS b
ON (a.字段名称=b.字段名称);
SELECT 字段名
FROM 表名 AS a
LEFT JOIN 表名 AS b
ON (a.字段名称=b.字段名称);
SELECT 字段名
FROM 表名 AS a
RIGHT JOIN 表名 AS b
ON (a.字段名称=b.字段名称);12.如果你的业务场景因高并发等原因,不能使用外键约束,在这种情况下,你怎么在应用层面确保数据的一致性呢?
如果不能使用外键约束,你可以在应用层增加确保数据完整性的功能模块,比如删除主表记录时,增加检查从表中是否应用了这条记录的功能,如果应用了,就不允许删除。
13.因为 HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。GROUP BY 理解成对数据进行分组,方便我们对组内的数据进行统计计算。
14.having和where的区别:
第一个区别是,如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也就比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
第二个区别是,WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。

15.有这样一种说法:HAVING 后面的条件,必须是包含分组中的计算函数的条件,你觉得对吗?为什么?
HAVING后面的条件,必须是包含分组中计算函数的条件。这种说法是有道理的,主要是考虑到查询的效率。因为如果不是分组中的计算函数的条件,那么这个条件应该可以用WHERE而不是用HAVING,查询的效率就不高了。
16.事务有 4 个主要特征,分别是原子性(atomicity)、一致性(consistency)、持久性(durability)和隔离性(isolation)。
原子性:表示事务中的操作要么全部执行,要么全部不执行,像一个整体,不能从中间打断。
一致性:表示数据的完整性不会因为事务的执行而受到破坏。
隔离性:表示多个事务同时执行的时候,不互相干扰。不同的隔离级别,相互独立的程度不同。
持久性:表示事务对数据的修改是永久有效的,不会因为系统故障而失效。
通过对锁的使用,可以实现事务之间的相互隔离。锁的使用方式不同,隔离的程度也不同。
17.MySQL 支持 4 种事务隔离等级。
READ UNCOMMITTED:可以读取事务中还未提交的被更改的数据。
READ COMMITTED:只能读取事务中已经提交的被更改的数据。
REPEATABLE READ:表示一个事务中,对一个数据读取的值,永远跟第一次读取的值一致,不受其他事务中数据操作的影响。这也是 MySQL 的默认选项。
SERIALIZABLE:表示任何一个事务,一旦对某一个数据进行了任何操作,那么,一直到这个事务结束,MySQL 都会把这个数据锁住,禁止其他事务对这个数据进行任何操作。
事务可以确保事务中的一系列操作全部被执行,不会被打断;或者全部不被执行,等待再次执行。事务中的操作,具有原子性、一致性、永久性和隔离性的特征。但是这并不意味着,被事务包裹起来的一系列 DML 数据操作就一定会全部成功,或者全部失败。你需要对操作是否成功的结果进行判断,并通知 MySQL 针对不同情况,分别完成事务提交或者回滚操作,才能最终确保事务中的操作全部成功或全部失败。MySQL 支持 4 种不同的事务隔离等级,等级越高,消耗的系统资源也越多,你要根据实际情况进行设定。在 MySQL 中,并不是所有的操作都可以回滚。比如创建数据库、创建数据表、删除数据库、删除数据表等,这些操作是不可以回滚的,所以,你在操作的时候要特别小心,特别是在删除数据库、数据表时,最好先做备份,防止误操作。
18.事务就是确保事务中的数据操作,要么全部正确执行,要么全部失败,你觉得这句话对吗?为什么?
这种说法是不对的,事务会确保事务处理中的操作要么全部执行,要么全部不执行,执行中遇到错误,是继续还是回滚,则需要程序员来处理。
19.视图是一种虚拟表,我们可以把一段查询语句作为视图存储在数据库中,在需要的时候,可以把视图看做一个表,对里面的数据进行查询。
20.
一个完整的数据库设计文档应该包含哪些内容呢?
