软件测试python常用知识点
1 Python2和Python3的区别
1)Python2需要指定编码#coding:utf-8,Python3默认utf-8。
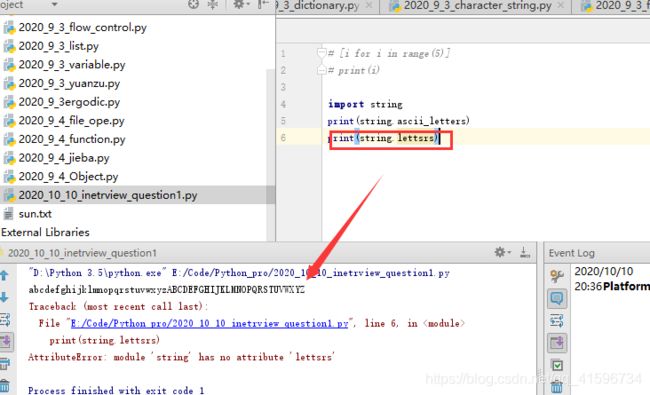
2)import string:Python3没有string.letters这个属性。
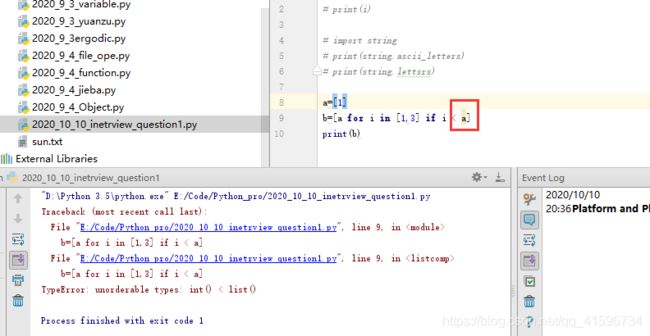
3)列表推导式表达式变量的问题,Python报错如下,Python2会打印结果
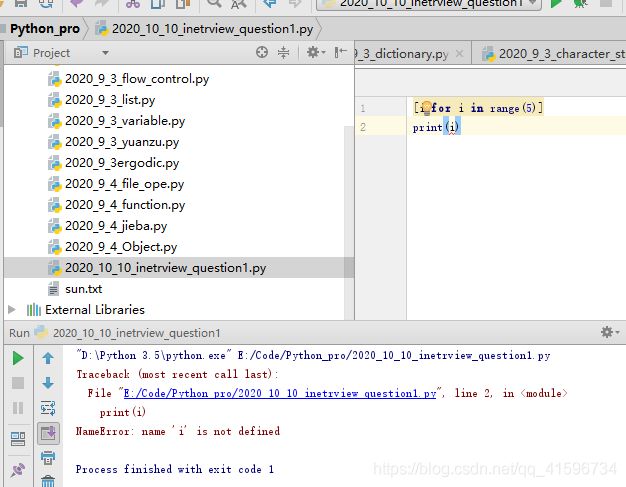
4)作用域问题
在列表解析式变量不能直接引用
正确用法:
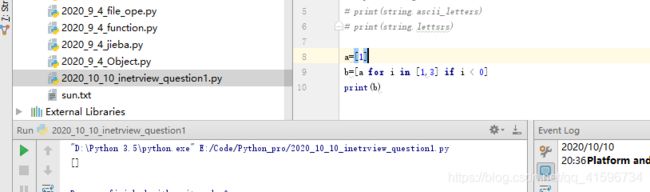
错误用法:条件为变量
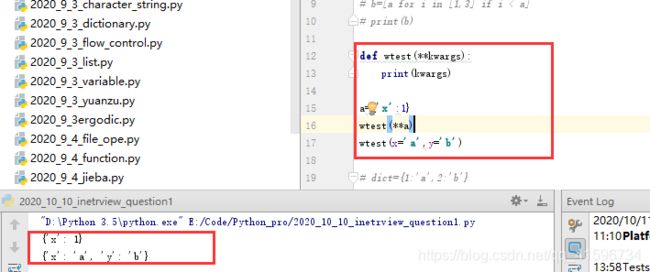
5)在Python函数中可以使用不定长函数来表示传入的是字典
语法:
def 函数名(**kwarge):
函数体
#return
调用函数语句(PS:函数不调用不执行)
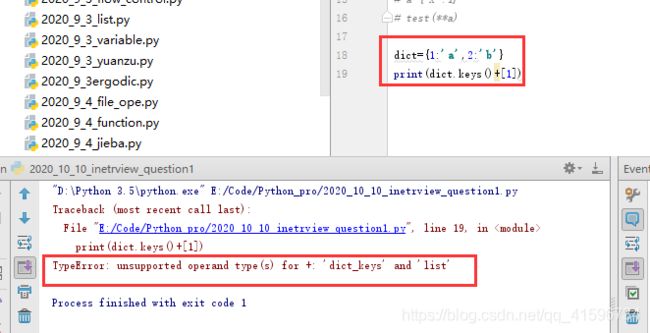
6)Python2,字典的key和list可以一起打印,Python3会报错
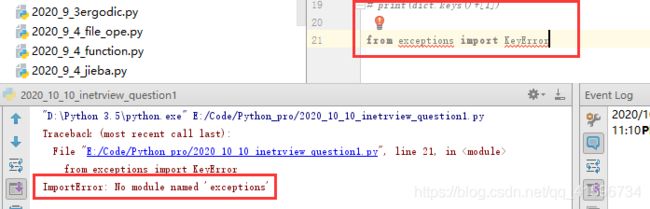
7)Python3没有exception这个包了
8)Python3有对字节长度做限制
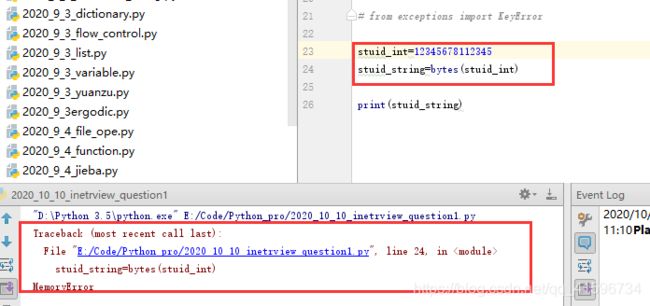
bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
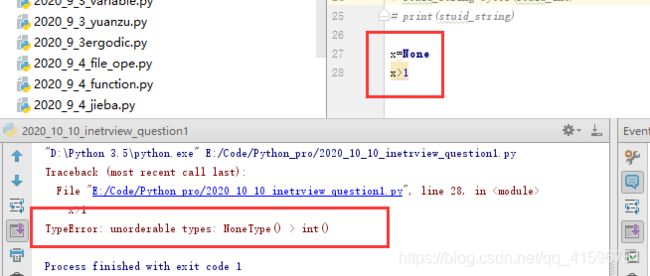
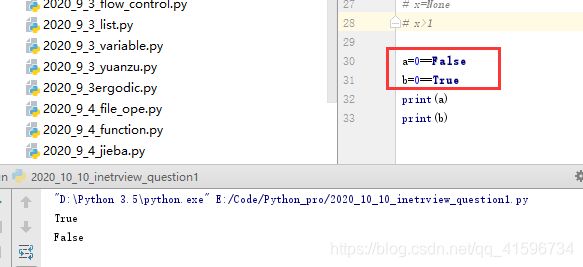
9)Python3 None与数值做比较会报错,不同类型不能做比较,但是0和ture、false可以比较,
Python2会做比较结果输出false
2 一行代码实现1-100之和
#for循环
s1=0
for i in range(1,101):
s1=s1+i
print(s1)
#reduce使用,python3中需要导入
from functools import reduce
def add(a,b):
return a+b
s2=reduce(add,range(1,101))
print(s2)
#reduce改进使用,使用 lambda 匿名函数
s3=reduce(lambda a,b:a+b,range(1,101))
print(s3)
#使用sum函数
s4=sum(range(1,101))
print(s4)
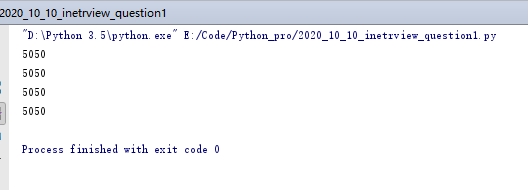
输出结果:
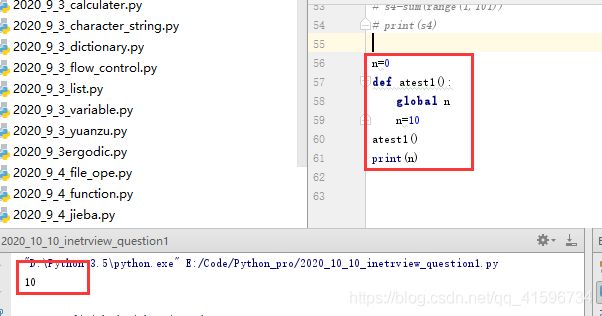
3 函数内修改全局变量
实例1:
实例2
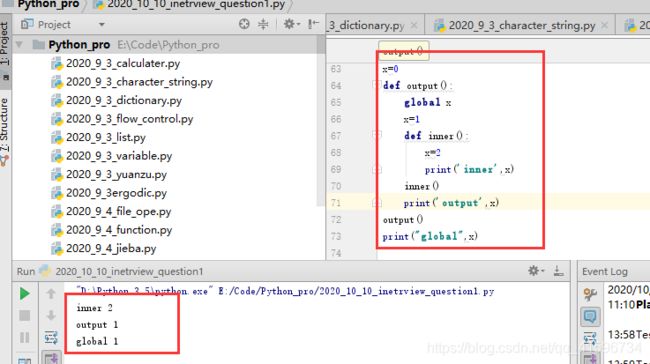
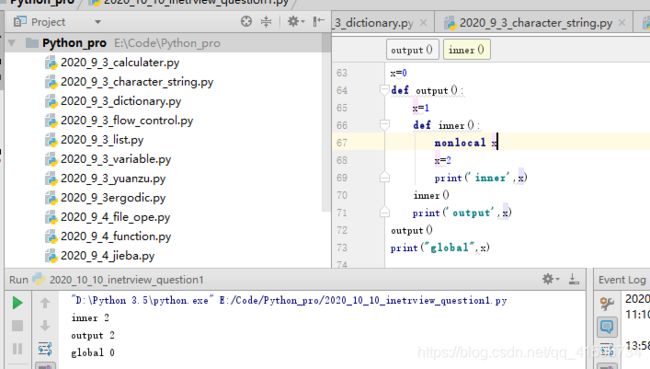
实例3:
nonlocal关键字修饰变量后标识该变量是上一级函数中的局部变量,如果上一级函数中不存在该局部变量,nonlocal位置会发生错误。
4 列出5个Python标准库
4.1 pathlib:路径操作模块,比os模块拼接方便
4.2 urllib:网络请求模块,包括对url结构解析
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
... line = line.decode('utf-8') # Decoding the binary data to text.
... if 'EST' in line or 'EDT' in line: # look for Eastern Time
