异常检测之孤立森林算法详细解释且配上代码运行实例
由于异常值往往有的两个特点:异常数据只占很少量、异常数据特征值和正常数据差别很大。孤立森林,不是描述正常的样本点,而是要孤立异常点,由周志华教授等人于2008年在第八届IEEE数据挖掘国际会议上提出。孤立森林不需要根据距离和密度来衡量异常,因此孤立森林的时间复杂度是线性的,需要的内存也很少。孤立森林有能力处理大数据和高维数据,对于我们大数据背景下的异常识别,是十分适合的一个模型。
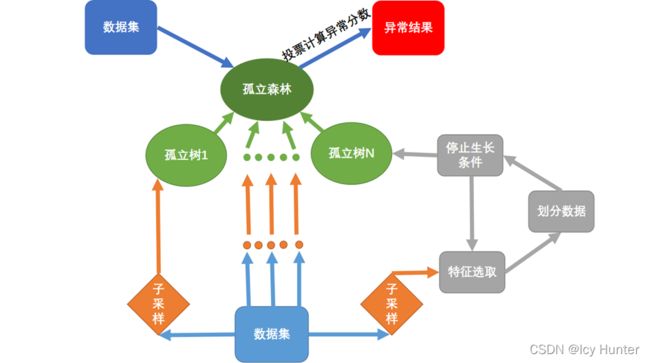
孤立森林的基本思想是对数据子采样后选择特征孤立数据到一颗树的叶节点,直到终止条件发生,孤立树建立完成。再循环建立新的孤立树,直至形成一片孤立森林。然后数据放入计算此数据在对于叶节点的路径长度,路径长度越短表示越先被孤立出来,越可能是异常值。
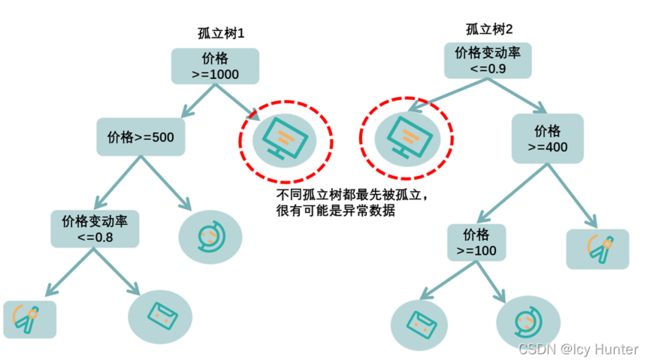
孤立森林的思想如下图所示:
孤立森林相关定义如下:


异常分数的评价:
当异常分数s越接近1时,表明数据异常的可能性很大
当异常分数大于0.5时,数据有可能是异常值
当所有数据异常分数s在0.5左右时,可以不认为数据整体有明显异常。
孤立森林的算法流程图如下
======================================================
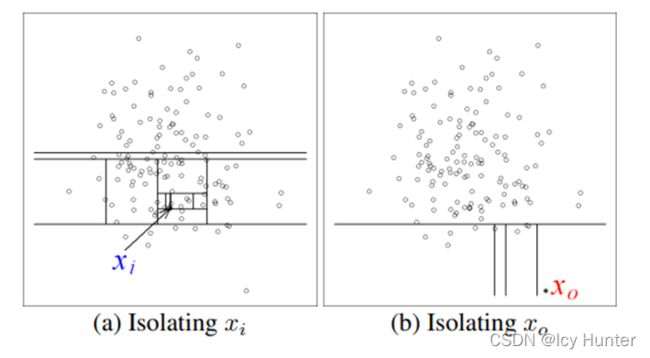
论文中的图,表达的意思应该是一样的。
通过一颗树分叉来划分数据集,往往异常值(和正常值差的比较大)只需几次会被首先孤立出来,而正常值,往往需要更多的次数才会被孤立出来。
如下图所示Xi为正常值,一棵树需要对数据切分多次才能够将其孤立出来,而Xo明显为离群值,一棵树只需要划分一两次就可能将其孤立出来了。
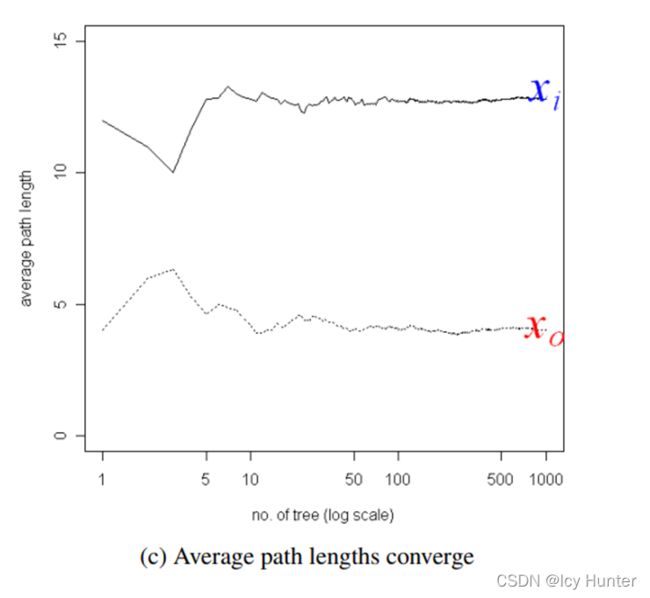
由于是集成学习模型,那么孤立树的个数也有讲究,当数量过小时,会导致路径平均值波动较大,当数量过大时,会白白浪费计算资源,因此文章也经过多次实验证明,当孤立树选100棵时,既能使得路径平均收敛(即稳定在为某一值),也能拥有较高的性能。
还有一点就是,由于孤立森林的思想是孤立异常值,那么当样本数据量过大时,可能异常值也可能会挤在一起,就会导致孤立的思路失效了。如下图所示

