大规模分布式存储系统 - 读书笔记
文章目录
- 大规模分布式存储系统(原理解析与架构实战OceanBase)
-
- 第1章 概述
-
- 1.1 分布式存储概述
- 1.2 分布式存储分类
- 第一篇 基础篇
-
- 第2章 单机存储系统
-
- 2.1 硬件基础
-
- 2.1.1 CPU架构
- 2.1.2 IO总线
- 2.1.3 网络拓扑
- 2.1.4 性能参数
- 2.1.5 存储层次架构
- 2.2 单机存储引擎
-
- 2.2.1 哈希存储引擎
- 2.2.2 B树存储引擎
- 2.2.3 LSM树存储引擎(Log Structured Merge Tree)
- 2.3 数据模型
-
- 2.3.1 文件模型
- 2.3.2 关系模型
- 2.3.3 键值模型
- 2.3.4 SQL与NoSQL
- 2.4 事务与并发控制
-
- 2.4.1 事务
- 2.4.2 并发控制
- 2.5 故障恢复
-
- 2.5.1 操作日志
- 2.5.2 重做日志
- 2.5.3 优化手段
- 2.6 数据压缩
-
- 2.6.1 压缩算法
- 2.6.2 列式存储
- 第3章 分布式系统
-
- 3.1 基本概念
-
- 3.1.1 异常
- 3.1.2 一致性
- 3.1.3 衡量指标
- 3.2 性能分析
- 3.3 数据分布
-
- 3.3.1 哈希分布
- 3.3.2 顺序分布
- 3.3.3 负载均衡
- 3.4 复制
-
- 3.4.1 复制的概述
- 3.4.2 一致性与可用性
- 3.5 容错
-
- 3.5.1 常见故障
- 3.5.2 故障检测
- 3.5.3 故障恢复
- 3.6 可扩展性
-
- 3.6.1 总控节点
- 3.6.2 数据库扩容
- 3.6.3 异构系统
- 3.7 分布式协议
-
- 3.7.1 两阶段提交协议(Two-phase Commit,2PC)
- 3.7.2 Paxos协议
- 3.7.3 Paxos与2PC
- 3.8 跨机房部署
- 第二篇 范型篇
-
- 第4章 分布式文件系统
-
- 4.1 Google文件系统
-
- 4.1.1 系统架构
- 4.1.2 关键问题
- 4.1.3 Master设计
- 4.1.4 ChunkServer设计
- 4.1.5 讨论
- 4.2 Taobao File System
-
- 4.2.1 系统架构
- 4.2.2 讨论
- 4.3 Facebook Haystack
-
- 4.3.1 系统架构
- 4.3.2 讨论
- 4.4 内容分发网络
-
- 4.4.1 CDN架构
- 4.4.2 讨论
- 第5章 分布式键值系统
-
- 5.1 Amazon Dynamo
-
- 5.1.1 数据分布
- 5.1.2 一致性与复制
- 5.1.3 容错
- 5.1.4 负载均衡
- 5.1.5 读写流程
- 5.1.6 单机实现
- 5.1.7 讨论
- 5.2 淘宝Tair
-
- 5.2.1 系统架构
- 5.2.2 关键问题
- 5.2.3 讨论
- 第6章 分布式表格系统
-
- 6.1 Google Bigtable
-
- 6.1.1 架构
- 6.1.2 数据分布
- 6.1.3 复制与一致性
- 6.1.4 容错
- 6.1.5 负载均衡
- 6.1.6 分裂与合并
- 6.1.7 单机存储
- 6.1.8 垃圾回收
- 6.1.9 讨论
- 6.2 Google Megastore
-
- 6.2.1 系统架构
- 6.2.2 实体组
- 6.2.3 并发控制
- 6.2.4 复制
- 6.2.5 索引
- 6.2.6 协调者
- 6.2.7 读取流程
- 6.2.8 写入流程
- 6.2.9 讨论
- 6.3 Windows Azure Storage
-
- 6.3.1 整体架构
- 6.3.2 文件流层
- 6.3.3 分区层
- 6.3.4 讨论
- 第7章 分布式数据库
-
- 7.1 数据库中间层
-
- 7.1.1 架构
- 7.1.2 扩容
- 7.1.3 讨论
- 7.2 Microsoft SQL Azure
-
- 7.2.1 数据模型
- 7.2.2 架构
- 7.2.3 复制与一致性
- 7.2.4 容错
- 7.2.5 负载均衡
- 7.2.6 多租户
- 7.2.7 讨论
- 7.3 Google Spanner
-
- 7.3.1 数据模型
- 7.3.2 架构
- 7.3.3 复制与一致性
- 7.3.4 TrueTime
- 7.3.5 并发控制
- 7.3.6 数据迁移
- 7.3.7 讨论
- 第三篇 实践篇
-
- 第8章 OceanBase架构初探
-
- 8.1 背景简介
- 8.2 设计思路
- 8.3 系统架构
-
- 8.3.1 整体架构图
- 8.3.2 客户端
- 8.3.3 RootServer
- 8.3.4 MergeServer
- 8.3.5 ChunkServer
- 8.3.6 UpdateServer
- 8.3.7 定期合并&数据分发
- 8.4 架构剖析
-
- 8.4.1 一致性选择
- 8.4.2 数据结构
- 8.4.3 可靠性与可用性
- 8.4.4 读写事务
- 8.4.5 单点性能
- 8.4.6 SSD支持
- 8.4.7 数据正确性
- 8.4.8 分层结构
- 第9章 分布式存储引擎
-
- 9.1 公共模块
-
- 9.1.1 内存管理
- 9.1.2 基础数据结构
- 9.1.3 锁
- 9.1.4 任务队列
- 9.1.5 网络框架
- 9.1.6 压缩与解压缩
- 9.2 RootServer实现机制
-
- 9.2.1 数据结构
- 9.2.2 子表复制与负载均衡
- 9.2.3 子表分裂与合并
- 9.2.4 UpdateServer选主
- 9.2.5 RootServer主备
- 9.3 UpdateServer实现机制
-
- 9.3.1 存储引擎
- 9.3.2 任务模型
- 9.3.3 主备同步
- 9.4 ChunkServer实现机制
-
- 9.4.1 子表管理
- 9.4.2 SSTable
- 9.4.3 缓存实现
- 9.4.4 IO实现
- 9.4.5 定期合并&数据分发
- 9.4.6 定期合并限速
- 9.5 消除更新瓶颈
-
- 9.5.1 读写优化回顾
- 9.5.2 数据旁路导入
- 9.5.3 数据分区
- 第10章 数据库功能
-
- 10.1 整体结构
- 10.2 只读事务
-
- 10.2.1 物理操作符接口
- 10.2.2 单表操作
- 10.2.3 多表操作
- 10.2.4 SQL执行本地化
- 10.3 写事务
-
- 10.3.1 写事务执行流程
- 10.3.2 多版本并发控制
- 10.4 OLAP业务支持
-
- 10.4.1 并发查询
- 10.4.2 列式存储
- 10.5 特色功能
-
- 10.5.1 大表左连接
- 10.5.2 数据过期与批量删除
- 第11章 质量保证、运维及实践
-
- 11.1 质量保证
-
- 11.1.1 RD开发
- 11.1.2 QA测试
- 11.1.3 试运行
- 11.2 使用与运维
-
- 11.2.1 使用
- 11.2.2 运维
- 11.3 应用
-
- 11.3.1 收藏夹
- 11.3.2 天猫评价
- 11.3.3 直通车报表
- 11.4 最佳实践
-
- 11.4.1 系统发展路径
- 11.4.2 人员成长
- 11.4.3 系统设计
- 11.4.4 系统实现
- 11.4.5 使用与运维
- 11.4.6 工程现象
- 11.4.7 经验法则
- 第四篇 专题篇
-
- 第12章 云存储
-
- 12.1 云存储的概念
- 12.2 云存储的产品形态
- 12.3 云存储技术
- 12.4 云存储的核心优势
- 12.5 云平台整体架构
-
- 12.5.1 Amazon云平台
- 12.5.2 Google云平台
- 12.5.3 Microsoft云平台
- 12.5.4 云平台架构
- 12.6 云存储技术体系
- 12.7 云存储安全
- 第13章 大数据
-
- 13.1 大数据的概念
- 13.2 MapReduce
- 13.3 MapReduce扩展
-
- 13.3.1 Google Tenzing
- 13.3.2 Microsoft Dryad
- 13.3.3 Google Pregel
- 13.4 流式计算
-
- 13.4.1 原理
- 13.4.2 Yahoo S4
- 13.4.3 Twitter Storm
- 13.5 实时分析
-
- 13.5.1 MPP架构
- 13.5.2 EMC Greenplum
- 13.5.3 HP Vertica
- 13.5.4 Google Dremel
大规模分布式存储系统(原理解析与架构实战OceanBase)
序言
分布式系统理论出现在上个世纪70年代,但其广泛应用确是最近十多年的事情,其中一个原因就是人类活动创造出的数据量远远超出了单个计算机的存储和处理能力。另一个原因是分布式环境下的编程十分困难(异步调用,自己保存和恢复调用前后的上下文,处理更多的异常)。
前言
海量数据处理系统。分布式存储系统由数量众多的、低成本和高性价比的普通PC服务器通过网络连接而成。化纵向扩展为横向扩展,在软件层面实现自动容错,保证数据的一致性,自动负载均衡,使得系统的处理能力得到线性的扩展。
分布式存储是基础,云存储和大数据是构建在分布式存储之上的应用。如果没有分布式存储,便谈不上对大数据进行分析。分布式存储技术是互联网后端架构的“九阳神功”,掌握了这项技能,以后理解其他技术的本质会变得非常容易。
- 基础篇
基础知识包含两个部分:单机存储系统以及分布式系统。其中,单机存储系统的理论基础是数据库技术,包括数据模型、事务与并发控制、故障恢复、存储引擎、数据压缩等;分布式技术涉及数据分布、复制、一致性、容错、可扩展性等分布式技术。另外,分布式存储系统工程师还需要一项基础训练,即性能预估,因此,基础篇也会顺带介绍硬件基础知识以及性能预估方法。 - 范型篇
这部分内容将介绍Google、亚马逊、微软、阿里巴巴等各大互联网公司的大规模分布式存储系统,分为四章:分布式文件系统、分布式键值系统、分布式表格系统以及分布式数据库。 - 实践篇
这部分内容将以笔者在阿里巴巴开发的分布式数据库OceanBase为例详细介绍分布式数据库内部实现以及实践过程中的禁言总结。 - 专题篇
云存储和大数据是近年来兴起的两大热门领域,其底层都依赖分布式存储技术,这部分将简单介绍这两方面的基础知识。
第1章 概述
云计算、大数据以及互联网公司的各种应用,其后台基础设施的主要目标都是构建低成本、高性能、可扩展、易用的分布式存储系统。
相比传统的分布式系统,互联网公司的分布式系统具有两个特点:一个特点是规模大,另一个特点是成本低。不同的需求造就了不同的设计方案。本章介绍大规模分布式系统的定义与分类。
1.1 分布式存储概述
分布式存储系统是大量普通PC服务器通过Internet互联,对外作为一个整体提供存储服务。具备可扩展、低成本、高性能、易用等特性。
分布式存储系统的挑战主要在于数据、状态信息的持久化,要求在自动迁移、自动容错、并发读写的过程中保证数据的一致性。分布式存储涉及的技术主要来自两个领域:分布式系统以及数据库
- 数据分布
- 一致性
- 容错
- 负载均衡
- 事务与并发控制
- 易用性
- 压缩/解压缩
分布式存储系统挑战大,研发周期长,涉及的知识面广。一般来说,工程师如果过能够深入理解分布式存储系统,理解其他互联网后台架构不会再有任何困难。
1.2 分布式存储分类
分布式存储面临的数据需求比较复杂,大致分为三类
- 非结构化数据
- 结构化数据
- 半结构化数据
1.分布式文件系统
分布式文件系统用于存储Blob(Binary Large Object,二进制大对象)对象,此外分布式文件系统也常作为分布式表格系统以及分布式数据库的底层存储。
总体上看,分布式文件系统存储三种类型的数据:Blob对象、定长块以及大文件。分布式文件系统内部按照数据块来组织数据,将这些数据块分散到存储集群,处理数据复制、一致性、负载均衡、容错等分布式系统难题,并将用户对Blob对象、定长块以及大文件的操作映射为对底层数据块的操作。

2.分布式键值系统
分布式键值系统用于存储关系简单的半结构化数据。从数据结构的角度看,分布式键值系统与传统的哈希表比较类似,不同的是,分布式键值系统支持将数据分布到集群中的多个存储节点。
3.分布式表格系统
分布式表格系统用于存储关系较为复杂的半结构化数据。
4.分布式数据库
分布式数据库一般是从单机关系数据库扩展而来,用于存储结构化数据。
第一篇 基础篇
第2章 单机存储系统
单机存储引擎就是哈希表、B树等数据结构在机械磁盘、SSD等持久化介质上的实现。单机存储系统是单机存储引擎的一种封装,对外提供文件、键值、表格或者关系模型。
哈希存储引擎是哈希表的持久化实现,B树存储引擎是B树的持久化实现,而LSM树(Log Structure Merge Tree)存储引擎采用批量转储技术来避免磁盘随机写入。
2.1 硬件基础
计算机的硬件体系架构保持相对稳定。架构设计很重要的一点就是合理选择并且能够最大限度地发挥底层硬件的价值。
2.1.1 CPU架构
为了提高计算机的性能,出现多核处理器,架构也逐渐从SMP(对称多处理结构)过渡到NUMA(Non-Uniform Memory Access,非一致存储访问)架构。
2.1.2 IO总线
存储系统的性能瓶颈一般在于IO。
2.1.3 网络拓扑
传统的数据中心网络拓扑,分为三层,接入层、汇聚层和核心层。Google在2008年的时候将网络改造为扁平化拓扑结构,即三级CLOS网络。
2.1.4 性能参数
存储系统的性能瓶颈主要在于磁盘随机读写。设计存储引擎的时候会针对磁盘的特性做很多的处理,不如将随机写操作转化为顺序写,通过缓存减少磁盘随机读操作。
2.1.5 存储层次架构
存储系统的性能主要包括两个维度:吞吐量以及访问延时,设计系统时要求能够在保证访问延时的基础上,通过最低的成本实现尽可能高的吞吐量。磁盘和SSD的访问时延差别很大,但带宽差别不大。
2.2 单机存储引擎
存储引擎是存储系统的发动机,直接决定了存储系统能够提供的性能和功能。
2.2.1 哈希存储引擎
Bitcask是一个基于哈希表结构的键值存储系统,仅支持追加操作。
1.数据结构
Bitcask在内存中存储了主键和value的索引信息,磁盘文件中存储了主键和value的实际内容。
2.定期合并
将所有老数据文件中的数据扫描一遍合并生成新的数据文件,这里的合并其实就是对同一个key的多个操作以只保留最新一个的原则机型删除,每次合并后,新生成的数据文件就不再有冗余数据了。
3.快速恢复
索引文件就是将内存中的哈希索引表转储到磁盘生成的结果文件。
2.2.2 B树存储引擎
1.数据结构
叶子节点保存每行的完整数据,非叶子结点保存索引信息。B+树的根节点是常驻内存的。修改操作首先需要记录提交日志,接着修改内存中的B+树。
2.缓冲区管理
缓冲区管理器的关键在于替换策略,即选择将哪些页面淘汰出缓冲池
- LRU
LRU算法淘汰最长时间没有读或者写过的块。 - LIRS
为了防止全表扫描导致的缓冲区大量页面被替换,将缓冲池分为两级,这个思想和JVM的虚拟机的内存划分老年代和年轻代的思想有这着异曲同工之妙。
2.2.3 LSM树存储引擎(Log Structured Merge Tree)
将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作写入磁盘,读取时需要合并磁盘中的历史数据和内存中最近的修改操作。
1.存储结构
LevelDB存储引擎主要包括:内存中的MemTable和不可变MemTable(Immutable MemTable,也称为Frozen MemTable,即冻结MemTable,即冻结MemTable)以及磁盘上的几种主要文件:当前(Current)文件、清单(Manifest)文件、操作日志(Commit Log,也称为提交日志)文件以及SSTable文件。
2.合并
LevelDB写入操作很简单,但是读取操作比较复杂。LevelDB的Compaction操作分为两种:minor compaction和major compaction。
2.3 数据模型
如果说存储引擎相当于存储系统的发动机,那么,数据模型就是存储系统的外壳。数据模型大概分为文件、关系以及随着NoSQL技术流行起来的键值模型。
2.3.1 文件模型
文件系统以目录树的形式组织文件。POSIX(Portable Operating System Interface)是应用程序访问文件系统的API标准,定义了文件系统存储接口及操作集。POSIX标准不仅定义了文件操作接口,而且还定义了读写操作语义。POSIX标准适合单机文件系统,在分布式文件系统中,出于性能考虑,一般不会完全遵守这个标准。
2.3.2 关系模型
Select查询语句计算过程大致如下(不考虑查询优化):
- 取FROM子句中列出的各个关系的元组和所有可能的组合
- 将不符合WHERE子句中给出的条件的元组去掉
- 如果有GROUP BY子句,则将剩下的元组按GROUP BY子句中给出的属性的值分组
- 如果有HAVING子句,则按照HAVING子句中给出的条件检查每一个组,去掉不符合条件的组
- 按照SELECT子句的说明,对于指定的属性和属性上的聚集(例如求和)计算出结果元组
- 按照ORDER BY子句中的属性列的值对结果元组进行排序
2.3.3 键值模型
大量的NoSQL系统采用了键值模型(Key-Value模型),每行记录由主键和值两个部分组成。Key-Value模型过于简单,支持的应用场景有限,NoSQL系统中使用比较广泛的模型是表格模型(没有一个统一的标准)。
2.3.4 SQL与NoSQL
NoSQL系统带来了很多新的理念,比如良好的可扩展性,弱化数据库的设计范式,弱化一致性要求,在一定程度上解决了海量数据和高并发的问题。NoSQL只是对SQL特性的一种取舍和升华,使得SQL更加适应海量数据的应用场景,二者的优势将不断融合。
关系数据库在海量数据场景中,面临着事务,联表,性能等问题。然而NoSQL系统也面临如下问题,缺少统一标准,使用以及运维复杂。
总而言之,不必纠结SQL和NoSQL的区别,而是借鉴二者各自不同的优势,着重理解关系数据库的原理以及NoSQL系统的高可扩展性。
2.4 事务与并发控制
事物的概念和特性。为了性能的考虑,定义多种合理级别。并发控制通过锁机制来实现。互联网业务中读事务的比例往往远远高于写事务,为了提高读事务性能,可以采用写时复制(Copy-On-Write,COW)或者多版本并发控制(Multi-Version Concurrency Control,MVCC)技术来避免写事务阻塞读事务。