作者回复: 一般来说应该包括需求分析、建模(ER)、逻辑设计(比如建库建表)、物理设计(比如索引)、实施、运维(容灾和备份)等,根据实际需求,可以进一步细化
21.我们在开发应用的时候,经常会遇到一种需求,就是要根据用户的不同,对数据进行横向和纵向的分组。所谓横向的分组,就是指用户可以接触到的数据的范围,比如可以看到哪些表的数据;所谓纵向的分组,就是指用户对接触到的数据能访问到什么程度,比如能看、能改,甚至是删除。
22.角色是在 MySQL 8.0 中引入的新功能,相当于一个权限的集合
23.MySQL 的数据备份有 2 种,一种是物理备份,通过把数据文件复制出来,达到备份的目的;另外一种是逻辑备份,通过把描述数据库结构和内容的信息保存起来,达到备份的目的。逻辑备份这种方式是免费的,广泛得到使用 。
首先,我们来学习下用于数据备份的工具 mysqldump。它总共有三种模式:备份数据库中的表;备份整个数据库;备份整个数据库服务器。
24.第一范式所要求的:所有的字段都是基本数据字段,不可进一步拆分。
第二范式要求,在满足第一范式的基础上,还要满足数据表里的每一条数据记录,都是可唯一标识的。而且所有字段,都必须完全依赖主键,不能只依赖主键的一部分。
我们就按照第二范式的要求,把原先的一个数据表拆分成了 3 个数据表。
第三范式要求数据表在满足第二范式的基础上,不能包含那些可以由非主键字段派生出来的字段,或者说,不能存在依赖于非主键字段的字段。
25.那么,该如何区分实体和属性呢?我给你提供一个原则:我们要从系统整体的角度出发去看,可以独立存在的是实体,不可再分的是属性。也就是说,属性不需要进一步描述,不能包含其他属性。
26.如何把 ER 模型图转换成数据表?通过绘制 ER 模型,我们已经理清了业务逻辑,现在,我们就要进行非常重要的一步了:把绘制好的 ER 模型,转换成具体的数据表。我来介绍下转换的原则。一个实体通常转换成一个数据表;一个多对多的关系,通常也转换成一个数据表;一个 1 对 1,或者 1 对多的关系,往往通过表的外键来表达,而不是设计一个新的数据表;属性转换成表的字段。好了,下面我就结合前面的表格,给你具体讲解一下怎么运用这些转换的原则,把 ER 模型转换成具体的数据表,从而把抽象出来的数据模型,落实到具体的数据库设计当中。
27.我给你介绍了几个从设计角度提升查询性能的方法:修改数据类型以节省存储空间;在利大于弊的情况下增加冗余字段;把大表中查询频率高的字段和查询频率低的字段拆分成不同的表;尽量使用非空约束。这些都可以帮助你进一步提升系统的查询效率,让你开发的应用更加简洁高效。
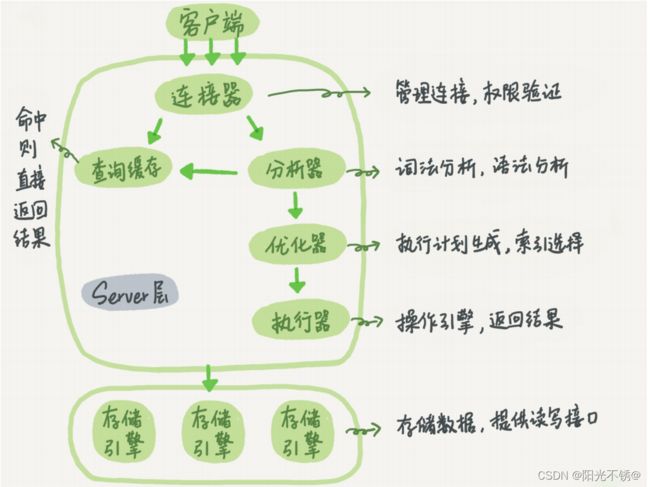
28.MySQL通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶
段,开始执行语句。