OpenVINO使用介绍
接着前面系列博客继续实验,这篇来介绍OpenVINO,主要还是参考官网资料,前面也说过好的东西,官网对其的介绍是很详尽的,我觉得此要比Tensor RT的的官网做的更好,示例sample也很多。
Get Started — OpenVINO™ documentation https://docs.openvino.ai/latest/get_started.html博主此时的电脑软件环境为:
https://docs.openvino.ai/latest/get_started.html博主此时的电脑软件环境为:
Ubuntu 20.04
python3.6.13 (Anaconda)
cuda version: 11.2
cudnn version: cudnn-11.2-linux-x64-v8.1.1.33
因为涉及到模型的转换及训练自己的数据集,博主这边安装OpenVINO Development Tools,后续会在树莓派部署时,尝试下只安装OpenVINO Runtime
一.安装
1.为了不影响之前博主系列博客中的环境配置(之前的也都是在虚拟环境中进行),这里创建了一个名为testOpenVINO的虚拟环境,关于Anaconda下创建虚拟环境的详情可见之前博客
conda create -n testOpenVINO python=3.6
接下来update下pip
![]()
2.执行下如下命令,博主最近前几篇博客中用的是tensorflow2.6.2,为了方便验证一些东西,这里框架就指定tensorflow2和onnx
pip install openvino-dev[tensorflow2,onnx]完毕后,输入mo -h以验证
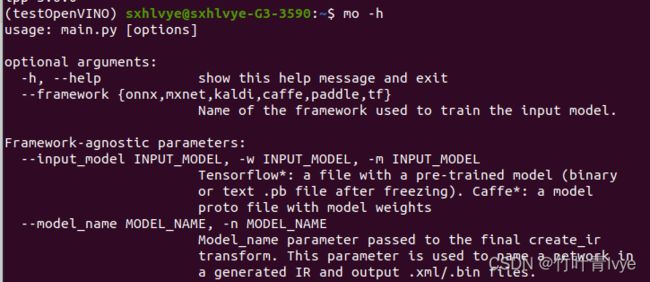
openvino-dev · PyPI 网页里提到的开发工具也都全部安装了
二.用model Optimizer转换tensorflow2模型
Converting a TensorFlow* Model — OpenVINO™ documentation
tensorflow的版本是2.5.2,可以直接将一个预训练模型以save_model方式保存
import tensorflow as tf
import numpy as np
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications import resnet50
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from PIL import Image
import time
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
#加载预训练模型
model = resnet50.ResNet50(weights='imagenet')
#save_model方式保存模型
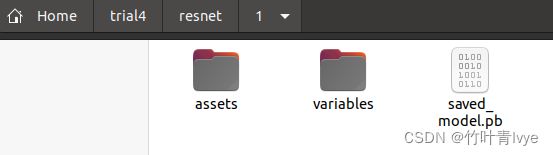
tf.saved_model.save(model, "resnet/1/")
运行后,可看到生成的模型
执行如下命令即可完成模型的转换
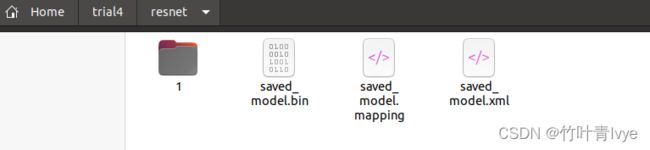
mo --saved_model_dir 1
可看到,生成了3个文件
三.使用OpenVINO在python环境下来完成推断
Integrate OpenVINO™ with Your Application — OpenVINO™ documentation
加载上面转换后的模型,去预测小猫图片

