Python 爬虫实战 - Selenium 爬取 Amazon.com 商品信息 & 对抗广告、推广干扰和反反爬 (Seleium、re、Xpath、openpyxl、列表操作、反反爬)
项目概述
- 爬取目标:爬取亚马逊网 HUAWEI 上架产品的相关信息,并用邮件发送爬取结果给邮箱
- 涉及知识:Seleium、re、Xpath、openpyxl、列表操作
- 完整代码:GitHub - Shawshank-LIUYU/Python3-Crawler-projects
文章目录
# 1. Selenium 信息获取
## 1.1 Selenium 操控浏览器进入信息界面
## 1.2 Xpath 单页信息爬取
### 1.2.1 单个变量的 Xpath
### 1.2.2 爬取一页 - 多个 frame 的爬取并添加到列表中
## 1.3 页面循环爬取模块
### 1.3.1 '下一页' 的不同
# 2. Openpyxl 信息存储
# 3.(重点)反反爬
## 3.0 概述
## 3.1 随机广告弹出
## 3.2 动态商品总数
## 3.3 页面动态加载 - Ajax
## 3.4 多种时间点的反爬
## 3.5 频率限制
# 4. 全部代码
# 5. 结果截图
# 6. 遇到的坑
# 7. 心得 & 展望
# 1. Selenium 信息获取
## 1.1 Selenium 操控浏览器进入信息界面
流程:get 到 Amazon.com,输入 HUAWEI,点击回车,点击 HUAWEI 选项
注意:webdriver 构造函数被重构了,Executable_path 变量不再被支持,全部集成到了 Service 函数里,具体见 文章
s = Service("D:\Software\webdrivers\chromedriver.exe")
driver = webdriver.Chrome(service=s)
driver.get("https://www.amazon.com/")
driver.implicitly_wait(10)
driver.find_element(By.XPATH,"//input[@id='twotabsearchtextbox']").send_keys("huawei")
driver.find_element(By.ID,"nav-search-submit-button").click()
driver.find_element(By.XPATH,"//span[text()='HUAWEI']").click()## 1.2 Xpath 单页信息爬取
难点:三个数据得对应上 —— 因为有些产品都没有评分,如果直接 zip 打包会上错花轿!
思路:先限定在一个框内,然后 框框里 找标题,然后找星,最后找评价数!
流程:Xpath 方式,find_elements 函数,返回需要的节点集 -> 节点.text 取出后添加到列表里
涉及知识点:WebElement 变量自身的 Xpath
### 1.2.1 单个变量的 Xpath
要点:注意 WebElement 变量自身的 Xpath 为 .//
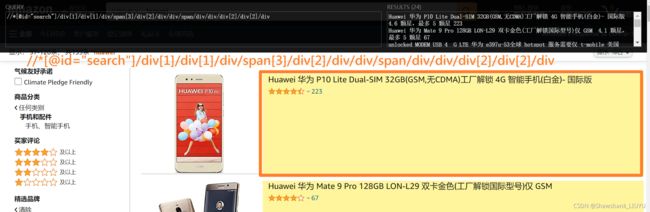
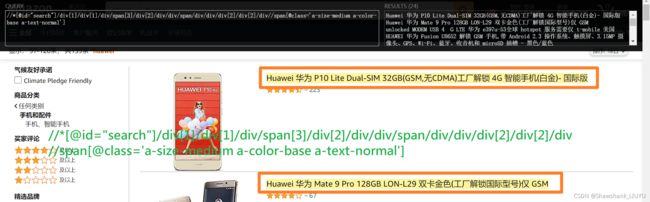


# 框
frames = driver.find_elements(By.XPATH,"//div[contains(@class,'s-include-content-margin')]//div[@class='a-section']")
# 框/名字
ele_huaweiName = frame.find_element(By.XPATH, ".//span[@class='a-size-medium a-color-base a-text-normal']")
# 框/评分
ele_averageScore = frame.find_element(By.XPATH, ".//span[contains(@aria-label,'颗')]")
# 框/评价人数
ele_evaluationNumber = frame.find_element(By.XPATH, ".//div[contains(@class,'a-spacing-top-micro')]//span/a/span")### 1.2.2 爬取一页 - 多个 frame 的爬取并添加到列表中
要点:
- 要将数据不断加入一个数据结构,为了方便打包送入 Excel 中,选择用三个列表 zip 成一个元祖列表 finallist,在送入 Excel 时,用 list(finallist)
- 要排除为空的情况,即 No Score or No number ,则加入一个新的数据结构后跳出循环
代码:
frames = driver.find_elements(By.XPATH,"//div[contains(@class,'s-include-content-margin')]//div[@class='a-section']")
for frame in frames:
ele_huaweiName = frame.find_element(By.XPATH, ".//span[@class='a-size-medium a-color-base a-text-normal']")
huaweiName = ele_huaweiName.text
myNames.append(huaweiName)
try:
ele_averageScore = frame.find_element(By.XPATH, ".//span[contains(@aria-label,'颗')]")
