cephadm安装ceph
环境
操纵系统及内核版本(最小化安装,不自带python)
[root@node-01 ~]# cat /etc/redhat-release
CentOS Linux release 8.0.1905 (Core)
[root@node-01 ~]# uname -r
4.18.0-80.el8.x86_64
[root@node-01 ~]# uname -a
Linux node-01 4.18.0-80.el8.x86_64 #1 SMP Tue Jun 4 09:19:46 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
ip地址及主机名
192.168.91.133 node-01
192.168.91.134 node-02
192.168.91.135 node-03
前置操作
关闭防火墙及selinux
所有节点都操作
systemctl disable firewalld
systemctl stop firewalld
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
setenforce 0
配置yum源地址
所有节点都操作
注意:如下图Centos8.0(1905)的yum源centos官网已经不再维护,下载cephadm会报错,因此将其改成vault源。
[root@node-01 ~]# cat /etc/yum.repos.d/CentOS-AppStream.repo
# CentOS-AppStream.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[AppStream]
name=CentOS-$releasever - AppStream
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=AppStream&infra=$infra
#baseurl=http://mirror.centos.org/$contentdir/$releasever/AppStream/$basearch/os/
#更改baseurl行
baseurl=http://vault.centos.org/$contentdir/$releasever/AppStream/$basearch/os/
gpgcheck=1
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
[root@node-01 ~]# cat /etc/yum.repos.d/CentOS-Base.repo
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[BaseOS]
name=CentOS-$releasever - Base
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=BaseOS&infra=$infra
#baseurl=http://mirror.centos.org/$contentdir/$releasever/BaseOS/$basearch/os/
#更改baseurl行
baseurl=http://vault.centos.org/$contentdir/$releasever/BaseOS/$basearch/os/
gpgcheck=1
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
dnf clean all
时钟同步
所有节点都操作
安装时钟同步软件
dnf -y install chrony
#开机自启动
systemctl enable chronyd
#启动
systemctl start chronyd
#验证
chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^+ 139.199.214.202 2 6 33 4 +4521us[+4521us] +/- 79ms
^? makaki.miuku.net 0 6 0 - +0ns[ +0ns] +/- 0ns
^- de-user.deepinid.deepin.> 3 6 17 6 +34ms[ +34ms] +/- 164ms
^* time.cloudflare.com 3 6 17 7 +122us[ +21ms] +/- 128ms
安装podman
所有节点都操作
[root@node-01 ~]# dnf -y install podman
报错
invalid literal for int() with base 10
[root@node-01 ~]# cephadm bootstrap --mon-ip 192.168.91.133
Traceback (most recent call last):
File "/usr/sbin/cephadm", line 8571, in <module>
main()
File "/usr/sbin/cephadm", line 8557, in main
check_container_engine(ctx)
File "/usr/sbin/cephadm", line 2014, in check_container_engine
engine.get_version(ctx)
File "/usr/sbin/cephadm", line 197, in get_version
self._version = _parse_podman_version(out)
File "/usr/sbin/cephadm", line 1603, in _parse_podman_version
return tuple(map(to_int, version_str.split('.')))
File "/usr/sbin/cephadm", line 1601, in to_int
return to_int(val[0:-1], org_e or e)
File "/usr/sbin/cephadm", line 1597, in to_int
raise org_e
File "/usr/sbin/cephadm", line 1599, in to_int
return int(val)
ValueError: invalid literal for int() with base 10: ''
解决:
安装podman
安装cephadm
所有节点都操作。
说明:安装这个会顺带把python3也安装上,而后续的操作(比如添加主机)是需要python3环境的,所以就直接执行这个把python3安装了。
dnf install --assumeyes centos-release-ceph-pacific.noarch
dnf install --assumeyes cephadm
引导新集群
修改cephadm脚本
将镜像地址改成下载速度快的地址
cat /usr/sbin/cephadm |head -75
替换后的内容如下
# Default container images -----------------------------------------------------
#DEFAULT_IMAGE = 'quay.io/ceph/ceph:v16'
#DEFAULT_IMAGE_IS_MASTER = False
#DEFAULT_IMAGE_RELEASE = 'pacific'
#DEFAULT_PROMETHEUS_IMAGE = 'quay.io/prometheus/prometheus:v2.18.1'
#DEFAULT_NODE_EXPORTER_IMAGE = 'quay.io/prometheus/node-exporter:v0.18.1'
#DEFAULT_ALERT_MANAGER_IMAGE = 'quay.io/prometheus/alertmanager:v0.20.0'
#DEFAULT_GRAFANA_IMAGE = 'quay.io/ceph/ceph-grafana:6.7.4'
#DEFAULT_HAPROXY_IMAGE = 'docker.io/library/haproxy:2.3'
#DEFAULT_KEEPALIVED_IMAGE = 'docker.io/arcts/keepalived'
#DEFAULT_REGISTRY = 'docker.io' # normalize unqualified digests to this
# ------------------------------------------------------------------------------
# Default container images -----------------------------------------------------
DEFAULT_IMAGE = 'docker.io/ceph/ceph:v16'
DEFAULT_IMAGE_IS_MASTER = False
DEFAULT_IMAGE_RELEASE = 'pacific'
DEFAULT_PROMETHEUS_IMAGE = 'docker.io/bitnami/prometheus:latest'
DEFAULT_NODE_EXPORTER_IMAGE = 'docker.io/bitnami/node-exporter:latest'
DEFAULT_ALERT_MANAGER_IMAGE = 'docker.io/prom/alertmanager:latest'
DEFAULT_GRAFANA_IMAGE = 'docker.io/ceph/ceph-grafana:latest'
DEFAULT_HAPROXY_IMAGE = 'docker.io/library/haproxy:2.3'
DEFAULT_KEEPALIVED_IMAGE = 'docker.io/arcts/keepalived'
DEFAULT_REGISTRY = 'docker.io' # normalize unqualified digests to this
# ------------------------------------------------------------------------------
[root@node-01 ~]# cephadm bootstrap --mon-ip 192.168.91.133
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman (/usr/bin/podman) version 3.3.1 is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 2e99a36a-bfb8-11ec-8fe2-000c29779b64
Verifying IP 192.168.91.133 port 3300 ...
