可以用于云原生中Skywalking框架原理你真的懂吗
可以用于云原生中Skywalking框架原理你真的懂吗
- ✨博主介绍
- 全链路监控
-
- 什么是全链路监控,为什么我们需要全链路监控?
- OpenTracing
-
- OpenTracing定位
- OpenTracing重要概念
- OpenTracing API相关概念
- OpenTelemetry
- 全链路监控考虑因素
- 为什么不用Istio做追踪?
- 字节码增强
-
- 字节码和Java类加载机制
- 运行时类的重载
-
- 代码AOP
- 静态重写
- 动态重载
- 字节码增强
- Skywalking实现
-
- skywalking整体架构
- 追踪实现原理
-
- Agent和Plugin
- TraceSegment设计
- TraceId设计
- 请求采样设计
- 数据收集和消费(轻量级队列内核)
- 性能剖析实现原理
- 点击直接资料领取
✨博主介绍
作者主页:苏州程序大白
作者简介:CSDN人工智能域优质创作者,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
如果文章对你有帮助,欢迎关注、点赞、收藏
有任何问题欢迎私信,看到会及时回复
关注苏州程序大白,分享粉丝福利
全链路监控
什么是全链路监控,为什么我们需要全链路监控?
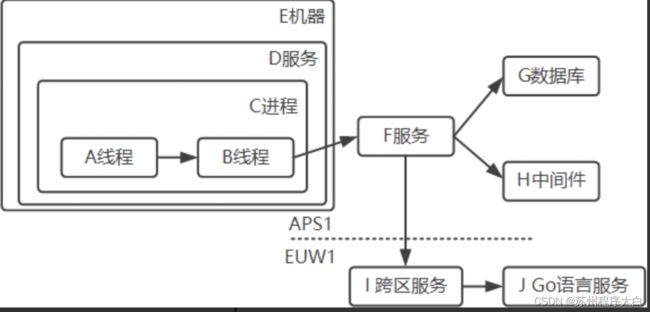
1、全链路监控:对请求源头到底层服务的调用链路中间的所有环节进行监控。
2、为什么需要:对于单体应用,我们可以很容易地监控和分析它的性能。对于微服务,编程语言不同、服务器数量庞大、可能跨多个服务/区域,那么面对复杂的请求调用链路,就会有一系列问题,只有全链路监控才能处理,例如:
- 如何快速发现有问题的服务?
- 如何判断故障影响范围?
- 如何梳理服务间依赖关系?
- 如何分析链路性能问题?
- 对于一次慢请求,如何找到慢请求的来源?
3、和其他监控组件的定位区别:
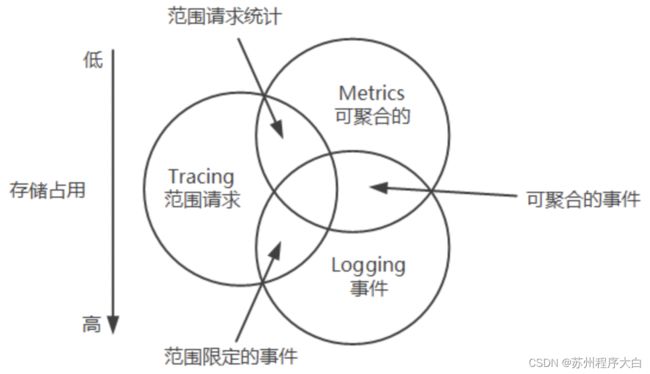
监控、追踪和日志是可观测性(observability)的基石:
-
和日志监控Logs区别:日志监控侧重于单个业务的代码bug分析。虽然利用MDC可以追踪一个请求,但不能追踪跨线程、跨服务、跨区的情况,且对中间件、数据库的请求无法追踪,当然也可以手动传递MDC,本质上也就是实现了全链路监控的追踪功能。
-
和Prometheus监控Metrics区别:Prometheus监控侧重于报警和业务指标监控。对于接口间的延迟等不能很好地处理,当然也可以在接口出入口计时,本质上也就是实现了一个全链路监控的性能分析功能。
MDC:Mapped Diagnostic Context,映射调试上下文,log4j 和 logback 提供的一种方便在多线程条件下记录日志的功能。
OpenTracing
OpenTracing定位
微服务架构普及,分布式追踪系统大量涌现,但API互不兼容,难以整合和切换,因此OpenTracing提出了统一的平台无关、厂商无关的API,不同的分布式追踪系统去实现。这种作用与“JDBC”类似。

OpenTracing是一个轻量级的标准化层,位于“应用程序/类库”和“日志/追踪程序”之间。