2.4.1 事务
事务是数据库操作的基本单位,它具有原子性、一致性、隔离性和持久性这四个基本属性。
隔离级别与读写异常的关系。
2.4.2 并发控制
- 数据库锁
- 写时复制(Copy-On-Write,COW)
- 多版本并发控制(Multi-Version Concurrency Control,MVCC)
2.5 故障恢复
数据库系统以及其他的分布式存储系统一般采用操作日志技术来实现故障恢复。
2.5.1 操作日志
通过操作日志顺序记录每个数据库操作并在内存中执行这些操作,内存中的数据定期刷新到磁盘,实现将随机写请求转化为顺序写请求。
2.5.2 重做日志
REDO日志的约束规则:在修改内存中的元素X之前,要确保与这一修改相关的操作日志必须先刷入磁盘中。
2.5.3 优化手段
- 成组提交
定期刷入磁盘,如果存储系统意外故障,可能丢失最后一部分更新操作。与定期刷入磁盘不同的是,成组提交技术保证REDO日志成功刷入磁盘后才返回写操作成功。这种做法可能会牺牲写事务的延迟,但大大提高了系统的吞吐量。 - 检查点
将内存中的数据定期转储(Dump)到磁盘,这种技术称为checkpoint(检查点)技术。如果同一个操作执行一次与重复执行多次的效果相同,这种操作具有“幂等性”。有些操作不具备这种特性,例如加法操作、追加操纵。
2.6 数据压缩
数据压缩分为有损压缩与无损压缩两种。压缩算法的核心是找出重复数据,列式存储技术通过把相同列的数据组织在一起,不仅减少了大数据分析需要查询的数据量,还大大地提高了数据的压缩比。
2.6.1 压缩算法
压缩是一个专门的研究课题,需要根据数据的特点选择或者自己开发和是的算法。压缩的本质就是找数据的重复或者规律,用尽量少的字节表示。
存储系统在选择压缩算法时需要考虑压缩比和效率,压缩比和读写数据两者之间需要一个很好的权衡点。Google Bigtable系统中通过牺牲一定的压缩比换取算法执行速度的大幅提升,从而获得更好的折中。
- Huffman编码
Huffman编码需要解决的问题是,如何找出一种前缀编码方式,使得编码的长度最短。 - LZ系列压缩算法
LZ系列压缩算法是基于字典的压缩算法。LZ系列的算法是一种动态创建字典的方法,压缩过程中动态创建字典并保存在要锁信息里面。
算法存在的问题:
1)如何区分匹配信息和源信息?通用的解决方法是额外使用一个位(bit)来区分压缩信息里面的源信息和匹配信息。
2)需要使用多少个字节表示匹配信息?记录重复信息的匹配信息包含两项,一个是匹配串的相对位置,另一个是匹配的长度。例如,可以采用固定的两个字节来表示匹配信息,其中,1位用来区分源信息和匹配信息,11位表示匹配位置,4位表示匹配长度。这样,压缩算法支持的最大数据窗口为2的11次方=为2048字节,支持重复串的最大长度为2的4次方=16字节。当然,也可以采用边长的方式表示匹配信息。
3)如何快速查找最长匹配串?最容易想到的做法是把字符串的所有字串都存放到一张哈希表中。这样做法的运行效率很低,实际的做法往往会做一些改进。例如,哈希表中只保存所有长度为3的子串,如果在数据字典中找到匹配串,即前3个字节相同,接着再往后顺序遍历找出最长匹配。 - BMDiff与Zippy
这两个压缩算法也属于LZ系列,相比传统的LZW或者Gzip,这两种算法的压缩比不算高,但是处理速度非常快。
1)Zippy算法的压缩字典只保存最后一个长度等于4的字串的位置,这种方式牺牲了压缩比,但是提升了性能。
2)Zippy内部将数据划分为一个一个长度为32KB的数据块,每个数据块分别压缩,多个数据之间没有联系。
2.6.2 列式存储
传统的行式数据库将一个个完整的数据行存储再数据页中。列式数据库是将同一个数据列的各个值存放在一起。很多列式数据库还支持列组(column group,Bigtable系统中称为locality group),即将多个经常一起访问的数据列的各个值存放在一起。列组是一种行列混合存储模式,这种模式能够同时满足OLTP和OLAP的查询需求。
由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。
第3章 分布式系统
介绍分布式系统相关的基础概念和性能估算方法。接着,介绍分布式系统的基础理论知识,包括数据分布、复制、一致性、容错等。最后介绍常见的分布式协议。
3.1 基本概念
3.1.1 异常
大规模分布式存储系统的一个核心问题在于自动容错。然而,服务器节点是不可靠的,网络也是不可靠的,本节介绍系统运行过程中可能会遇到的各种异常。
- 异常类型
1)服务器宕机
2)网路异常
3)磁盘故障 - 超时
分布式存储系统的三态:成功、失败、超时(未知状态)
RPC的执行结果为超时的时候,客户端不能简单地认为服务器端处理失败。当出现超时状态时,只能通过不断读取之前操作的状态来验证RPC操作是缶成功。覆盖写是一种常见的幂等操作。
3.1.2 一致性
可以这么认为,副本是分布式存储系统容错技术的唯一手段。由于多个副本的存在,如何保证副本之间的一致性是整个分布式系统的理论核心。
可以从两个角度理解一致性:第一个角度是用户,或者说是客户端,即客户端读写操作是否符合某种特性;第二个角度是存储系统,即存储系统的多个副本之间是否一致,更新的顺序是否相同。
- 客户端角度
强一致性
弱一致性
最终一致性
最终一致性变体(读写一致性、会话一致性、单调读一致性、单调写一致性) - 存储系统的角度
副本一致性
更新顺序一致性
3.1.3 衡量指标
评价分布式存储系统的一些常用的指标
- 性能
系统的吞吐能力以及系统的响应时间 - 可用性
系统停服务的时间与正常服务的时间的比例来衡量 - 一致性
越是强的一致性模型,用户使用起来越简单 - 可扩展性
分布式存储系统通过扩展集群服务器规模来提高系统存储容量、计算量和性能的能力。“线性可扩展”
3.2 性能分析
性能分析是作为后续性能优化的依据。系统中的资源(CPU、内存、磁盘、网络)是有限的,性能分析就是需要找出可能出现的资源瓶颈。
- 生成一张有30张缩略图(假设图片原始大小为256KB)的页面需要多少时间?
顺序操作
并行操作 - 1GB的4字节整数,执行一次快速排序需要多少时间?
排序时间=比较时间(分支预测错误)+内存访问时间 - Bigtable系统性能分析
只有理解存储系统的底层设计和实现,并在实践中不断地练习,性能估才会越来越准
3.3 数据分布
数据分布的方式主要有两种,一种是哈希分布,另一种方法是顺序分布。分布式存储系统的一个基本要求就是透明性,包括数据分布透明性,数据迁移透明性,数据复制透明性,故障处理透明性。
3.3.1 哈希分布
哈希取模的方法很常见,其方法是根据数据的某一种特征计算哈希值,并将哈希值与集群中的服务器建立映射关系,从而将不同哈希值的数据分布到不同的服务器上。
传统的哈希分布算法还有一个问题:当服务器上线或者下线时,N值发生变化,数据映射完全被打乱,几乎所有的数据都需要重新分布,这将带来大量的数据迁移。解决方法有增加元数据服务器和一致性哈希(Distrid Hash Table,DHT)算法(在很大程度上避免了数据迁移)
3.3.2 顺序分布
哈希散列破坏了数据的有序性,只支持随机读取操作,不能够支持顺序扫描。顺序分布与B+树数据结构比较类似,每个子表相当于叶子节点,随着数据的插入和删除,某些子表可能变得很大,某些变得很小,数据分布不均匀。
3.3.3 负载均衡
分布式存储系统的每个集群中一般有一个总控节点,其他节点为工作节点,由总控节点根据全局负载信息进行整体调度。
3.4 复制
分布式存储系统通过复制协议将数据同步到多个存储节点,并确保多个副本之间的数据一致性。
同一份数据的多个副本中往往由一个副本为主副本(Primary),其他副本为备副本(Backup),由主副本将数据复制到备份副本。复制协议分为两种,强同步复制以及异步复制,二者的区别在于用户的写请求是否需要同步到备副本才可以返回成功。
一致性和可用性时矛盾的。
3.4.1 复制的概述
强同步复制和异步复制都是将主副本的数据以某种形式发送到其他副本,这种复制协议称为基于主副本的复制协议(Primary-based protocol)。
主备副本之间的复制一般通过操作日志来实现。操作日志的原理很简单:为了利用好磁盘的顺序读写特性,将客户端的写操作先顺序写入磁盘中,然后应用到内存中,由于内存是随机读写设备,可以很容易通过各种数据结构,比如B+树将数据有效地组织起来。
3.4.2 一致性与可用性
CAP理论:一致性(Consistency),可用性(Availability)以及分区可容忍性(Tolerance of network Partition)三者不能同时满足。
工程理解CAP
- 一致性:
读操作总是能读取之前完成的写操作结果,满足这个条件的系统称为强一致性系统,这里的“之前”一般对同一个客户端而言; - 可用性
读写操作在单台机器发生故障的情况下仍然能够正常执行,而不需要等待发生故障的机器重启或者其上的服务迁移到其他服务; - 分区可容忍性
机器故障、网络故障、机房停电等异常情况下仍然能够满足一致性和可用性
分布式存储系统要求能够自动容错,也就是说,分区可容忍性总是需要满足的,因此,一致性和写操作的可用性不能同时满足。
3.5 容错
首先,分布式存储系统需要能够检测到机器故障,在分布式系统中,故障检测往往通过租约(Lease)协议实现。接着,需要能够将服务复制或者迁移到集群中的其他正常服务的存储节点。
3.5.1 常见故障
单机故障和磁盘故障发生概率最高,几乎每天都有多起事故,系统设计首先需要对单台服务器故障进行容错处理。
3.5.2 故障检测
心跳是一种很自然的想法。存在的问题是“机器B是否应该被认为故障且停止服务”达成一致,通过租约(Lease)机制进行故障检测。租约机制就是带有超时时间的一种授权。
3.5.3 故障恢复
当总控机检测到工作机发生故障时,需要将服务迁移到其他工作机节点。常见的分布式存储系统分为两种结构:单层机构和双层结构。
3.6 可扩展性
可扩展性不能简单地通过系统是否为P2P架构或者是否能够将数据分布到多个存储节点来衡量,而应该综合考虑节点故障后的恢复时间,扩容的自动化程度,扩容的灵活性等。
3.6.1 总控节点
分布式存储系统种往往有一个总控节点用于维护数据分布信息,执行工作机管理,数据定位,故障检测和恢复,负载均衡等全局调度工作。一般情况,总控节点不会成为瓶颈。
3.6.2 数据库扩容
数据库可扩展性实现的手段包括:通过主从复制提高系统的读取能力,通过垂直拆分和水平拆分将数据分布到多个存储节点,通过主从复制将系统扩展到多个数据中心。
传统的数据库架构在可扩展性上面临如下问题
- 扩容不够灵活
- 扩容不够自动化
- 增加副本时间长
3.6.3 异构系统
传统数据库扩容与大规模存储系统的可扩展性有何区别呢?
将存储节点分为若干组,某个组内的节点服务完全相同的数据,其中有一个节点为主节点,其他节点为备节点。由于同一个组内的节点服务相同的数据,这样的系统称为同构系统。而异构系统是为了实现线性可扩展性,将数据划分为很多大小接近的分片,每个分片的多个副本可以分布到集群种的任何一个存储节点。如果某个节点放生故障,原有的服务将由整个集群而不是某几个固定的存储节点来恢复,由于整个集群都参与到节点1的故障恢复过程,故障恢复时间很短,而且集群规模越大,优势就会越明显。
3.7 分布式协议
两阶段提交协议用于保证跨多个节点操作的原子性,也就是说,跨多个节点的操作要么在所有节点上全部执行成功,要么全部失败。Paxos协议用于确保多个节点对某个投票(例如哪个节点为主节点)达成一致。
3.7.1 两阶段提交协议(Two-phase Commit,2PC)
两阶段提交协议经常用来实现分布式事务,在此过程中包括协调者和事务参与者两类节点。正常执行过程分为请求阶段和提交阶段。
可能会面临两种故障:事务参与者发生故障和协调者发生故障。总而言之,两阶段提交协议是阻塞协议,执行过程中需要锁住其他更新,且不能容错,大多数分布式存储系统都采用敬而远之的做法,放弃对分布式事务的支持。
3.7.2 Paxos协议
Paxos协议用于解决多个节点之间的一致性问题。主节点发生故障,系统选举新的主节点,存在网络分区的时候,有可能存在多个备节点提议(Proposer,提议者)自己成为主节点。Paxos协议正是用来实现这个需求。
3.7.3 Paxos与2PC
常见的做法是将2PC和Paxos协议集合起来,通过2PC保证多个数据分片上的操作的原子性,通过Paxos协议实现同一个数据分片的多个副本之间的一致性。另外,通过Paxos协议解决2PC协议中协调者宕机问题。当2PC协议中的协调者出现故障时,通过Paxos协议选举出新的协调者继续提供服务。
3.8 跨机房部署
跨机房问题主要包含两个方面:数据同步以及服务切换。
跨机房部署三个方案
- 集群整体切换
- 单个集群跨机房
- Paxos选主副本
第二篇 范型篇
第4章 分布式文件系统
分布式文件系统的主要功能有两个:一个是存储文档、图像、视频之类的Blob类型数据;另外一个是作为分布式表格系统的持久化层。
4.1 Google文件系统
GFS是Google分布式存储的基石。Google文件系统(GFS)是构建在廉价服务器之上的大型分布式系统。
4.1.1 系统架构
GFS系统的节点可分为三种角色:GFS Master(主控服务器)、GFS ChunkServer(CS,数据块服务器)以及GFS客户端
主控服务器会定期与CS通过心跳的方式交换信息。需要注意的是,GFS种的客户端不缓存文件数据,只缓存主控服务器种获取的元数据,这是由GFS的应用特点决定的。GFS最主要的应用有两个:MapReduce与Bigtable。
4.1.2 关键问题
- 租约机制
为防止因每次追加记录都要请求Master而使得Master成为系统的性能瓶颈,因此GFS系统中通过租约(lease)机制将chunk写操作授权给ChunkServer。 - 一致性模型
GFS主要是为了追加(append)而不是改写(overwrite)而设计的。GFS的这种一致性模型是追求性能导致的,这增加了应用程序开发的难度。 - 追加流程
追加流程是GFS系统中最为复杂的地方,而且,高效支持记录追加对基于GFS实现的分布式表格系统Bigtable是至关重要的。
GFS追加流程有两个特色:流水线及分离数据流与控制流。流水线操作用来减少延时。分离数据流与控制流主要是为了优化数据传输,每一台机器都是把数据发送给网络拓扑图上“最近”的尚未收到数据的数据节点。 - 容错机制
(1)Master容错
Master上保存了三种元数据信息:命名空间(Name Space),也就是整个文件系统的目录结构以及chunk基本信息;文件到chunk之间的映射;chunk副本的位置信息,每个chunk通常有三个副本。
(2)ChunkServer容错
GFS采用复制多个副本的方式实现ChunkServer的容错,另外ChunkServer会对存储的数据维持校验和。
4.1.3 Master设计
- Master内存占用
Master内存容量不会成为GFS的系统瓶颈。Master维护了系统中的元数据,包括文件及chunk命名空间、文件到chunk之间的映射、chunk副本的位置信息。其中前两种元数据需要持久化到磁盘,chunk副本的位置信息不需要持久化,可以通过ChunkServer汇报获取。 - 负载均衡
系统中需要创建chunk副本的情况有三种:chunk创建、chunk复制(re-replication)以及负载均衡(rebalancing)。 - 垃圾回收
GFS采用延迟删除的机制,也就是说,当删除文件后,GFS并不要求立即归还可用的物理存储,而是在元数据中将文件改名为一个隐藏的名字,并且包含一个删除时间戳。 - 快照
快照(Snapshot)操作是对源文件/目录进行一个“快照”操作,生成该时刻源文件/目录的一个瞬间状态存放于目标文件/目录中。GFS中使用标准的写时复制机制生成快照。
4.1.4 ChunkServer设计
Linux文件系统删除64MB大文件消耗的时间太久且没有必要,因此,删除chunk时可以只将对应的chunk文件移动到每个磁盘的回收站,以后新建chunk的时候可以重用。
ChunkServer是一个磁盘和网络IO密集型应用,为了最大限度地发挥机器性能,需要能够做到将磁盘和网络操作异步化,但这会增加代码实现的难度。
4.1.5 讨论
从GFS的架构设计可以看出,GFS是一个具有良好可扩展性并能够在软件层面自动处理各种异常情况的系统。
Google的成功经验也表明了一点:单Master的设计是可行的。单Master的设计不仅简化了系统,而且能够较好地实现一致性,后面我们将要看到的绝大多数分布式存储系统都和GFS一样依赖单总控节点。
4.2 Taobao File System
文档、图片、视频一般称为Blob数据,存储Blob数据的文件系统也相应地称为Blob存储系统。Blob文件系统的特点是数据写入后基本都是只读,很少出现更新操作。
TFS架构设计时需要考虑两个问题:Metadata信息存储和减少图片读取的IO次数
TFS设计时采用的思路是:多个逻辑图片文件共享一个物理文件
4.2.1 系统架构
TFS架构上借鉴了GFS,但与GFS又有很大的不同。首先,TFS内部不维护文件目录树,每个小文件使用一个64位的编号表示;其次,TFS是一个读多写少的应用,相比GFS,TFS的写流程可以做得更加简单有效。
- 追加流程
TFS是写少读多的应用,即使每次写操作都需要经过NameNode也不会出现问题,大大简化了系统的设计。另外,TFS中也不需要支持类似GFS的多客户端并发追加操作,同一时刻每个Block只能有一个写操作,多个客户端的写操作会被串行化。
相比GFS,TFS的写流程不够优化,第一,每个写请求都需要多次访问NameServer;第二,数据推送也没有采用流水线方式减小延迟。淘宝的系统是需求驱动的,用最简单的方式解决用户面临的问题。
TFS的一致性模型保证所有返回给客户端的表示的图片数据在TFS中的所有副本都是有效的。 - NameServer
NameServer主要功能是:Block管理,包括创建、删除、复制、重新均衡;Data-Server管理,包括心跳、DataServer加入及退出;以及管理Block与所在DataServer之间的映射关系。
4.2.2 讨论
图片应用中有几个问题,第一个问题是图片去重,第二个问题是图片更新与删除。去重使用的是在外部维护一套文件级别的去重系统(Dedup),采用MD5或者SHA1等Hash算法为图片文件计算指纹(FingerPrint)。去重是一个键值存储系统,淘宝内部使用Tair来进行图片去重。
图片在TFS中的位置是通过
4.3 Facebook Haystack
