《SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS》代码详解(Tensorflow版)
paper链接
code链接
目录
-
- 1.文件目录结构
- 2.运行方法、要求
-
- 2.1运行方法
- 2.2.运行要求
- 3. 数据集
- 4.代码分析
-
- 4.1requirements.txt
- 4.2setup.py
- 4.3__init__.py
- 4.4train.py
- 4.5model.py
- 4.6layer.py
- 4.7inits.py
- 4.8metrics.py
- 4.9自用测试
- 5.参考
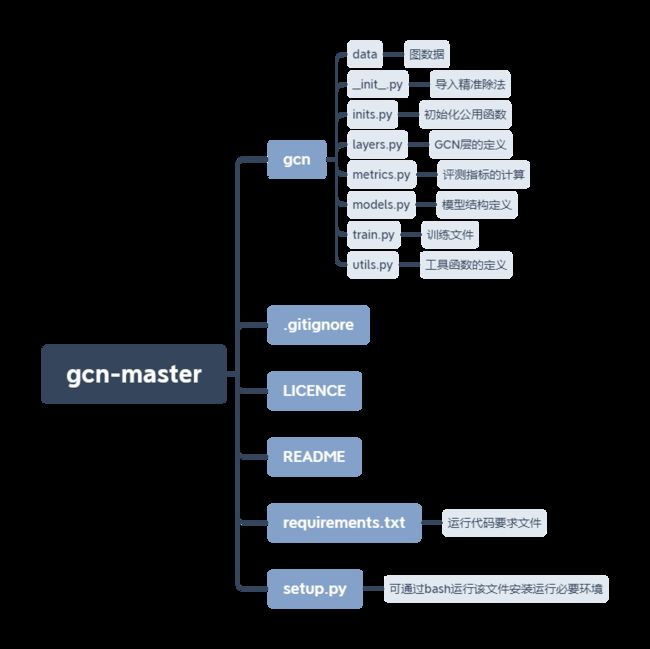
1.文件目录结构
2.运行方法、要求
2.1运行方法
cd gcn
python train.py --model gcn --dataset citeseer
模型选择:
- gcn: Graph convolutional network
- gcn_cheby: Chebyshev polynomial version of graph convolutional network
- dense: Basic multi-layer perceptron that supports sparse inputs
2.2.运行要求
- ‘numpy>=1.15.4’, ‘tensorflow>=1.15.2,<2.0’,
- ‘networkx>=2.2’,
- ‘scipy>=1.1.0’
- setuptools==40.6.3
可通过bash运行setup.py 安装运行必要的包版本。
python setup.py install
3. 数据集
LIL(Row-Based Linked List Format)-基于行的链表格式
载入数据的维度(以Cora数据集为例)
metrics.py
inits.py
从gcn/data文件夹下读取数据,文件包括有:
ind.dataset_str.x => 训练实例的特征向量,如scipy.sparse.csr.csr_matrix类的实例
ind.dataset_str.tx => 测试实例的特征向量,如scipy.sparse.csr.csr_matrix类的实例
ind.dataset_str.allx => 有标签的+无无标签训练实例的特征向量,是ind.dataset_str.x的超集
ind.dataset_str.y => 训练实例的标签,独热编码,numpy.ndarray类的实例
ind.dataset_str.ty => 测试实例的标签,独热编码,numpy.ndarray类的实例
ind.dataset_str.ally => 有标签的+无无标签训练实例的标签,独热编码,numpy.ndarray类的实例
ind.dataset_str.graph => 图数据,collections.defaultdict类的实例,格式为 {index:[index_of_neighbor_nodes]}
ind.dataset_str.test.index => 测试实例的id
载入数据的维度(以Cora数据集为例)
adj(邻接矩阵):由于比较稀疏,邻接矩阵格式是LIL的,并且shape为(2708, 2708)
features(特征矩阵):每个节点的特征向量也是稀疏的,也用LIL格式存储,features.shape: (2708, 1433)
labels:ally, ty数据集叠加构成,labels.shape:(2708, 7)
train_mask, val_mask, test_mask:shaped都为(2708, )的向量,但是train_mask中的[0,140)范围的是True,其余是False;val_mask中范围为(140, 640]范围为True,其余的是False;test_mask中范围为[1708,2707]范围是True,其余的是False
y_train, y_val, y_test:shape都是(2708, 7) 。y_train的值为对应与labels中train_mask为True的行,其余全是0;y_val的值为对应与labels中val_mask为True的行,其余全是0;y_test的值为对应与labels中test_mask为True的行,其余全是0
特征矩阵进行归一化并返回一个格式为(coords, values, shape)的元组
将邻接矩阵加上自环以后,对称归一化,并存储为COO模式,最后返回格式为(coords, values, shape)的元组
总共2708个节点,但是训练数据仅用了140个,范围是(0, 140),验证集用了500个,范围是(140, 640],测试集用了1000个,范围是[1708,2707],其余范围从[641,1707]的数据集呢
4.代码分析