... print(line)
Nov. 25, 09:43:32 PM EST
>>> import smtplib
>>> server = smtplib.SMTP('localhost')
>>> server.sendmail('[email protected]', '[email protected]',
... """To: [email protected]
... From: [email protected]
...
... Beware the Ides of March.
... """)
>>> server.quit()
4.3 asyncio:Python的异步库,基于事件循环的协程模块
4.4 re:正则表达式模块
re模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简洁、优化的解决方案:
4.5 itertools:提供操作生成器的一些模块
4.6 os:操作系统接口
os模块提供了不少与操作系统相关联的函数
4.7 sys:命令行参数
可以用sys.argv获取当前正在执行的命令行参数的参数列表(list)。
变量解释
sys.argv[0]当前程序名
sys.argv[1]第一个参数
sys.argv[2]第二个参数
len(sys.argv)-1 参数个数(减去文件名)
4.8 math,为浮点运算提供对底层c函数库的访问,提供生成随机数的工具
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
>>> import random
>>> random.choice(['apple', 'pear', 'banana'])
'apple'
>>> random.sample(range(100), 10) # sampling without replacement
[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]
>>> random.random() # random float
0.17970987693706186
>>> random.randrange(6) # random integer chosen from range(6)
4
5 字典删除键值对和合并字典
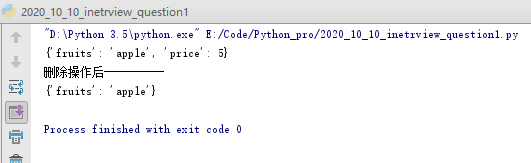
实例1:删除字典
dic1={'fruits':'apple','price':5}
print(dic1)
#进行删除操作
print('删除操作后----------')
del dic1['price']
print(dic1)
打印结果:
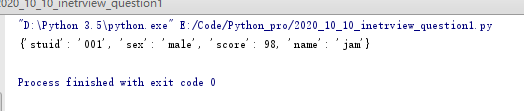
实例2:合并字典
dic1={'name':'jam','sex':'male'}
dic2={'stuid':'001','score':98}
#字典拆包操作
new_dic={**dic1,**dic2}
print(new_dic)
打印结果:
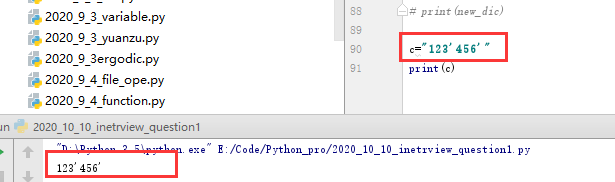
6 单引号、双引号、三引号区别
6.1 单引号
都可以引用一个字符串
6.2 双引号
都可以引用一个字符串
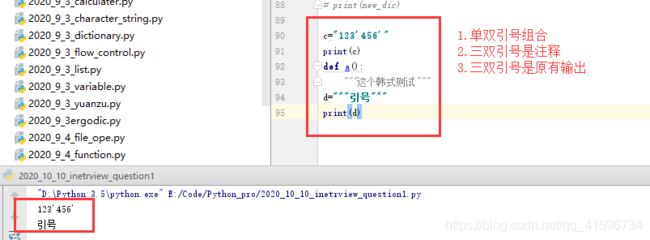
6.3 三引号
推荐三双引号
7 列表去重
#方法1
list1=[1,2,3,4,5,2,3]
new_list=[]
for i in list1:
if i not in new_list:
new_list.append(i)
print('方法一输出结果:',new_list)
#方法2
print('方法二输出结果:',list(set(list1)))
打印结果:
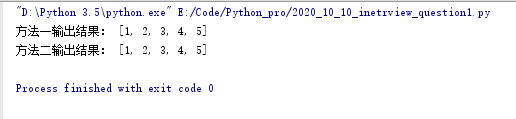