代码如下:
import openvino.runtime as ov
import numpy as np
import time
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications import resnet50
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from PIL import Image
core = ov.Core()
compiled_model = core.compile_model("./resnet/saved_model.xml", "AUTO")
infer_request = compiled_model.create_infer_request()
img = image.load_img('2008_002682.jpg', target_size=(224, 224))
img = image.img_to_array(img)
img = preprocess_input(img)
img = np.expand_dims(img, axis=0)
# Create tensor from external memory
input_tensor = ov.Tensor(array=img, shared_memory=False)
infer_request.set_input_tensor(input_tensor)
t_model = time.perf_counter()
infer_request.start_async()
infer_request.wait()
print(f'do inference cost:{time.perf_counter() - t_model:.8f}s')
# Get output tensor for model with one output
output = infer_request.get_output_tensor()
output_buffer = output.data
# output_buffer[] - accessing output tensor data
print(output_buffer.shape)
print('Predicted:', decode_predictions(output_buffer, top=5)[0])
print("ok")运行结果如下:
/home/sxhlvye/anaconda3/envs/testOpenVINO/bin/python3.6 /home/sxhlvye/trial4/test_inference.py
2022-04-20 12:54:36.780974: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
do inference cost:0.02717873s
(1, 1000)
Predicted: [('n02123597', 'Siamese_cat', 0.16550684), ('n02108915', 'French_bulldog', 0.14137998), ('n04409515', 'tennis_ball', 0.08570903), ('n02095314', 'wire-haired_fox_terrier', 0.052046664), ('n02123045', 'tabby', 0.050695512)]
ok
Process finished with exit code 0
对比未转换前,在tensorflow框架下的预测时间,速度从0.18s提升到了0.027s。
四.c++环境下使用OpenVINO
如果想在c++里使用OpenVINO库,还需要如下的一些配置, 此页面上可以下载OpenVINO的Toolkit
Download Intel® Distribution of OpenVINO™ Toolkithttps://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html选择好符合自己的选项

博主的文件放在了此位置(结合自己的路径)

然后按照官网step-by-setp的进行安装即可
Install and Configure Intel® Distribution of OpenVINO™ Toolkit for Linux — OpenVINO™ documentation

如下界面上可以看到安装的目录
完毕后会出现提示
可看到OpenVINO的安装目录

cd到目录下,再执行如下命令

接下来需要更新下环境变量,编辑./bashrc文件
sudo gedit ~/.bashrc添加语句(结合自己的路径)
source /home/sxhlvye/intel/openvino_2022/setupvars.sh 完毕后别忘了执行 source ~/.bashrc
完毕后别忘了执行 source ~/.bashrc
这样每次新建一个terminal的时候,关于openvino的变量都会自动添加进环境变量里,电脑上若有多版本的openvino,通过修改./bashrc中的setupvars.sh路径,就能方便完成切换了。