4.1requirements.txt
networkx==2.2
scipy==1.1.0
setuptools==40.6.3
numpy==1.15.4
tensorflow==1.15.2
4.2setup.py
from setuptools import setup
from setuptools import find_packages
setup(name='gcn',
version='1.0',
description='Graph Convolutional Networks in Tensorflow',
author='Thomas Kipf',
author_email='[email protected]',
url='https://tkipf.github.io',
download_url='https://github.com/tkipf/gcn',
license='MIT',
install_requires=['numpy>=1.15.4',
'tensorflow>=1.15.2,<2.0',
'networkx>=2.2',
'scipy>=1.1.0'
],
package_data={'gcn': ['README.md']},
packages=find_packages())
4.3__init__.py
from __future__ import division
#即使在python2.X,使用print就得像python3.X那样加括号使用。
from __future__ import print_function
# 导入python未来支持的语言特征division(精确除法),
# 当我们没有在程序中导入该特征时,"/"操作符执行的是截断除法(Truncating Division);
# 当我们导入精确除法之后,"/"执行的是精确除法, "//"执行截断除除法
4.4train.py
from __future__ import division
'''即使在python2.X,使用print就得像python3.X那样加括号使用'''
from __future__ import print_function
'''导入python未来支持的语言特征division(精确除法),
6 # 当我们没有在程序中导入该特征时,"/"操作符执行的是截断除法(Truncating Division);
7 # 当我们导入精确除法之后,"/"执行的是精确除法, "//"执行截断除除法'''
import time #导入time模块
import tensorflow as tf #导入TensorFlow
from gcn.utils import * #导入GCN工具函数
from gcn.models import GCN, MLP #导入GCN模型
# Set random seed
seed = 123#random是一个算法,设置随机数种子,再不同设备上生成的随机数一样。
np.random.seed(seed)
tf.set_random_seed(seed)
# Settings
"""# 构造了一个解析器FLAGS 这样就可以从命令行中传入数据,从外部定义参数,如python train.py --model gcn
flags.DEFINE_float(参数1,参数2,参数3)
flags.DEFINE_integer(参数1,参数2,参数3)
flags.DEFINE_string(参数1,参数2,参数3)
flags.DEFINE_boolean(参数1,参数2,参数3)
参数1:定义的参数名称;
参数2:参数默认值;
参数3:对参数的描述
"""
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('dataset', 'cora', 'Dataset string.') # 'cora', 'citeseer', 'pubmed'
flags.DEFINE_string('model', 'gcn', 'Model string.') # 'gcn', 'gcn_cheby', 'dense'
flags.DEFINE_float('learning_rate', 0.01, 'Initial learning rate.')
flags.DEFINE_integer('epochs', 200, 'Number of epochs to train.')
#输出维度为16
flags.DEFINE_integer('hidden1', 16, 'Number of units in hidden layer 1.')
#dropout率 避免过拟合(按照一定的概率随机丢弃一部分神经元)
flags.DEFINE_float('dropout', 0.5, 'Dropout rate (1 - keep probability).')