一般使用方法2
8 *args 和**kwargs的理解
#固定参数
#固定参数,可变参数args,默认参数,可变参数kwargs
#args运行传入多个元素,kwargs可以传入键值对
def atest(name,*args,flag=True,**kwargs):
print(name,args)
print(kwargs)
print(flag)
if __name__ == '__main__':
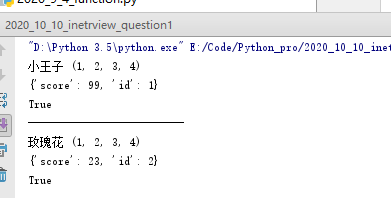
atest('小王子',*(1,2,3,4),flag=True,**{"id":1,"score":99})
print("--------------------------")
atest('玫瑰花',*(1,2,3,4),flag=T
打印结果:
9 单下划线和双下划线的区别
以下介绍命名方法:
1)object #共用方法
2) __ object __ #内建方法,用户不要这样定义
3)__object #全私有方法,相当于private
4)_object #半保护(protected)
单下划线开头(protcted变量),这个称为保护变量,意思是只有类对象和子类对象可以访问这些变量
双下划线开发为私有变量,只有类本身才可以访问这些变量,子类对象也不能访问
10 AOP和装饰器
AOP:在运行、编译时,类和方法加载时,动态地将代码切入到类的指定方法,指定位置上的编程思想就是面向切面的编程。
切入到指定类指定方法的代码片段称为切面,而切入到哪些类、哪些方法就叫切入点。
有了AOP,我们可以把几类共有 的代码,抽取到一个切片中,等到需要时再切入对象中去,从而改变原有的行为。
这样的做法,对原有代码毫无入侵性
装饰器,是一个设计模式,经常被用于有切面需求的场景。
经典用法:插入日志、性能测试、事务处理。
装饰器是解决这类问题的绝佳设计,有了装饰器,我们可以抽离出大量函数中与函数功能本身无关的雷同代码并继续重用。
装饰器作用:
就是为已经存在的对象添加额外的功能。
import time
#判断是否为质数
def is_prime(num):
if num<2:
return False
elif num==2:
return True
else:
for i in range(2,num):
if num % i ==0:
return False
return True
#装饰器
def display_time(func):
#运行需要装饰的方法,*args可以输入多个参数
def wrapper(*args):
t1 = time.time()
result=func(*args)
t2 = time.time()
#保留时间为4位小数
print('Total time:{:.4}s'.format(t2-t1))
return result
return wrapper
#需要装饰的方法:传入参数进行判断
#运用装饰器
@display_time
def prime_nums(maxnum):
count=0
for i in range(2,maxnum):
if is_prime(i):
count=count+1
return count
print(prime_nums(10000))
打印结果:

11 Python3数据类型有哪些
数字、字符串、列表、字典、元祖、集合
1、数字
(int,float,complex、bool,例如a, b, c, d = 20, 5.5, True, 4+3j)
在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
2、字符串 (str)
Python中的字符串用单引号 ’ 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。
注意:
1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变。
