让 Python 爬虫也能读得懂「滑动验证码」
动态网页与静态网页最大的不同是资料是在什么时间点取得的,动态网页是在浏览器已经取得 HTML 后,才透过 JavaScript 在需要时动态地取得资料。因此,爬虫程式也必须要考虑动态取得资料这件事情,才有办法正确地找到想要的资料。 「滑动验证码(Slider Captcha)」是验证码机制当中常见的典型,也是防范爬虫程式中一种难缠的对手。这一篇文章将会利用 Python 、opencv 与 Selenium 三个工具,示范如何拆解和模拟滑动验证码。

常见的网页验证码类型与原理
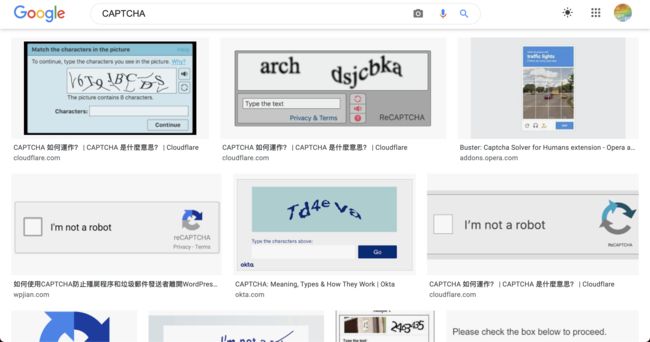
你在浏览网页的时候,有看过这些验证机制吗?网页验证码的专业术语称为「CAPTCHA 」(全名是Completely Automated Public Turing test to tell Computers and Humans Apart 自动判别电脑与人类的公开图灵测试),是目前在网页当中常见的一种验证机制,用来判断恶意的使用者干扰与攻击。目前常见的 CAPTCHA 方法有以下几种:
- 信件验证码/简讯验证码
- 图形验证码
- 问题验证码
- 行为验证码
reCAPTCHA 计画目前是由 Google 主要发展的验证机制,最早是由 CMU 发起的 。 reCAPTCHA 透过不同的情境让人类回答,并借此来帮助帮助文件数位化的进行。这个计画将纸本扫描后无法被辨识文字显示在问题中,让人类在回答问题也能加以利用。
利用 Python 处理「滑动程式码」的思路
而在「图形验证码」当中,有一种常见的变形称为「滑动验证码」。滑动验证码会动态的更新图片与缺块,并且要求使用者将缺块移动到图片中的特定位置才能通过判断,如图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0KyrXkiR-1622897197711)(https://imgur.com/

对于爬虫的开发者而言,滑动验证码的确是一个蛮大的门槛。如何爬虫程式可以读得懂验证码,并且进一步模拟其行为都需要对网页运作有一定的熟悉程度才行。接下来,就让我们透过实作范例一起来体验滑动程式码的解决思路,我们可以分成两个大区块:
- ① 利用 Python + opencv 拆解缺块位置
- ② 利用 Python + Selenium 模拟滑动行为
① 利用 Python + opencv 拆解缺块位置
先手动把「背景图」下载到本地端电脑,再试着利用图像识别的方法试着找出位置。
(1)利用 cv2 将图片读取到程式中
OpenCV(Open Source Computer Vision Library)是用于电脑视觉的处理套件,在 Python 可以使用 opencv-python 与 cv2 进行安装/载入。第一步,我们先利用 cv2.imread(…) 把图片读到程式中,并且利用 cv2.cvtColor 进行颜色转换(原始图片有误差):
from matplotlib import pyplot as plt
import cv2
path = '~/Downloads/filename.png'
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Converting BGR to RGB
plt.imshow(image)
plt.show()

(2)判断图片中的物体边缘轮廓
Canny 是图形识别中用来作边缘侦测(Edge Detection)的方法,细节的参数细节可以看官方文件。 Canny 方法能将原始图片转成灰阶之后,输出包含边缘范围的黑白影像:
canny = cv2.Canny(image, 300, 300)
plt.imshow(canny)
plt.show()
可以从结果中看到除了区块之后,也包含很多小的零散的区块部分:

(3)取出缺块所在的位置
接下来利用 cv2.findContours() 找出图片中所有侦测到的区块,把他标记成蓝色的部分画出来。从长度(w)跟宽度(h)可以判断出哪一个区块是图片中真正的区块,但图片颜色太接近的情况下会增加判断的难度。
contours, hierarchy = cv2.findContours(canny, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)
dx, dy = 0, 0
for i, contour in enumerate(contours):
x, y, w, h = cv2.boundingRect(contour)
if (w > 50) and (h > 50):
dx = x
dy = y
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
plt.imshow(image)
plt.show(
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o8pix3m9-1622897408487)(https://i.imgur.com/qflYzVf.png)]
最终就可以得到缺块所在的位置是 dx 和 dy 两个变数:
dx, dy # (202, 15)
以这个例子来说,我们就可以得知缺块距离最左边距离 202 px 的偏移量。
② 利用 Python + Selenium 模拟滑动行为
第二段,我们会利用 Selenium 浏览器测试工具帮助我们「模拟使用者移动方块」的行为。关于 Selenium 的动态网页模拟,之前也有写过这一篇分享文。
(1)打开浏览器前往网页,下载原始图片
先观察一下网页的组成,发现给定的范例网站是利用 Canvas 动态载入图片实现滑动验证码的效果的:

接下来利用 Selenium 打开浏览器跳转到网页中,利用 JavaScript 的先将 Canvas 转成图片后再进行下载 。
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome('./chromedriver')
js_download_code = '''
var link = document.createElement('a');
link.download = 'filename.png';
link.href = document.getElementById('captcha').getElementsByTagName("canvas")[0].toDataURL()
link.click();
'''
browser.execute_script(js_download_code)
这么做就可以把原始图片下载下来,搭配「① 利用 Python + opencv 拆解缺块位置」可以得知需要移动的偏移量。
找出按钮元素
透过观察网页的结构,可以明确的找出需要被移动的方块是位在class = jigsaw__slider–ihcNg 的div 元素(具体的找法,可以参考 这一篇 文章):
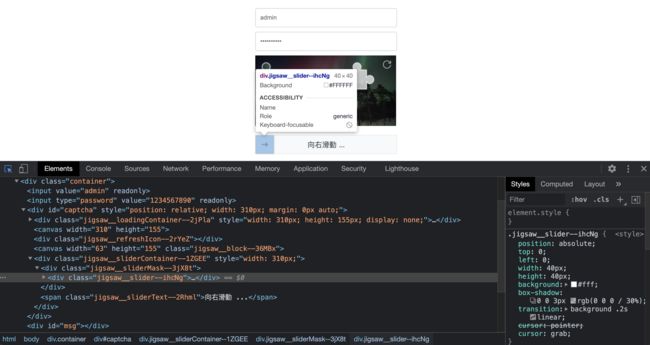
使用 Selenium 轻松选取:
btn = browser.find_element_by_class_name("jigsaw__slider--ihcNg")
(2)模拟使用者拖拉方块行为
最后一步,就可以利用刚刚找出来缺块的位置及浏览器模拟的工具,把方块移动到指定的偏移位置:
move = ActionChains(browser)
move.click_and_hold(btn)
move.move_by_offset(dx, 0)
move.perform()
实战!让 Python 爬虫也能读得懂「滑动验证码」
在这个例子当中,除了实作滑动验证码的爬虫之外,也弄了一个简单的滑动验证码作为标的。最后的成果大概像这样,从「打开网页」 → 「下载图片」 → 「解析位置」 → 「模拟滑动」的整个过程:
网页爬虫是资料收集的一种手法,不过面对于网页技术的变化,爬虫程式也有不同的应对策略。如果你在爬虫实作上还遇到什么问题,也欢迎留言分享你的观察与解法
Reference
- WIKI: 验证码
- Captcha验证码有哪些分类?有什么作用?
- 使用 Python + Selenium 破解滑块验证码
嗨,你好,我是维元,持续在不同的平台发表对 #资料科学、 #网页开发 或 #软体职涯 相关的文章。如果对于内文有疑问都欢迎与我们进一步的交流,都可以追踪我的Facebook 粉专:资料科学家的工作日常 ,也会不定时的举办分享活动,一起来玩玩吧ヽ(●´∀`●)ノ
在大数据时代下,资料收集与程式爬虫你已经是基本的数位技能!最近正在计画【超新手也能用Python 爬虫打造货比千家的比价网站】的线上课程,实现一键极速收集海量资料,手把手带你打造比价网站。从资料收集、资料整理到最终的部属展示,将海量数据转化为可视化的图表,并结合网站实作,实现真正的落地运用

填问卷即可抽免费课程: https://pse.is/3fyr4n