#权衰减 目的就是为了让权重减少到更小的值,在一定程度上减少模型过拟合的问题
# loss计算方式(权值衰减+正则化):self.loss += FLAGS.weight_decay * tf.nn.l2_loss(var)
flags.DEFINE_float('weight_decay', 5e-4, 'Weight for L2 loss on embedding matrix.')
flags.DEFINE_integer('early_stopping', 10, 'Tolerance for early stopping (# of epochs).')
#K阶的切比雪夫近似矩阵的参数k
flags.DEFINE_integer('max_degree', 3, 'Maximum Chebyshev polynomial degree.')
# Load data
#print(np.shape(adj))#(2708, 2708)
#print(np.shape(features))#(2708, 1433)
#print(np.shape(y_train))#(2708, 7)
#print(np.shape(y_val))#(2708, 7)
#print(np.shape(y_test))#(2708, 7)
#print(np.shape(train_mask))#(2708,)
#print(np.shape(val_mask))#(2708,)
#prin t(np.shape(test_mask))#(2708,)
# 数据的读取,这个预处理是把训练集(其中一部分带有标签),测试集,标签的位置,对应的掩码训练标签等返回。
adj, features, y_train, y_val, y_test, train_mask, val_mask, test_mask = load_data(FLAGS.dataset)
# Some preprocessing
#预处理特征矩阵:将特征矩阵进行归一化并返回tuple (coords, values, shape)
features = preprocess_features(features)#X 2708 *1433
if FLAGS.model == 'gcn':
support = [preprocess_adj(adj)]# Z = D -1/2( A +IN) D -1/2 2708*2708
num_supports = 1
model_func = GCN
elif FLAGS.model == 'gcn_cheby':
support = chebyshev_polynomials(adj, FLAGS.max_degree)
num_supports = 1 + FLAGS.max_degree
model_func = GCN
elif FLAGS.model == 'dense':
support = [preprocess_adj(adj)] # Not used
num_supports = 1
model_func = MLP
else:
raise ValueError('Invalid argument for model: ' + str(FLAGS.model))
# Define placeholders
placeholders = {
# #由于邻接矩阵是稀疏的,并且用LIL格式表示,因此定义为一个tf.sparse_placeholder(tf.float32),可以节省内存
'support': [tf.sparse_placeholder(tf.float32) for _ in range(num_supports)],
# features也是稀疏矩阵,也用LIL格式表示,因此定义为tf.sparse_placeholder(tf.float32),维度(2708, 1433)
'features': tf.sparse_placeholder(tf.float32, shape=tf.constant(features[2], dtype=tf.int64)),#(2708, 1433)
'labels': tf.placeholder(tf.float32, shape=(None, y_train.shape[1])),#y_train.shape(2708, 7) -> 7
'labels_mask': tf.placeholder(tf.int32),
'dropout': tf.placeholder_with_default(0., shape=()),#可以用作手段来提供值但不直接评估的张量。
'num_features_nonzero': tf.placeholder(tf.int32) # helper variable for sparse dropout
}
# Create model
model = model_func(placeholders, input_dim=features[2][1], logging=True)#features[2][1] = 1433
# Initialize session
sess = tf.Session()
# Define model evaluation function
def evaluate(features, support, labels, mask, placeholders):#evaluate(features, support, y_test, test_mask, placeholders)
t_test = time.time()
feed_dict_val = construct_feed_dict(features, support, labels, mask, placeholders)
outs_val = sess.run([model.loss, model.accuracy], feed_dict=feed_dict_val)
return outs_val[0], outs_val[1], (time.time() - t_test)
# Init variables
sess.run(tf.global_variables_initializer())
cost_val = []
# Train model
for epoch in range(FLAGS.epochs):#epochs = 200
t = time.time()
# Construct feed dictionary
feed_dict = construct_feed_dict(features, support, y_train, train_mask, placeholders)
feed_dict.update({placeholders['dropout']: FLAGS.dropout})#传入的dropout
# Training step
outs = sess.run([model.opt_op, model.loss, model.accuracy], feed_dict=feed_dict)
# Validation
cost, acc, duration = evaluate(features, support, y_val, val_mask, placeholders)
cost_val.append(cost)
# Print results
print("Epoch:", '%04d' % (epoch + 1), "train_loss=", "{:.5f}".format(outs[1]),
"train_acc=", "{:.5f}".format(outs[2]), "val_loss=", "{:.5f}".format(cost),
"val_acc=", "{:.5f}".format(acc), "time=", "{:.5f}".format(time.time() - t))
if epoch > FLAGS.early_stopping and cost_val[-1] > np.mean(cost_val[-(FLAGS.early_stopping+1):-1]):
print("Early stopping...")
break
print("Optimization Finished!")