3、列表 (list)
表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
注意:
1、List写在方括号之间,元素用逗号隔开。
2、和字符串一样,list可以被索引和切片。
3、List可以使用+操作符进行拼接。
4、List中的元素是可以改变的。
4、元祖 (tuple)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
注意:
1、与字符串一样,元组的元素不能修改。
2、元组也可以被索引和切片,方法一样。
3、注意构造包含 0 或 1 个元素的元组的特殊语法规则。
4、元组也可以使用+操作符进行拼接。
5、字典 (dict)
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
注意:
1、字典是一种映射类型,它的元素是键值对。
2、字典的关键字必须为不可变类型,且不能重复。
3、创建空字典使用 { }。
6、集合 (set)
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,…}
或者
set(value)
注意:
可迭代类型:
str、tuple、list、set、dict
可变数据:列表、字典、集合
不可变数据:数字、字符串、元祖
12 __init__和__new__的使用
1) init:是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值,是实例方法。
2)new:是在实例创建之前被调用的,因为它的任务就是创建实例然后就返回该实例,是个静态方法。
作用:
__new__方法主要是当你继承一些不可变的class时(比如int, str, tuple), 提供给你一个自定义这些类的实例化过程的途径。还有就是实现自定义的metaclass。
注意:
_new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
实例:
class A:
def __new__(cls, *args, **kwargs):
#实现单例模式,改变new这个方法,创建两个实例,实际是用的一个实例
if not hasattr(cls,'_ins'):
cls._ins=super().__new__(cls)
print('in__new')
return cls._ins
def __init__(self,title):
print('in——init')
super().__init__()
self.titie=title
if __name__ == '__main__':
a=A('The Spider Book')
print(a.titie)
a2=A('The 2 Spider Book')
print(id(a))
print(id(a2))
print(a.titie)
print(a2.titie)
打印结果:

13 简述with方法打开处理文件帮我们坐了什么
#以上写法可以避免因读取文件时异常发生没有关闭问题的处理,但代码不够优雅,解决办法如下
# 以r开头,那么说明后面的字符,都是普通的字符了,即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
with open(r'./sun.txt','r') as f:
data=f.read()
#with的实现
class Test:
def __enter__(self):
print('__enter__() is call')
return self
def dosomething(self):
print('dosomething')
def __exit__(self, exc_type, exc_val, exc_tb):
print('__exit()__ is call1')