averageScore = ele_averageScore.get_attribute('aria-label')[0:3]
myScores.append(averageScore)
except:
print("No Score or No number:", huaweiName)
continue
try:
ele_evaluationNumber = frame.find_element(By.XPATH, ".//div[contains(@class,'a-spacing-top-micro')]//span/a/span")
evaluationNumber = ele_evaluationNumber.text.replace(',','')
myEvaluations.append(evaluationNumber)
except:
print("No Score or No number:", huaweiName)
continue
print("-"*50)
finalList = zip(myNames, myScores, myEvaluations)
for data in list(finalList):
print(data)效果 (只有一开始的测试版本):
## 1.3 页面循环爬取模块
### 1.3.1 '下一页' 的不同
先观察最后一页和其他页面的不同,发现最后一页的 '下一页' 节点 href 属性里没有 'HUAWEI',但是更简单的是 —— 最后一页的 '下一页' 节点的节点名为 li ,其他则是 a!

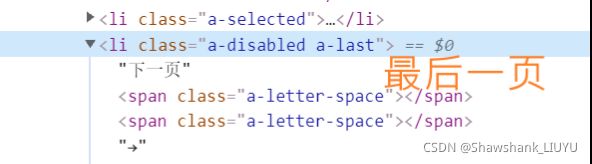
代码( 去除了信息的保存,仅展示翻页的逻辑 ) :
for i in range(100):
try:
# 显示等待 '下一页' 图标出现
wait = WebDriverWait(driver, 5)
nextPageButton = wait.until(EC.presence_of_element_located((By.XPATH,"//a[(contains(text(),'下一页') or contains(text(),'ext'))]")))
nextPageButton.click()
except TimeoutException:
print("找不着了,什么意思,就是没有下一页了!到底了!")
break测试效果:
# 2. Openpyxl 信息存储
# 之前用的是 csv 模块,重点就是列表形式的 writerows,今天尝试一个新的库 —— openpyxl,据说设计丰富,文档便于寻找,而且层次分明,用了之后发现确实如此
分为两个 sheet ,一个是评分及评分人数都是齐全的,一个是有缺失的,分别命名为 'Amazon HUAWEI data' 和 'Info_missing HUAWEI data' ,预计结果如下方表格所示:
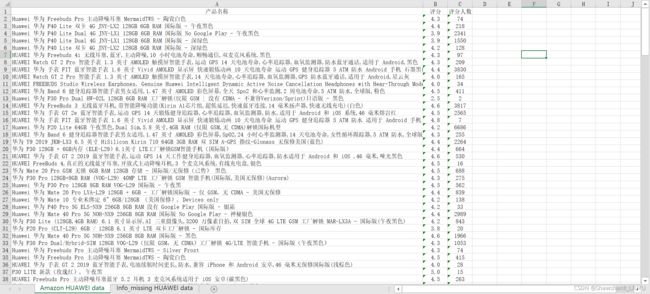
openpyxl 库 的操作比 csv 库 的要精简和明晰很多,只需要记得一行对应 append 的数据结构是个列表就行,代码如下:
wb = Workbook()
wb['Sheet'].title = 'Amazon HUAWEI data'
sh1 = wb.active
sh1.append(['产品名称','评分','评分人数'])
for data in list(finalList):
sh1.append(data)
sh2 = wb.create_sheet()
sh2.title = 'Info_missing HUAWEI data'
sh2.append(['产品名称'])
for name in infoMissNames:
sh2.append(name)
wb.save("FinalRecords.xlsx")# 3.(重点)反反爬
## 3.0 概述
没有 “ 多IP ” , “ 多线程 ” ,因为我还没有学到。只是一些对 Amazon.com 的反爬方式做了一些应对,在最终频率限制的问题上,我只能用 time.sleep(60) 来解决,但是解决其他的反爬措施
- 一开始页数只显示 9 页,全部的商品的数额是前几页的商品数量总和,到达一定页数之前不会改掉这个页数和数量,可以反掉一些一开始设初值为 9 的爬虫;
- 在进入界面的过程中,会随机广告弹出,需要将鼠标悬停在广告后再悬停到主体才能访问主体里的节点,会在爬虫找不到'下一页'的时候让爬虫误以为已经到最后一页了;
- 动态修改商品总数,数值会变大也会变小,因此若是爬虫根据这个值变化判定就是进入反爬界面了,就会随机暂停,达成反爬的目的;
- 有时候会有网页推广,推广的 Xpath 和商品的 Xpath 很像,需要排除掉推广,也正因为推广的存在,商品总数值会上下浮动 1或者 2,和 3 的问题相似;
- Ajax 动态加载,当页面没有滚动到一定高度时,不显示元素,即找不到 '下一页' 的节点;
- 反爬措施可能出现在多种时间点:点击下一页时,或是点击下一页下一页界面出现很短时间直接变成反爬界面,因此需要在代码中涵盖多种情况;
- 频率限制
## 3.1 随机广告弹出

反爬:广告弹出,页面元素消失,找不到想要的 WebElement
解决:页面滚动可以解决一部分,解决不了的鼠标悬停两次即可
代码:
# 若 '下一页' 图标能点击,则点击,不能则说明出问题,退出循环
if nextPageButton.is_enabled():
try:
nextPageButton.click()