# Testing
test_cost, test_acc, test_duration = evaluate(features, support, y_test, test_mask, placeholders)
print("Test set results:", "cost=", "{:.5f}".format(test_cost),
"accuracy=", "{:.5f}".format(test_acc), "time=", "{:.5f}".format(test_duration))
4.5model.py
from gcn.layers import *
from gcn.metrics import *
flags = tf.app.flags
FLAGS = flags.FLAGS
class Model(object):
def __init__(self, **kwargs):
allowed_kwargs = {'name', 'logging'}
for kwarg in kwargs.keys():
assert kwarg in allowed_kwargs, 'Invalid keyword argument: ' + kwarg
name = kwargs.get('name')
if not name:
name = self.__class__.__name__.lower()
self.name = name
logging = kwargs.get('logging', False)
self.logging = logging
self.vars = {}
self.placeholders = {}
self.layers = []
self.activations = []
self.inputs = None
self.outputs = None
self.loss = 0
self.accuracy = 0
self.optimizer = None
self.opt_op = None
# 定义私有方法,只能被类中的函数调用,不能在类外单独调用
def _build(self):
raise NotImplementedError
def build(self):
""" Wrapper for _build() """#命名空间 在GCN中
with tf.variable_scope(self.name):
self._build()#调用子类构建网络模型
# Build sequential layer model
self.activations.append(self.inputs)# features X (1211.111 ……1122) [2708 * 1433]
for layer in self.layers:# self.layers = []
hidden = layer(self.activations[-1])
self.activations.append(hidden)#
self.outputs = self.activations[-1]
# Store model variables for easy access
variables = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.name)
self.vars = {var.name: var for var in variables}
# Build metrics
self._loss()
self._accuracy()
self.opt_op = self.optimizer.minimize(self.loss)
def predict(self):
pass
def _loss(self):
raise NotImplementedError
def _accuracy(self):
raise NotImplementedError
def save(self, sess=None):
if not sess:
raise AttributeError("TensorFlow session not provided.")
saver = tf.train.Saver(self.vars)
save_path = saver.save(sess, "tmp/%s.ckpt" % self.name)
print("Model saved in file: %s" % save_path)
def load(self, sess=None):
if not sess:
raise AttributeError("TensorFlow session not provided.")