Verifying IP 192.168.91.133 port 6789 ...
Mon IP `192.168.91.133` is in CIDR network `192.168.91.0/24`
- internal network (--cluster-network) has not been provided, OSD replication will default to the public_network
Pulling container image docker.io/ceph/ceph:v16...
Ceph version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network to 192.168.91.0/24
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 9283 ...
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr not available, waiting (4/15)...
mgr not available, waiting (5/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to /etc/ceph/ceph.pub
Adding key to root@localhost authorized_keys...
Adding host node-01...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://node-01:8443/
User: admin
Password: ld8nohjdgd
Enabling client.admin keyring and conf on hosts with "admin" label
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 2e99a36a-bfb8-11ec-8fe2-000c29779b64 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/pacific/mgr/telemetry/
Bootstrap complete.
保存如下信息
Ceph Dashboard is now available at:
URL: https://node-01:8443/
User: admin
Password: ld8nohjdgd
Enabling client.admin keyring and conf on hosts with "admin" label
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 2e99a36a-bfb8-11ec-8fe2-000c29779b64 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/pacific/mgr/telemetry/
Bootstrap complete.
访问ceph的dashboard
注意:用https,否则访问不到。
https://192.168.91.133:8443

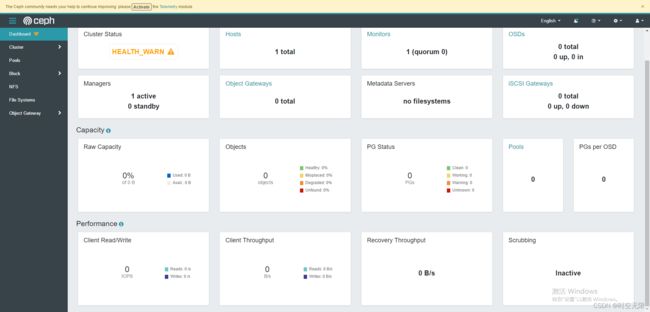
添加主机
登录ceph命令行(关于对ceph的操作都需要先登录ceph的命令行,有免登录的设置,本文未设置)
[root@node-01 ~]# cephadm shell
输出
Inferring fsid 2e99a36a-bfb8-11ec-8fe2-000c29779b64
Using recent ceph image docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb
添加node-01节点
[ceph: root@node-01 /]# ceph orch host add node-01 192.168.91.133
输出
Added host 'node-01' with addr '192.168.91.133'
添加node-02节点
[ceph: root@node-01 /]# ceph orch host add node-02 192.168.91.134
输出
Added host 'node-02' with addr '192.168.91.134'
添加node-03节点
[ceph: root@node-01 /]# ceph orch host add node-03 192.168.91.135
输出
Added host 'node-03' with addr '192.168.91.135'
报错
[ceph: root@node-01 /]# ceph orch host add node-02 192.168.91.134
Error EINVAL: Host node-02 (192.168.91.134) failed check(s): []
原因:该节点没有安装podman或者docker。
[ceph: root@node-01 /]# ceph orch host add node-03 192.168.91.135
Error EINVAL: Can't communicate with remote host `192.168.91.135`, possibly because python3 is not installed there: cannot send (already closed?)