应用程序/类库层示例:开发者在开发应用代码想要加入追踪数据、ORM类库想要加入ORM和SQL的关系、HTTP负载均衡器使用OpenTracing标准来设置请求、跨进程的任务(gRPC等)使用OpenTracing的标准格式注入追踪数据。所有这些,都只需要对接OpenTracing API,而无需关心后面的追踪、监控、日志等如何采集和实现。
OpenTracing重要概念
场景:购买资源
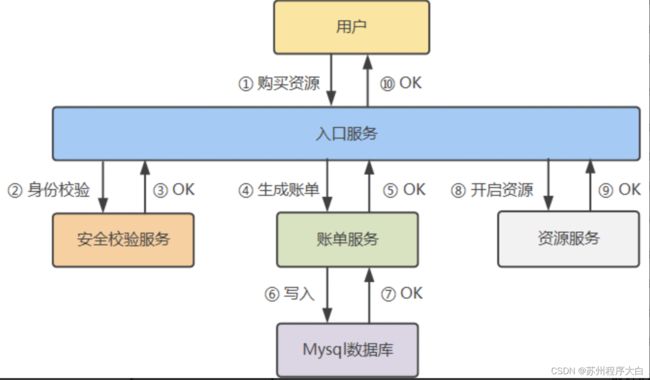
Span(跨度)指代系统中具有“操作名称”、“开始时间”和“执行时长”的逻辑运行单元。
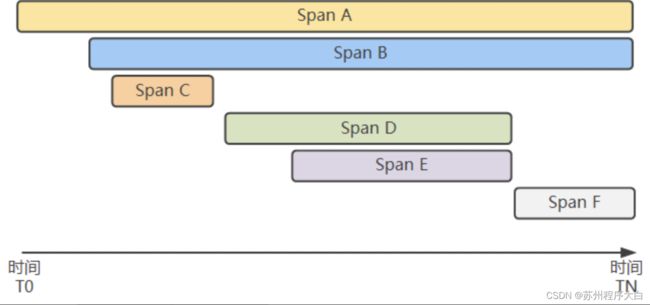
Trace(追踪)指代一个分布式的、可能存在并行数据和轨迹的系统,直观上看就是一次请求在分布式系统中行进的生命周期,本质上是多个span组成的有向无环图(DAG)。

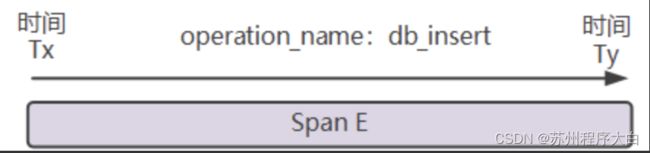
Operation Names(操作名称):每个span都有一个操作名称,操作名称应该是一个抽象的、通用的标识,具备统计意义的名称。以数据库插入动作为例:
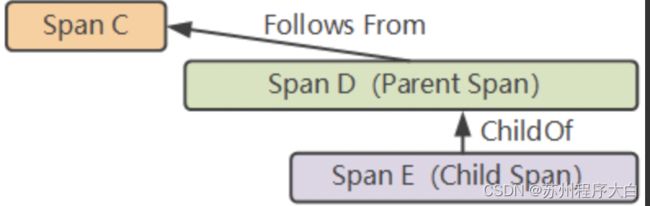
Inter-Span References(内部跨度引用关系):1个span可以和1个或多个span存在因果关系,目前只支持父子节点之间的直接因果关系ChildOf和FollowsFrom。
-
ChildOf:父span依赖子span,如RPC调用服务器和客户端、ORM的save和mysql的insert、countdownlatch。
-
Follows From:父span不以任何形式依赖子span结果。
示例:(ChildOf是官方示例,Follows From的示例不太确定,是个人理解,如有想法欢迎指正)。
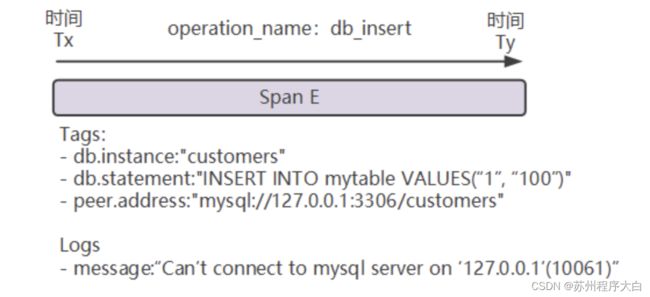
Logs(日志),每个span可以进行多次logs操作,logs反映了瞬间的状态,带有一个时间戳,以及至少一个k-v对。例如msyql访问失败,可能出现这样的信息:

Tags(标签),每个span可以携带多个标签,标签存在于span的整个生命周期里,能够提供很多有效信息。注意tags是不会传递给子span的。例如mysql可能出现这样的信息:
SpanContexts(跨度上下文),当需要跨越进程进行传递时(例如RPC调用),需要使用到跨度上下文来延续请求调用链:

包含了两部分:
-
区分span和trace的信息:通常是TraceId和SpanId。
-
baggage(随行数据):k-v集合,在Trace的所有span内全局传输,可以用来存储业务数据(如customerID等)。存储数量量太大或元素太多,可能降低吞吐量、增加RPC延迟。

OpenTracing API相关概念
Tracer的Inject/Extract
我们跨进程调用的方式有很多,HTTP、gRPC、Dubbo、Kafka等,为了抽象出统一的概念,OpenTracing提出了Tracer的API(io.opentracing.Tracer)通过carrier去操作spanContext,有两个方法:
-
inject(spanContext, format, carrier)
-
extract(format, carrier)