saver = tf.train.Saver(self.vars)
save_path = "tmp/%s.ckpt" % self.name
saver.restore(sess, save_path)
print("Model restored from file: %s" % save_path)
class MLP(Model):
def __init__(self, placeholders, input_dim, **kwargs):
super(MLP, self).__init__(**kwargs)
self.inputs = placeholders['features']
self.input_dim = input_dim
# self.input_dim = self.inputs.get_shape().as_list()[1] # To be supported in future Tensorflow versions
self.output_dim = placeholders['labels'].get_shape().as_list()[1]
self.placeholders = placeholders
self.optimizer = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)
self.build()
def _loss(self):
# Weight decay loss
for var in self.layers[0].vars.values():
self.loss += FLAGS.weight_decay * tf.nn.l2_loss(var)
# Cross entropy error
self.loss += masked_softmax_cross_entropy(self.outputs, self.placeholders['labels'],
self.placeholders['labels_mask'])
def _accuracy(self):
self.accuracy = masked_accuracy(self.outputs, self.placeholders['labels'],
self.placeholders['labels_mask'])
def _build(self):
self.layers.append(Dense(input_dim=self.input_dim,
output_dim=FLAGS.hidden1,
placeholders=self.placeholders,
act=tf.nn.relu,
dropout=True,
sparse_inputs=True,
logging=self.logging))
self.layers.append(Dense(input_dim=FLAGS.hidden1,
output_dim=self.output_dim,
placeholders=self.placeholders,
act=lambda x: x,
dropout=True,
logging=self.logging))
def predict(self):
return tf.nn.softmax(self.outputs)
class GCN(Model):
def __init__(self, placeholders, input_dim, **kwargs):#placeholders 1433 logging=True
super(GCN, self).__init__(**kwargs)
self.inputs = placeholders['features']#输入 X (1211.111 ……1122) [2708 * 1433]
self.input_dim = input_dim#1433
# self.input_dim = self.inputs.get_shape().as_list()[1] # To be supported in future Tensorflow versions
self.output_dim = placeholders['labels'].get_shape().as_list()[1]#7
self.placeholders = placeholders
self.optimizer = tf.train.AdamOptimizer(learning_rate=FLAGS.learning_rate)#0.01
self.build()
def _loss(self):
# Weight decay loss
for var in self.layers[0].vars.values():
self.loss += FLAGS.weight_decay * tf.nn.l2_loss(var)
# Cross entropy error
self.loss += masked_softmax_cross_entropy(self.outputs, self.placeholders['labels'],
self.placeholders['labels_mask'])
# 计算模型准确度
def _accuracy(self):
self.accuracy = masked_accuracy(self.outputs, self.placeholders['labels'],
self.placeholders['labels_mask'])
def _build(self):
#第一层的输入维度:input_dim=1433
#第一层的输出维度:output_dim=FLAGS.hidden1=16
#第一层的激活函数:relu
self.layers.append(GraphConvolution(input_dim=self.input_dim,#1433
output_dim=FLAGS.hidden1,#16
placeholders=self.placeholders,#传入字典集合
act=tf.nn.relu,#
dropout=True,
sparse_inputs=True,
logging=self.logging))#logging=True
#第二层的输入等于第一层的输出维度:input_dim=FLAGS.hidden1=16
#第二层的输出维度:output_dim=placeholders['labels'].get_shape().as_list()[1]=7
#第二层的激活函数:lambda x: x,即没有加激活函数
self.layers.append(GraphConvolution(input_dim=FLAGS.hidden1,#16
output_dim=self.output_dim,#7
placeholders=self.placeholders,#传入字典集合
act=lambda x: x,
dropout=True,
logging=self.logging))#logging=True
# 模型预测
def predict(self):
return tf.nn.softmax(self.outputs)#返回的tensor每一行和为1
4.6layer.py
from gcn.inits import *
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
# global unique layer ID dictionary for layer name assignment
_LAYER_UIDS = {}
def get_layer_uid(layer_name=''):
"""Helper function, assigns unique layer IDs."""
if layer_name not in _LAYER_UIDS:
_LAYER_UIDS[layer_name] = 1
return 1
else:
_LAYER_UIDS[layer_name] += 1
return _LAYER_UIDS[layer_name]
def sparse_dropout(x, keep_prob, noise_shape):
"""Dropout for sparse tensors."""
random_tensor = keep_prob
random_tensor += tf.random_uniform(noise_shape)
dropout_mask = tf.cast(tf.floor(random_tensor), dtype=tf.bool)
pre_out = tf.sparse_retain(x, dropout_mask)
return pre_out * (1./keep_prob)
def dot(x, y, sparse=False):
"""Wrapper for tf.matmul (sparse vs dense)."""
if sparse:
res = tf.sparse_tensor_dense_matmul(x, y)
else:
res = tf.matmul(x, y)
return res
#根据Layer来建立Model,主要是设置了self.layers 和 self.activations 建立序列模型,
# 还有init中的其他比如loss、accuracy、optimizer、opt_op等。
class Layer(object):
"""Base layer class. Defines basic API for all layer objects.
Implementation inspired by keras (http://keras.io).