except ElementClickInterceptedException:
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(random.random())
driver.execute_script('window.scrollTo({top: 6000, behavior: "smooth" });')
time.sleep(random.random())
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
nextPageButton.click()
# 鼠标悬停
move_to_ads = driver.find_element(By.XPATH,"//div[@data-a-carousel-options]")
ActionChains(driver).move_to_element(move_to_ads).perform()
move_to_frame = driver.find_element(By.XPATH,"//div[@id = 'search']")
ActionChains(driver).move_to_element(move_to_frame).perform()
else:
print("warning[3]: '下一页'无法点击,可能是 Chrome 浏览器版本的问题.")
break问题:已经设置了 ElementClickInterceptedException 的异常处理,仍旧报这个异常,查了一下可能是 Chrome 版本的问题,这个大概10次测试会出现一次,暂时不处理
## 3.2 动态商品总数
反爬:商品总数随着页面变化,在到达一定页面之后会变多,因为推广产品的原因会随机增减1,在进入反爬界面时会一下变小,因此需要对这个数值采取动态处理
解决:变量 framesCount ,若是有增大则更新 framesCount,若是减小则判断是减小范围是否合理,我的判准是减 3 就要处理,因为页面上的推广最多两个
代码:
- 未开始循环时的初始化
# 先初始化 ele_framesCount = driver.find_element(By.XPATH, "//h1[contains(@class,'s-desktop-toolbar')]//div[contains(@class,'a-spacing-top-small')]/span[1]") framesCount = int(re.findall(r'共(.*?)条',ele_framesCount.text)[0]) # 多打了一个符号!凸(艹皿艹 ) print('一共有 {} 条商品信息.'.format(framesCount)) - 循环中的动态更新以及状态分析
driver.implicitly_wait(3) text_nowFramesCount = driver.find_element(By.XPATH,"//h1[contains(@class,'s-desktop-toolbar')]//div[contains(@class,'a-spacing-top-small')]/span[1]").text nowFramesCount = int(re.findall(r'共(.*?)条', text_nowFramesCount)[0]) print(nowFramesCount) if nowFramesCount > framesCount: framesCount = nowFramesCount print("Warning[1]: 出现反爬措施: 动态修改商品数量为 {}.".format(framesCount)) if nowFramesCount < framesCount-3: print("warning[2]: 出现反爬限制: 爬取频率过高,界面短时间内无法刷新.") print("method: 休息 1min,降低频率后继续爬取") driver.back() driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });') time.sleep(60) driver.find_element(By.XPATH, "//li[@class = 'a-selected']/following-sibling::li[1]").click() # 找弟弟节点 continue
## 3.3 页面动态加载 - Ajax
反爬:没有加载到一定位置,元素不会加载,因此想要的节点也 find 不到
解决:传入 JavaScript 代码,selenium 执行,设定为多个位置,随机暂停,慢慢滚动(smooth)
代码:
driver.execute_script('window.scrollTo({top: 2600, behavior: "smooth" });')
time.sleep(1+random.random()*3)
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(1+random.random()*6)## 3.4 多种时间点的反爬
反爬:点击下一页时,或是点击下一页下一页界面出现很短时间直接变成反爬界面,因此需要在代码中涵盖多种情况;
解决:在循环中的 TimeoutException 也加上判断商品总数的代码判断是否遇到反爬
代码:
except TimeoutException:
# 还有一种情况是中途突变的网页,此时已经过了循环
print("Tips: 找不到可以点击的下一页了... 正在测试是否为反爬...或许我们要成功了!")