ormat有几个选项:
-
TEXT_MAP:k-v集合 。
-
BINARY:字节数组。
-
HTTP_HEADERS:和k-v类似,但保证了HTTP Header的安全性(保证了key、value的格式合法)。
HTTP Headers 安全性见源码注释 io.opentracing.propagation.ForMat.BuiltIn:
/**
* The HTTP_HEADERS format allows for HTTP-header-compatible String->String map encoding of SpanContext state
* for Tracer.inject and Tracer.extract.
*
* I.e., keys written to the TextMap MUST be suitable for HTTP header keys (which are poorly defined but * certainly restricted); and similarly for values (i.e., URL-escaped and "not too long").
*
* @see io.opentracing.Tracer#inject(SpanContext, Format, Object)
* @see io.opentracing.Tracer#extract(Format, Object)
* @see Format
* @see Builtin#TEXT_MAP
*/
public final static Format<TextMap> HTTP_HEADERS = new Builtin<TextMap>("HTTP_HEADERS");
具体后面怎么注入和提取数据,各自实现即可,本质上这里类似于序列化反序列化。
ActiveSpan(活跃跨度)
activeSpan(io.opentracing.ActiveSpan),当前运行点附近的跨度。当创建新跨度时,这个活跃跨度默认会被当做父节点(Parent Span),每个线程有且只有1个活跃跨度。
为了避免方法之间把ActiveSpan当做参数传递,用Scope作为ActiveSpan的容器,通过ThreadLocal将Scope存储下来,通过ScopeManager进行管理,就能够在任何地方获取该线程的ActiveSpan了。
这里并没有直接存储ActiveSpan到ThreadLocal,因为当当前span结束(close)时,需要弹栈上一个span,因此通过Scope存储上一个Scope的引用组成链表进行弹栈。(Skywalking采用了栈指针的形式进行弹栈,并采用ContextManager管理整个TraceSegement的周期,后面会提到。)
https://wu-sheng.gitbooks.io/opentracing-io/content/pages/api/cross-process-tracing.html https://opentracing.io/docs/overview/scopes-and-threading/ https://opentracing.io/docs/overview/tracers/ https://opentracing.io/docs/supported-tracers/ https://blog.csdn.net/shuai_wy/article/details/107744631 https://github.com/yurishkuro/opentracing-tutorial/tree/master/java/src/main/java/
