Hive系列(一)—— Hive初识及基础介绍
Hive 基础
- Hive 简介
-
- 什么是 Hive
- 为什么使用 Hive
- Hive 特点
- Hive 体系结构
- Hive 和 RDBMS 的对比
- Hive 基础
-
- Hive 数据存储
- Hive 基本操作
Hive 简介
什么是 Hive
Hive 是由 Facebook 实现并开源的、基于 Hadoop 的一个数据仓库工具。它可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能;其底层数据是存储在 HDFS 上,Hive的本质是将 SQL 语句转换为 MapReduce 任务运行,使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
数据仓库之父比尔·恩门(Bill Inmon)在 1991 年出版的“Building the Data Warehouse”(《建立数据仓库》)指出:
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。用一张图表示Hive如下:
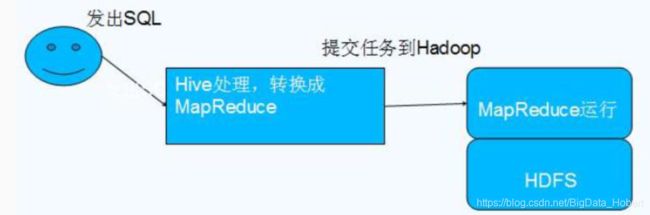
为什么使用 Hive
直接使用 MapReduce 所面临的问题:
- 人员学习成本太高
- 项目周期要求太短
- MapReduce实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
-
更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
-
更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
-
更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
Hive 特点
Hive 优势
-
基于hadoop的数据仓库解决方案:
- 将结构化的数据(序列化)文件映射为数据库表
- 提供类sql的查询语言HQL(sql 代替 mapreduce)
- 让更多的人,容易的使用hadoop
-
可以整合更多的计算框架
- mapreduce(基于磁盘中间结果存于磁盘)
- spark(基于内存减少IO(磁盘数据流读写),DAG计算模型减少SHUFFLE)
- tez(也有DAG和container重用,但部署繁琐)
-
支持在HDFS和HBase上临时查询数据
-
支持用户自定义函数、格式
-
成熟的JDBC和ODBC驱动程序,用于ETL和BI
-
稳定可靠(真实生产环境)的批处理
-
有庞大活跃的社区
Hive 劣势
-
Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
-
Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能用在交互查询系统中。
-
Hive 不支持事务(因为没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
Hive 体系结构

从上图看出hive的内部架构由四部分组成:
-
用户接口:
(1) CLI,Shell 终端命令行(Command Line Interface),采用交互形式使用 Hive 命令行与 Hive 进行交互,最常用(学习,调试,生产);
(2) JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过 这连接至 Hive server 服务;
(3) Web UI,通过浏览器访问 Hive。 -
底层的Driver:Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行。
Hive 的核心是驱动引擎Driver, 驱动引擎由四部分组成:
(1) 解释器Interpreter:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器Compiler:编译器是将语法树编译为逻辑执行计划
(3) 优化器Optimizer:优化器是对逻辑执行计划进行优化
(4) 执行器Executor:执行器是调用底层的运行框架执行逻辑执行计划 -
元数据存储系统 : Metastore(default derby,recommend mysql)
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。Hive 的元数据包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对 应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存储目录不固定。数据库跟着 Hive走,极度不方便管理,因此通常通过我们自己创建的 MySQL 库(本地 或 远程),进行Hive 和 MySQL 之间通过 MetaStore 服务交互。
-
执行平台hadoop:Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行。
执行流程分为以下两步,如下:
# hive 处理 CLI(beeline)/JAVA jdbc => Driver => SQL Parser -> sql cmd翻译成AST抽象语法树 -> 第三方工具antlr对AST进行语法分析:表、字段、语法寓意是否存在 => Query Optimizer -> 优化逻辑执行计划 => Physical Plan -> 将AST转换成逻辑执行计划 => Execution -> 转换逻辑执行计划为可执行物理执行计划 # hadoop 处理 hadoop平台 Hive => Mapreduce/spark/tez =>hdfs
此外,还需要了解hive中跨语言服务 thrift server:
thrift通过一个中间语言IDL(接口定义语言)来定义RPC(不同节点进程之间函数调用,即微服的核心所在)的数据类型和接口,这些内容写在以.thrift结尾的文件中,然后通过特殊的编译器来生成不同语言的代码,以满足不同需要的开发者,比如java开发者,就可以生成java代码,c++开发者可以生成c++代码,生成的代码中不但包含目标语言的接口定义,方法,数据类型,还包含有RPC协议层和传输层的实现代码。
Hive 和 RDBMS 的对比
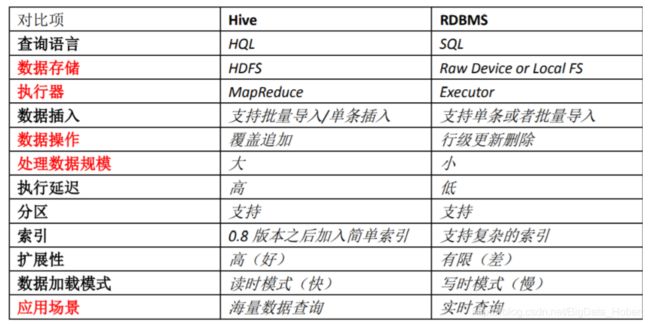
Hive 具有 SQL 数据库的外表,但应用场景完全不同,Hive 只适合用来做海量离线数 据统计分析,也就是数据仓库。
Hive 基础
Hive 数据存储
-
Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对 应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
-
Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式 (Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义文件格式等
-
Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在 HDFS 中表现所属 database 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
partition:在 HDFS 中表现为 table 目录下的子目录
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散 列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建
-
Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
Hive 基本操作
删库操作
-
删除空数据库
drop database if not exists hivetest; -
删除非空数据库
drop database if not exists hivetest cascade;
建表操作
-
只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据:
create table shop( shopid BIGINT, shopname STRING, running BOOLEAN, contact ARRAY<STRING>, address STRUCT<province:STRING,city:STRING,district:STRING,detail:STRING>, yearlymoney MAP<STRING,FLOAT> ) row format delimited fields terminated by '|' #行中列分隔符:默认'\001' collection items terminated by ',' #指定集合数据ARRAY或者STRUCT分隔符,默认'\002' map keys terminated by ':' #指定map分隔符,默认'\003' lines terminated by '\n' #指定行结束符:默认'\n' stored as textfile #文件存储类型:默认textfile ,压缩用sequen location '/hive110/warehouse/shop' #文件存储位置:默认hive.metastore.warehouse.dir位置 ; -
内部表、外部表、分区表、分桶表
内部表和外部表的区别:
删除内部表,就是删除表元数据和数据,内部表建立核心数据。
删除外部表,只删除元数据,不删除数据,外部表建立共享数据。
内部表和外部表的使用选择:
大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于选择内部表,但是如果Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在 HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
分区表和分桶表的区别:
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理(分桶是以分桶字段的hashcode()%numberReducerTasks)类似。
分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所 以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列 形成的多个文件,所以数据的准确性也高很多
-
查询排序操作
order by 全局排序:启动一个reducer。值得注意的是,当开启MR严格模式(set hive.mapred.mode=strict;)的时候 order by 必须设置 limit 子句,否则会报错;对于分区表,必须要对分区字段加限制条件,否则会报错。
sort by 部分排序:只对每个reducer中的字段排序。值得注意的是,sort by 可指定执行的reducer个数(set mapreduce.job.reduces=number);对输出的数据再执行归并排序,即可以得到全部结果。
distribute by :控制map输出在reducer中的分布就是说相同KEY划分到同一个Reducer中。简单的说,distribute by就是按某字段(key)分区。
cluster by 当(sort by + distribute by )为相同字段时,对分区的区内进行排序;但是只能是升序排序。
-
行列互转
行转列
语法:
Lateral view + UDTF(explode表达式) 别名 as columnAlias [,columnAlias] #explode(explode表达式) [as (别名,...)] 理论上不能与其他字段并列在select子句中,除非查询的结果行数一致,不提供别名,就是默认map(key,value)、array(array_name)、... # map(key,value): explode(map_name) key和value自动拆分,key为新列字段,value为行值 # array(array_name): explode(split(array_name,'分隔符')) 原字段为新字段,拆分的值为行值 # struct(fieldname:fieldvalue): explode(struct_name) fieldname和fieldvalue自动拆分,fieldname为新列字段,fieldvalue为行值例如:
select shopname,nian,qian from shop lateral view explode(yearlymoney)t as nian,qian
列转行语法:
concat_ws(SEP_CHAR,collect_list/collect_set()) # collect_list 有序,不唯一 # collect_set 无序,唯一例如:
select userid,concat_ws(',',collect_list(cast(cast(paymoney as decimal(10,2)) as string))) from consume group by userid order by userid结果:

-
窗口函数
语法:sort_func/agg_func/analyze_func over(partition by FIELD order by FIELD[,…]) [as] ALIAS
sort_func
介绍:
# set mapred.reduce.tasks = 1; # 行号 row_number() 序号不重复 1,2,3,4,... # 排名 rank() 并列调号 1,2,2,4,... 序号有可能不连续,排序字段值相同序号 # 排名 dense_rank() 并列续号 1,2,2,3... 序号连续,排序字段值相同序号 # 小于等于当前值的当前组内的记录数(百分比0-1之间,rank/总数(去除重复)) cume_dist() # 切片 ntile(N) 切成N片,当前行的分片号 # 如果切片不均,默认增加第一分片 # 取多少个分片,哪些分片,抽样(类似软分桶)例如:
select studentid,score,courseid, row_number() over() as no1, row_number() over(order by studentid) as no2, row_number() over(partition by courseid order by studentid) as no3, cume_dist() over(order by studentid) as no4, cume_dist() over(partition by courseid order by studentid) as no5, ntile(2) over(partition by courseid order by studentid) as no6 from score; 结果: +------------+--------+-----------+------+------+------+----------------------+----------------------+------+--+ | studentid | score | courseid | no1 | no2 | no3 | no4 | no5 | no6 | +------------+--------+-----------+------+------+------+----------------------+----------------------+------+--+ | 1 | 80 | 1 | 18 | 1 | 1 | 0.16666666666666666 | 0.16666666666666666 | 1 | | 2 | 70 | 1 | 15 | 4 | 2 | 0.3333333333333333 | 0.3333333333333333 | 1 | | 3 | 80 | 1 | 12 | 7 | 3 | 0.5 | 0.5 | 1 | | 4 | 50 | 1 | 9 | 10 | 4 | 0.6666666666666666 | 0.6666666666666666 | 2 | | 5 | 76 | 1 | 6 | 13 | 5 | 0.7777777777777778 | 0.8333333333333334 | 2 | | 6 | 31 | 1 | 4 | 15 | 6 | 0.8888888888888888 | 1.0 | 2 | | 1 | 90 | 2 | 17 | 2 | 1 | 0.16666666666666666 | 0.16666666666666666 | 1 | | 2 | 60 | 2 | 14 | 5 | 2 | 0.3333333333333333 | 0.3333333333333333 | 1 | | 3 | 80 | 2 | 11 | 8 | 3 | 0.5 | 0.5 | 1 | | 4 | 30 | 2 | 8 | 11 | 4 | 0.6666666666666666 | 0.6666666666666666 | 2 | | 5 | 87 | 2 | 5 | 14 | 5 | 0.7777777777777778 | 0.8333333333333334 | 2 | | 7 | 89 | 2 | 2 | 17 | 6 | 1.0 | 1.0 | 2 | | 1 | 99 | 3 | 16 | 3 | 1 | 0.16666666666666666 | 0.16666666666666666 | 1 | | 2 | 80 | 3 | 13 | 6 | 2 | 0.3333333333333333 | 0.3333333333333333 | 1 | | 3 | 80 | 3 | 10 | 9 | 3 | 0.5 | 0.5 | 1 | | 4 | 20 | 3 | 7 | 12 | 4 | 0.6666666666666666 | 0.6666666666666666 | 2 | | 6 | 34 | 3 | 3 | 16 | 5 | 0.8888888888888888 | 0.8333333333333334 | 2 | | 7 | 98 | 3 | 1 | 18 | 6 | 1.0 | 1.0 | 2 | +------------+--------+-----------+------+------+------+----------------------+----------------------+------+--+agg_func
介绍:
# unbounded:无界限 # preceding:从分区第一行头开始,则为 unbounded。 N为:相对当前行向前的偏移量 # following:与preceding相反,到该分区结束,则为 unbounded。N为:相对当前行向后的偏移量 # current row:当前行,偏移量为0 # rang/rows between N preceding and N following # rows unbounded/1 preceding例如:
select studentid,score,courseid, sum(score) over(partition by studentid) ssum, sum(score) over(partition by courseid) csum, sum(score) over(order by studentid,courseid rows between 1 preceding and 1 following) sum3, avg(score) over(partition by studentid) savg, avg(score) over(partition by courseid) cavg, min(score) over(partition by studentid) smin, max(score) over(partition