driver.implicitly_wait(3)
text_nowFramesCount = driver.find_element(By.XPATH,"//h1[contains(@class,'s-desktop-toolbar')]//div[contains(@class,'a-spacing-top-small')]/span[1]").text
nowFramesCount = int(re.findall(r'共(.*?)条', text_nowFramesCount)[0])
if nowFramesCount < framesCount - 3:
print("Warning[2]: 出现反爬限制: 爬取频率过高,界面短时间内无法刷新.")
print(" - Variation: 商品总量被 robot 修改为 {}".format(nowFramesCount))
print("Method: 休息 1min,降低频率后继续爬取")
driver.back()
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(60)
driver.find_element(By.XPATH, "//li[@class = 'a-selected']/following-sibling::li[1]").click()
continue
else:
# print("找不到属性为a的'下一页'了 —— 爬取完毕")
print("Success!!!")
overFlag = True
break## 3.5 频率限制
概述:如题,这无疑是最蛋疼的,除了等就是分IP,但是多IP我还不会,所以直接等待60s了
代码:
if nowFramesCount < framesCount-3:
print("warning[2]: 出现反爬限制: 爬取频率过高,界面短时间内无法刷新.")
print("method: 休息 1min,降低频率后继续爬取")
driver.back()
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(60)
driver.find_element(By.XPATH, "//li[@class = 'a-selected']/following-sibling::li[1]").click()
continue# 4. 全部代码
# -*- coding = utf-8 -*-
# @Time : 2021/10/18 15:12
# @Author : LIUYU
# @File : TestFindNextPageButton.py
# @Software : PyCharm
import random
import re
import time
from openpyxl import Workbook
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, ElementClickInterceptedException
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
s = Service("D:\Software\webdrivers\chromedriver.exe")
driver = webdriver.Chrome(service=s)
driver.get("https://www.amazon.com/")
driver.implicitly_wait(10)
driver.find_element(By.XPATH,"//input[@id='twotabsearchtextbox']").send_keys("huawei")
driver.find_element(By.ID,"nav-search-submit-button").click()
driver.find_element(By.XPATH,"//span[text()='HUAWEI']").click()
ele_framesCount = driver.find_element(By.XPATH,
"//h1[contains(@class,'s-desktop-toolbar')]//div[contains(@class,'a-spacing-top-small')]/span[1]")
framesCount = int(re.findall(r'共(.*?)条',ele_framesCount.text)[0])
print('一共有 {} 条商品信息.'.format(framesCount))
myNames = []
myScores = []
myEvaluations = []
infoMissNames = []
overFlag = False
for i in range(100):
if overFlag:
break
driver.implicitly_wait(3)
text_nowFramesCount = driver.find_element(By.XPATH,"//h1[contains(@class,'s-desktop-toolbar')]//div[contains(@class,'a-spacing-top-small')]/span[1]").text
nowFramesCount = int(re.findall(r'共(.*?)条', text_nowFramesCount)[0])
print(nowFramesCount)
if nowFramesCount > framesCount:
framesCount = nowFramesCount
print("Warning[1]: 出现反爬措施: 动态修改商品数量为 {}.".format(framesCount))
if nowFramesCount < framesCount-3:
print("warning[2]: 出现反爬限制: 爬取频率过高,界面短时间内无法刷新.")