OpenTelemetry

OpenTelemetry合并了Goole的OpenCensus和CNCF(Cloud Native Computing Foundation,云原生计算基金会)的OpenTracing,并统一由CNCF管理。
OpenTelemetry的终极目标是做Logging、Metrics、Tracing的融合,作为CNCF可观察性(Observability)的最终解决方案,包含了:
-
规范的指定和统一
-
SDK实现和集成
-
采集系统的实现
目前官方推荐的是Logging→Fluentd,Metrics→Prometheus,Tracing→Jaeger。
但现在OpenTelemetry还处于沙盒状态,且Jaeger比Skywalking的使用体验差了非常多,侵入性强,功能缺失,还出过生产事故(因为数据加载耗费太多内存导致节点崩溃),因此目前用skywalking是没有什么问题的。
skywalking本身支持OpenTracing,因此OpenTelemetry的支持也是OK的。
全链路监控考虑因素
我们对全链路监控有如下要求:
-
低侵入性:代码低侵入,容易切换,且开发工作量小。
-
低性能影响:对业务本身机器资源使用和响应延迟影响较小。
-
操作简便、接入灵活。
-
时效性高:实时或近实时展示数据和报警。
为什么不用Istio做追踪?
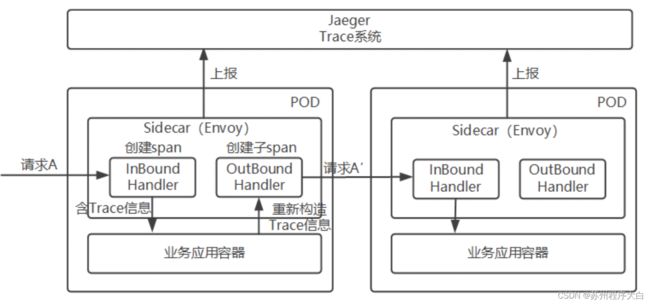
请求经过sidecar,sidecar创建span,sidecar直接上报trace信息(如envoyAcessLogService)给trace系统(如jaeger、skywalking)。 旧版本是通过Mixer的Adapter对接的,这里不再提及。
存在问题:
-
业务需要侵入性地为HTTP等协议添加Header,因为跨进程了,类似于SpanContexts的传递。
-
裸机业务无法追踪。
提醒:对于skywalking,只能在istio的tracing和普通agent形式任选其一,否则数据会重复,数据量会翻倍。
字节码增强
问题:在不修改原有Java代码的条件下,如何增加我们的新功能?(例如方法调用前打印一条日志)
字节码和Java类加载机制

运行时类的重载
代码AOP
我们在最初,总是会这样来统计方法访问的时间:
public void a()
{
long startTimeMs = System.currentTimeMillis();
log.info("processing...");
long runningTimeMs = System.currentTimeMillis() - startTimeMs;
}
当有很多个方法都要修改,我们可能用到一些AOP切面,统一去处理。但这样是需要修改代码的,有侵入性。
静态重写
为了保证无侵入,如果我们在类被加载前,将这些语句写入.class字节码文件,就OK了。
![]()
利用ASM和Javassist等工具很容易做到。问题是,这样的操作我们需要一个一个文件手动修改,如何让它自动化呢?