opencv这边,博主暂时不安装了,电脑上还保留着之前两篇博客中的opencv环境
TensorRT加速模型推断时间方法介绍(c++ pytorch模型)_竹叶青lvye的博客-CSDN博客
Ubuntu下Qt Creator配置opencv_竹叶青lvye的博客-CSDN博客_ubuntu下qt配置opencv
有了以上环境后,博主在c++环境下加载上面第二步生成的openVINO runtime中间模型Intermediate Representation (IR),这里还是用的QTCreator做的编译器。QTCreator纯c++代码的配置,也可以见博主之前的博客
工程目录结构如下:
main.cpp中的代码如下(不是官网的代码,自己手写),仅供参考:
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
int main()
{
ov::Core core;
ov::CompiledModel compiled_model = core.compile_model("/home/sxhlvye/trial4/resnet/saved_model.xml", "AUTO");
ov::InferRequest infer_request = compiled_model.create_infer_request();
auto input_port = compiled_model.input();
cout << input_port.get_element_type() << std::endl;
std::vector size;
size.push_back(1);
size.push_back(224);
size.push_back(224);
size.push_back(3);
ov::Shape shape(size);
cv::Mat image = cv::imread("/home/sxhlvye/Trial1/Tensorrt/2008_002682.jpg", cv::IMREAD_COLOR);
//cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cout << image.channels() << "," << image.size().width << "," << image.size().height << std::endl;
cv::Mat dst = cv::Mat::zeros(224, 224, CV_32FC3);
cv::resize(image, dst, dst.size());
cout << dst.channels() << "," << dst.size().width << "," << dst.size().height << std::endl;
const int channel = 3;
const int inputH = 244;
const int inputW = 244;
// Read a random digit file
std::vector fileData(inputH * inputW * channel);
/*for (int c = 0; c < channel; ++c)
{
for (int i = 0; i < dst.rows; ++i)
{
cv::Vec3b *p1 = dst.ptr(i);
for (int j = 0; j < dst.cols; ++j)
{
fileData[c * dst.cols * dst.rows + i * dst.cols + j] = p1[j][c] / 255.0f;
}
}
}*/
for (int i = 0; i < dst.rows; ++i)
{
cv::Vec3b *p1 = dst.ptr(i);
for (int j = 0; j < dst.cols; ++j)
{
for(int c = 0; c < 3; ++c)
{
fileData[i*dst.cols*3 + j*3 + c] = p1[j][c] / 255.0f;
}
}
}
ov::Tensor input_tensor(input_port.get_element_type(), shape, fileData.data());
infer_request.set_input_tensor(input_tensor);
clock_t startTime = clock();
infer_request.start_async();
infer_request.wait();
clock_t endTime = clock();
cout << "cost: "<< double(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
// Get output tensor by tensor name
auto output_tensor = infer_request.get_output_tensor();
int outputSize = output_tensor.get_size();
cout << outputSize << std::endl;
const float *output_temp = output_tensor.data();
float output[1000];
for(int i=0;i<1000;i++)
{
output[i] = output_temp[i];
}
// Calculate Softmax
/* float sum{0.0f};
for (int i = 0; i < outputSize; i++)
{
output[i] = exp(output[i]);
sum += output[i];
}
for (int i = 0; i < outputSize; i++)
{
output[i] /= sum;
}*/
vector voutput(1000);
for (int i = 0; i < outputSize; i++)
{
voutput[i] = output[i];
}
for(int i=0; i<1000; i++)
{
for(int j= i+1; j< 1000; j++)
{
if(output[i] < output[j])
{
int temp;
temp = output[i];
output[i] = output[j];
output[j] = temp;
}
}
}
for(int i=0; i<5;i++)
{
cout << output[i] << std::endl;
}
vector labels;
string line;
ifstream readFile("/home/sxhlvye/Trial/yolov3-9.5.0/imagenet_classes.txt");
while (getline(readFile,line))
{
//istringstream record(line);
//string label;
// record >> label;
//cout << line << std::endl;
labels.push_back(line);
}
vector indexs(5);
for(int i=0; i< 1000;i++)
{
if(voutput[i] == output[0])
{
indexs[0] = i;
}