Facebook相册后端早期采用基于NAS的存储,通过NFS挂载NAS中的照片文件来提供服务。
4.3.1 系统架构
HayStack系统主要包括三个部分:目录(Directory)、存储(Store)以及缓存(Cache)。
- 写流程
处理流程:Web服务器首先请求Haystack目录获取可写的逻辑卷轴,接着生成照片唯一id并将数据写入每一个对应的物理卷轴。写操作成功要求所有的物理卷轴都成功,如果中间出现故障,需要重试。 - 容错处理
(1)Haystack存储节点容错
检测到存储节点故障时,所有物理卷轴对应的逻辑卷轴都被标记为只读。
(2)Haystack目录容错
Haystack目录采用主备数据库(Replicated Database)做持久化存储,由主备数据库提供容错机制。 - Haystack目录
- Haystack存储
写操作首先更新物理卷轴文件,然后异步更新索引文件。Haystack Store存储节点采用延迟删除的回收策略,删除照片只是向卷轴中追加一个带有删除标记的Needle,定时执行Compaction任务回收已删除空间。所谓的Compaction操作,即将所有老数据文件中的数据扫描一遍,以保留最新一个照片的原则进行删除,并生成新的数据文件。
4.3.2 讨论
相比TFS,Haystack的一大特色就是磁盘空间回收。
4.4 内容分发网络
CDN通过将网络内容发布到靠近用户的边缘节点,使不同地域的用户在访问相同网页时可以就近获取。这样既可以减轻源服务器的负担,也可以减少整个网络中的流量分布不均的情况,进而改善整个网络性能。
4.4.1 CDN架构
CDN采用两级Cache:L1-Cache以及L2-Cache。图片服务器是一个运行着Nginx的Web服务器,它还会在本地缓存图片,只有当本地缓存也不命中时才会请求后端的TFS集群,图片服务器集群和TFS集群部署在同一个数据中心内。
每个CDN节点内部通过LVS+Haproxy的方式进行负载均衡。其中,LVS是四层负载均衡软件,性能好。Haproxy是七层负载均衡软件,能够支持更加灵活的负载均衡策略。数据通过一致性哈希的方式分布到不同的Squid服务器,使得增加/删除服务器只需要移动1/n(n为Squid服务器总数)的对象。
相比分布式存储系统,分布式缓存系统的实现要容易很多。这是因为缓存系统不需要考虑数据持久化,如果缓存服务器出现故障,只需要简单地将它从集群中剔除即可。
- 分级存储
分级存储是淘宝CDN架构的一个很大创新。缓存数据有较高的局部性,图片数据随热点变化而迁移,最热门的存储到SSD,中等热度的存储到SAS,轻热度的存储到SATA。通过这样的方式,能够很好地结合SSD的性能和SAS、SATA磁盘的成本优势。 - 低功耗服务器定制
淘宝CDN架构的另外一个亮点是低功耗服务器定制。CDN缓存服务是IO密集型而不是CPU密集型的服务,选用Intel Atom CPU定制低功耗服务器即可。
4.4.2 讨论
由于Blob存储系统读访问量大,更新和删除很少,特别适合通过CDN技术分发到离用户最近的节点。CDN也是一种缓存,需要考虑与源服务器之间的一致性。
第5章 分布式键值系统
分布式键值模型可以看成是分布式表格模型的一种特例。
5.1 Amazon Dynamo
Dynamo以很简单的键值方式存储数据,不支持复杂的查询。Dynamo中存储的是数据值的原始形式,不解析数据的具体内容。
5.1.1 数据分布
Dynamo系统采用一致性哈希算法将数据分不到多个存储节点中。一致性哈希的优点在于节点加入/删除时只会影响到在哈希环中相邻的节点,而对其他节点没影响。
考虑到节点的异构性,不同节点的处理能力差别可能很大,Dynamo使用了改进的一致性哈希算法:每个物理节点根据其性能的差异分配多个token,每个token对应一个“虚拟节点”。
Gossip协议用于P2P系统中自治的节点协调对整个集群的认识,比如集群的节点状态、负载情况。由于有种子节点的存在,新节点加入可以做得比较简单。
5.1.2 一致性与复制
机器宕机开始被认定为永久失效的时间不会太长,积累的写操作也不会太多,可以利用Merkle树对机器的数据文件进行快速同步。
NWR是Dynamo中的一个亮点,其中N标识复制的备份数,R指成功读操作的最少节点数,W指成功写操作的最少节点数。可以对NWR取不同的值来满足不同的需求。
通过在Dynamo这样的P2P集群中,引入向量时钟(Vector Clock)的技术手段来尝试解决冲突。(类似于多版本控制机制)最常见的解决冲突方法有两种:一种是通过客户端逻辑来解决,另一种常见的策略是“last write wins”,即选择时间戳最新的副本,然而,这个策略依赖集群内节点之间的时钟同步算法,不能完全保证准确性。
5.1.3 容错
Dynamo把异常分为两种类型:临时性的异常和永久性异常。
Dynamo的容错机制:
- 数据回传
临时性的异常,在机器K+i重新提供服务时,机器K+N将通过Gossip协议发现,并将启动传输任务将暂存的数据回传给机器K+i。 - Merkle树同步
当机器发生永久性异常时,需要借助Merkle树机制从其他副本进行数据同步。Merkle树同步的原理很简单,每个非叶子节点对应多个文件,为其所有子节点值组合以后的哈希值;叶子节点对应单个数据文件,为文件内容的哈希值。
每台机器对每一段范围的数据维护一颗Merkle树,机器同步时首先传输Merkle树信息,并且只需要同步从根到叶子的所有节点值均不相同的文件。 - 读取修复
合并多个副本的数据,并使用合并后的结果更新过期的副本,从而使得副本之间保持一致。
5.1.4 负载均衡
Dynamo的负载均衡取决于如何给每台机器分配虚拟节点号,即token。
- 随机分配
负载平衡的效果还是不错的,该方法的问题是可控性较差,新节点加入/离开系统时,集群中的原有节点都需要扫描所有的数据从而找出属于新节点的数据,Merkle树也需要全部更新;另外,增量归档/备份变得几乎不可能。 - 数据范围等分+随机分配
该种方法的负载也比较均衡,并且每台机器都可以对属于每个范围的数据维护一颗逻辑上的Merkle树,新节点加入/离开时只需扫描部分数据进行同步,并更新这部分数据对应的逻辑Merkle树,增量归档也变得简单。
5.1.5 读写流程
写的过程平平无奇;读取数据的时候,当各个副本的数据一致时,会直接返回,否则,需要根据冲突处理规则合并多个副本的读取结果。
5.1.6 单机实现
Dynamo的存储节点包含三个组件:请求协调、成员和故障检测、存储引擎。
Dynamo设计支持可插拔的存储引擎;请求协调组件采用基于事件驱动的设计;读操作成功返回客户端以后对应的状态机不会立即被销毁,而是等待一小段时间,这段时间内可能还有一些节点会返回过期的数据,协调者将更新这些节点的数据到最新版本,这个过程称为读取修复。
5.1.7 讨论
Dynamo采用务中心节点的P2P设计,增加了系统可扩展性,但同时带来了一致性问题,影响上层应用。主流的分布式系统一般都带有中心节点,这样能够简化设计,而且中心节点只维护少量元数据,一般不会成为性能瓶颈。
5.2 淘宝Tair
Tair是淘宝开发的一个分布式键/值存储引擎。Tair分为持久化和非持久化两种使用方式:非持久化的Tair可以看成是一个分布式缓存,持久化的Tair将数据存放于磁盘上。
5.2.1 系统架构
Tair作为一个分布式系统,是由一个中心控制节点和若干个服务节点组成。
5.2.2 关键问题
- 数据分布
根据数据的主键计算哈希值后,分布到Q个桶中,桶是负载均衡和数据迁移的基本单位。根据Dynamo论文中的实验结论,Q去只需要远大于集群的物理机器数,例如Q取值10240. - 容错
当某台Data Server故障不可用时,Config Server能够检测到。 - 数据迁移
机器加入或者负载不均衡可能导致桶迁移,迁移的过程中需要保证对外服务。 - Config Server
客户端缓存路由表,大多数情况下,客户端不需要访问Config Server,Config Server宕机也不影响客户端正常访问。 - Data Server
Data Server负责数据的存储,并根据Config Server的要求完成数据的复制和迁移工作。Data Server具备抽象的存储引擎层,可以很方便地添加新存储引擎。Data Server还有一个插件容器,可以动态加载/卸载插件。
5.2.3 讨论
Amazon Dynamo采用P2P架构,而在Tair中引入了中心节点Config Server。这种方式很容易处理数据的一致性,不再需要向量时钟、数据回传、Merkle树、冲突处理等复杂的P2P技术。另外,中心节点的负载很低。笔者认为,分布式键值系统的整体架构应该参考Tair,而不是dynamo。
第6章 分布式表格系统
分布式表格系统对外提供表格模型,每个表格由很多行组成,通过主键唯一标识,每一行包含很多列。整个表格再系统中全局有序,顺序分布。
6.1 Google Bigtable
Bigtable是Google开发的基于GFS和Chubby的分布式表格系统,用于存储海量结构化和半结构化数据。某一行的某一列构成一个单元(Cell),每个单元包含很多列(Column)。
整体上看,Bigtable是一个分布式多维映射表。Bigtable将多个列组织成列族(column family),这样,列名由两个部分组成:(column family,qualifier)。列族是Bigtable中访问控制的基本单元,也就是说,访问权限的设置是再列族这一级别上进行的。
Google的很多服务,比如Web检索和用户的个性化设置,都需要保存不同时间的数据,这些不同的数据版本必须通过时间戳来区分。
6.1.1 架构
Bigtable构建在GFS之上,为文件系统增加一层分布式索引层。Bigtable主要由三个部分组成:客户端程序库(Client)、一个主控服务器(Master)和多个子表服务器(Tablet Server)。
- 客户端程序库(Client):
提供接口给客户端使用,操作表格数据单元。客户端通过Chubby锁服务获取一些控制信息,但所有表格的数据内容都在客户端与子表服务器之间直接传送。 - 主控服务器(Master):
管理所有的子表服务器。 - 子表服务器(Tablet Server):
Tablet Server服务的数据包括操作日志以及每个子表上的sstable数据,这些数据存储在底层的GFS中。
Chubby是一个分布式锁服务,底层的核心算法为Paxos。Paxos算法的实现过程需要一个“多数派”就某个值达成一致,进而才能得到一个分布式一致性状态。客户端、主控服务器以及子表服务器执行过程中都需要依赖Chubby服务,如果Chubby发生故障,Bigtable系统整体不可用。
6.1.2 数据分布
Bigtable中的数据在系统中切分为大小100~200MB的子表,所有的数据按照行主键全局排序。Bigtable中包含两级元数据,元数据表及根表。为了减少访问开销,客户端使用了缓存(cache)和预取(prefetch)技术。
6.1.3 复制与一致性
Bigtable系统保证强一致性,同一个时刻同一个子表只能被一台Tablet Server服务,这是通过Chubby的互斥锁机制保证的。
Bigtable的底层存储系统为GFS。GFS本质上是一个弱一致性系统,其一致性模型只保证“同一个记录至少成功写入一次”,但是可能存在重复记录,而且可能存在一些补零(padding)记录。
Bigtable写入GFS的数据分为两种:
- 操作日志
- 每个子表包含的SSTable数据
Bigtable本质上构建在GFS之上的一层分布式索引,通过它解决了GFS遗留的一致性问题,大大简化了用户使用。
6.1.4 容错
Bigtable中Master对Tablet Server的监控是通过Chubby完成的,Tablet Server在初始化时都会从Chubby中获取一个独占锁。通过这种方式所有的Tablet Server基本信息被保存在Chubby中一个称为服务器目录(Server Directory)的特殊目录之中。
每个子表持久化的数据包含两个部分:操作日志以及SStable。
Bigtable Master启动时需要从Chubby中获取一个独占锁,如果Master发生故障,Master的独占锁将过期,管理程序会自动指定一个新的Master服务器,它从Chubby成功获取独占锁后可以继续提供服务。
6.1.5 负载均衡
子表是Bigtable负载均衡的基本单位。子表迁移分为两步:第一步请求原有的Table Server卸载子表;第二步选择一台负载较低的Tablet Server加载子表。子表迁移前原有的Tablet Server会对其执行Minor Compaction操作,将内存中的更新操作以SSTable文件的形式转储到GFS中,因此,负载均衡带来的子表迁移在新的Tablet Server上不需要回放操作日志。
子表迁移的过程中有短暂的时间需要暂停服务,为了尽可能减少暂停服务的时间,Bigtable内部采用两次Minor Compaction的策略。具体操作如下:
- 原有Tablet Server对子表执行一次Minor Compaction操作,操作过程中仍然允许写操作。
- 停止子表的写服务,对子表再次执行一次Minor Compaction操作。由于第一次Minor Compaction过程中写入的数据一般比较少,第二次Minor Compaction的时间会比较短。
6.1.6 分裂与合并
顺序分布于哈希分布的区别在于哈希分布往往是静态的,而顺序分布式动态的,需要通过分裂与合并操作动态调整。
Bigtable每个子表的数据分为内存中的MemTable和GFS中的多个SStable,由于Bigtable中同一个子表只被一台Tablet Server服务,进行分类时比较简单。
合并操作由Master发起,相比分裂操作要更加复杂。
6.1.7 单机存储
Bigtable采用Merge-dump存储引擎。
插入、删除、更新、增加(Add)等操作在Merge-dump引擎中都看成一回事,除了最早生成的SSTable外,SSTable中记录的只是操作,而不是最终的结果,需要等到读取(随机或者顺序)时才合并得到最终结果。
Bigtable中包含三种Compaction策略:Minor Compaction、Merging Compaction和Major Compaction。
数据在SSTable中按照主键有序存储,每个SSTable由若干个大小相近的数据块(Block)组成,每个数据块包含若干行。Tablet Server的缓存包括两种:块缓存(Block Cache)和行缓存(Row Cache)。另外,Bigtable还支持布隆过滤器(Bloom Filter),如果读取的数据行在SSTable中不存在,可以通过布隆过滤器发现,从而避免一次读取GFS文件操作。
6.1.8 垃圾回收
Compaction后生成新的SSTable,原有的SSTable称为垃圾需要被回收掉。这里需要注意,由于Tablet Server执行Compaction操作生成一个全新的SSTable与修改元数据这两个操作不是原子的,垃圾回收需要避免删除刚刚生成但还没有记录到元数据中的SSTbale文件。一种比较简单的做法是垃圾回收只删除至少一段时间,比如1小时没有被使用的SSTable文件。
6.1.9 讨论
GFS+Bigtable两层架构以一种很优雅的方式兼顾系统的强一致性和可用性。
Bigtable架构也面临一些问题:单副本服务,SSD使用,架构的复杂性导致Bug定位很难。
6.2 Google Megastore
Google Bigtable架构把可扩展性基本做到了极致,Megastore则是在Bigtable系统之上提供友好的数据库功能支持,增强易用性。Megastore是介于传统的关系型数据库和NoSQL之间的存储技术。
可以根据用户将数据拆分为不同的子集分布到不同的机器上。Google进一步从互联网应用特性中抽取实体组(Entity Group)概念,从而实现可扩展性和数据库语义之间的一种权衡,同时获得NoSQL和RDBMS的优点。存在实体组根表和实体组子表的概念,根实体除了存放用户数据,还需要存放Megastore事务及复制操作所需的元数据,包括操作日志。
6.2.1 系统架构
Megastore系统由三个部分组成:
- 客户端库:
提供Megastore到应用程序的接口,应用程序通过客户端操作Megastore的实体组。客户端能够实现Megastore系统大部分功能。 - 复制服务器:
接受客户端的用户请求并转发到所在机房的Bigtable实例,用于解决跨机房连接数过多的问题。 - 协调者:
存储每个机房本地的实体组是否处于最新状态的信息,用于实现快速读。
Megastore的功能主要分为三个部分:映射Megastore数据模型到Bigtable,事务及并发控制,跨机房数据复制及读写优化。Megastore首先解析用户通过客户端传入的SQL请求,接着根据用户定义的Megastore数据模型将SQL请求转化为对底层Bigtable的操作。
6.2.2 实体组
总体上看,数据拆分成不同的实体组,每个实体组内的操作日志采用基于Paxos的方式同步到多个机房,保证强一致性。实体组之间通过分布式队列的方式保证最终一致性或者两阶段提交协议的方式实现分布式事务。
- 单集群实体组内部:
同一个实体组内部支持满足ACID特性的事务。数据库系统事务实现时总是会提到REDO日志和UNDO日志,在Megastore系统中通过REDO日志的方式实现事务。同一个实体组的REDO日志都写到这个实体组的根实体中,对应Bigtable系统中的一行,从而保证REDO日志操作的原子性。客户端写完REDO日志后,事务操作成功,接下来的事情只是回放REDO日志。如果回放REDO日志失败,比如某些行所在的子表服务器宕机,事物操作也可成功返回客户端。后续的读操作如果要求读取最新的数据,需要先回放REDO日志。 - 单集群实体组之间:
实体组之间一般采用分布式队列的方式提供最终一致性,子表服务器上有定时扫描线程,发送跨实体组的操作到目的实体组。如果需要保证多个实体组之间的强一致性,即实现分布式事务,只能通过两阶段提交协议加锁协调。
6.2.3 并发控制
- 读事务
Megastore提供了三种读取模式:最新读取(current read)、快照读取(snapshot read)、非一致性读取(inconsistent read)。最新读取和快照读取利用了Bigtable存储多版本数据的特性,保证不会读取到未提交的事务。非一致性读取忽略日志的状态而直接读取Bigtable内存中最新的值,可能读到不完整的事务。 - 写事务