动态重载
JVMTI、Instrumentation、Bytebuddy
JVM不允许在运行时动态重载一个类(加载1个类2次),因此考虑使用Java类库Instrument,对已加载类进行修改。
-
JVMTI(JVM Tool Interface),是JVM暴露出来供用户扩展的接口集合,类似于JVM的后门。实现上面就是运行到逻辑点后就插入回调接口的执行,例如前面的“加载”,就插入一些“before加载”,"after加载"等回调钩子。
-
Java Instrumentation(java.lang.instrument.Instrumentation)是利用JVMTI的接口提供了代理加载的动态库,JDK1.5支持“JVM启动时加载Agent”(premain,-javaagent:yourAgent.jar,例如skywalking),JDK1.6支持“JVM运行时加载Agent”(agentmain,com.sun.tools.attach,例如Arthas)。Agent可以翻译为“代理”或者“探针”。
-
Bytebuddy基于ASM实现,封装了非常友好的API,避免接触JVM底层细节。skywalking正是利用Bytebuddy进行了字节码增强。
(1)skywalking和其他使用java agent技术的组件兼容性不是特别好,例如Arthas:when use skywalking agent ,arthas is can‘t work well。在8.1.0版本已利用Cache机制修复,稳定性没有验证过:Java Agent:[Core] Support instrumented class cached in memory or file, to be compatible with other agents, such as Arthas。
(2)一些破解程序也是利用premain的形式,对校验部分的方法体进行修改,完成破解的:
(3)著名的BTrace正是利用agent+ASM进行动态调试的,但操作复杂,因此2018年阿里开源了Arthas,可以线上体验,动态调试非常好用。
(4)阿里著名的混沌测试工具chaosblade也是通过java agent的agentmain注入故障的。

premain和agentmain premain
【premain】
public static void premain(String agentArgs, Instrumentation inst)
{
inst.addTransformer(new ClassFileTransformer()
{
@Override
public byte[] transform(……)
{
……
}
}, true);
}
1、在类加载前,注册自己的classFileTransformer到Instrumention实例中,在classFileTransformer中通过targetClassName可以指定要修改的类限定名;
2、class文件读入内存后,触发ClassFileLoadHook回调,在该回调中会遍历所有的Instrumentation实例,并执行其中所有的ClassFileTransformer的transform方法,修改字节码
这样指定类的字节码就被我们动态修改了,且这些代码都是在agent里面,不会影响原有业务代码。
【agentmain】
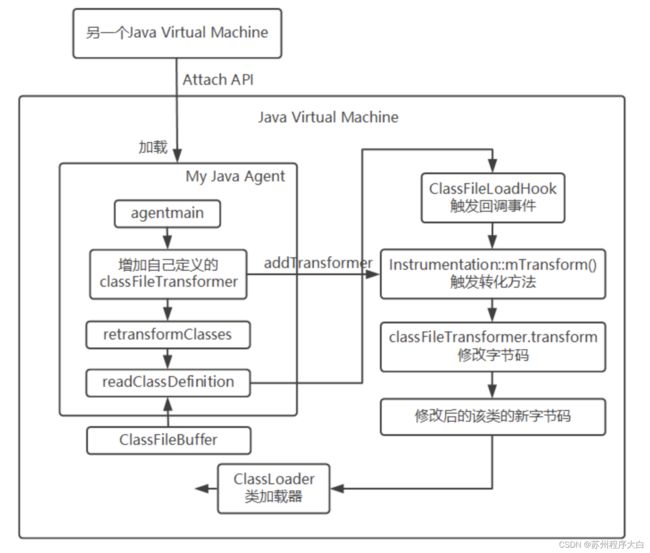
public static void agentmain(String agentArgs, Instrumentation inst)
{
inst.addTransformer(new ClassFileTransformer()
{
@Override
public byte[] transform(……)
{
……
}
}, true);
inst.retransformClasses(xxxxxxxx.class);
}
1、通过另一个进程JVM,利用Attach API,在native函数的Agent_OnAttach中请求目标加载agent,创建InstrumentationImpl对象、监听ClassFileLoadHook事件,注册机的transformer。
2、触发retransformClasses方法,然后会去读取ClassFile,触发ClassFileLoadHook事件,后面的流程与premain一致。
(1)动态替换时,如果该类的方法正处于运行点怎么办?