by studentid) smax from score; +------------+--------+-----------+-------+-------+-------+---------------------+--------------------+-------+-------+--+ | studentid | score | courseid | ssum | csum | sum3 | savg | cavg | smin | smax | +------------+--------+-----------+-------+-------+-------+---------------------+--------------------+-------+-------+--+ | 1 | 80 | 1 | 269 | 387 | 170 | 89.66666666666667 | 64.5 | 80 | 99 | | 1 | 90 | 2 | 269 | 436 | 269 | 89.66666666666667 | 72.66666666666667 | 80 | 99 | | 1 | 99 | 3 | 269 | 411 | 259 | 89.66666666666667 | 68.5 | 80 | 99 | | 2 | 70 | 1 | 210 | 387 | 229 | 70.0 | 64.5 | 60 | 80 | | 2 | 60 | 2 | 210 | 436 | 210 | 70.0 | 72.66666666666667 | 60 | 80 | | 2 | 80 | 3 | 210 | 411 | 220 | 70.0 | 68.5 | 60 | 80 | | 3 | 80 | 1 | 240 | 387 | 240 | 80.0 | 64.5 | 80 | 80 | | 3 | 80 | 2 | 240 | 436 | 240 | 80.0 | 72.66666666666667 | 80 | 80 | | 3 | 80 | 3 | 240 | 411 | 210 | 80.0 | 68.5 | 80 | 80 | | 4 | 50 | 1 | 100 | 387 | 160 | 33.333333333333336 | 64.5 | 20 | 50 | | 4 | 30 | 2 | 100 | 436 | 100 | 33.333333333333336 | 72.66666666666667 | 20 | 50 | | 4 | 20 | 3 | 100 | 411 | 126 | 33.333333333333336 | 68.5 | 20 | 50 | | 5 | 76 | 1 | 163 | 387 | 183 | 81.5 | 64.5 | 76 | 87 | | 5 | 87 | 2 | 163 | 436 | 194 | 81.5 | 72.66666666666667 | 76 | 87 | | 6 | 31 | 1 | 65 | 387 | 152 | 32.5 | 64.5 | 31 | 34 | | 6 | 34 | 3 | 65 | 411 | 154 | 32.5 | 68.5 | 31 | 34 | | 7 | 89 | 2 | 187 | 436 | 221 | 93.5 | 72.66666666666667 | 89 | 98 | | 7 | 98 | 3 | 187 | 411 | 187 | 93.5 | 68.5 | 89 | 98 | +------------+--------+-----------+-------+-------+-------+---------------------+--------------------+-------+-------+--+analyze_func
介绍:
# lag/lead(COLUMN_NAME,PRECEDING_ROW_NO,DEFAULT_VALUE) over(...) 向上/下取第几行的某列的值,若值为null,取默认值 # first_value/last_value(COLUMN_NAME) over(...) 取分组内排序后截止到当前行的第一行或最后一行某字段例如:
select studentid,score,courseid, lag(score,1,0) over(partition by studentid order by courseid) prevscore, lead(score,1,0) over(partition by studentid order by courseid) nextscore, first_value(score) over(partition by studentid order by courseid) firstscore from score; +------------+--------+-----------+------------+------------+-------------+--+ | studentid | score | courseid | prevscore | nextscore | firstscore | +------------+--------+-----------+------------+------------+-------------+--+ | 1 | 80 | 1 | 0 | 90 | 80 | | 1 | 90 | 2 | 80 | 99 | 80 | | 1 | 99 | 3 | 90 | 0 | 80 | | 2 | 70 | 1 | 0 | 60 | 70 | | 2 | 60 | 2 | 70 | 80 | 70 | | 2 | 80 | 3 | 60 | 0 | 70 | | 3 | 80 | 1 | 0 | 80 | 80 | | 3 | 80 | 2 | 80 | 80 | 80 | | 3 | 80 | 3 | 80 | 0 | 80 | | 4 | 50 | 1 | 0 | 30 | 50 | | 4 | 30 | 2 | 50 | 20 | 50 | | 4 | 20 | 3 | 30 | 0 | 50 | | 5 | 76 | 1 | 0 | 87 | 76 | | 5 | 87 | 2 | 76 | 0 | 76 | | 6 | 31 | 1 | 0 | 34 | 31 | | 6 | 34 | 3 | 31 | 0 | 31 | | 7 | 89 | 2 | 0 | 98 | 89 | | 7 | 98 | 3 | 89 | 0 | 89 | +------------+--------+-----------+------------+------------+-------------+--+