对于这个问题,可以通过子采样来解决。
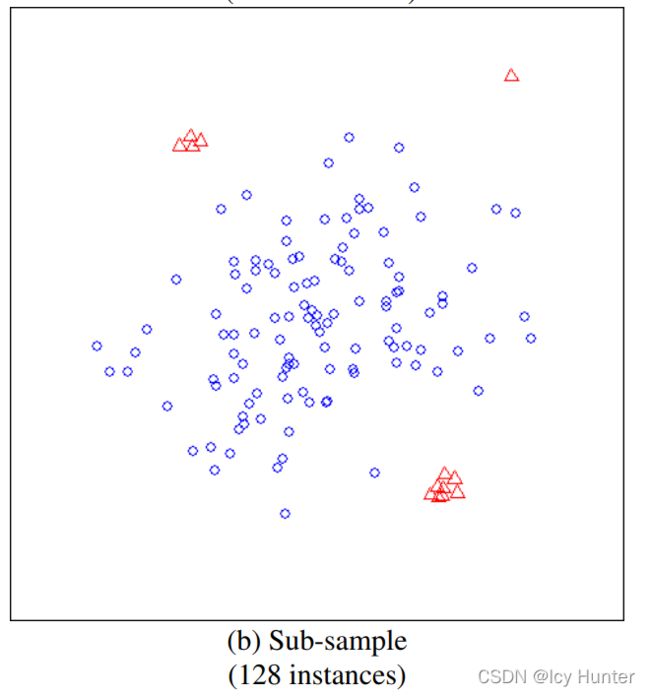
子采样之后可见异常值又重新被明显的区分开来了,论文中也通过多次实验发现子采样为256时,效果是最好的。
时间复杂度和空间复杂度

简单来说训练时间是O(1),预测时间是O(N),空间同理。
最后因为这个模型十分经典,sklearn中已经帮我们实现了。
# coding:utf-8
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
np.random.seed(0)
mean = np.array([3, 0])
cov = np.eye(2)
dot_num = 300
fxy = np.random.multivariate_normal(mean, cov, dot_num)
data = pd.DataFrame(fxy)
data.columns = ["X", "Y"]
model = IsolationForest()
model.fit(data)
data["label"] = model.predict(fxy)
data["score"] = model.decision_function(fxy)
inner = data[data["label"] == 1]
outer = data[data["label"] == -1]
fig = plt.figure()
fig1 = fig.add_subplot(121)
fig2 = fig.add_subplot(122)
fig1.scatter(inner["X"], inner["Y"], label="inner-position", alpha=0.5, color="blue")
fig1.scatter(outer["X"], outer["Y"], label="outer-position", alpha=1, color="red")
fig1.legend()
fig2.bar(inner.index, inner["score"], label="inner-score", alpha=0.5, color="blue")
fig2.bar(outer.index, outer["score"], label="outer-score", alpha=1, color="red")
fig2.legend()
plt.show()
结果:
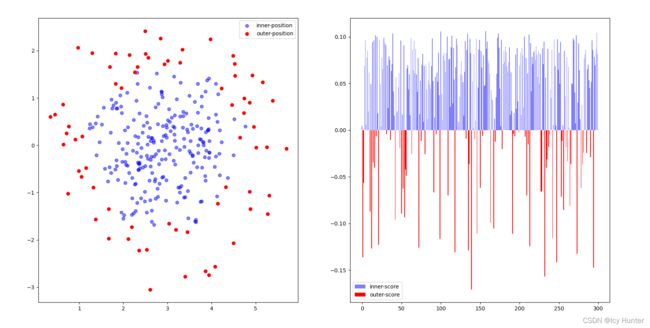
可见孤立森林的效果还是很客观的,不过值得注意的是,sklearn中的异常分数是经过调整的,他应该是通过取负之后再加上0.5作为异常分数,因此这里的异常线为0,即大于0为正常,小于0为异常,从图中应该也看得出来。