print("method: 休息 1min,降低频率后继续爬取")
driver.back()
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(60)
driver.find_element(By.XPATH, "//li[@class = 'a-selected']/following-sibling::li[1]").click()
continue
# 滚动暂停,骗过浏览器 Ajax 加载以及检测
driver.execute_script('window.scrollTo({top: 2600, behavior: "smooth" });')
time.sleep(1+random.random()*3)
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(1+random.random()*6)
frames = driver.find_elements(By.XPATH,"//div[contains(@class,'s-include-content-margin')]//div[@class='a-section']")
for frame in frames:
ele_huaweiName = frame.find_element(By.XPATH, ".//span[@class='a-size-medium a-color-base a-text-normal']")
huaweiName = ele_huaweiName.text
myNames.append(huaweiName)
try:
# ele_averageScore = frame.find_element(By.XPATH, ".//a/i/span")
ele_averageScore = frame.find_element(By.XPATH, ".//span[contains(@aria-label,'颗')]")
averageScore = ele_averageScore.get_attribute('aria-label')[0:3]
myScores.append(averageScore)
except:
# print("No Score or No number:", huaweiName)
infoMissNames.append([huaweiName])
continue
try:
ele_evaluationNumber = frame.find_element(By.XPATH,".//div[contains(@class,'a-spacing-top-micro')]//span/a/span")
evaluationNumber = ele_evaluationNumber.text.replace(',', '')
myEvaluations.append(evaluationNumber)
except:
# print("No Score or No number:", huaweiName)
infoMissNames.append([huaweiName])
continue
try:
wait = WebDriverWait(driver, 5)
nextPageButton = wait.until(EC.presence_of_element_located((By.XPATH,"//a[(contains(text(),'下一页') or contains(text(),'ext'))]")))
if nextPageButton.is_enabled():
try:
nextPageButton.click()
except ElementClickInterceptedException:
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(random.random())
driver.execute_script('window.scrollTo({top: 6000, behavior: "smooth" });')
time.sleep(random.random())
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
nextPageButton.click()
# 鼠标悬停
move_to_ads = driver.find_element(By.XPATH,"//div[@data-a-carousel-options]")
ActionChains(driver).move_to_element(move_to_ads).perform()
move_to_frame = driver.find_element(By.XPATH,"//div[@id = 'search']")
ActionChains(driver).move_to_element(move_to_frame).perform()
else:
print("warning[3]: '下一页'无法点击,可能是 Chrome 浏览器版本的问题.")
break
except TimeoutException:
# 网页中途突变
print("Tips: 找不到可以点击的下一页了... 正在测试是否为反爬...或许我们要成功了!")
driver.implicitly_wait(3)
text_nowFramesCount = driver.find_element(By.XPATH,"//h1[contains(@class,'s-desktop-toolbar')]//div[contains(@class,'a-spacing-top-small')]/span[1]").text
nowFramesCount = int(re.findall(r'共(.*?)条', text_nowFramesCount)[0])
if nowFramesCount < framesCount - 3:
print("Warning[2]: 出现反爬限制: 爬取频率过高,界面短时间内无法刷新.")
print(" - Variation: 商品总量被 robot 修改为 {}".format(nowFramesCount))
print("Method: 休息 1min,降低频率后继续爬取")
driver.back()
driver.execute_script('window.scrollTo({top: 5200, behavior: "smooth" });')
time.sleep(60)
driver.find_element(By.XPATH, "//li[@class = 'a-selected']/following-sibling::li[1]").click()
continue
else:
# print("爬取完毕")
print("Success!!!")
overFlag = True
break
finalList = zip(myNames,myScores,myEvaluations)
wb = Workbook()
wb['Sheet'].title = 'Amazon HUAWEI data'
sh1 = wb.active
sh1.append(['产品名称','评分','评分人数'])
for data in list(finalList):
sh1.append(data)
sh2 = wb.create_sheet()
sh2.title = 'Info_missing HUAWEI data'
sh2.append(['产品名称'])
for name in infoMissNames:
sh2.append(name)
wb.save("FinalRecords.xlsx")# 5. 结果截图

# 6. 遇到的坑
出于内存优化的考虑,zip 对象只能调用一次。就是说如果你 for item in list(zip(xxx)) 打印了一次,你后面再 for item in list(zip(xxx)) 保存的时候,这个 zip 对象就是空的!是不报错的!
# 7. 心得 & 展望
心得:
在不同模块采用不同的 test 文件然后不断改版,在每个 test 文件的开头注释记录每次改版的内容是一个好的习惯,也方便复盘修改代码的思路,下面是我这次项目的几个源文件.

展望:
这次的项目把之前学到的 xpath、selenium、执行 JavaScript 代码,以及调试的很多知识和技巧都运用上了,是一次对所学技能很好的巩固。
不过整个项目是通过直接把模块衔接起来,可读性不是很好,下次可以把一个功能单独写成一个函数,到时候直接调用即可,也可以做一个思维导图,在做这种总结文章时,大家读起来也会更思路清晰一些。
这个项目的遗憾在于,试了很多种方法,也没办法用一个 IP 绕过 Amazon 的所有反爬 —— 存在频率限制这一大门槛,因此下一步,要尝试采取多个 IP ,多个线程的爬取,到时候也会完善这个代码!同时我也看到了 selenium 的局限,它的速度和体量是相对较小的,在面对大量数据的时候,有时候只能望洋兴叹。
最后感谢所有看到这里的同学们,我刚刚入门,深感爬虫这条路有趣而道阻且长,多多交流,一起进步!
—— 2021.10.20(于自习教室)