# Properties
name: String, defines the variable scope of the layer.
logging: Boolean, switches Tensorflow histogram logging on/off
# Methods
_call(inputs): Defines computation graph of layer
(i.e. takes input, returns output)
__call__(inputs): Wrapper for _call()
_log_vars(): Log all variables
"""
"""基础层类。为所有层对象定义基本API。
受keras(http://keras.io)启发的实现。
#属性
name:字符串,定义图层的变量范围。
logging:布尔值,打开/关闭Tensorflow直方图记录
# 方法
_call(inputs):定义层的计算图
(即接受输入,返回输出)
__call __(输入):_call()的包装
_log_vars():记录所有变量
"""
def __init__(self, **kwargs):#构造方法,该方法在类实例化时会自动调用
allowed_kwargs = {'name', 'logging'}
for kwarg in kwargs.keys():
assert kwarg in allowed_kwargs, 'Invalid keyword argument: ' + kwarg
name = kwargs.get('name')
if not name:
layer = self.__class__.__name__.lower()#返回将字符串中所有大写字符转换为小写后生成的字符串。
name = layer + '_' + str(get_layer_uid(layer))
self.name = name
self.vars = {}
logging = kwargs.get('logging', False)
self.logging = logging
self.sparse_inputs = False
def _call(self, inputs):
return inputs
#__call__ 的作用让 Layer 的实例成为可调用对象;
def __call__(self, inputs):#__私有,外部不可访问(其实也有方法能访问),_代表保护,外部可以访问。
with tf.name_scope(self.name):
if self.logging and not self.sparse_inputs:#打开或关闭TensorFlow直方图日志记录
tf.summary.histogram(self.name + '/inputs', inputs)
outputs = self._call(inputs)
if self.logging:
tf.summary.histogram(self.name + '/outputs', outputs)
return outputs
def _log_vars(self):
for var in self.vars:
tf.summary.histogram(self.name + '/vars/' + var, self.vars[var])#用来显示直方图信息
#根据 Layer 继承得到denseNet
class Dense(Layer):
"""Dense layer."""
def __init__(self, input_dim, output_dim, placeholders, dropout=0., sparse_inputs=False,
act=tf.nn.relu, bias=False, featureless=False, **kwargs):
super(Dense, self).__init__(**kwargs)
if dropout:
self.dropout = placeholders['dropout']
else:
self.dropout = 0.
self.act = act
self.sparse_inputs = sparse_inputs
self.featureless = featureless
self.bias = bias
# helper variable for sparse dropout
self.num_features_nonzero = placeholders['num_features_nonzero']
with tf.variable_scope(self.name + '_vars'):
self.vars['weights'] = glorot([input_dim, output_dim],
name='weights')
if self.bias:
self.vars['bias'] = zeros([output_dim], name='bias')
if self.logging:
self._log_vars()
#重写了_call 函数,其中对稀疏矩阵做 drop_out:sparse_dropout()
def _call(self, inputs):
x = inputs
# dropout
if self.sparse_inputs:
x = sparse_dropout(x, 1-self.dropout, self.num_features_nonzero)
else:
x = tf.nn.dropout(x, 1-self.dropout)
# transform
output = dot(x, self.vars['weights'], sparse=self.sparse_inputs)
# bias
if self.bias:
output += self.vars['bias']
return self.act(output)
#从 Layer 继承下来得到图卷积网络,与denseNet的唯一差别是_call函数和__init__函数(self.support = placeholders['support']的初始化)
class GraphConvolution(Layer):
"""Graph convolution layer."""
def __init__(self, input_dim, output_dim, placeholders, dropout=0.,
sparse_inputs=False, act=tf.nn.relu, bias=False,
featureless=False, **kwargs):# input_dim = 1433,output_dim = 16,placeholders = placeholders,sparse_inputs=True
super(GraphConvolution, self).__init__(**kwargs)
if dropout:
self.dropout = placeholders['dropout']#dropout = true,
else:
self.dropout = 0.