原因:该节点没有安装python3。
解决:
dnf install --assumeyes centos-release-ceph-pacific.noarch
dnf install --assumeyes cephadm
查看可用主机和设备
[ceph: root@node-01 /]# ceph orch host ls
HOST ADDR LABELS STATUS
node-01 192.168.91.133
node-02 192.168.91.134
node-03 192.168.91.135
[ceph: root@node-01 /]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
node-01 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
node-02 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
注意:node-03节点的设备没有显示出来,而node-03节点实际是有可用设备的。为什么?
node-03节点相关的容器没有启动。
等node-03节点相关容器启动再次查看
[ceph: root@node-01 /]# ceph orch host ls
HOST ADDR LABELS STATUS
node-01 192.168.91.133
node-02 192.168.91.134
node-03 192.168.91.135
[ceph: root@node-01 /]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
node-01 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
node-02 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
node-03 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
各个主机目前启动的容器
[root@node-01 ~]# podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a620ac0a433a docker.io/ceph/ceph:v16 -n mon.node-01 -f... 22 hours ago Up 22 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-mon-node-01
5fbcb8b47e20 docker.io/ceph/ceph:v16 -n mgr.node-01.vk... 22 hours ago Up 22 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-mgr-node-01-vkduxo
8e15dc167b28 docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n client.crash.n... 22 hours ago Up 22 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-crash.node-01
5a39b8488648 docker.io/prom/node-exporter:v0.18.1 --no-collector.ti... 22 hours ago Up 22 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-node-exporter.node-01
dc95861f41f8 docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb 21 hours ago Up 21 hours ago romantic_varahamihira
7f35cdb22c80 docker.io/prom/alertmanager:v0.20.0 --cluster.listen-... 19 hours ago Up 19 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-alertmanager.node-01
82a2ec351349 docker.io/prom/prometheus:v2.18.1 --config.file=/et... 2 hours ago Up 2 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-prometheus.node-01
[root@node-02 ~]# podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a333d817326f docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n client.crash.n... 19 hours ago Up 19 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-crash.node-02
a3dfbe105d18 docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n mgr.node-02.kn... 19 hours ago Up 19 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-mgr.node-02.knnehw
0deab1a1d01e docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n mon.node-02 -f... 19 hours ago Up 19 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-mon.node-02
ddd55502e17b docker.io/prom/node-exporter:v0.18.1 --no-collector.ti... 19 hours ago Up 19 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-node-exporter.node-02
[root@node-03 ~]# podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
47ba78c7a826 docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n client.crash.n... 2 hours ago Up 2 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-crash.node-03
008e3dc211a3 docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n mon.node-03 -f... 2 hours ago Up 2 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-mon.node-03
24166557cea6 docker.io/prom/node-exporter:v0.18.1 --no-collector.ti... 2 hours ago Up 2 hours ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-node-exporter.node-03
cc53a5de5faf docker.io/ceph/ceph@sha256:829ebf54704f2d827de00913b171e5da741aad9b53c1f35ad59251524790eceb -n osd.0 -f --set... 10 minutes ago Up 10 minutes ago ceph-2e99a36a-bfb8-11ec-8fe2-000c29779b64-osd.0
创建osds
创建osd有两种方法,本文采用的是第一种。
方法一:告诉ceph使用一切可用和未使用的设备
[ceph: root@node-01 /]# ceph orch apply osd --all-available-devices
输出
Scheduled osd.all-available-devices update...
方法二:从特定主机的特定设备创建osd
[ceph: root@node-01 /]# ceph orch daemon add osd node-01:/dev/sdb
输出(因为已经用第一种方法从node-01:/dev/sdb创建好了osd,所以会输出这个提示)
Created no osd(s) on host node-01; already created?
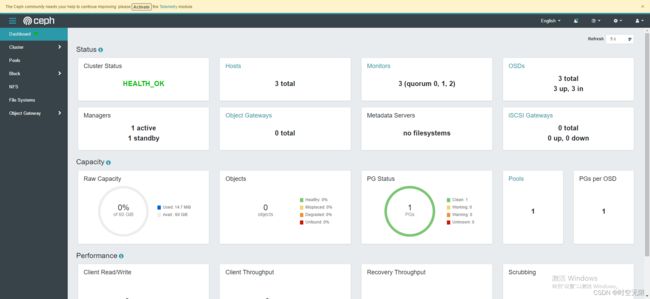
验证集群状态
说明:到目前为止集群状态就已经正常了。
ceph命令行验证
[ceph: root@node-01 /]# ceph -s
cluster:
id: 2e99a36a-bfb8-11ec-8fe2-000c29779b64
health: HEALTH_OK
services:
mon: 3 daemons, quorum node-01,node-02,node-03 (age 2h)
mgr: node-01.vkduxo(active, since 22h), standbys: node-02.knnehw
osd: 3 osds: 3 up (since 7m), 3 in (since 7m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 15 MiB used, 60 GiB / 60 GiB avail
pgs: 1 active+clean
web界面验证