redefineClasses依赖VMThread单线程操作,该线程维护一个vm操作队列,执行vm操作必须在安全点(safepoint)执行。常见的安全点如方法调用前、方法返回、for循环调用前等等。常见的vm操作例如GC,或者这里的redefineClasses。通过SafepointSynchronize使得所有线程进入安全点,再执行vm操作,完成之后再唤醒所有线程。因此该类正在运行的线程会被挂起,且是STW的。
当线程恢复后,旧类中正在执行的方法仍然会使用旧类的定义,后续代码均使用新类定义。
(2)retransformClasses对类的修改有限制,只能修改方法体、常量池和属性,不能添加、删除、重命名字段或者方法,不能更改方法签名,不能更改继承关系。
字节码增强
-
字节码增强(bytecode-enhance)指的是在Java字节码生成之后,对其进行修改,从而增强其功能。
-
字节码增强有很多方式,例如编译期增强,直接使用ASM等工具修改字节码,或者运行期增强,例如使用Java Agent等技术。
-字节码增强可以用来做很多事情,例如开发期间热部署、或者测试时做一些Mock(如Mockito利用了ASM),或者做一些Trace、性能诊断、故障注入等等。
Skywalking实现
Skywalking是一个可观测性分析平台(Observability Analysis Platform,OAP)和一个应用性能管理(Application Performance Management,APM)系统。
skywalking整体架构
Skywalking目前想要做成跟踪、监控、日志一体的解决方案(Tracing, Metrics and Logging all-in-one solution)。
-
数据收集:Tracing依赖探针(Agent),Metrics依赖Prometheus或者新版的Open Telemetry,日志通过ES或者Fluentd。
-
数据传输:通过kafka、Grpc、HTTP传输到Skywalking Reveiver
-
数据解析和分析:OAP系统进行数据解析和分析。
-
数据存储:后端接口支持多种存储实现,例如ES。
-
UI模块:通过GraphQL进行查询,然后通过VUE搭建的前端进行展示。
-
告警:可以对接多种告警,最新版已经支持钉钉。
这里着重提一下新版本已经支持日志收集和查询,但功能有限(可以在线体验:用户名skywalking,密码skywalking),本质上是利用日志框架直接传输日志到Skywalking后端(OAP)。
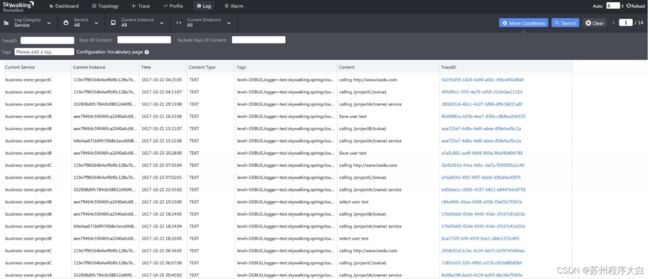
追踪实现原理
Agent和Plugin
skywalking agent为了能够让更多开发者加入开发,并且能够有足够的自由度(比如一些私有协议),使用了插件机制。 agent启动时会加载所有plugins,进行字节码增强。
Plugins的核心问题有2个:
-
创建span,让它能够显示Trace调用链
-
考虑如何传输,例如Kafka需要考虑如何把它加入kafka header中;HTTP需要考虑加入Http Header中。
org.apache.skywalking.apm.plugin.kafka.KafkaProducerInterceptor
public class KafkaProducerInterceptor implements InstanceMethodsAroundInterceptor
{
@Override
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
MethodInterceptResult result) throws Throwable
{
……
// 创建span信息
AbstractSpan activeSpan = ContextManager.createExitSpan(OPERATE_NAME_PREFIX + topicName + PRODUCER_OPERATE_NAME_SUFFIX, contextCarrier, (String) objInst