if(voutput[i] == output[1])
{
indexs[1] = i;
}
if(voutput[i] == output[2])
{
indexs[2] = i;
}
if(voutput[i] == output[3])
{
indexs[3] = i;
}
if(voutput[i] == output[4])
{
indexs[4] = i;
}
}
cout << "top 5: " << std::endl;
cout << labels[indexs[0]] << "--->" << output[0] << std::endl;
cout << labels[indexs[1]] << "--->" << output[1] << std::endl;
cout << labels[indexs[2]] << "--->" << output[2] << std::endl;
cout << labels[indexs[3]] << "--->" << output[3] << std::endl;
cout << labels[indexs[4]] << "--->" << output[4] << std::endl;
cout << "ok" << std::endl;
return 0;
}
test8.pro工程配置文件的内容如下:
TEMPLATE = app
CONFIG += console c++11
CONFIG -= app_bundle
CONFIG -= qt
SOURCES += \
main.cpp
INCLUDEPATH += /usr/local/include \
/usr/local/include/opencv \
/usr/local/include/opencv2 \
/home/sxhlvye/intel/openvino_2022/runtime/include \
/home/sxhlvye/intel/openvino_2022/runtime/include/ie \
LIBS += /usr/local/lib/libopencv_highgui.so \
/usr/local/lib/libopencv_core.so \
/usr/local/lib/libopencv_imgproc.so \
/usr/local/lib/libopencv_imgcodecs.so \
/home/sxhlvye/intel/openvino_2022/runtime/lib/intel64/libopenvino.so \
/home/sxhlvye/intel/openvino_2022/runtime/3rdparty/tbb/lib/libtbb.so.2 \
运行完毕后,在终端下运行生成的可执行文件,预测信息如下
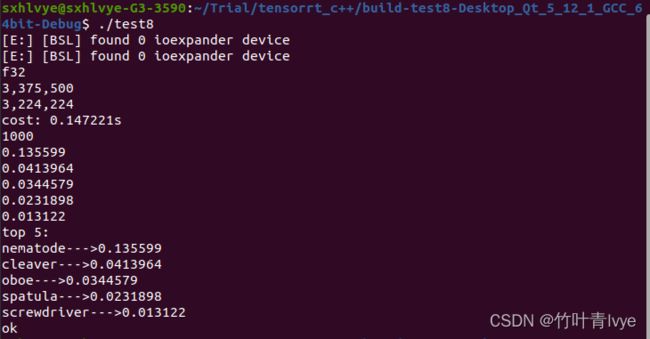
这边一看,和上面第三步中python环境下的预测结果大相径庭,主要是图像预处理这块不一致。
为了验证,博主这边将第三步中python环境的图像预处理和c++下保持一致,也使用opencv库来做处理,修改后的代码如下:
import cv2
import openvino.runtime as ov
import numpy as np
import time
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications import resnet50
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from PIL import Image
core = ov.Core()
compiled_model = core.compile_model("./resnet/saved_model.xml", "AUTO")
infer_request = compiled_model.create_infer_request()
# img = image.load_img('2008_002682.jpg', target_size=(224, 224))
# img = image.img_to_array(img)
# img = preprocess_input(img)
img = cv2.imread('2008_002682.jpg')
img = cv2.resize(img,(224,224))
img_np = np.array(img, dtype=np.float32) / 255.
img_np = np.expand_dims(img_np, axis=0)
print(img_np.shape)
# Create tensor from external memory
input_tensor = ov.Tensor(array=img_np, shared_memory=False)
infer_request.set_input_tensor(input_tensor)
t_model = time.perf_counter()
infer_request.start_async()
infer_request.wait()
print(f'do inference cost:{time.perf_counter() - t_model:.8f}s')
# Get output tensor for model with one output
output = infer_request.get_output_tensor()
output_buffer = output.data
# output_buffer[] - accessing output tensor data
print(output_buffer.shape)
print('Predicted:', decode_predictions(output_buffer, top=5)[0])
print("ok")预测结果如下:
/home/sxhlvye/anaconda3/envs/testOpenVINO/bin/python3.6 /home/sxhlvye/trial4/test_inference.py
2022-04-21 07:59:02.427084: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
[E:] [BSL] found 0 ioexpander device
[E:] [BSL] found 0 ioexpander device
(1, 224, 224, 3)
do inference cost:0.02702089s
(1, 1000)
Predicted: [('n01930112', 'nematode', 0.13559894), ('n03041632', 'cleaver', 0.041396398), ('n03838899', 'oboe', 0.034457874), ('n02783161', 'ballpoint', 0.02541826), ('n04270147', 'spatula', 0.023189805)]
ok
Process finished with exit code 0
可以看到,预处理保持一致后,c++和python两边的结果就保持一致了。
官网上还有很多详细的资料,有时间会再细读,这边只是先跑下流程!
Object Detection Model Tutorial — OpenVINO™ documentation