self.act = act#act=tf.nn.relu
self.support = placeholders['support']#D -1/2( A +IN) D -1/2 2708*2708
self.sparse_inputs = sparse_inputs#sparse_inputs=True
self.featureless = featureless#默认
self.bias = bias#默认
# helper variable for sparse dropout
self.num_features_nonzero = placeholders['num_features_nonzero']
# 下面是定义变量,主要是通过调用utils.py中的glorot函数实现
with tf.variable_scope(self.name + '_vars'):
for i in range(len(self.support)):#1
self.vars['weights_' + str(i)] = glorot([input_dim, output_dim],
name='weights_' + str(i))# input_dim = 1433,output_dim = 16
#return tf.Variable(initial, name=name)
if self.bias:#无
self.vars['bias'] = zeros([output_dim], name='bias')
if self.logging:#logging=Trur
self._log_vars()#调用父类 用来显示直方图信息
def _call(self, inputs):
x = inputs
# dropout
if self.sparse_inputs:
x = sparse_dropout(x, 1-self.dropout, self.num_features_nonzero)
else:
x = tf.nn.dropout(x, 1-self.dropout)
# convolve
# convolve 卷积的实现。主要是根据论文中公式Z = \tilde{D}^{-1/2}\tilde{A}^{-1/2}X\theta实现
supports = list()
for i in range(len(self.support)):
if not self.featureless:
pre_sup = dot(x, self.vars['weights_' + str(i)],
sparse=self.sparse_inputs)
else:
pre_sup = self.vars['weights_' + str(i)]
support = dot(self.support[i], pre_sup, sparse=True)
supports.append(support)
output = tf.add_n(supports)
# bias
if self.bias:
output += self.vars['bias']
return self.act(output)
4.7inits.py
import tensorflow as tf
import numpy as np
def uniform(shape, scale=0.05, name=None):
"""Uniform init."""
initial = tf.random_uniform(shape, minval=-scale, maxval=scale, dtype=tf.float32)
return tf.Variable(initial, name=name)
"""glorot初始化方法:它为了保证前向传播和反向传播时每一层的方差一致:在正向传播时,每层的激活值的方差保持不变;在反向传播时,每层的梯度值的方差保持不变。根据每层的输入个数和输出个数来决定参数随机初始化的分布范围,是一个通过该层的输入和输出参数个数得到的分布范围内的均匀分布。"""
#产生一个维度为shape的Tensor,值分布在(-0.005-0.005)之间,且为均匀分布
def glorot(shape, name=None):# input_dim = 1433,output_dim = 16 name = 'weights_' + str(i)
"""Glorot & Bengio (AISTATS 2010) init."""
init_range = np.sqrt(6.0/(shape[0]+shape[1]))#
initial = tf.random_uniform(shape, minval=-init_range, maxval=init_range, dtype=tf.float32)
return tf.Variable(initial, name=name)
def zeros(shape, name=None):
"""All zeros."""
initial = tf.zeros(shape, dtype=tf.float32)
return tf.Variable(initial, name=name)
def ones(shape, name=None):
"""All ones."""
initial = tf.ones(shape, dtype=tf.float32)
return tf.Variable(initial, name=name)
4.8metrics.py
import tensorflow as tf
# 其中 mask 是一个索引向量,值为1表示该位置的标签在训练数据中是给定的;比如100个数据中训练集已知带标签的数据有50个,
# 那么计算损失的时候,loss 乘以的 mask 等于 loss 在未带标签的地方都乘以0没有了,而在带标签的地方损失变成了mask倍;
# 即只对带标签的样本计算损失。
# 注:loss的shape与mask的shape相同,等于样本的数量:(None,),所以 loss *= mask 是向量点乘。
def masked_softmax_cross_entropy(preds, labels, mask):
"""Softmax cross-entropy loss with masking."""
loss = tf.nn.softmax_cross_entropy_with_logits(logits=preds, labels=labels)
mask = tf.cast(mask, dtype=tf.float32)#类型投射,将变成float32
mask /= tf.reduce_mean(mask)
loss *= mask
return tf.reduce_mean(loss)
def masked_accuracy(preds, labels, mask):
"""Accuracy with masking."""