.getSkyWalkingDynamicField());
Tags.MQ_BROKER.set(activeSpan, (String) objInst.getSkyWalkingDynamicField());
Tags.MQ_TOPIC.set(activeSpan, topicName);
SpanLayer.asMQ(activeSpan);
activeSpan.setComponent(ComponentsDefine.KAFKA_PRODUCER);
……
// 加入Kafka头部
while (next.hasNext())
{
next = next.next();
record.headers().add(next.getHeadKey(), next.getHeadValue().getBytes());
}
……
}
@Override
public Object afterMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
Object ret) throws Throwable
{
ContextManager.stopSpan();
return ret;
}
@Override
public void handleMethodException(EnhancedInstance objInst, Method method, Object[] allArguments,
Class<?>[] argumentsTypes, Throwable t)
{
}
TraceSegment设计
skywalking没有使用传统的span模型,处于性能考虑,将span保存为数组,存放到TraceSegment结构中批量发送;同时Segment可以很好地在UI上展示信息。
一个TraceSegment是Trace在一个进程内所有span的集合。如果是多个线程协同产生1个Trace(例如多次RPC调用不同的方法),它们只会共同创建1个TraceSegment。
由于支持多个入口,因此skywalking去掉了RootSpan的概念,skywalking提出了3种span类型:
-
EntrySpan:进入TraceSegment的请求,一般为HTTP/RPC服务,如SpringMVC。
-
LocalSpan:内部请求,一般为方法调用,或者跨线程调用。
-
ExitSpan:从TraceSegment调出,一般为httpClient。
跨度类型可以从UI上观察到:

当Kafka等进行批量消费时,消费的数据可能来自于不同的生产者,由于skywalking的TraceSegment支持多个EntrySpan,使得生产和消费的调用链可以保存在同一个Trace中。
skywalking的TraceSegment从UI上看,可以通过颜色区分:
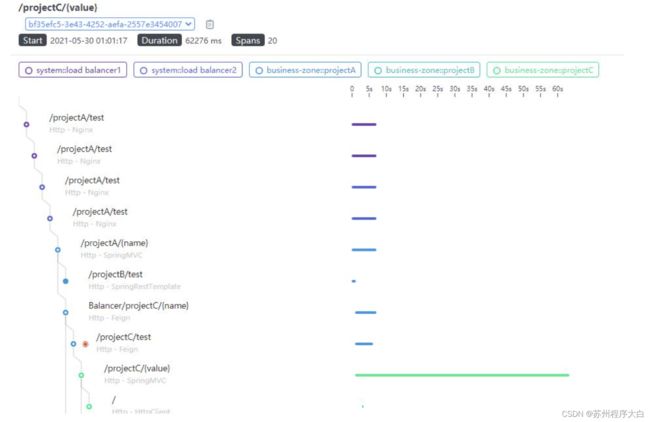
TraceId设计
org.apache.skywalking.apm.agent.core.context.ids:GlobalIdGenerator.java
类似雪花算法的原理(在《Apache Skywalking实战》中,作者直接称其为雪花算法)

-
32位去掉横线的UUID,表示应用实例的ID
-
当前线程ID
-
当前毫秒时间戳,例如这里的1621825236671时间为:2021-05-24 11:00:36
-
4位从0000到9999的,循环单调递增的随机数。实现上采用ThreadLocal保证线程安全。
时钟回拨(time-shift-back)问题:机器依赖NTP服务进行时间校准,当出现问题时,可能发生新生成的ID时间戳比旧ID时间戳更小,导致可能产生2个完全相同的时间戳。
skywalking的解决方法是:产生一个随机数字替代时间戳。但它的实现上面使用了random.nextInt()的方法,注意实际上可能产生负数,这里比较迷。
![]()
请求采样设计
org.apache.skywalking.apm.agent.core.sampling:SamplingService
