浅谈Hive
让我们开门见山来一句介绍,Hive是建立在Hadoop HDFS上的数据仓库基础架构。
在Hadoop大数据体系中,Hive和HBase事两种基于Hadoop的不同技术,Hive是一类类SQL的引擎,其数据存放在HDFS上,并运用MapReduce进行计算,适合OLAP事务。而HBase是一种在Hadoop上的NOSQL的键值对数据库,提供数据的实时访问。
好,接下来我们细细地讲。
数据仓库
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time variant)数据集合,用于支持管理决策。下面图为数据仓库体系结构:数据源-》数据存储管理-》分析和挖掘引擎-》应用:
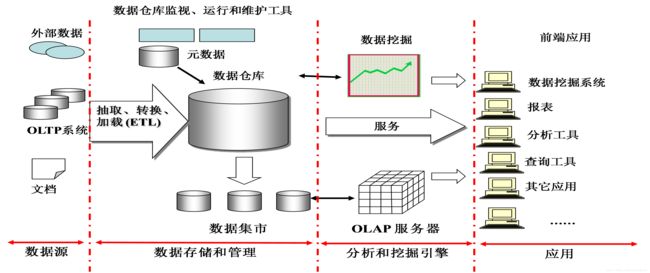
那么数据仓库到底有什么用呢?
传统的数据库适用于OLTP(联机事务处理),主要是基本的,日常的事务处理。比如说银行的转账业务,对于扣钱和存钱这两个操作,操作频率很高,而且只能是要么同时成功要么同时失败。
数据仓库系统的主要应用主要是OLAP(联机分析处理),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。而且数据仓库里面的数据时不可更新的,很久以前的数据也会存在(稳定的,面向历史记录的),只有查询操作没有增删查改。
举个例子:搭建一个商品的推荐系统,我们需要用到很多用户以往购买商品的记录。传统数据库中的结构是为了完成交易设计的,并不太支持大量的查询操作。而且传统数据库会不停更改,不一定保留以往数据。有个不错的例子:知乎:数据库与数据仓库的本质区别是什么
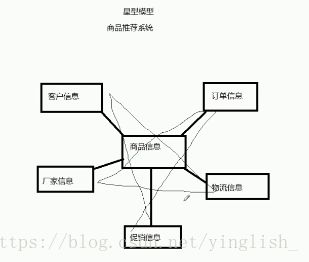
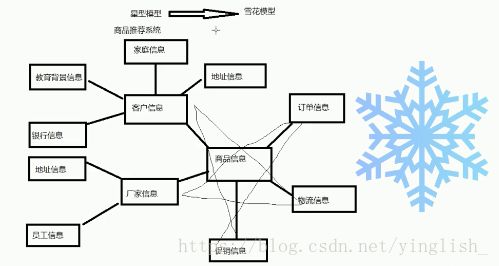
同时做个插曲(宝宝某次笔试的时候出过这个考题,不会填,哭唧唧):数据仓库的两种数据模型:星型和雪花型
同样是商品的推荐系统:
Hive
个人理解的话,Hive的核心说白了也就两句话。
Hive中的表就是HDFS中的表。
在运算方面,Hive定义了简单的类似SQL查询语言,称为HQL它允许熟悉SQL的用户查询数据 。 而HiveQL语句将被转换成MapReduce任务进行运行。
所以Hive就是一个数据仓库的引擎。采用批处理的方式处理海量的数据,并提供了适合数据仓库操作的工具:比如一系列对数据的提取、转换、加载(ETL),可以存储、查询、分析存储在Hadoop中的大规模数据。
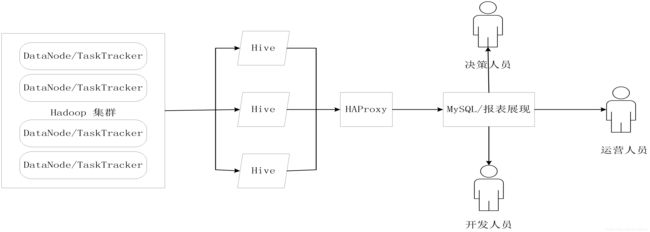
在实际应用中,Hive也暴露出了一些不稳定的问题:端口调用没有响应,出现进程丢失等情况。于是乎便有了Hive HA机制(是不是感觉有点熟悉撒?嘻嘻,对了!HDFS也有HA机制,就是采用active-standby nameNode节点来处理单个NameNode节点出现故障的问题)。
这个图表现了HA机制的基本原理,多个Hive实例被纳到一个资源池中,并由HAProxy提供一个统一对外的接口,对于程序开发人员来说,这就只是一台超强的“Hive”。
而HAProxy每次接到HQL时都会进行逻辑可用性测试,如果存在故障Hive,就将其放入黑名单,选择其他Hive进行工作。同时,HAProxy也会周期处理黑名单,如果检查到可用Hive将会将其放回。
HiveSQL
HiveSQL的语句与SQL非常像,接下来写几个简单的例子吧。
- 创建数据库
hive>create database hive;
hive>create database if not exists hive;- 创建表
hive> use hive;
hive> create table if not exists usr(id bigint, name string, age int);
//create a table in specific location
hive>create table if not exists hive.usr(id bigint, name string, age int) location '/usr/local/hive/warehouse/hive/usr'- 创建视图
hive> create view little_usr as select id, age from usr;- show:查看数据库,表和视图
// show all databases in hive
hive> show databases;
// find databases start with 'h'
hive>show databases like 'h.*';
//show the tables and views in database hive
hive> use hive;
hive> show tables;
//find the tables and views in database hive which start with 'h'
hive>show tables in hive like 'h.*';- load:向表中加载数据
//local files in '/usr/local/data' to table usr and overwrite it
hive>load data **local** inpath '/usr/local/data' **overwrite** into table usr;
//don't overwrite
hive>local data **local** inpath '/usr/local/data' into table usr;
//loacl data files from hdfs to user and overwrite, no more 'local'
hive> load data inpath 'hdfs://master_server/usr/local/data' overwrite into table usr;- insert:向表中插入数据或从表中到处数据
hive> insert **overwrite** table age_table
hive> select * from usr where age=10