print(f'type:{exc_type}')
print(f'value:{exc_val}')
print('__exit()__ is call2')
return True
with Test() as sample:
pass
#当对象实例化时,就会主动调用__enter__()方法,任务执行完成后就会调用__exit__()方法
#另外,注意到,__exit__()方法是带有3个参数的(exc_type,exc_value,traceback)
#依据上面的官方说明,如果上下文运行时没有发生异常,那么三个参数都会为None
14 map和列表推导式的题目
map() 会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
给定一个列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25];
并使用列表推导式提取出大于10的数,最终输出[16,25]。
#给定一个列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25]
#并使用列表推导式提取出大于10的数,最终输出[16,25]
a=[1,2,3,4,5]
#用map
new_a=map(lambda x:x**2,a)
#new_a是map对象所有需要进一步转换为list
a1=list(new_a)
print(a1)
#用列表推导式
print([i for i in a1 if i>10])
15 随机数生成
import random
import numpy
#生成随机整数1-1000
print(random.randint(1,1000))
#生成随机小数
print(numpy.random.randn())
#生成0-1之间小数
print(random.random())
#生成0-5之间的小数
print(random.uniform(0,5))
16 Python中的自省
#自省是面向对象的语言缩写程序在运行时,能知道对象的类型,就是运行时可以知道对象的类型
#例如 type() dir() getattr() hasattr() isinstance()
from collections.abc import Sequence,Mapping #判断对象为序列和字典
class Demo(object):
def __init__(self):
pass
def set_msg(self):
print('set msg')
def get_msg(self):
print('get msg')
def run():
demo=Demo()
#以下两句代码打印数据一致,getattr()函数用于返回一个对象属性值
# object -- 对象。
# name -- 字符串,对象属性。
# default -- 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
demo.set_msg()
a=getattr(demo,'set_msg')()
#isinstance 一个类是否是另一个的子类
print(isinstance(True,int)) #True
b={"a":1,"b":2}
print(isinstance(b,Mapping)) #True
if __name__ == '__main__':
run()
17 匹配标签内容
# 中国,匹配标签里面内容(“中国”),其中class类名是不确定的
#匹配除"\n"之外的任何单个字符
#表达式 .* 就是单个字符匹配任意次,就是贪婪匹配
#表达式 .*? 是满足条件的情况只能匹配一次,就是小匹配
#方法1:使用正则表达式
import re
print('方法一:使用正则表达式匹配“中国”出中国--------------------')
source='''
中国
'''
patten=re.compile('(.*?)')