Megastore事务中的写操作采用了预写式日志(Write-ahead日志或REDO日志),也就是说,只有当所有的操作都在日志中记录下来后,写操作才会对数据执行修改。一个写事务总是开始于一个最新读取,以便于确认下一个可用的日志位置。
对同一个实体组的多个事务被串行化,Megastore之所以能提供可串行化的隔离级别,得益于定义的实体组的数据模型,由于同一个实体组同时进行的更新往往很少,事务冲突导致重试的概率很低。
6.2.4 复制
对于多个集群之间的操作日志同步,Megastore系统采用的是基于Paxos的复制协议机制。
6.2.5 索引
- 局部索引(local index):
局部索引是单个实体组内部的,用于加速单个实体组内部的查找。 - 全局索引(global index):
全局索引横跨多个实体组。 - STORING子句:
通过在索引中增加STORING子句,系统可以在索引中冗余一些常用的列字段,从而不需要查询基本表,减少一次查询操作。 - 可重复索引:
Megastore数据中某些字段是可重复的,相应的索引就是可重复索引。
6.2.6 协调者
- 快速读
Paxos协议要求读取最新的数据至少需要经过一半以上的副本,然而不出现故障,每个副本基本都是最新的。也就是说,能够利用本地读取(local reads)实现快速读,减少读取延时和跨机房操作。 - 协调者的可用性
每次写操作都需要涉及协调者,因此协调者出现故障将会导致系统不可用。 - 竞争条件
除了可用性问题,对于协调者的读写协议必须满足一系列的竞争条件。如果协调者先收到较晚的失效操作再收到较早的生效操作,生效操作将被忽略。
协调者从启动到退出为一个生命周期,每个生命周期用一个唯一的序号标识。生效操作只允许在最近一次对协调者进行读取操作以来序号没有发生变化的情况下修改协调者的状态。
6.2.7 读取流程
Megastore最新读取流程如下
- 本地查询
查询本地副本的协调者来决定这个实体组上数据是否已经是最新的。 - 发现位置
确认一个最高的已经提交的操作日志位置,并选择最新的副本,具体操作如下:
本地读取(Local Read)
多数派读取(Majority Read) - 追赶
一旦某个副本被选中,就采取如下方式使其追赶到已知的最大位置处:
获取操作日志
应用操作日志 - 使实体组生效
- 查询数据
6.2.8 写入流程
- 请求主副本接受
- 准备
- 接受
- 使实体组失效
- 应用操作日志
6.2.9 讨论
分布式存储系统有两个目标:一个是可扩展性,最终目标是线性可扩展;另外一个是功能,最终目标是支持全功能SQL。Megastore是一个介于传统的关系型数据库和分布式NoSQL系统之间的存储系统,融合了SQL和NoSQL两者的优势。
Megastore的主要创新点:
- 提出实体组的数据模型
- 通过Paxos协议同时保证高可靠和高可用性,既把数据强同步到多个机房,又做到发生故障时自动切换不影响读写服务
6.3 Windows Azure Storage
Windows Azure Storage(WAS)时微软开发的云存储系统,包括三种数据存储服务:Windows Azure Blob、Windows Azure Table。Windows Azure Queue。三种数据存储服务共享一套底层架构。
6.3.1 整体架构
WAS部署在不同地域的多个数据中心,依赖底层的Windows Azure结构控制器(Fabric Controller)管理硬件资源。结构控制器的功能包括节点管理,网络配置,健康检查,服务启动,关闭,部署和升级。另外,WAS还通过请求结构控制器获取网络拓扑信息,集群物理部署以及存储节点硬件配置信息。
WAS主要分为两个部分:定位服务(Location Service,LS)和存储区(Storage Stamp)
- 定位服务的功能包括:
管理所有的存储区,管理用户到存储区之间的映射关系,收集存储区的负载信息,分配新用户到负载较轻的存储区。LS服务自身也分布在两个不同的地域以实现高可用。LS需要通过DNS服务来使得每个账户的请求定位到所属存储区。 - **存储区分为三层:**文件流层(Stream Layer)、分区层(Patition Layer)以及前端层(Front-End Layer)
另外,WAS包含两种复制方式:存储区内复制(Intra-Stamp Replication)和跨存储区复制(Inter-Stamp Replication)
6.3.2 文件流层
文件流层提供内部接口供服务分区层使用。文件流层中的文件称为流,每个流包含一系列的extent。每个extent由一连串的block组成。block是数据读写的最小单位,每个block最大不超过4MB。WAS中的block与GFS中的记录(record)概念是一致的。
extent是文件流层数据复制,负载均衡的基本单位,每个存储区默认对每个extent保留三个副本,每个extent的默认大小为1GB。WAS中的extent与GFS中的chunk概念是一致的。
stream用于文件流层对外接口,每个stream在层级命名空间中有一个名字。WAS中的stream与GFS中的file概念是一致的。
- 架构
文件流层由三个部分组成
流管理器(Stream Manager,SM)
extent存储节点(Extent Node,EN)
客户端库(Partition Layer Client) - 复制及一致性
WAS中的六文件只允许追加,不允许更改。
分区层通过两种方式处理重复记录:对于元数据(metadata)和操作日志流(commit log streams),所有的数据都有一个唯一的事务编号(transaction sequence),顺序读取时忽略编号相同的事务;对于每个表格中的行数据流(row data sreams),只有最后一个追加成功的数据块才会被索引,因此先前追加失败的数据块不会被分区层读取到,将来也会被系统的垃圾回收机制删除。
文件流层保证:只要记录被追加并成功响应客户端,从任何一个副本都能够读到相同的数据;即使追加过程出现故障,一旦extent被缝合,从任何一个被缝合的副本都能够读取到相同的内容。 - 存储优化
extent存储节点面临两个问题:如何保证磁盘调度公平性以及避免磁盘随机写操作。
很多硬盘通过牺牲公平性来最大限度地提高吞吐量,这些磁盘优先执行大块顺序读写操作。为此,WAS改进了IO调度策略,如果存储节点上某个磁盘当前已发出请求的期望完成时间超过100ms或者最近一段时间内某个请求的响应时间超过200ms,避免将新的IO请求调度到该磁盘。这种策略适当牺牲了磁盘的吞吐量,但是保证公平性。
文件流层客户端追加操作应答成功要求所有的副本都将数据持久化到磁盘。为了减少随机写,存储节点采用单独的日志盘(journal drive)顺序保存节点上所有extent的追加数据,追加数据分为两步:a)将待追加数据写入日志盘;b)将数据写入对应的extent文件
文件流层还有一种抹除码(erasure coding)机制用于减少exent副本占用的空间,GFS以及开源的HDFS也采用了这个机制。其实就是一种纠错码。
6.3.3 分区层
分区层构建在文件流层之上,用于提供Table、Blob、Queue等数据服务。分区层的一个重要特性是提供一致性并保证事务操作顺序。
分区层内部支持一种称为对象表(Object Table,OT)的数据架构,每个OT是一张最大可达若干PB的大表。
- 架构
分区层包含如下四个部分:
客户端程序库(Client)
分区服务器(Partition Server,PS)
分区管理器(Partition Manager,PM)
锁服务(Lock Service) - 分区数据结构
WAS分区层中的操作与Bigtable基本类似。
与Bigtable的不同点如下:a)WAS中每个分区拥有一个专门的操作日志文件,而Bigtable中同一个Tablet Server的所有子表共享同一个操作日志文件;b)WAS中每个分区维护各自的元数据(例如分区包含哪些快照文件,持久化成元数据文件流),分区管理器只管理每个分区与所在的分区服务器之间的映射关系;而Bigtable专门维护了两级元数据表;元数据表(Meta Table)及根表(Root Table),每个分区的元数据保存在上一级元数据表中;c)WAS专门引入了Blob数据文件流用于支持Blob数据类型。 - 负载均衡
对某个分区负载均衡两个阶段:
卸载
加载 - 分裂与合并
有两种可能导致WAS对某个分区执行分裂操作,一种可能是分区太大,另外一种可能是分区的负载过高。PM发起分裂操作,并且PS确定分裂点。如果是基于分区大小的分裂操作,PS维护了每个分区的大小以及大致的中间位置,并将这个中间位置作为分裂点;如果是基于负载的分裂操作,PS自适应地计算分区中哪个逐渐范围的负载最高并通过它来确定分裂点。
合并操作需要选择两个连续的负载较低的分区。假设需要把分区C和D合并称为新的分区E。
6.3.4 讨论
WAS整体架构借鉴GFS+Bigtable并有所创新。
- Chunk大小选择
- 元数据层次
- GFS的多个Chunk副本之间是弱一致性的,不保证每个Chunk的不同副本之间每个字节都完全相同,而WAS能够保证这一点
- Bigtable每个Tablet Server的所有子表共享一个操作日志文件从而提高写入性能,而WAS将每个范围分区的操作写入到不同的操作日志文件
第7章 分布式数据库
关系型数据库设计之初并没有预见到IT行业发展如此之快,总是假设系统运行在单机这一封闭系统上。
有很多思路可以实现关系数据库的可扩展性。例如,在应用层划分数据,将不同的数据分片划分到不同的关系数据库上,如MySQL Sharding;或者在关系数据内部支持数据自动分片,如Microsoft SQL Azure;或者干脆从存储引擎开始重写一个全新的分布式数据库,如Google Spanner以及Alibaba OceanBase。
7.1 数据库中间层
为了扩展关系数据库,最简单也是最为常见的做法就是应用层按照规则将数据拆分为多个分片,分布到多个数据库节点,并引入一个中间层来对应用屏蔽后端的数据库拆分细节。
7.1.1 架构
以MySQL Sharding架构为例,分为几个部分
- MySQL客户端库
- 中间层dbproxy
中间层解析客户端SQL请求并转发到后端的数据库。具体来讲,它解析MqSQL协议,执行SQL路由、SQL过滤,读写分离,结果归并,排序以及分组,等等。 - 数据库组dbgroup
- 元数据服务器
元数据服务器主要负责维护dbgroup拆分规则并用于dbgroup选主。 - 常驻进程agents
部署在每台数据库服务器上的常驻进程,用于实现监控,单点切换,安装,卸载程序等。dbgroup中的数据库需要进行主备切换,软件升级,这些控制逻辑需要与数据库读写事务处理逻辑隔离开来。
7.1.2 扩容
MySQL Sharding集群一般按照用户id进行哈希分区,这里面存在两个问题:
- 集群的容量不够怎么办?
- 单个用户的数据量太大怎么办?
7.1.3 讨论
引入数据库中间层将后端分库分表对应用透明化在大公司互联网公司内部很常见。面临一些问题:数据库复制、扩容问题、动态数据迁移问题
7.2 Microsoft SQL Azure
Microsoft SQL Azure是微软的云关系型数据库,后端存储又称为云SQL Server(Cloud SQL Server)。他构建在SQL Server之上,通过分布式技术提升传统关系型数据库的可扩展性和容错能力。
7.2.1 数据模型
- 逻辑模型
云SQL Server将数据划分为多个分区,通过限制事务只能在一个分区执行来规避分布式事务。云SQL Server中一个逻辑数据库称为一个表格组(table group),表格组中所有划分主键相同的行集合称为行组(row group)。云SQL Server只支持同一个行组内的事务,这就意味这,同一个行组的数据逻辑会分布到一台服务器。同一个行组总是被一台物理的SQL Server服务,从而避免了分布式事务。 - 物理模型
在物理层面,每个有主键的表格组根据划分主键列有序地分成多个数据分区(partition)。这些分区之间互相不重叠,并且覆盖了所有的划分主键值。这就确保了每个行组属于一个唯一的分区。分区是云SQL Server复制、迁移、负载均衡的基本单位。
分区划分是动态的,如果某个分区超过了允许的最大分区大小或者负载太高,这个分区将分裂为两个分区。
7.2.2 架构
云SQL Server分为四个主要部分:
- SQL Server实例
每个SQL Server实例是一个运行着SQL Server的物理进程。每个物理数据库包含多个子数据库,它们之间相互隔离。子数据库是一个分区,包含用户的数据以及schema信息。 - 全局分区管理器(Global Partition Manager)
维护分区映射表信息,包括每个分区的主键范围,每个副本所在的服务器,以及每个副本的状态,包括副本当前是主还是备,前一次是主还是备,正在变成主,正在被拷贝或者正在被追赶。当服务器发生故障时,分布式基础部件检测并保证服务器故障后通知全局分区管理器。全局分区管理器接着执行重新配置操作。另外,全局分区管理器监控集群中的SQL Server工作机,执行负载均衡,副本拷贝等管理操作。 - 协议网关(Protocol Gateway)
负责将用户的数据库连接请求转发到相应的主分区。协议网关通过将分区管理器获取分区所在的SQL Server实例,后续的读写事务操作都在网关与SQL Server实例之间进行。 - 分布式基础部件(Distributed Fabric)
用于维护机器上下线状态,检测服务器故障并为集群中的各种角色执行选举主节点操作。它在每台服务器上都运行了一个守护进程。
7.2.3 复制与一致性
云SQL Server采用“Quorum Commit”的复制协议,用户数据存储三个副本,至少写成功两个副本才可以返回客户端成功。某些备副本可能出现故障,恢复后将往主副本发送本地已经提交的最后一个事务的提交顺序号。主副本与备副本之间传送逻辑操作日志,而不是对磁盘物理页的redo&undo日志。
7.2.4 容错
如果数据节点发生了故障,需要启动宕机恢复过程。由于云SQL Server采用“Quorum Commit”复制协议,如果每个分区有三个副本,至少保证两个副本写入成功,主副本出现故障后选择最新的备副本可以保证不丢数据。
全局分区管理器控制重新配置任务的优先级,否则,用户的服务会受到影响。
全局分区管理器也采用“Quorum Commit”实现高可用性。它包含七个副本,同一时刻只有一个副本为主,分区相关的元数据操作至少需要在四个副本上成功。如果全局分区管理器主副本出现故障,分布式基础部件将负责从其他副本中选择一个最新的副本作为新的主副本。
7.2.5 负载均衡
负载均衡相关的操作包含三种:副本迁移以及主备副本切换。新的服务器节点加入时,系统内的分区会逐步地迁移到新节点,这里需要注意的是,为了避免过多的分区同时迁入新节点,全局分区管理器需要控制迁移的频率,否则系统整体性能可能会下降。另外,如果主副本所在服务器负载过高,可以选择负载较低的备副本替换为主副本提供读写服务。这个过程称为主备副本切换,不涉及数据拷贝。
7.2.6 多租户
云存储系统中多个用户的操作相互干扰,因此需要限制每个SQL Azure逻辑实例使用的系统资源:
- 操作系统资源限制,比如CPU、内存、写入速度,等等。如果超过限制,将在10秒内拒绝相应的用户请求;
- SQL Azure逻辑数据库容量限制。每个逻辑数据库都预先设置了最大的容量,超过限制时拒绝更新请求,但允许删除操作;
- SQL Server物理数据库数据大小限制。超过该限制时返回客户端错误,此时需要人工介入。
7.2.7 讨论
Microsoft SQL Azure将传统的关系型数据库SQL Server搬到云环境中,比较符合用户过去的使用习惯。云SQL Server与单机SQL Server的区别:不支持的操作、观念转变
相比Azure Table Storage,SQL Azure在扩展上有一些劣势,例如,单个SQL Azure实例大小限制。Azure Table Storage单个用户表格的数据可以分布到多个存储节点,数据总量几乎没有限制;而单个SQL Azure实例最大限制为50GB,如果用户的数据量大于最大值,需要用户在应用层对数据库进行水平或者垂直拆分,使用起来比较麻烦。
7.3 Google Spanner
Google Spanner是Google的全球级分布式数据库(Globally-Distributed Database)。Spanner的扩展性达到了全球级,可以扩展到数百个数据中心,数百万台机器,上万亿行记录。更为重要的是,除了夸张的可扩展性之外,它还能通过同步复制和多版本控制来满足外部一致性,支持跨数据中心事务。
7.3.1 数据模型
Spanner的表是层次化的,最底层的表是目录表(Directory table),其他表创建时,可以用INTERLEAVE IN PARENT来表示层次关系。实际存储时,Spanner会将同一个目录的数据存放到一起,只要目录不太大,同一个目录的每个副本都会分配到同一台机器。因此,针对同一个目录的读写事务大部分情况下都不会涉及跨机操作。
7.3.2 架构
Spanner构建在Google下一代分布式文件系统Colossus之上。由于Spanner是全球性的,因此它有两个其他分布式存储系统没有的概念:Universe和Zones。
Spanner系统包含如下组件:
- Universe Master:监控这个Universe里Zone级别的状态信息。
- Placement Driver:提供跨Zone数据迁移功能。
- Location Proxy:提供获取数据的位置信息服务。客户端需要通过它才能够知道数据由哪台Spanserver服务。
- Spanserver:提供存储服务,功能上相当于Bigtable系统中的Tablet Server。
7.3.3 复制与一致性
每个数据中心运行着一套Colossus,每个机器有100~1000个子表,每个子表会在多个数据中心部署多个副本。
通过Paxos协议,实现了跨数据中心的多个副本之间的一致性。
锁表实现单个Paxos组内的单机事务,事务管理器实现跨多个Paxos组的分布式事务。为了实现分布式事务,需要实现两阶段提交协议。有一个Paxos组的主副本会成为两阶段提交协议中的协调者,其他Paxos组的主副本为参与者。
7.3.4 TrueTime
为了实现并发控制,数据库需要给每个事务分配全局唯一的事务id。然而,在分布式系统中,很难生成全局唯一id。一种方式是采用Google Percolator(Google Caffeine的底层存储系统)中的做法,即专门部署一套Oracle数据库用于生成全局唯一id。虽然Oracle逻辑上是一个单点,但是实现的功能单一,因而能够做得很高效。Spanner选择了另外一种做法,即全球时钟同步机制TrueTime。
7.3.5 并发控制
Spanner使用TrueTime来控制并发,实现外部一致性,支持以下几种事务:
- 读写事务
- 只读事务
- 快照读,客户端提供时间戳
- 快照读,客户端提供时间范围
- 不考虑TrueTime
如果事务读写的数据只属于同一个Paxos组,快照读和只读事务的区别在于:快照读将指定读事务的版本,而不是取系统的当前时间戳。
如果事务读写的数据涉及多个Paxos组,那么,对于读写事务,需要执行一次两阶段提交协议,只读事务需要保证不会读不到不完整的事务。假设有一个读写事务修改了两个Paxos组:Paxos组A和Paxos组B,Paxos组A上的修改已提交,Paxos组B上的修改还未提交。那么,只读事务会发现Paxos组B处于两阶段提交协议中的PrePare阶段,需要等待一会,知道Paxos组B上的修改生效后才能读到正确的数据。 - 考虑TrueTime
Spanner实现功能完备的全球数据库是付出了一定代价的,涉及架构时不能盲目崇拜。
7.3.6 数据迁移
目录是Spanner中对数据分区、复制和迁移的基本单位,用户可以指定一个目录有多少副本,分别存放在哪些机房中,例如将用户的目录存放在这个用户所在地区附近的几个机房中。
一个Paxos组包含多个目录,目录可以在Paxos组之间移动。Spanner移动一个目录一般出于以下几种考虑:
- 某个Paxos组的负载太大,需要切分;
- 将数据移动到离用户更近的地方,减少访问延时;
- 把经常一起访问的目录放进同一个Paxos组。
实现时,首先将目录的实际数据移动到指定位置,然后再用一个院子操作更新元数据,从而完成整个移动过程。
7.3.7 讨论
Google的分布式存储系统一步步地从Bigtable到Megastore,再到Spanner,这也印证了分布式技术和传统关系数据库技术融合的必然性,即底层通过分布式技术实现可扩展性,上层通过关系数据库的模型和接口将系统的功能暴露给用户。
OceanBase系统的最终目标:可扩展的关系数据库。
第三篇 实践篇
第8章 OceanBase架构初探
从模块划分的角度看,OceanBase可以划分为四个模块:主控服务器RootServer、更新服务器UpdateServer、基线数据服务器ChunkServer以及合并服务器MergeServer。OceanBase系统内部按照时间线将数据划分为基线数据和增量数据,基线数据是只读的,所有的修改更新到增量数据中,系统内部通过合并操作定期将增量数据融合到基线数据中。
8.1 背景简介
阿里巴巴需要研发适合互联网规模的分布式数据库,这个数据库不仅能解决收藏夹面临的业务挑战,还要能做到可扩展、低成本、易用,并能够应用到更多的业务场景。
8.2 设计思路
根据业务特点对数据库进行水平拆分,这种方式目前还存在一定的弊端
- 数据和负载增加后添加机器的操作比较复杂,往往需要人工介入;
- 有些范围查询需要访问几乎所有的分区,例如,按照user_id分区,查询收藏了一个商品的所有用户需要访问所有的分区;
- 目前广泛使用的关系数据库存储引擎都是针对机械硬盘的特点设计的,不能够完全发挥新硬件(SSD)的能力。
另一种做法是参考分布式表格系统的做法,例如Google Bigtable系统,将大表划分为几万、几十万甚至几百万个子表,子表之间按照主键有序,如果某台服务器发生故障,它上面服务的数据能够在很短的时间内自动迁移到集群中所有的其他服务器。
Bigtable只支持单行事务,针对同一个user_id下的多条记录的操作都无法保证原子性。而OceanBase希望能够支持跨行跨表事务,这样使用起来会比较方便。
OceanBase决定采用单台更新服务器来记录最近一段时间的修改增量,而以前的数据保持不变,以前的数据称为基线数据。基线数据以类似分布式文件系统的方式存储于多台基线数据服务器中,每次查询都需要把基线数据和增量数据融合后返回给客户端。这样,写事务都集中在单台服务器上,避免了复杂的分布式事务,高校地实现了跨行跨表事务;另外,更新服务器上的修改增量能够定期分发到多台基线数据服务器中,避免成为瓶颈,实现了良好的扩展性。
8.3 系统架构
8.3.1 整体架构图
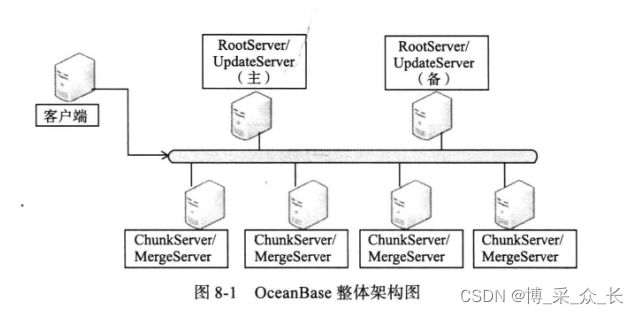
OceanBase由如下几个部分组成:
- 客户端: 用户使用OceanBase的方式和MySQL数据库完全相同,支持JDBC、C客户端访问,等等。基于MySQL数据库开发的应用程序、工具能够直接迁移到OceanBase。
- RootServer: 管理集群中的所有服务器,子表(tablet)数据分布以及副本管理。RootServer一般为一主一备,主备之间数据强同步。
- UpdateServer: 存储OceanBase系统的增量更新数据。UpdateServer一般为一主一备,主备之间可以配置不同的同步模式。部署时,UpdateServer进程和RootServer进程往往共用物理服务器。
- ChunkServer: 存储OceanBase系统的基线数据。基线数据一般存储两份或者三份,可配置。
- MergeServer: 接受并解析用户的SQL请求,经过词法分析、语法分析、查询优化等一系列操作后转发给相应的ChunkServer或者UpdateServer。如果请求的数据分布在多台ChunkServer上,MergeServer还需要对多台ChunkServer返回的结果进行合并。客户端和MergeServer之间采用原生的MySQL通信协议,MySQL客户端可以直接访问MergeServer。
8.3.2 客户端
OceanBase客户端与MergeServer通信,目前主要支持如下几种客户端:
- MySQL客户端
- Java客户端
- C客户端
Java/C客户端访问OceanBase的流程大致如下:
- 请求RootServer获取集群中MergeServer的地址列表。
- 按照一定的策略选择某台MergeServer发送读写请求。
- 如果请求MergeServer失败,则从MergeServer列表重新选择一台MergeServer重试;如果请求某台MergeServer失败超过一定的次数,将这台MergeServer加入黑名单并从MergeSever列表中删除。
8.3.3 RootServer
RootServer的功能主要包括:集群管理、数据分布以及副本管理。RootServer管理集群中的所有MergeServer、ChunkServer以及UpdateServer。OceanBase内部使用主键对表格中的数据进行排序和存储,主键由若干列组成并且具有唯一性。
8.3.4 MergeServer
MergeServer的功能主要包括:协议解析、SQL解析、请求转发、结果合并、多表操作等。
OceanBase客户端与MergeServer之间的协议为MySQL协议。MergeServer缓存了子表分布信息,根据请求涉及的子表将请求转发给该子表所在的ChunkServer。如果是写操作,还会转发给UpdateServer。MergeServer支持并发请求多台ChunkServer,即将多个请求发送给多台ChunkServer,再一次性等待所有请求的应答。
MergeServer本身是没有状态的,因此,MergeServer宕机不会对使用者产生影响,客户端会自动将发生故障的MergeServer屏蔽掉。
8.3.5 ChunkServer
ChunkServer的功能包括:存储多个子表,提供读取服务,执行定期合并以及数据分发。
MergeServer将每个子表的读取请求发送到子表所在的ChunkServer,ChunkServer首先读取SSTable中包含的基线数据,接着请求UpdateServer获取相应的增量更新数据,并将基线数据与增量更新融合后得到最终结果。
8.3.6 UpdateServer
UpdateServer是集群唯一能够接受写入的模块,每个集群中只有一个主UpdateServer。UpdateServer中的更新操作首先写入到内存表,当内存表的数据量超过一定值时,可以生成快照文件并转储到SSD中。为了保证可靠性,主UpdateServer更新内存表之前需要首先写操作日志,并同步到备UpdateServer。另外,系统实现时也需要对UpdateServer的内存操作、网络框架、磁盘操作做大量的优化。
8.3.7 定期合并&数据分发
定期合并和数据分发都是将UpdateServer中的增量更新分发到ChunkServer中的手段。
定期合并于数据分发两者之间的不同点在于,数据分发过程中ChunkServer只是将UpdateServer中冻结内存表中的增量更新数据缓存到本地,而定期合并过程中ChunkServer需要将本地SSTable中的基线数据与冻结内存表的增量更新数据执行一次多路归并,融合后生成新的基线数据并存放到新的SSTable中。
虽然定期合并过程中给个ChunkServer的各个子表合并时间和完成时间可能都不相同,但并不影响读取服务。如果子表没有合并完成,那么使用旧子表,并且读取UpdateServer中的冻结内存表以及新的活跃内存表;否则,使用新子表,只读取新的活跃内存表,
查询结果 = 旧子表 + 冻结内存表 + 新的活跃内存表
= 新子表 + 新的活跃内存表
8.4 架构剖析
8.4.1 一致性选择
Eric Brewer教授的CAP理论指出,在满足分区可容忍性的前提下,一致性和可用性不可兼得。
虽然目前大量的互联网项目选择了弱一致性,但我们认为是底层存储系统,比如MySQL数据库,在大数据量和高并发需求压力之下的无奈选择。强一致性将大大简化数据库的管理,应用程序也会因此而简化。因此,OceanBase选择支持强一致性和跨行跨表事务。
另外,OceanBase所有写事务最终都落到UpdateServer,而UpdateServer逻辑上是一个单点,支持跨行跨表事务,实现上借鉴了传统关系数据库的做法。
8.4.2 数据结构
OceanBase数据分为基线数据和增量数据两个部分,基线数据分布在多台ChunkServer上,增量数据全部存放在一台UpdateServer上。
不考虑数据复制,基线数据的数据结构如下:
- 每个表格按照主键组成一颗分布式B+树,主键由若干列组成;
- 每个叶子节点包含表格一个前开后闭的主键范围(rk1,rk2]内的数据;
- 每个叶子节点称为一个子表(tablet),包含一个或者多个SSTable;
- 每个SSTable内部按主键范围有序划分为多个块(block)并内建块索引(block index);
- 每个块的大小通常在4~64KB之间并内建块内的索引;
- 数据压缩以块为单位,压缩算法由用户指定并可随时变更;
- 叶子节点可能合并或者分裂;
- 所有叶子节点基本上是均匀的,随即地分布在多台ChunkServer机器上;
- 通常情况下每个叶子节点有2~3个副本;
- 叶子节点是负载平衡和任务调度的基本单元;
- 支持布隆过滤器的过滤。
增量数据的数据结构如下:
- 增量数据按照时间从旧到新划分为多个版本;
- 最新版本的数据为一颗内存中的B+树,称为活跃MemTable;
- 用户的修改操作写入活跃MemTable,到达一定大小后,原有的活跃MemTable将被冻结,并开启新的活跃MemTable接受修改操作;
- 冻结的MemTable将以SSTable的形式转储到SSD中持久化;
- 每个SSTable内部将按主键范围有序划分为多个块并内建块索引,每个块的大小通常为4~8KB并内建块内行索引,一般不压缩;
- UpdateServer支持主备,增量数据通常为2个副本,每个副本支持RAID1存储。
8.4.3 可靠性与可用性
分布式系统需要处理各种故障,例如,软件故障、服务器故障、网络故障、数据中心故障、地震、火灾等。与其他分布式存储系统一样,OceanBase通过冗余的方式保障了高可靠性和高可用性。
- OceanBase在ChunkServer中保存了基线数据的多个副本。
- OceanBase在UpdateServer中保存了增量数据的多个副本。
- ChunkServer的多个副本可以同时提供服务。
- UpdateServer主备之间为热备,同一时刻只有一台机器为主UpdateServer提供写服务。
- OceanBase存储多个副本并没有带来太多的成本。
8.4.4 读写事务
在OceanBase系统中,用户的读写请求,即读写事务,都发给MergeServer。MergeServer解析这些读写事务的内容,例如词法和语法分析、schema检查等。对于只读事务,由MergeServer发给相应的ChunkServer分别执行后再合并每个ChunkServer的执行结果;对于读写事务,由MergeServer进行预处理后,发送给UpdateServer执行。
8.4.5 单点性能
OceanBase架构的优势在于即支持跨行跨表事务,又支持存储服务器线性扩展。当然,这个架构也有一个明显的缺陷:UpdateServer单点,这个问题限制了OceanBase集群的整体读写性能。
8.4.6 SSD支持
磁盘随机IO是存储系统性能的决定因素,传统的SAS盘能够提供的IOPS不超过300。最近几年,SSD磁盘取得了很大的进展,它不仅提供了非常好的随机读取性能,功耗也非常低,大有取代传统机械磁盘之势。
然而,SSD盘的随机写性能并不理想。这是因为,尽管SSD的读和写以页(page,例如4KB,8KB等)为单位,但SSD写入前需要首先擦除已有内容,而擦除以块(block)为单位,一个块由若干个连续的页组成,大小通常在512KB2MB。加入写入的页有内容,即使值写入一个字节,SSD也是需要擦除整个512KB2MB大小的块,然后再写入整个页的内容,这就是SSD的写入放大效应。
8.4.7 数据正确性
数据丢失或者数据错误对于存储系统来说是一种灾难。
OceanBase采取了以下数据校验措施:
- 数据存储校验
- 数据传输校验
- 数据镜像校验
- 数据副本校验
8.4.8 分层结构
OceanBase对外提供的是与关系数据库一样的SQL操作接口,而内部却实现成一个线性可扩展的分布式系统。系统从逻辑实现上可以分为两个层次:分布式存储引擎层以及数据库功能层
从另外一个角度看,OceanBase融合了分布式存储系统和关系数据库这两种技术。通过分布式存储技术将基线数据分布到多台ChunkServer,实现数据复制、负载均衡、服务器故障检测与自动容错,等等;UpdateServer相当于一个高性能的内存数据库,底层采用关系数据库技术实现。
第9章 分布式存储引擎
分布式存储引擎层负责处理分布式系统中的各种问题,例如数据分布、负载均衡、容错、一致性协议等。数据库功能层构建在分布式存储引擎层之上。分布式存储引擎层包括三个模块:RootServer、UpdateServer以及ChunkServer。
OceanBase包含一个公共模块,包含其他模块共用的网络框架、内存池、任务队列、锁、基础数据结构等。
9.1 公共模块
OceanBase源代码中有一个公共模块,包含其他模块需要的公共类,例如公共数据结构、内存管理、锁、任务队列、RPC框架、压缩/解压缩等。
9.1.1 内存管理
内存管理是C++高性能服务器的核心问题。在分布式存储系统开发初期,这个时期内存管理的首要问题并不是高效,而是可控性,并防止内存碎片。
OceanBase系统有一个全局的定长内存池,这个内存池维护了由64KB大小的定长内存块组成的空闲联表,其工作原理如下:
- 如果申请的内存不超过64KB,尝试从空闲链表中获取一个64KB的内存块返回给申请者;如果空闲链表为空,需要首先从操作系统中申请一批大小为64KB的内存块加入空闲链表。释放时将64KB的内存块加入到空闲链表中以便下次重用。
- 如果申请的内存超过64KB,直接调用Glibc的内存分配(malloc)函数,向操作系统申请用户所需大小的内存块。施放时直接调用该Glibc的内存释放(free)函数,将内存块归还给操作系统。
OceanBase的全局内存池实现简单,但内存使用率比较低,即使申请几个字节的内存,也需要占用大小为64KB的内存块。因此,全局内存池不适合管理小块内存,每个需要申请内存的模块,比如UpdateServer中的MemTable,Chunkserver中的缓存等,都只能从全局内存池中申请大块内存,每个模块内部再实现专用的内存池。每个线程处理读写请求时需要使用临时内存,为了提高效率,每个线程会缓存若干大小分别为64KB和2MB的内存块,每个线程总是首先尝试从线程局部缓存中申请内存,如果申请不到,再从全局内存池中申请。
OBIAllocator是内存管理器的接口,包含alloc和free两个方法。ObMalloc和ObTCMalloc是两个实现了ObIAllocator接口的全局内存池,不同点在于,ObMalloc不支持线程缓存,ObTCMalloc支持线程缓存。ObTCMalloc首先尝试从线程局部的空闲链表申请内存块,如果申请不到,再通过ObMalloc的alloc方法申请。释放内存时,如果没有超出线程缓存的内存块个数限制,则将内存块还给线程局部的空闲链表;否则,通过ObMalloc的free方法释放。另外,允许通过set_mod_id函数设置申请者所在的模块编号,便于统计每个模块的内存使用情况。
群居内存池的意义如下:
- 全局内存池可以统计每个模块的内存使用情况,如果出现内存泄漏,可以很快定位到发生问题的模块
- 全局内存池可用于辅助调试。例如,可以将全局内存池中申请到的内存块按字节填充为某个非法的值(比如0xFE),当出现内存越界等问题时,服务器程序会很快在出现问题的位置Core Dump,而不是带着错误运行一段时间后才Core Dump,从而方便问题定位。
总而言之,OceanBase的内存管理没有采用高深的技术,也没有做到通用或者最优,但是很好地满足了服务器程序开发的两个最主要的需求:可控性以及没有内存碎片。
9.1.2 基础数据结构
- 哈希表
为了提高随机读取性能,UpdateServer支持创建哈希索引,这个哈希索引结构就是LightyHashMap。
LightyHashMap设计用来存储几千万甚至几亿个元素,它与普通哈希表的不同点在于以下两点:
(1)位锁(BitLock):LightyHashMap通过BitLock实现哈希桶的锁结构,每个哈希桶的锁结构只需要占用一个位(Bit)。如果哈希桶对应的位锁值为0,表示没有锁冲突。否则,表示出现锁冲突。需要注意的是,LightyHashMap没有区分读锁和写锁,多个get请求也是冲突的。可以对LightyHashMap的BitLock做一些改进,例如用两个位(Bit)表示哈希桶对应的锁,其中一个位表示是否有读冲突,另一个位表示是否有写冲突。
(2)延迟初始化(Lazy Initialization):LightyHashMap的哈希桶个数往往特别多(默认为1000万个),即使仅仅对所有哈希桶执行一次memset操作,消耗的时间也是相当可观的。因此,LightyHashMap采用延迟初始化策略,即将哈希桶划分为多个单元,默认情况下每个单元包含65536个哈希桶。每次未初始化,则对该单元内的所有哈希桶执行初始化操作。 - B树
UpdateServer的MemTable结构底层采用B树结构索引其中的数据行。
B树支持多线程并发修改。王MemTable插入数据行(Data)时,将修改其B树索引结构(Index),分为两种情况: - 两个线程分别插入Data1和Data2:由于Data1和Data2属于不同的索引节点,插入Data1和Data2将影响B树的不同部分,两个线程可以并发执行,不会产生冲突。
- 两个线程分别插入Data2和Data3:由于Data2和Data3属于相同的索引节点,因此,插入操作将产生冲突。其中一个线程会执行成功,另一个线程失败后将重试。
每个索引节点满了以后将分裂为两个节点,并触发对该索引节点的父亲节点的修改操作。分裂操作将增加插入线程冲突的概率,如果Data1和Data2的祖父节点,从而产生冲突。
另外,为了提高读写并发能力,B树实现时采用了写时复制(Copy-on-write)技术,修改每个索引节点时首先将该节点拷贝出来,接着在拷贝出来的节点上执行修改操作,最后再原子地修改其父亲节点的指针使其指向拷贝出现的节点。这种实现方式的好处在于修改操作不影响读取,读取操作永远不会被阻塞。
这里的B树不支持更新(Update)以及删除操作,这是由OceanBase MVCC存储引擎的实现机制决定的。对于更新操作,MVCC存储引擎会在行的末尾追加一个单元记录更新的内容,而不会影响索引结构;对于删除操作,MVCC存储引擎内部实现为标记删除,即在行的末尾追加一个单元记录行的删除时间,而不会物理删除某行数据。
9.1.3 锁
为了实现并发控制,OceanBase需要对一行记录加共享锁或者互斥锁。
9.1.4 任务队列
在生产者/消费者模型中,往往有一个任务队列,生产者将任务加入到任务队列,消费者从任务队列中取出任务进行处理。OceanBase还实现了LightyQueue用于解决全局任务队列锁冲突问题。
9.1.5 网络框架
OceanBase服务端接收客户端发送的网络包(ObPacket),并交给handlePacket处理函数进行处理。默认情况下,handlePacket会将网络包加入到全局任务队列中。接着,工作线程会从全局任务队列中不断获取网络包,并调用do_request进行处理,处理完成后应答客户端。可以通过set_thread_count函数来设置工作线程以及网络线程的个数。
客户端发包分为两种情况:异步请求(post_request)以及同步请求(send_request)。异步请求时,客户端将请求包加入到网络发送队列后立即返回,不等待应答。同步请求时,客户端将请求包加入到网络发送队列后开始阻塞等待,直到网络线程接收到服务端的应答包后才唤醒客户端,从而执行后续处理逻辑。
9.1.6 压缩与解压缩
ObCompressor定义了压缩与解压缩的通用接口,具体的压缩库实现了这些接口。压缩库以动态库(.so)的形式存在,每个工作线程第一次调用compress或者decompress方法时将加载相应的动态库,这样便实现了压缩库的插件化。目前,支持的压缩库包括LZO以及Snappy。
9.2 RootServer实现机制
RootServer是OceanBase集群对外的窗口,客户端通过RootServer获取集群中其他模块的信息。RootServer实现的功能包括:
- 管理集群中的所有ChunkServer,处理ChunkServer上下线;
- 管理集群中的UpdateServer,实现UpdateServer选主;
- 管理集群中子表数据分布,发起子表复制、迁移以及合并等操作;
- 与ChunkServer保持心跳,接受ChunkServer汇报,处理子表分裂;
- 接受UpdateServer汇报的大版本冻结消息,通知ChunkServer执行定期合并;
- 实现主备RootServer,数据强同步,支持主RootServer宕机自动切换。
9.2.1 数据结构
RootServer的中心数据结构为一张存储了子表数据分布的有序表格,称为RootTable。每个子表存储的信息包括:子表主键范围、子表各个副本所在ChunkServer的编号、子表各个副本的数据行数、占用的磁盘空间、CRC校验值以及基线数据版本。
RootServer是一个读多写少的数据结构,除了ChunkServer汇报、RootServer发起子表复制、迁移以及合并等操作需要修改RootTable外,其他操作都只需要从RootTable中读取某个子表所在的ChunkServer。
ChunkServer汇报的子表信息可能和RootTable中记录的不同,比如发生了子表分裂。此时,RootServer需要根据汇报的tablet信息更新RootTable。
RootServer中还有一个管理所有ChunkServer信息的数组,称为ChunkServer-Manager。数组中的每个元素代表一台ChunkServer,存储的信息包括:机器状态(已下线、正在服务、正在汇报、汇报完成,等等)、启动后注册时间、上次心跳时间、磁盘相关信息、负载均衡相关信息。
9.2.2 子表复制与负载均衡
RootServer中有两种操作都可能触发子表迁移:子表复制(rereplication)以及负载均衡(rebalance)。
每台ChunkServer记录了子表迁移相关信息,包括:ChunkServer上子表的个数以及所有子表的大小总和,正在迁入的子表个数、正在迁出的子表个数以及子表迁移任务列表。
子表复制以及负载均衡生成的子表迁移任务并不会立即执行,而是会加入到迁移源的迁移任务列表中,RootServer还有一个后台线程会扫描所有的ChunkServer,接着执行每台ChunkServer的迁移任务列表中保存的迁移任务。子表迁移时限制了每台ChunkServer同时进行的最大迁入和迁出任务数,从而防止一台新的ChunkServer刚上线时,迁入大量子表而负载过高。
9.2.3 子表分裂与合并
子表分裂由ChunkServer在定期合并过程中执行,由于每个子表包含多个版本,且分布在多台ChunkServer上,如何确保多个副本之间的分裂点保持一致成为问题的关键。OceanBase采用了一种比较直接的做法:每台ChunkServer使用相同的分裂规则。由于每个子表的不同副本之间的基线数据完全一致,且定期合并过程中冻结的增量数据也完全相同,只要分裂规则一致,分裂后的子表主键范围也保证相同。
每个子表包含多个副本,只要某一个副本合并成功,OceanBase就认为子表合并成功,其他合并失败的子表将通过垃圾回收机制删除掉。
9.2.4 UpdateServer选主
为了确保一致性,RootServer需要确保每个集群中只有一台UpdateServer提供写服务,这个UpdateServer称为主UpdateServer。RootServer通过租约(Lease)机制实现UpdateServer选主。
9.2.5 RootServer主备
每个集群一般部署一主一备两台RootServer,主备之间数据强同步,即所有的操作都需要首先同步到备机,接着修改主机,最后才能返回操作成功。
RootServer主备之间需要同步的数据包括:RootTable中记录的子表分布信息、ChunkServerManager中记录的ChunkServer机器变化信息以及UpdateServer机器信息。子表复制、负载均衡、合并、分裂以及ChunkServer/UpdateServer上下线等操作都会引起RootServer内部数据变化,这些变化都将以操作日志的形式同步到备RootServer。备RootServer实现回放这些操作日志,从而与主RootServer保持同步。
9.3 UpdateServer实现机制
UpdateServer用于存储增量数据,他是一个单机存储系统,由如下几个部分组成:
- 内存存储引擎,在内存中存储修改增量,支持冻结以及转储操作;
- 任务处理模型,包括网络框架、任务队列、工作线程等,针对小数据包做了专门的优化;
- 主备同步模块,将更新事务以操作日志的形式同步到备UpdateServer。
UpdateServer是OceanBase性能瓶颈点,核心是高效,实现时对锁(例如、无锁数据结构)、索引结构、内存占用、任务处理模型以及主备同步都需要做专门的优化。
9.3.1 存储引擎

UpdateServer存储引擎与Bigtable存储引擎看起来很相似,不同点在于:
- UpdateServer只存储了增量修改数据,基线数据以SSTable的形式存储在ChunkServer上,而Bigtable存储引擎同时包含某个子表的基线数据和增量数据;
- UpdateServer内部所有表格共用MemTable以及SSTable,而Bigtable中每个子表的MemTable和SSTable分开存放;
- UpdateServer的SSTable存储在SSD磁盘中,而Bigtable的SSTable存储在GFS中。
UpdateServer存储引擎包含几个部分:操作日志、MemTable以及SSTable。更新操作首先记录到操作日志中,接着更新内存中活跃的MemTable(Active MemTable),活跃的MemTable到达一定大小后将被冻结,称为Frozen MemTable,同时创建新的Active MemTable。Frozen MemTable将以SSTable文件的形式转储到SSD磁盘中。
- 操作日志
OceanBase中有一个专门的提交线程负责确定多个写事务的顺序(即事务id),将这些写事务的操作追加到日志缓冲区,并将日志缓冲区的内容写入日志文件。 - MemTable
MemTable底层是一个高性能内存B树。MemTable封装了B树,对外提供统一的读写接口。
B树中的每个叶子节点对应MemTable中的一行数据,key为行主键,value为行操作链表的指针。每行的操作按照时间顺序构成一个行操作链表。
MemTable的内存结构包含两部分:索引结构以及行操作链表,索引结构为B树,支持插入、删除、更新、随机读取以及范围查询操作。行操作链表保存的是对某一行哥哥列(每个行和列确定一个单元)的修改操作。
MemTable实现时做了很多优化,包括:
(1)哈希索引:针对主要操作为随机读取的应用,MemTable不仅支持B树索引,还支持哈希索引,UpdateServer内部会保证两个索引之间的一致性。
(2)内存优化:行操作链表中每个cell操作都需要存储操作列的编号(column_id)、操作类型(更新操作还是删除操作)、操作值以及指向下一个cell操作的指针,如果不做优化,内存膨胀会很大。为了减少内存占用,MemTable实现时会对整数值进行变长编码,并将多个cell操作编码后序列到同一块缓冲区中,共用一个指向下一批cell操作缓冲区的指针 - SSTable
当活跃的MemTable超过一定大小或者管理员主动发出冻结命令时,活跃的MemTable将被冻结,生成冻结的MemTable,并同时以SSTable的形式转储到SSD磁盘中。
UpdateServer的缓存预热机制实现如下:在丢弃冻结MemTable之前的一段时间(比如10分钟),每隔一段时间(比如30秒),将一定比率(比如5%)的请求发送给SSTable,而不是冻结MemTable。这样,SSTable上的读请求将从5%到10%,再到15%,以此类推,直到100%,很自然地实现了缓存预热。
9.3.2 任务模型
任务模型包括网络框架、任务队列、工作线程。
- Tbnet
Tbnet队列模型本质上是一个生产者-消费者队列模型,有两个线程:网络读写线程以及超时检查线程,其中,网络读写线程执行事件循环,当服务器端有可读事件时,调用回调函数读取请求数据包,生成请求任务,并加入到任务队列中。工作线程从任务队列中获取任务,处理完成后触发可写事件,网络读写线程会将处理结果发送给客户端。超时检查线程用于将超时的请求移除。 - Libeasy
为了解决收发小数据包带来的上下文切换问题,OceanBase目前采用Libeasy任务模型。Libeasy采用多个线程收发包,增强了网络收发能力,每个线程收到网络包后立即处理,减少了上下文切换。
UpdateServer有多个网络读写线程,每个线程通过Linux epool监听一个套接字集合上的网络读写事件,每个套接字只能同时分配一个线程。
9.3.3 主备同步
正常情况下,备UpdateServer的日志回放线程会从全局日志缓冲区中读取操作日志,在内存中回放并同时将操作日志刷到备机的日志文件中。如果发生异常,比如备UpdateServer刚启动或者主备之间网络刚恢复,全局日志缓冲区中没有日志或者日志不连续,此时,备UpdateServer需要主动请求主UpdateServer拉取操作日志。主UpdateServer首先查找日志缓冲区,如果缓冲区没有数据,还需要读取磁盘日志文件,并将操作日志回复备UpdateServer。
9.4 ChunkServer实现机制
ChunkServer用于存储基线数据,它由如下基本部分组成:
- 管理子表,主动实现子表分裂,配合RootServer实现子表迁移、删除、合并;
- SSTable,根据主键有序存储每个子表的基线数据;
- 基于LRU实现块缓存(Block cache)以及行缓存(Row cache);
- 实现Direct IO,磁盘IO与CPU计算并行化;
- 通过定期合并 & 数据分发获取UpdateServer的冻结数据,从而分散到整个集群。
每台ChunkServer服务着几千到几万个子表的基线数据,每个子表由若干个SSTable组成(一般为1个)。
9.4.1 子表管理
每台ChunkServer服务于多个子表,子表的个数一般在10000~100000之间。ChunkServer内部通过ObMultiVersionTabletImage来存储每个子表的索引信息,包括数据行数(row_count),数据量(occupy_size),校验和(check_sum),包含的SSTable列表,所在磁盘编号(disk_no)等。
ChunkServer维护了多个版本的子表数据,每日合并后升级子表的版本号,如果子表发生分裂,每日合并后将一个子表变成多个子表。
9.4.2 SSTable
SSTable中的数据按主键排序后存放在连续的数据块(Block)中,Block之间也有序。接着,存放数据块索引(Block Index),由每个Block最后一行的主键(End Key)组成,用于数据查询中的Block定位。接着,存放布隆过滤器(Bloom Filter)和表格的Schema信息。最后,存放固定大小的Trailer以及Trailer的偏移位置。
SSTable分为两种格式:稀疏格式以及稠密格式。ChunkServer中的SSTable为稠密格式,而UpdateServer中的SSTable为稀疏格式,且存储了多张表格的数据。另外,SSTable支持压缩功能,压缩以Block为单位。每个Block写入磁盘之前调用压缩算法执行压缩,读取时需要解压缩。
OceanBase读取的数据可能来源于MemTable,也可能来源于SSTable,或者是合并多个MemTable和多个SSTable生成的结果。无论底层数据来源如何变化,上层的读取接口总是ObIterator。
9.4.3 缓存实现
ChunkServer中包含三种缓存:块缓存(Block Cache)、行缓存(Row Cache)以及块索引缓存(Block Index Cache)。一般来说,块索引不会太大,ChunkServer中所有SSTable的块索引都是常驻内存的。不同缓存的底层采用相同的实现方式。
- 底层实现
经典的LRU缓存实现包含两个部分:哈希表和LRU链表,其中,哈希表用于查找缓存中的元素,LRU链表用于淘汰。 - 惊群效应
以行缓存为例,假设ChunkServer中有一个热点行,ChunkServer中的N个工作线程(假设为N=50)同时发现这一行的缓存失效,于是,所有工作线程同时读取这行数据并更新行缓存。可以看出,N-1共49个线程不仅做了无用功,还增加了锁冲突。这种现象称为“惊群效应”。为了解决这个问题,第一个线程发现行缓存失效时会往缓存中加入一个fake标记,其他线程发现这个标记后会等待一段时间,直到第一个线程从SSTable中读取到这行数据并加入到行缓存后,再从行缓存中读取。 - 缓存预热
ChunkServer定期合并后需要使用生成的新的SSTable提供服务,如果大量请求同时读取新的SSTable文件,将使得ChunkServer的服务能力在切换SSTable瞬间大幅下降。目前的线上版本使用的时被动缓存预热。
9.4.4 IO实现
OceanBase没有使用操作系统本身的页面缓存(page cache)机制,而是自己实现缓存。相应地,IO也采用Direct IO实现,并且支持磁盘IO与CPU计算并行化。
ChunkServer采用Linux的Libaio实现异步IO,并通过双缓冲机制实现磁盘预读与CPU处理并行化。
双缓冲区广泛用于生产者/消费者模型,ChunkServer中使用了双缓冲区异步预读的技术,生产者为磁盘,消费者为CPU,磁盘中生产的原始数据需要给CPU计算消费掉。为了做到不冲突,给每个缓存区分配一把互斥锁(简称La和Lb)。生产者或者消费者如果要操作某个缓冲区,必须先拥有对应的互斥锁。
缓冲区包括如下几种状态:
- 双缓冲区都在使用的状态(并发读写):节约开销的主要来源
- 单个缓冲区空闲状态
- 缓冲区的切换
9.4.5 定期合并&数据分发
RootServer将UpdateServer上的版本变化信息通知ChunkServer后,ChunkServer将执行定期合并或者数据分发。
如果UpdateServer执行了大版本冻结,ChunkServer将执行定期合并。
如果UpdateServer执行了小版本冻结,ChunkServer将执行数据分发。与定期合并不同的是,数据分发只是将UpdateServer冻结的数据缓存到ChunkServer,并不会生成新的SSTable文件。因此,数据分发对ChunkServer造成的压力不大。
9.4.6 定期合并限速
定期合并期间系统的压力较大,需要控制定期合并的速度,避免影响正常服务。定期合并限速的措施如下:
- ChunkServer
- UpdateServer
9.5 消除更新瓶颈
OceanBase团队持续不断地性能优化以及旁路导入功能的开发,单点的架构经受住了考验。但是OceanBase系统设计时已经留好了“后门”,以后可以通过对系统打补丁的方式支持UpdateServer线性扩展。
9.5.1 读写优化回顾
OceanBase UpdateServer相当于一个内存数据库。
- 网络框架优化
- 高性能内存数据结构
- 写操作日志优化
1)成组提交
2)降低日志缓冲区的锁冲突
3)日志文件并发写入 - 内存容量优化
9.5.2 数据旁路导入
对于定期导入大批数据,对导入性能要求很高。为此,OceanBase专门开发了旁路导入功能,直接将数据导入到ChunkServer中(即ChunkServer旁路导入)。
OceanBase的数据按照全局有序排列,因此,旁路导入的第一步就是使用Hadoop MapReduce这样的工具将所有的数据排好序,并且划分为一个个有序的范围,每个范围对应一个SSTable文件。接着,再将SSTable文件并行拷贝到集群中所有的ChunkServer中。最后,通知RootServer要求每个ChunkServer并行加载这些SSTable。每个SSTable文件对应ChunkServer的一个子表,ChunkServer加载完本地的SSTable文件后会向RootServer汇报,RootServer接着将汇报的子表信息更新到RootTable中。
9.5.3 数据分区
OceanBase可以借鉴关系数据库中的分区表的概念,将数据划分为多个分区,允许不同的分区被不同的UpdateServer服务。
第10章 数据库功能
数据库功能层构建在分布式存储引擎层之上,实现完整的关系数据库功能。关系数据库系统中优化器是最为复杂的,这个问题困扰了关系数据库几十年。
10.1 整体结构

用户可以通过兼容MySQL协议的客户端、JDBC/ODBC等方式请求发送给某一台MergeServer,MergeServer的MySQL协议模块将解析出其中的SQL语句,并交给MS—SQL模块进行词法分析(采用GUN Flex实现)、语法分析(采用GUN Bison实现)、预处理、并生成逻辑执行计划和物理执行计划。
- CS-SQL:实现针对单个子表的SQL查询,包括表格扫描(table scan)、投影(projection)、过滤(filter)、排序(order by)、分组(group by)、分页(limit),支持表达式计算、聚集函数(count、sum、max、min等)。执行表格扫描时,需要从UpdateServer读取修改增量,与本地的基线数据合并。
- UPS-SQL:实现写事务,支持的功能包括多版本并发控制、操作日志多线程并发回放等。
- MS-SQL:SQL语句解析,包括词法分析、语法分析、预处理、生成执行计划,按照子表范围合并多个ChunkServer返回的部分结果,实现针对多个表格的物理操作符,包括联表(Join),子查询(subquery)等。
10.2 只读事务
只读事务(SELECT语句),经过词法分析、语法分析,预处理后,转化为逻辑查询计划和物理查询计划。逻辑查询计划的改进以及物理查询计划的选择,即查询优化器,是关系数据库最难的部分。
10.2.1 物理操作符接口
所有的物理运算符构成一个树,每个物理运算的输出结果都可以认为是一个临时的二维表,树中孩子节点的输出总是作为它的父亲节点的输入。
SQL最终执行时,只需要迭代root_op(即limit_op)也能够把需要的数据依次迭代出来。limit_op发现前一批数据迭代完成则驱动下层的project_op获取下一批数据,project_op发现前一批数据迭代完成则驱动下层的sort_op获取下一批数据。以此类推,直到最底层的table_scan_op不断地从原始表t1中读取数据。
10.2.2 单表操作
单表相关的物理运算符包括:
- TableScan:扫描某个表格,MergeServer将扫描请求发给请求的各个子表所在的ChunkServer,并将ChunkServer返回的结果按照子表范围拼接起来作为输出。如果请求涉及多个子表,TableScan可由多台ChunkServer并发执行。
- Filter:针对每行数据,判断是否满足过滤条件。
- Projection:对输入的每一行,根据定义的输出表达式,计算输出结果行。
- GroupBy:把输入数据按照指定列进行聚集,对聚集后的每组数据可以执行计数(count)、求和(sum)、计算最小值(min)、计算最大值(max)、计算平均值(avg)等聚集操作。
- Sort:对输入数据进行整体排序,如果内存不够,需要使用外排序。
- Limit(offset,count):返回行号在[offset,offset+count]范围内的行。
- Distinct:消除某些列相同的重复行。
GroupBy、Distinct物理操作符可以通过基于排序的算法实现,也可以通过基于哈希的算法实现,分别对应HashGroupBy和MergeGroupBy,以及HashDistinct和MergeDistinct。
10.2.3 多表操作
多表相关的物理操作符主要是Join。最为常见的Join类型包括两种:内连接(Inner Join)和左外连接(Left Outer Join),而且基本都是等值连接。两张表实现等值连接方式主要分为两类:基于排序的算法(MergeJoin)以及基于哈希的算法(HashJoin)。
子查询分为两种:关联子查询和非关联子查询,其中比较常用的是使用IN子句的非关联子查询。IN子查询转化为常量表达式后,MergeServer执行SQL计算时,可以将IN后面的常量列表发送给ChunkServer,ChunkServer只返回category_id在常量列表中的商品记录,而不是将所有的记录返回给MergeServer过滤,从而减少二者之间传输的数据量。
10.2.4 SQL执行本地化
多表操作由MergeServer执行,对于单表操作,OceanBase涉及的基本原则是尽量支持SQL计算本地化,保持数据节点与计算节点一致,也就是说,只要ChunkServer能够实现的操作,原则上都应该有它来完成。
当然,如果能够确定请求的数据全部属于同一个子表,那么,所有的物理运算符都可以由ChunkServer执行,MergeServer只需要将ChunkServer计算得到的结果转发给客户端。
10.3 写事务
写事务,包括更新(UPDATE)、插入(INSERT)、删除(DELETE)、替换(REPLACE,插入或者更新,如果行不存在则插入新行;否则,更新已有行),由MergeServer解析后生成物理执行计划,这个物理执行计划最终将发给UpdateServer执行。写事务可能需要读取基线数据,用于判断更新或者插入的数据行是否存在,判断某个条件是否满足,等等,这些基线数据也会由MergeServer传给UpdateServer。
10.3.1 写事务执行流程
大部分写事务都是针对单行的操作,如果单行事务不带其他条件:
- REPLACE:REPLACE事务不关心写入行是否已经存在,因此,MergeServer直接将修改操作发送给UpdateServer执行。
- INSERT:MergeServer首先读取ChunkServer中的基线数据,并将基线数据中行是否存在信息发送给UpdateServer,UpdateServer接着查看增量数据中行是否被删除或者有新的修改操作,融合基线数据和增量数据后,如果行不存在,则执行插入操作;否则,返回行已存在错误。
- UPDATE:与INSERT事务执行步骤类似,不同点在于,行已存在则执行更新操作;否则,什么也不做。
- DELETE:与UPDATE事务执行步骤类似。如果行已存在则执行删除操作;否则,什么也不做。
- UPDATE:如果UPDATE事务带有其他条件,那么,MergeServer除了从基线数据中读取行是否存在,还需要读取用于条件判断的基线数据,并传给UpdateServer。UpdateServer融合基线数据和增量数据后,将会执行条件判断,如果行存在且判断条件成立则执行刚更新操作。否则,返回行已存在或者条件不成立错误。
10.3.2 多版本并发控制
OceanBase的MemTable包含两个部分:索引结构及行操作链。其中,索引结构存储行头信息,采用内存B树实现;行操作链表中存储了不同版本的修改操作,从而支持多版本控制。
MemTable行操作链表包含两个部分:已提交部分和未提交部分。
每个写事务会根据提交时的系统事件生成一个事务版本,读事务只会读取在它之前提交的写事务的修改操作。
- 锁机制
OceanBase锁定力度为行锁,默认情况下的隔离级别为读已提交(read committed)。另外,读操作总是读取某个版本的快照数据,不需要加锁。
只写事务(修改单行)
只写事务(修改多行)
读写事务(read committed)
为了保证系统并发性能,OceanBase暂时不支持更高的隔离级别。OceanBase目前处理死锁的方式很简单,事务执行过程中如果超过一定时间无法获取写锁,则自动回滚。 - 多线程并发日志回放
10.4 OLAP业务支持
OLAP业务的特点是SQL每次执行涉及的数据量很大,需要一次性分析几百万行甚至几千万行的数据。另外,SQL执行时往往只读取每行的部分列而不是整行数据。
10.4.1 并发查询
MergeServer将大请求拆分为多个子请求,同时发往每个子请求所在的ChunkServer并发执行,每个ChunkServer执行子请求并将部分结果返回给MergeServer。MergeServer合并ChunkServer返回的部分结果并将最终结果返回给客户端。
10.4.2 列式存储
列式存储主要的目的有两个:1)大部分OLAP查询只需要读取部分列而不是全部列数据,列式存储可以避免读取无用数据;2)将同一列的数据在物理上存放在一起,能够极大地提高数据压缩率。
列组(Column Group)
OceanBase通过列组支持行列混合存储,每个列组存储多个经常一起访问的列。OceanBase SSTable首先按照列组存储,每个列组内部再按行存储。分为几种情况:
- 所有列属于同一个列组。数据在SSTable中按行存储,OLTP应用往往配置为这种方式。
- 每列对应一个列组。数据在SSTable中按列存储,这种方式在实际应用中比较少见。
- 每个列组对应一个数据的部分列。数据在SSTable中按行列混合存储,OLAP应用往往配置为这种方式。
OceanBase还允许一个列属于多个列,通过冗余存储这些列,能够提高访问性能。
10.5 特色功能
10.5.1 大表左连接
大表左连接需求来源于淘宝收藏夹业务。关系数据库多表连接操作和冗余都是不能够被接受的。
这个问题本质上是一个大表左连接(Left Join)的问题,连接列为item_id,即右表(商品表)的主键。对于这个问题,OceanBase的做法是在collect_info的基线数据中冗余collect_item信息,修改增量中将collect_info和collect_item两张表格分开存储。商品价格、人气变化只需要记录在UpdateServer的修改增量中。
OceanBase的实现方式得益于每天业务低峰期进行的每日合并操作。每日合并时,ChunkServer会将UpdateServer上collect_info和collect_item表格中的修改增量融合到collect_info表格的基线数据中,生成新的基线数据。因此,collect_info和collect_item的数据量不至于太大,从而能够存放到单机机器的内存中提供高效查询服务。
10.5.2 数据过期与批量删除
很多业务只需要存储一段时间,比如三个月或者半年的数据,更早之前的数据可以被丢弃或者转移到历史库从而节省存储成本。
OceanBase线上每个表格都包含创建时间(gmt_create)和修改时间(gmt_modified)列。使用者可以设置自动过期规则,比如只保留创建时间或修改时间不晚于某个时间点的数据行,读取操作会根据规则过滤这些失效的数据行,每日合并时这些数据行会被物理删除。
第11章 质量保证、运维及实践
OceanBase系统一直在不断演化,需要在代码不断变化的过程中保持系统的稳定性。
11.1 质量保证
一个新版本需要经过开发 =》单元测试 & 快速测试 =》RD(开发工程师)压力测试 =》系统提测 =》QA(测试工程师)接口、功能、容灾、压力测试 =》兼容性测试 =》Benchmark测试才能最终发布,其中,RD压力测试和兼容性测试是可选的。发布的新版本还需要经过业务压力测试或者线上流量回放才能上线试运行,试运行一段时间后没有发现问题才能最终上线。
11.1.1 RD开发
系统Bug暴露越早修复代价越低,开发工程师是产生Bug的源头,开发阶段主要通过编码规范、代码审核(Code Review)、单元测试保证代码质量。
- 编码规范
- 代码审核
- 单元测试
- 快速测试(quicktest)
- RD压力测试
(1)分布式存储引擎压力测试
分布式存储引擎压力测试工具包含:syschecker以及mixed_test。
(2)数据库功能压力测试
数据库功能压力测试工具包含两个:sqltest以及bigquery。
11.1.2 QA测试
RD提测新版本后,进入QA测试阶段。
- 接口、功能、容灾测试
- 压力测试
- Benchmark测试
- 兼容性测试
11.1.3 试运行
- 业务压力测试
- 线上流量回放
- 灰度上线
11.2 使用与运维
OceanBase不是设计出来的,而是在使用过程中不断进化出来的。
11.2.1 使用
- MySQL客户端连接
- JDBC访问(JDBC template)
- Spring集成
- C客户端
11.2.2 运维
OceanBase内部实现了系统表机制,用于存储监控以及运维相关的信息。内部系统表包含的内容如下:
- 数据字典:表格的定义以及表格之间的关系、用户以及权限信息
- 服务器列表:集群中每种角色所在的服务器列表
- 配置信息:集群中每台服务器的配置信息
- 内部状态:每台服务器的读写次数、读写延时、缓存命中率、子表个数、内存、磁盘、CPU使用情况、请求关键路径时间消耗,每日合并状态等
11.3 应用
虽然OceanBase同时支持OLTP以及OLAP应用,但是OceanBase具有一定的适用场景。如果应用总数据量小于200TB,每天更新的数据量小于1TB,且读写压力较大,单台关系数据库无法支撑,那么,适合采用OceanBase。对于这种应用,OceanBase具有如下优势:
- 无需分库分表
- 易于使用
- 更低的成本
当然,OceanBase并不是万能的。例如,OceanBase不适合存储图片、视频等非结构化数据,也不适合存储业务原始日志。这些信息更适合存储在专门的分布式文件系统,比如Taobao File System、HDFS中。
11.3.1 收藏夹
收藏夹属于典型的OLTP业务,主要功能如下:
- 收藏列表功能(范围查询):按照某种过滤条件,例如标题、标签等查询某个用户的所有收藏;可能需要按照某种特定条件排序,例如商品价格、收藏时间等;支持对结果的分页;支持在结果集上执行聚合操作,例如Count计数。
- 修改操作:将商品或者店铺添加到收藏夹,删除收藏,对收藏条目打标签。
11.3.2 天猫评价
天猫评价也属于典型的OLTP应用,主要功能如下:
- 评价展示(范围查询):按照某种过滤条件,例如标签,查询某个商品的所有评价;可能需要按照某种特定条件排序,例如时间、信用;支持对结果的分页;支持在结果集上执行聚合操作,例如Count计数。
- 修改操作:新增一条评价,求改评价,例如将好评需修改为差评。
和传统数据库方案相比,OceanBase的优势主要体现在两个方面:
- 相比传统数据库,OceanBase的数据在物理上连续存放,因此,顺序扫描性能更好,适合大查询使用场景。
- 如果过一个商品的评价数过多,OceanBase系统内部会自动将该商品的数据拆分为多个子表,从而发挥OceanBase的并发查询优势。
11.3.3 直通车报表
直通车报表是典型的OLAP报表,包含如下几个方面:
- 数据定期导入:每天凌晨将Hadoop分析结果导入OceanBase
- 报表查询:按照用户、推广计划、宝贝、关键词等多种维度分组,统计展现量、财务花费等数据,相应前端的实时查询需求。
11.4 最佳实践
分布式存储系统从整体架构的角度看大同小异,实现起来却困难重重。
11.4.1 系统发展路径
通用分布式存储系统不是设计出来的,而是随着应用需求不断发展起来的。他来源于具体业务,又具有一定的通用性,能够解决一大类问题。通用分布式存储平台的优势在于规模效应,等到平台的规模超过某个平衡点时,成本优势将会显现。
11.4.2 人员成长
- 师兄带师弟
- 架构理论学习
论文或者系统仅仅给出一种整体方案,并不会明确给出方案的实现细节以及背后经历的权衡。这就要求我们在架构学习的过程中主动挖掘整体架构背后的设计思想和关键实现细节。
阅读GFS论文时,可以尝试思考如下问题:
1)为什么存储三个副本?而不是两个或者四个?
2)Chunk的大小为何选择64MB?这个选择主要基于哪些考虑?
3)GFS主要支持追加(append)、改写(overwrite)操作比较少。为什么这样设计?如何基于一个仅支持追加操作的文件系统构建分布式表格系统Bigtable?
4)为什么要将数据流和控制流分开?如果不分开,如何实现追加流程?
5)GFS有时会出现重复记录或者补零记录(padding),为什么?
6)租约(Lease)是什么?在GFS起什么作用?它与心跳(heartbeat)有何区别?
7)GFS追加操作过程中如果备副本(Secondary)出现故障,如何处理?如果主副本(Primary)出现故障,如何处理?
8)GFS Master需要存储哪些信息?Master数据结构如何设计?
9)假设服务一千万个文件,每个文件1GB,Master中存储的元数据大概占用多少内存?
10)Master如何实现高可用性?
11)负载的影响因素有哪些?如何计算一台机器的负载值?
12)Master新建chunk时如何选择ChunkServer?如果新机器上线,负载值特别低,如何避免其他ChunkServer同时往这台机器迁移chunk?
13)如果某台ChunkServer报废,GFS如何处理?
14)如果ChunkServer下线后过一会重新上线,GFS如何处理?
15)如何实现分布式文件系统的快照操作?
16)ChunkServer数据结构如何设计?
17)磁盘可能出现“位翻转”错误,ChunkServer如何应对?
18)ChunkServer重启后可能有一些过期的chunk,Master如何能够发现?
阅读Bigtable论文时,可以尝试思考如下问题:
1)GFS可能出现重复记录或者补零记录(padding),Bigtable如何处理这种情况使得对外提供强一致性模型?
2)为什么Bigtable设计成根表(RootTable)、元数据表(MetaTable)、用户表(UserTable)三级结构,而不是两级或者四级结构?
3)读取某一行用户数据,最多需要几次请求?分别是什么?
4)如何保证同一个子表不会被多台机器同时服务?
5)子表在内存中的数据结构如何设计?
6)如何设计SSTable的存储格式?
7)minor、merging、major这三种compaction有什么区别?
8)TabletServer的缓存如何实现?
9)如果TabletServer出现故障,需要将服务迁移到其他机器,这个过程需要排序操作日志。如何实现?
10)如何使得子表迁移过程暂停服务时间尽量短?
11)子表分裂的流程是怎样的?
12)子表合并的流程是怎样的?
11.4.3 系统设计
- 架构师职责
分布式存储系统的挑战不在于存储理论,而在于如何做出稳定运行且能够逐步进化的系统。 - 设计原则
(1)容错
(2)自动化
(3)保持兼容
11.4.4 系统实现
- 重视服务器代码资源管理
- 做好代码审核
- 重视测试
11.4.5 使用与运维
稳定性和性能并不是分布式存储系统的全部,一个好的系统还必须具备较好的可用性和可运维性。
- 吃自己的狗粮
- 标准客户端
- 线上版本管理
- 自动化运维
11.4.6 工程现象
- 错误必然发生
- 错误必然复现
- 两倍数据规模
- 怪异现象的背后总有一个愚蠢的初级bug
- 线上问题第一次出现后,第二次将很快出现
11.4.7 经验法则
- 简单性原则
- 精力投入原则
- 先稳定再优化
- 想清楚,再动手
第四篇 专题篇
第12章 云存储
云存储是云计算的存储部分,云计算后端架构的难点集中在云存储。
12.1 云存储的概念
云存储目前为止并没有一个明确的定义。云存储是通过网络将大量普通存储设备构成的存储资源池中的存储和数据服务以及统一的接口按需提供给授权用户。
- 超大规模
- 高可扩展性
- 高可靠性和可用性
- 安全
- 按需服务
- 透明服务
- 自动容错
- 低成本
可以看出,云存储技术的核心在于分布式存储。云存储是传统存储技术在大数据时代自然演进的结果,相比传统存储,云存储具有如下优势:
- 可扩展性
- 利用率
- 成本
- 服务能力
- 便携性
12.2 云存储的产品形态
Amazon推出的针对企业的S3简单存储服务(Amazon Simple Storage Service),它是Amazon云计算平台(Amazon Web Service,AWS)的一种对象存储服务,用于存储照片、图片、视频、音乐等个人文件。
12.3 云存储技术
云存储包括两个部分:云端+终端。
- 摩尔定律
- 宽带网络
- Web技术
- 移动设备
- 分布式存储、CDN、P2P技术
- 数据加密、云安全
12.4 云存储的核心优势
作为云计算的存储部分,云存储的核心优势与云计算相同。主要包括两个方面:最大程度地节省成本以及加快创新速度。
综上所述,由于云存储更低的硬件成本和网络成本,更低管理成本和电力成本,以及更高的资源利用率,Google,Amazon,Microsoft等互联网巨头能够通过从数据中心开始构建整套公有云存储解决方案达到节省30倍以上成本的目的。
12.5 云平台整体架构
云存储是云计算的存储部分,理解云存储架构的前提是理解云平台整体架构。云计算按照服务类型大致可以分为三类:基础设施即服务(IaaS)、平台即服务(PaaS)以及软件即服务(SaaS)。
12.5.1 Amazon云平台
Amazon Web Services(AWS)是Amazon构建的一个云计算平台的总称,它提供了一系列云服务。通过这些服务,用户能够访问和使用Amazon的存储和计算基础设施。AWS平台分为如下几个部分:
- 计算类
- 存储类
- 工具支持
AWS平台引入了区域(Zone)的概念。区域分为两种:地理区域(Region Zone)和可用区域(Availability Zone),其中地理区域是按照实际的地理位置划分的,而可用区域一般是按照数据中心划分的。
12.5.2 Google云平台
Google云平台(Google App Engine,GAE)是一种PaaS服务,使得外部开发者可以通过Google期望的方式使用它的基础设施服务,目前支持Python和Java两种语言。
GAE云平台主要包含如下几个部分:
- 前端服务器
- 应用服务器
- 应用管理节点(App Master)
- 存储区
- 服务区
另外,作为PaaS服务,GAE还提供了如下两种工具:
- 本地开发环境
- 管理工具
GAE的核心组件为应用服务器以及存储区。
12.5.3 Microsoft云平台
Windows Azure 平台包含如下几个部分:
- 计算服务
- 存储服务
- 连接服务
- 工具支持
12.5.4 云平台架构
从托管Web应用程序的角度看,云平台主要包括云存储以及应用运行平台。
云平台的核心组件包括:云存储组件和应用运行平台组件。
云存储平台还包含一些公共服务,这些基础服务由云存储组件及运行平台组件所共用。
- 消息服务
- 缓存服务
- 用户管理
- 权限管理
- 安全服务
- 计费管理
- 资源管理
- 运维管理
- 监控系统
12.6 云存储技术体系
云存储技术体系结构分为四层:硬件层、单机存储层、分布式存储层、存储访问层。
- 硬件层
硬件层包括存储、网络以及CPU。 - 单机存储层
云存储系统的底层大多为定制的Linux操作系统,服务提供商需要在文件系统、网络协议以及CPU和内存使用上对Linux系统进行大量的定制化工作。单机存储系统大致分为两类:传统的关系数据库以及NoSQL存储系统。 - 分布式存储层
分布式存储层是云存储技术的核心,也是最难实现的部分。 - 存储访问层
云存储系统通过存储访问层被个人用户的终端设备直接访问,或者被云存储平台中托管的应用程序访问。
用户的应用程序可能会托管在应用运行平台中,应用场景大致分为三类:
- 弹性计算平台
- 云引擎
- 分布式计算
12.7 云存储安全
在技术层面,云存储安全包括如下几个方面:
- 用户安全
- 网络安全
- 多租户隔离
- 存储安全
总而言之,安全是云存储的核心问题,但不必对此过分担心,前途是光明的,道路是曲折的,随着专业的云存储服务提供商对系统不断的优化,云存储比现有的IT模式反而会更加安全。
第13章 大数据
MapReduce并不是大数据的全部。虽然MapReduce解决了海量数据离线分析问题,但是,随着应用对数据的实时性要求越来越高,流式计算系统和实时分析系统得到越来越广泛的应用。
13.1 大数据的概念
简而言之,从各种各样类型的数据,包括非结构化数据、半结构化数据以及结构化数据中,快速获取有价值信息的能力,就是大数据技术。
大数据的特点可以用四个V来描述:
- Volume传统的数据仓库技术处理GB到TB级别的数据,大数据技术处理的数据量往往超过PB。
- Variety数据类型多。
- Velocity数据增长迅速。
- Value价值密度低。
互联网技术归根结底就是云计算和大数据技术,云计算提供海量数据的存储和计算能力,并最大程度地降低分布式处理的成本,大数据技术进一步从海量数据中抽取数据的价值,从而诞生Google搜索引擎、Amazon商品推荐系统这样的杀手级应用,形成一条大数据采集、处理、反馈的数据处理闭环。
13.2 MapReduce
MapReduce使得普通程序员可以在不了解分布式底层细节的前提下开发分布式程序。使用者只需编写两个称为Map和Reduce的函数即可,MapReduce框架会自动处理数据划分、多机并行执行、任务之间的协调,并且能够处理某个任务执行失败或者机器出现故障的情况。
MapReduce框架包含三种角色:主控进程(Master)用于执行任务划分、调度、任务之间的协调等;Map工作进程(Map Worker,简称Map进程)以及Reduce工作进程(Reduce Worker,简称Reduce进程)分别用于执行Map任务和Reduce任务。
MapReduce框架实现时主要做了两点优化:
- 本地化
尽量将任务分配给离输入文件最近的Map进程,如同一台机器或者同一个机架。通过本地化策略,能够大大减少传输的数据量。 - 备份任务
如果某个Map或者Reduce任务执行的时间较长,主控进程会生成一个该任务的备份并分配给另外一个空闲的Map或者Reduce进程。在大集群环境下,即使所有机器的配置相同,机器的负载不同也会导致处理能力相差很大,通过备份任务减少”拖后腿“的任务,从而降低整个作业的总体执行时间。
13.3 MapReduce扩展
- Google Tenzing
基于MapReduce模型构建SQL执行引擎,使得数据分析人员可以直接通过SQL语言处理大数据 - Microsoft Dryad
将MapReduce模型从一个简单的两步工作流扩展为任何函数集的组合,并通过一个有向无环图来表示函数之间的工作流 - Google Pregel
用于图模型迭代计算,这种场景下Pregel的性能远远好于MapReduce
13.3.1 Google Tenzing
Google Tenzing是一个构建在MapReduce之上的SQL执行引擎,支持SQL查询且能够扩展到成千上万台机器,极大地方便了数据分析人员。
- 整体架构
Tenzing系统有四个主要组件:分布式Worker池、查询服务器、客户端接口和元数据服务器。
查询服务器: 作为连接客户端和worker池的中间桥梁而存在。
分布式Worker池: 作为执行系统,它会根据查询服务器生成的执行计划运行MapReduce任务。
元数据服务器: 存储和获取表格schema、访问控制列表等全局元数据。
存储: 分布式worker池中的master和worker进程执行MapReduce任务时需要读写存储服务。 - 查询流程
- SQL运算符映射到MapReduce
查询服务器负责将用户的SQL操作转化为MapReduce作业。
13.3.2 Microsoft Dryad
Microsoft Dryad是微软研究院创建的研究项目,主要用来提供一个分布式并行计算平台。Dryad的主控进程(Job Manager)负责将整个工作分割成多个任务,并分发给多个节点执行。每个节点执行完任务通知主控进程,接着,主控进程会通知后续节点获取前一个结点的输出结果。等到后续节点的输出数据全部准备好后,才可以继续执行后续任务。
Dryad与MapReduce具有的共有特性就是,只有任务完成之后才会输出传递给接收任务。如果某个任务失败,其结果将不会传递给它在工作流中的任何后续任务。因此,主控进程可以在其他计算节点上重启该任务,同时不用担心会将结果重复传递给以前传递过的任务。
相比多个MapReduce作业串联模型,Dryad模型的优势在于不需要将每个MapReduce作业输出的临时结果存放在分布式文件系统中。如果先存储前一个MapReduce作业的结果,然后再启动新的MapReduce作业,那么,这种开销很难避免。
13.3.3 Google Pregel
Google Pregel用于图模型迭代计算。Pregel采用了BSP(Bulk Sychronous Parallel)模型。每个“超步”分为三个步骤:每个节点首先执行本地计算,接着将本地计算的结果发送给图中相邻的节点,最后执行一次栅栏同步,等待所有节点的前两步操作结束。Pregel模型会在每个超步做一次数迭代计算,当某次迭代生成的结果没有比上一次更好,说明结果已经收敛,可以终止迭代。
- 超步
- 终止条件
Pregel通过检查点(checkpoint)的方式进行容错处理。它在每执行完一个超步之后会记录整个计算的现场,即记录检查点情况。检查点中记录了这一轮迭代中每个任务的全部状态信息,一旦后续某个计算节点失效,Pregel将从最近的检查点重启整个超步。尽管上述的容错策略会重做很多并未失效的任务,但是实现简单。考虑到服务器故障的概率不高,这种方法在大多数时候还是令人满意的。
13.4 流式计算
流式计算(Stream Processing)解决在线聚合(Online Aggregation)、在线过滤(Online Filter)等问题,流式计算同时具有存储系统和计算系统的特点,经常应用在一些类似反作弊、交易异常监控等场景。流式计算的操作算子和时间相关,处理最近一段时间窗口内的数据。
13.4.1 原理
流式计算强调的是数据流的实时性。MapReduce系统主要解决的是对静态数据的批量处理,当MapReduce作业启动时,已经准备好了输入数据,比如保存在分布式文件系统上。而流式计算系统在启动时,输入数据一般并没有完全到位,而是经由外部数据流源源不断地流入。另外,流式计算并不像批处理系统那样,重视数据处理的总吞吐量,而是更加重视对数据处理的延迟。
典型钩子函数包括:
- 聚合函数
计算最近一段时间窗口内数据的集合值,如max、min、avg、sum、count等 - 过滤函数
过滤最近一段时间窗口内满足某些特性的数据,如过滤1秒钟内重复的点击
13.4.2 Yahoo S4
Yahoo S4最初是Yahoo为了提高搜索广告有效点击率而开发的一个流式处理系统。S4的主要设计目标是提供一种简单的编程接口来处理数据流,使得用户可以定制流式计算的操作算子。
S4中每个处理节点称为一个处理节点(Processing Node,PN),其主要工作是监听事件,当事件到达调用合适的处理元(Processing Elements,PE)处理事件。如果PE有输出,则还需调用通信层接口进行事件的分发和输出。
通信层提供集群路由(Routing)、负载均衡(Load Balancing)、故障恢复管理(Failover Management)、逻辑节点到物理节点的映射(存放在Zookeeper上)。当检测到节点故障时,会切换到备用节点,并自动更新映射关系。通信层隐藏的映射使得PN发送消息时只需要关心逻辑点而不用关心物理节点。
13.4.3 Twitter Storm
Twitter Storm是目前广泛使用的流式计算系统,它创造性地引入了一种记录级容错的方法。
- Nimbus
负责资源分配、任务调度、监控状态。Nimbus和supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。 - Supervisor
负责接受nimbus分配的任务,启动和停止属于自己管理的Worker进程。 - Worker
运行spout/bolt组件的进程。 - Spout
产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为内部的数据格式。Spout是一个主动的角色,其接口中有个nextTuple()函数,Storm框架会不停地调用此函数,用户只要在其中生源数据即可。 - Bolt
接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
Storm中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message绑定的若干tuple的处理路径。
13.5 实时分析
实时分为两种情况:如果查询模式单一,那么,可以通过MapReduce预处理后将最终结果导入到在线系统提供实时查询;如果查询模式复杂,例如设计到多个列热议组合查询,那么,只能通过实时分析系统解决。实时分析系统融合了并行数据库和云计算这两类技术,能够从海量数据中快速分析出汇总结果。
13.5.1 MPP架构
并行数据库往往采用MPP(Massively Parallel Processing,大规模并行处理)架构。MPP架构是一种不共享的结构,每个节点可以运行自己的操作系统、数据库等。每个节点内的CPU不能访问另一个节点的内存,节点之间的信息交互是通过节点互联网络实现的。
将数据分布到多个节点,每个节点扫描本地数据,并由Merge操作符执行结果汇总。
常见的数据分布算法有两种:
- 范围分区(Range partition): 按照范围划分数据
- 哈希分区(Hashing): 根据哈希函数计算结果将每个元组分配给相应的节点
13.5.2 EMC Greenplum
Greenplum是EMC公司研发的一款采用MPP架构的OLAP产品,底层基于开源的PostgreSQL数据库。
- 整体架构
Greenplum系统主要包含两种角色:Master服务器(Master Server)和Segment(Segment Server)。在Greenplum中每个表是分布在所有节点上的。Master服务器首先对表的某个或多个列进行哈希运算,然后根据哈希结果将表的数据分布到Segment服务器中。整个过程中Master服务器不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。
Greenplum支持两种访问方式:SQL和MapReduce。用户将SQL操作语句发送给Master服务器,由Master服务器执行词法分析、语法分析,生成查询计划,并将查询请求分发给多台Segment服务器。每个Segment服务器返回部分结果后,Master服务器会进行聚合并将最终结果返回用户。除了高效查询,Greenplum还支持通过数据的并行装载,将外部数据并行装载到所有的Segment服务器。 - 并行查询优化器
Greenplum的并行查询优化器负责将用户的SQL或者MapReduce请求转化为物理执行计划。
Greenplum除了生成传统关系数据库的物理运算符,包括表格扫描(Scan)、过滤(Filter)、聚集(Aggregation)、排序(Sort)、联表(Join),还会生成一些并行运算符,用来描述查询执行过程中如何在节点之间传输数据。
广播(Broadcast,N:N): 每个计算节点将目标数据发送给所有其他系节点
重新分布(Redistribute,N:N): 类似MapReduce中的shuffle过程,每个计算节点将目标数据重新哈希分散到所有节点
汇总(Gather,N:1): 所有的计算节点将目标数据发送给某个节点(一般为Master服务器)
13.5.3 HP Vertica
Vertica是Michael Stonebraker的学术研究项目C-Store的商业版本,并最终被惠普公司收购。Vetica在架构上与OceanBase由相似之处。
- 混合存储模型
- 多映射(Projection)存储
Vertica通常维护多个不同排序的有重叠的映射,尽量使得每个查询的数据只来自一个映射,以提高查询性能。为了支持任意列查询,需要保证每个列至少在一个映射中出现。 - 列式存储
Vertica中的每一列数据独立存储在磁盘中的连续块上。 - 压缩技术
Vertica中的每一列数据独立存储在磁盘中的连续块上。查询数据时,Vertica只需要读取那些需要的列,而不是被选择的行的所有的列数据。另外,Vertica还支持直接在压缩后的数据上做运算。
13.5.4 Google Dremel
Google Dremel是Google的实时分析系统,可以扩展到上千台及其规模,处理PB级别的数据。
- 系统架构
Dremel系统融合了并行数据库和Web搜索技术,Dremel采用多层并层级向上汇报的方式实现数据运算后的汇聚。 - Dremel与MapReduce的比较
MapReduce的输出结果直接由reduce任务写入到分布式文件系统,因此,只要reduce任务个数足够多,输出结果可以很大;而Dremel中的最终数据汇聚到一个根节点,因此一般要求最终的结果集比较小,例如GB级别以下。
Dremel的优势i在于实时性,只要服务器个数足够多,大部分情况下能够在3秒以内处理完成TB级别数据。