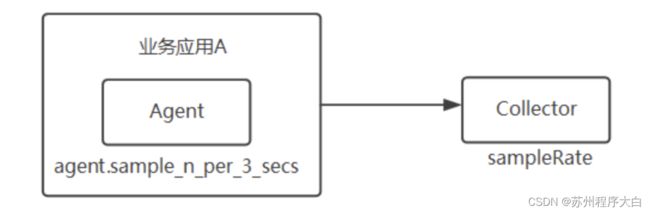
有两种方式可以调整请求采样:
1、skywalking agent调整采样率,减少数据上传
通过agent.sample_n_per_3_secs设置3秒内采样的数量,一般500~2000是合适的值。默认-1全采样。 在设置agent采样率后,如果调用链上游进行了采样,那么下游会忽略采样率进行强制采样,保证Trace调用链完整。
2、collector调整采样率,丢弃数据
通过sampleRate调整采样率,丢弃部分数据。默认10000是全采样,如果设置为5000则会有50%数据被丢弃。 丢弃数据只会影响Trace功能,不会影响Metric功能,Metric的所有数据都是根据全量数据计算的。
- Trace功能:调用链。
- Metric功能:性能检测指标,如成功率等等。
8.4.0开始支持Agent参数配置动态调整,在修改agent采样率时不必重启应用。
数据收集和消费(轻量级队列内核)
org.apache.skywalking.apm.commons.datacarrier.buffer
为了解耦数据上传和消费,平衡上传速度和消费速度,skywalking在内部构建了一个轻量级的消息队列。
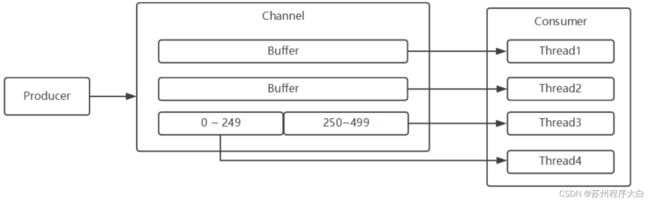
hannel可以类比为Topic,Buffer可以类比为Partition。
1、生产数据,先判断存储在哪个Buffer中,再判断存储在Buffer的哪个位置。
-
Partition:默认实现为从第一个到最后一个Buffer轮询。
-
判断存储位置:Buffer维护了一个从0开始的循环索引,记录下个可用位置:
-
BLOCKING:如果当前位置还有数据未消费,则阻塞新数据写入,且产生回调事件
-
OVERRIDE:如果当前位置还有数据未消费,直接覆盖新数据
-
IF_POSSIBLE:从当前index往后找n位,如果有空闲位置,则保留,如果没有,则丢弃。
2、消费消息,每个消费者可以有多个消费线程
如果Buffer队列数量>消费线程数量,则1个线程可以消费多个Buffer,和普通消息队列一样;
如果Buffer队列数量<消费线程数量,则部分Buffer可能对应多个线程,对应的方式是平分Buffer长度,例如长度500,平分0249给Thead4,250499给Thread3。 在消息消费时,消费线程会初始化一个1500长度的consumeList,然后把Buffer从头到尾遍历,遇到非null值就存入consumeList中,并将index置为null可写,然后调用consume方法执行具体的消费逻辑。
性能剖析实现原理
当线上代码运行缓慢时,我们希望找出缓慢的原因。一种常见的方式就是增加日志打印→重新编译→重新提测→上线观察→找到问题后修改代码→重新编译……一套流程走下来一周就过去了。 因此skywalking利用自身tracing优势+java agent技术,实现了“性能剖析”功能。
1、线程堆栈分析
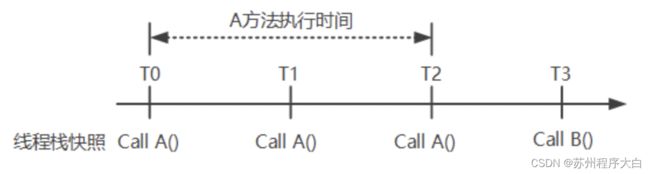
当性能剖析开始后,会对执行线程周期性地创建线程栈快照,并将所有快照进行汇总分析。当两个连续的快照含有同样的方法栈,说明大概率这段时间都在执行这个方法,估算出方法执行时间,就能够帮助判断性能问题出在哪里。
另外,LineNumberTable也是在方法信息里的,因此可以直接看到代码行数,实现代码级别的性能问题定位:

2、性能损耗控制 由于操作的是生产环境,不能对现有代码产生严重影响,所以需要控制性能损耗。
-
相比于侵入性地编写log打印,skywalking的性能剖析不需要埋点,也就不会增加额外的日志打印开销,也不会对日志系统/监控系统产生压力(例如有些应用会要求线上开启debug进行调试)。
-
采样间隔、采样数量,采样时间段,采样接口等都可以配置,且大于指定执行时间的调用链才会被监控。
-
监控时间可以设置定时,在业务低谷期进行处理 几乎是无损耗。
点击直接资料领取
这里有各种学习资料还有有有趣好玩的编程项目,更有难寻的各种资源。