target=patten.findall(source)[0]
print(target)
print('方法二:使用xpath匹配“中国”出中国--------------------')
#方法2:使用xpath
from lxml import html
root=html.fromstring(source)
# _content=root.xpath("//div[@class]/text()")
_content=root.xpath("string(//div[@class])")
# content=_content[0] if _content else None
if _content and isinstance(_content,list):
content=_content[0]
elif isinstance(_content,str):
content=_content
print(content)
18 Python中断言的使用方法
| 断言方法 | 断言描述 |
|---|---|
| assertEqual(arg1, arg2, msg=None) | 验证arg1=arg2,不等则fail |
| assertNotEqual(arg1, arg2, msg=None) | 验证arg1 != arg2, 相等则fail |
| assertTrue(expr, msg=None) | 验证expr是true,如果为false,则fail |
| assertFalse(expr,msg=None) | 验证expr是false,如果为true,则fail |
| assertIs(arg1, arg2, msg=None) | 验证arg1、arg2不是同一个对象,是则fail |
| assertIsNot(arg1, arg2, msg=None) | 验证arg1、arg2不是同一个对象,是则fail |
| assertIsNone(expr, msg=None) | 验证expr是None,不是则fail |
| assertIsNotNone(expr, msg=None) | 验证expr不是None,是则fail |
| assertIn(arg1, arg2, msg=None) | 验证arg1是arg2的子串,不是则fail assertNotIn(arg1, arg2, msg=None) |
| assertIsInstance(obj, cls, msg=None) | 验证obj是cls的实例,不是则fail |
| assertNotIsInstance(obj, cls, msg=None) | 验证obj不是cls的实例,是则fail |
import unittest
class Wtest(unittest.TestCase):
def test1(self):
'''判断a等于b'''
a=1
b='a'
try:
self.assertEquals(a,b)
print('test1测试通过')
except:
print('test1测试失败:a!=b')
def test2(self):
'''判断a等于b'''
a=1
b=2
try:
self.assertEquals(a, b)
print('test2测试通过')
except:
print('test2测试失败:a!=b')
def test3(self):
'''判断a is True'''
a=0
try:
self.assertTrue(a)
print('test3测试通过,a is True')
except:
print('test3测试失败,a is not True')
if __name__ == '__main__':
unittest.main()
19 pass 的作用
空语句,保证格式完成、保证语义完整,写程序时,执行语句部分思路没有完成可以用pass来占位,后面再来完成代码。
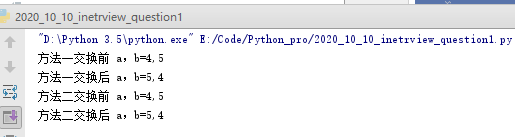
20 交互变量
#交换变量
#方法一
def demo1():
'''a和b交换值'''
a=4
b=5
c=0
print('方法一交换前 a,b={0},{1}'.format(a,b))
c=a
a=b
b=c
print('方法一交换后 a,b={0},{1}'.format(a,b))
#方法二交换两个值
def demo2():
a,b=4,5
print('方法二交换前 a,b={0},{1}'.format(a, b))
a,b=b,a
print('方法二交换后 a,b={0},{1}'.format(a, b))
demo1()
demo2()
打印结果: