机器学习算法-朴素贝叶斯
贝叶斯(Thomas Bayes) ,英国数学家。约1701年出生于伦敦,做过神甫。1742年成为英国皇家学会会员。1761年4月7日逝世。贝叶斯在数学方面主要研究概率论,他首先将归纳推理法用于概率论基础理论,并创立了贝叶斯统计理论,对统计决策函数、统计推断、统计的估算等做出了卓越的贡献。学过概率论的同学一定对贝叶斯耳熟能详,并且被其创造的贝叶斯定理深深折服。尽管书本上是以数学公式对外展现,并搭配详尽的理论证明,但其原理毋需数字也可明了:如果你看到一个人总是做一些好事,则那个人多半会是一个好人。这就是说,当你不能准确知悉一个事物的本质时,你可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。 用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。
贝叶斯定理特别好用,但并不复杂,它解决了生活中经常碰到的问题:已知某条件下的概率,如何得到两条件交换后的概率。贝叶斯分类法基于贝叶斯定理,是统计学分类方法,它可以基于当前条件预测样本的类隶属关系概率,如一个给定元组属于一个特定类的概率。朴素贝叶斯分类法假定一个属性值在给定类上的概率独立于其他属性的值,这一假定称为类条件独立性。
一、基本原理
设 x 是类标号未知的数据样本。对于分类问题,如数据样本 x 属于某特定的类 C 。我们希望确定P(C|x),即给定观测数据样本 x ,假定 x 属于某特定的类 C 成立的概率。贝叶斯定理给出了如下计算P(C|x)的简单有效的方法:
P(C) 是先验概率,或称 C 的先验概率。P(x|C)代表在类别 C 中观察到x的概率。 P(C|x) 是后验概率,或称条件 x 下 C 的后验概率。例如数据样本域由水果组成,用它们的颜色和形状来描述。假定x表示红色和圆的,如果 x 是苹果,则 P(C|x) 反映当我们看到 x 是红色并是圆的时,我们对 x 是苹果的确信程度。此确定度大于我们将 x 判定为梨、西瓜、火龙果等的可能。贝叶斯分类器对两种数据具有较好的分类效果:一种是完全独立的数据,另一种是函数依赖的数据。
二、算法步骤
接下来详细介绍一下朴素贝叶斯分类的工作过程,具体如下所示:
1. 每个数据样本用一个 n 维特征向量x={x1,x2,……,xn}表示,分别描述对 n 个属性A1, A2 ,……, An 样本的 n 个度量。
2. 假定有m个类 C1 , C2 ,…, Cm ,给定一个未知的数据样本 x′ (即没有类标号),计算样本 x′ 属于类 Ci 的后验概率。根据贝叶斯定理
3. 由于 P(x′) 只与数据的分布有关,对于所有类均为常数,因此可以不考虑,只需要 P(x′|Ci)P(Ci) 最大即可。如果 Ci 类的先验概率未知,则通常假定这些类是等概率的,即 P(C1)=P(C2)=…=P(Cm) ,因此问题就转换为对 P(x′|Ci) 的最大化( P(x′|Ci) 常被称为给定 Ci 时数据 x′ 的似然度,而使 P(x′|Ci) 最大的假设 Ci 称为最大似然假设)。否则需要最大化 P(x′|Ci)P(Ci) ,此时类的先验概率可以用 P(Ci)=si/s 计算,其中 si 是类 Ci 中的训练样本数,而 s 是训练样本总数。
4. 给定具有许多属性的数据集,计算P(x′|Ci) 的开销可能非常大。为降低计算 P(x′|Ci) 的开销,可以做类条件独立的朴素假定:给定样本的类标号,假定属性值相互条件独立,即在属性间,不存在依赖关系。这样
其中概率 P(x′1|Ci) , P(x′2|Ci) ,……, P(x′n|Ci) 可以由训练样本估值。
如果 Ak 是离散属性,则 P(x′k|Ci)=sik/si ,其中 sik 是在属性 Ak 上具有值 x′k 的类 Ci 的训练样本数,而 si 是 Ci 中的训练样本数。如果 Ak 是连续值属性,则通常假定该属性服从高斯分布。因而,
其中 g(x′k,μi,σi) 是高斯分布函数, μi 、 σi 分别是类 Ci 样本的平均值和标准差。
5. 对未知样本 x′ 分类,也就是对每个类 Ci ,计算 P(x′|Ci)∗P(Ci) 。样本 x′ 被指派到类 Ci ,当且仅当 P(Ci|x′)>P(Cj|x′) , 1≤j≤m , j≠i ,换言之, x′ 被指派到其 P(x′|Ci)∗P(Ci) 最大的类。
三、算法举例
数据样本用属性age,income,student和credit_rating描述。类标号属性buys_computer具有两个不同值(即{yes,no})。设 C1 对应于类buys_computer=”yes”,而 C2 对应于类buys_computer=”no”。我们希望分类的未知样本为: x′ =(age=”<=30”,income=”medium”,student=”yes”,credit_rating=”fair”)。
| age | income | studen | credit_rating | buy_computer |
|---|---|---|---|---|
| <=30 | High | No | Fair | No |
| <=30 | High | No | Excellent | No |
| 31~40 | High | No | Fair | Yes |
| > 40 | Medium | No | Fair | Yes |