correct_prediction = tf.equal(tf.argmax(preds, 1), tf.argmax(labels, 1))
accuracy_all = tf.cast(correct_prediction, tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
mask /= tf.reduce_mean(mask)
accuracy_all *= mask
return tf.reduce_mean(accuracy_all)
4.9自用测试
```python
from __future__ import division
#'''即使在python2.X,使用print就得像python3.X那样加括号使用'''
from __future__ import print_function
#'''导入python未来支持的语言特征division(精确除法),
6 # 当我们没有在程序中导入该特征时,"/"操作符执行的是截断除法(Truncating Division);
7 # 当我们导入精确除法之后,"/"执行的是精确除法, "//"执行截断除除法'''
import time #导入time模块
import tensorflow as tf #导入TensorFlow
from gcn.utils import * #导入GCN工具函数
from gcn.models import GCN, MLP #导入GCN模型
# Set random seed
seed = 123#random是一个算法,设置随机数种子,再不同设备上生成的随机数一样。
np.random.seed(seed)
tf.set_random_seed(seed)
adj, features, y_train, y_val, y_test, train_mask, val_mask, test_mask = load_data("cora")
print(np.shape(adj))#(2708, 2708)
print(type(adj) ,adj)
(2708, 2708)
(0, 633) 1
(0, 1862) 1
(0, 2582) 1
(1, 2) 1
(1, 652) 1
(1, 654) 1
(2, 1) 1
(2, 332) 1
(2, 1454) 1
(2, 1666) 1
(2, 1986) 1
(3, 2544) 1
(4, 1016) 1
(4, 1256) 1
(4, 1761) 1
(4, 2175) 1
(4, 2176) 1
(2706, 165) 1
(2706, 169) 1
(2706, 1473) 1
(2706, 2707) 1
(2707, 165) 1
(2707, 598) 1
(2707, 1473) 1
(2707, 2706) 1
print(type(features))
print(np.shape(features))#(2708, 1433)
print(features)
(2708, 1433)
(0, 19) 1.0
(0, 81) 1.0
(0, 146) 1.0
(0, 315) 1.0
(0, 774) 1.0
(0, 877) 1.0
(0, 1194) 1.0
(0, 1247) 1.0
(0, 1274) 1.0
(1, 19) 1.0
(1, 88) 1.0
(1, 149) 1.0
(1, 212) 1.0
(1, 233) 1.0
(1, 332) 1.0
(1, 336) 1.0
(1, 359) 1.0
(1, 472) 1.0
(1, 507) 1.0
(1, 548) 1.0
(1, 687) 1.0
(1, 763) 1.0
(1, 808) 1.0
(1, 889) 1.0
(1, 1058) 1.0
(1, 1177) 1.0
(1, 1254) 1.0
(1, 1257) 1.0
(1, 1262) 1.0
(1, 1332) 1.0
(1, 1339) 1.0
(1, 1349) 1.0
(2, 19) 1.0
(2, 89) 1.0
(2, 128) 1.0
(2, 322) 1.0
(2, 381) 1.0
(2, 480) 1.0
(2, 507) 1.0
(2, 551) 1.0
(2, 647) 1.0
(2, 702) 1.0
(2, 715) 1.0
(2, 912) 1.0
(2, 1076) 1.0
(2, 1091) 1.0
(2, 1177) 1.0
(2, 1209) 1.0
(2, 1263) 1.0
(2, 1314) 1.0
(2, 1353) 1.
(576, 137) 1.0
(576, 238) 1.0
(576, 339) 1.0
(576, 456) 1.0
(576, 521) 1.0
(576, 648) 1.0
(576, 660) 1.0
(576, 687) 1.0
(576, 723) 1.0
(576, 749) 1.0
(576, 821) 1.0
(576, 949) 1.0
(576, 1209) 1.0
(576, 1340) 1.0
(576, 1345) 1.0
(576, 1426) 1.0
(577, 25) 1.0
(577, 132) 1.0
(577, 194) 1.0
(577, 365) 1.0
(577, 378) 1.0
(577, 411) 1.0
(577, 434) 1.0
(577, 442) ```python
5.参考
http://51blog.com/?p=8409