使用YOLOv7进行Transformer检测模型的TensorRT部署
最近有大佬开源了YOLOv7, 大概看了一眼, 支持DETR等模型的ONNX导出,并且可以进行tensorrt推理。但是原作者并没有开源对应的权重,也没有开源onnx推理的脚本。本文就依托YOLOv7这个项目,将DETR导出到onnx,并教大家如何使用这个onnx进行tensorrt的部署。
首先clone一下原项目:
https://github.com/jinfagang/yolov7
DETR 权重推理验证
原来的项目其实也支持AnchorDETR,这个我没有测试,但是逻辑应该是一样的。首先大家可以从DETR官方repo下载官方的DETR权重:
GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
但是官方的DETR权重不是基于detection2的。好在我们可以在YOLOv7里面找到一个脚本, tools/convert_detr_to_d2.py可以将原版的模型转到d2.
python tools/convert_detr_to_d2.py --source_model ./detr-r50-e632da11.pth --output_model weights/detr-r50.pth
我是这样转的,然后我们就可以得到一个detr 的d2模型。
同样,我们使用YOLOV7里面的demo脚本,来推理一下这个权重是否正确:
python demo.py --config-file configs/coco/detr/detr_256_6_6_torchvision.yaml --input ./images -c 0.26 --opts MODEL.WEIGHTS weights/detr-r50.pth

结果正确!
看来YOLOv7诚不欺我!
接下来我在多跑几个图片看看:


可以看到,DETR的模型有两个显著的特点:
- 置信度非常高
- 对于遮挡推理效果非常好!
这也是为什么Transformer based的检测模型,才是未来。你会发现他学到的东西非常合理,比从一大堆boudingbox里面选择概率的范式要好一点。
好了,接着我们可以进行下一步了。
DETR导出ONNX
接下来要导出onnx.
我们依旧采用YOLOv7里面的脚本来试一下,里面有提供一个 export_onnx.py。他的使用方式大概是这样:
python3 export_onnx.py --config-file configs/coco/yolox_s.yaml --input ./images/COCO_val2014_000000002153.jpg --opts MODEL.WEIGHTS ./output/coco_yolox_s/model_final.pth
也就是说,YOLOv7里面的脚本,也可以用来导出YOLOX的onnx?这有点牛逼了,挖个坑,有时间用YOLOv7试一下YOLOX的onnx部署看看。
我们使用这行命令:
python export_onnx.py --config configs/coco/detr/detr_256_6_6_torchvision.yaml --input ./images/COCO_val2014_000000002153.jpg --opts MODEL.WEIGHTS weights/detr-r50.pth
来导出ONNX.激动人心的是到了!
看到了这个输出!
[03/26 10:31:13 detectron2]: Model saved into: weights/detr-r50.onnx
但是好像遇到了一个报错:
return self._sess.run(output_names, input_feed, run_options) onnxruntime.capi.onnxruntime_pybind11_state.RuntimeException: [ONNXRuntimeError] : 6 : RUNTIME_EXCEPTION : Non-zero status code returned while running Reshape node. Name:'Reshape_1682' Status Message: /onnxruntime_src/onnxruntime/core/providers/cpu/tensor/reshape_helper.h:41 onnxruntime::ReshapeHelper::ReshapeHelper(const onnxruntime::TensorShape&, std::vector&, bool) gsl::narrow_cast (input_shape.Size()) == size was false. The input tensor cannot be reshaped to the requested shape. Input shape:{2108,1,256}, requested shape:{2108,800,32}
应该是有个错误,好家伙,这后面还有一行输出:
[03/26 10:31:22 detectron2]: generate simplify onnx to: weights/detr-r50_sim.onnx
[INFO] onnx修改完成, 保存在weights/detr-r50_sim.onnx_changed.onnx.
[03/26 10:31:28 detectron2]: test if onnx export logic is right...
INFO 03.26 10:31:28 detr.py:152: [WARN] exporting onnx...
INFO 03.26 10:31:28 detr.py:363: [onnx export] in MaskedBackbone...
m: tensor([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]], device='cuda:0')
m: torch.Size([1, 1080, 1960])
torch.Size([1, 270, 490])
m: tensor([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]], device='cuda:0')
m: torch.Size([1, 1080, 1960])
torch.Size([1, 135, 245])
m: tensor([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]], device='cuda:0')
m: torch.Size([1, 1080, 1960])
torch.Size([1, 68, 123])
m: tensor([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]], device='cuda:0')
m: torch.Size([1, 1080, 1960])
torch.Size([1, 34, 62])
还有一个修改ONNX的逻辑呢?这么看来,DETR的部署还真不太容易,坑很多呢。
不管怎么说,好像YOLOv7给了一个正确的onnx输出结果:
看起来至少是正常的。好了,我们接下来看看导出的onnx长什么样:
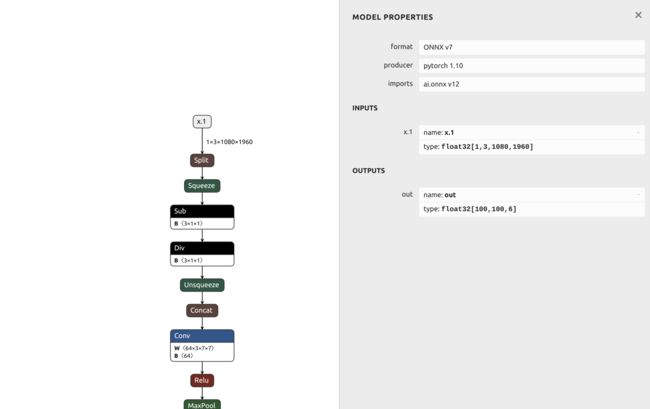
好家伙!费了九牛二虎之力,借助YOLOv7的魔法,我们终于得到了DETR onnx的模型结构了!!
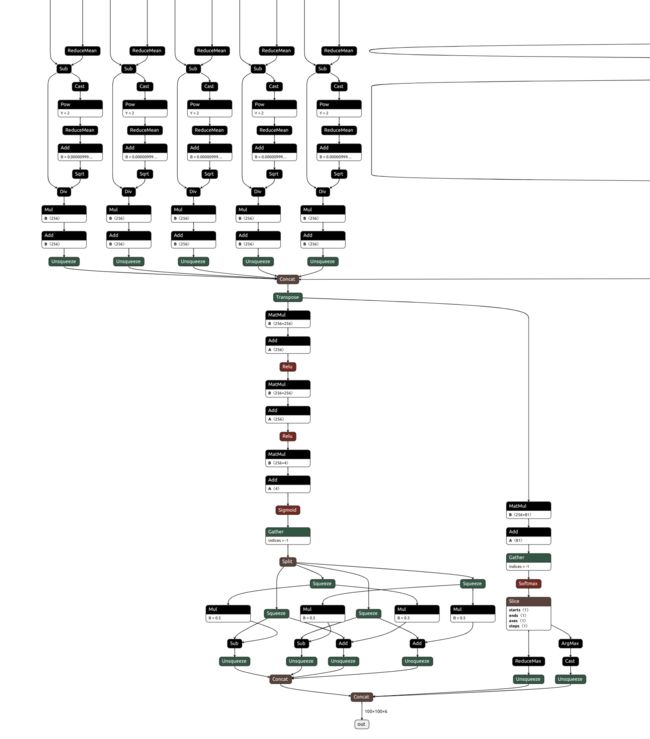
但是这个100x100x6的输出,令人无法理解。理论上应该是100x6才对。
但是我们可视化onnxsimplified的之后模型看看:
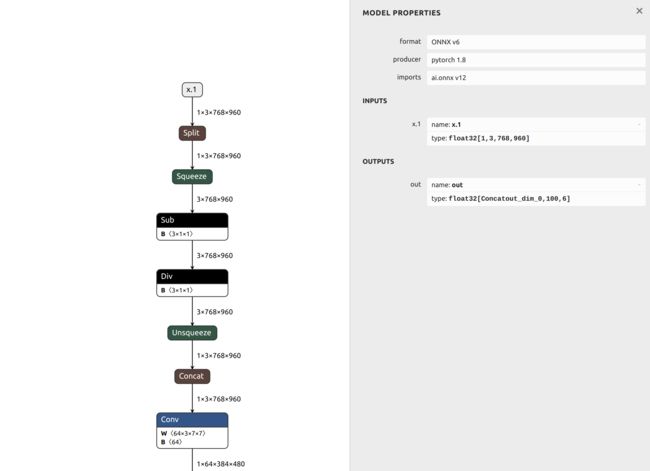
这个结果是正常的,输出第一个维度应该是batchsize.
好了,就这个了,既然可以推理,那就转换一波tensorrt看看。
onnx2trt weights/detr-r50_sim.onnx main ---------------------------------------------------------------- Input filename: weights/detr-r50_sim.onnx ONNX IR version: 0.0.6 Opset version: 12 Producer name: pytorch Producer version: 1.8 Domain: Model version: 0 Doc string: ---------------------------------------------------------------- Parsing model [2022-03-26 02:38:54 WARNING] onnx2trt_utils.cpp:364: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32. [2022-03-26 02:38:55 WARNING] Tensor DataType is determined at build time for tensors not marked as input or output. All done
可以转TensorRT!!
好了,万事具备,只需东风了。我们接着下一步。
DETR TensorRT推理
这个推理其实就很容易了,大家可以直接使用我之前案例的神力工具连,直接配置好config.yaml就可以直接推理。
INPUT: # input only for dynamic input, otherwise automatically read from trt engine # INPUT_WIDTH: 800 # INPUT_HEIGHT: 800 # INPUT_CHANNEL: 3 PREPROCESS_GPU: true # PREPROCESS_GPU: false TENSORRT: ENGINE_PATH: ./models/detr.trt ONNX_PATH: "" FP16: true INT8: false CALIBRATION_PATH: ./calibration_files TASK: SCORE_THRESH: 0.6 # NMS_THRESH: 0.6 # num queries in DETR OUTPUT_CANDIDATES: 100
然后命令行:
./build/examples/demo_detr configs/detr.yaml ~/data/road_demo.mp4
输出:

成功了!!!
终于可以实现DETR的TensorRT推理! 我大概测了一下速度,在1070 下,可以跑到30ms,速度已经很快了。根据YOLOv7作者说明,在2080上可以跑到10ms以内,如果fp16会更快,这个高精度的检测算法拿去部署他不香??
最后,本教程提到的所有代码和步骤,都可以在这些链接找到:
GitHub - jinfagang/yolov7: YOLO with Transformers and Instance Segmentation, with TensorRT acceleration!
MANA AI工具链详情