| >40 | Low | Yes | Fair | Yes |
| > 40 | Low | Yes | Excellent | No |
| 31~40 | Low | Yes | Excellent | Yes |
| <=30 | Medium | No | Fair | No |
| <=30 | Low | Yes | Fair | Yes |
| >40 | Medium | Yes | Fair | Yes |
| <=30 | Medium | Yes | Excellent | Yes |
| 31~40 | Medium | No | Excellent | Yes |
| 31~40 | High | Yes | Fair | Yes |
| > 40 | Medium | No | Excellent | No |
(1) 为了正确分类样本x′=(age=”<=30”,income=”medium”,student=”yes”,credit_rating=”fair”),需要最大化 P(x′|Ci)∗P(Ci) , i=1,2 。每个类的先验概率 P(Ci) 可以根据训练样本计算:
P(buys_computer=”yes”)=9/14=0.643,
P(buys_computer=”no”)=5/14=0.357。
(2) 为得到 P(x′|Ci) , i=1,2 ,需计算下面的条件概率:
P(age<=30|buys_computer=”yes”)=2/9=0.222,
P(age<=30|buys_computer=”no”)=3/5=0.600,
P(income=”medium”|buys_computer=”yes”)=4/9=0.444,
P(income=”medium”|buys_computer=”no”)=2/5=0.400,
P(student=”yes”|buys_computer=”yes” )=6/9=0.677,
P(student=”yes”|buys_computer=”no”)=1/5=0.200,
P(credit_rating=”fair”|buys_computer=”yes”)=6/9=0.667,
P(credit_rating=”fair”|buys_computer=”no”)=2/5=0.400。
(3) 假设条件独立性,使用以上概率,我们得到:
P( x′ |buys_computer=”yes” )=0.222*0.444*0.667*0.667=0.044,
P( x′ |buys_computer=”no”)=0.600*0.400*0.200*0.400=0.019,
P( x′ |buys_computer=”yes” )*P(buys_computer=”yes” )= 0.044*0.643=0.028
P( x′ |buys_computer=”no” )*P(buys_computer=”no” )=0.019*0.357=0.007。
因此,对于样本 x′ ,朴素贝叶斯分类预测buys_computer=”yes”。
四、算法的优缺点
1. 优点:算法基于贝叶斯法则,相对容易构建和理解。并且判断效率较快,能比许多其他分类算法更快地预测类。对于相互独立假设不成立的训练样本集,一般也有较好的效果。使用小数据集也可以容易地训练数据。
2. 缺点:偶尔会遇见”零条件概率问题”:如果给定没有出现过的类和特征,则该类别的条件概率估计将出现为0。这会影响到后验概率的计算结果,使分类产生偏差。有几个样本校正技术可以解决这个问题,如“拉普拉斯校正”。另外是它的特征之间独立的假设非常强,在现实生活中几乎不可能找到这样的数据集。
五、算法实战-Python语言
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 为了看模型在没有见过数据集上的表现,随机拿出数据集中30%的部分做测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
gnb = GaussianNB().fit(X_train, y_train)
y_pred = gnb.predict(X_test)
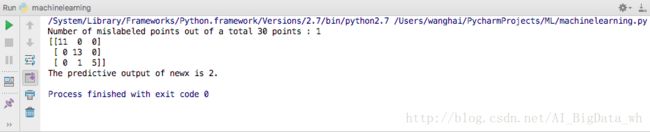
print "Number of mislabeled points out of a total %d points : %d" % (X_test.shape[0],(y_test != y_pred).sum())
print confusion_matrix(y_test,y_pred)
newx = [[4.5,3.0,2.0,3.6]]
newy_pred = gnb.predict(newx)
print "The predictive output of newx is %d." % newy_pred
参考资料
- http://blog.csdn.net/szuodao/article/details/51743501#朴素贝叶斯nb的优点 不同分类算法的优缺点是什么?
- https://baike.baidu.com/item/贝叶斯公式/9683982 贝叶斯公式
- 算法步骤及案例参考一份PPT,因时间久远,无法确定链接。在此对作者表示感谢。