Mask R-CNN(2018-01)

introduction
Mask R-CNN用于instance segmentation ,由Faster R-CNN通过在每一个ROI(Region ofinterest)增加一个预测 mask的分支扩展而来,与用于分类和bounding box回归的现有分支并行。
扩展的mask分支用于像素到像素的分割,这个分支是一个小的FCN网络用于每一个RoI。Mask R-CNN基于Faster R-CNN的基础上进行训练和实现,增加了结构设计的灵活性,同时仅增加了一点计算开销就可以快速实验。
Faster R-CNN 原则上不适用于像素的分类,作者在RoIPool(instance相关的核心操作,执行粗糙的空间量化用于提取特征)的基础上提出了一个简单、无量化的层,称为RoIAlign,保留了提取空间位置信息的能力。
看起来是一个很小的改变,但是RoIAlign具有很大影响,首先它将mask的精度从10%提高到了50%,在严格本地化指标下游更明显地提升。其次,对于解耦mask于分类预测很有必要,作者为每一个类别独立地预测一个二元mask,类别之间没有竞争,而且依赖于网络的RoI分类分支去预测类别。相反,FCNs(FCN类型的网络)通常对每个像素进行多个类别分类,将分割和分类耦合在一起,基于实验观察,对于instance segmentation效果很差。
COCO数据集像素标注格式
coco数据集中实例分割的标注格式:逐像素分割,有两种标注方式:polygons & RLE
在json文件中的annotations字段是包含多个annotation实例的一个数组,annotation类型本身又包含了一系列的字段,如这个目标的category id和segmentation mask。segmentation格式取决于这个实例是一个单个的对象(即iscrowd=0,将使用polygons-多边形格式)还是一组对象(即iscrowd=1,将使用RLE格式-一种压缩方式)。
annotation{
"id": int,
"image_id": int, #图片id
"category_id": int, # 类别id,对应COCO 81个类中的一个
"segmentation": RLE or [polygon], # 目标的分割区域
"area": float, # 标注区域面积
"bbox": [x,y,width,height], #图片中目标的边框 ;注意这里给的是左上角坐标及宽度、高度,有时需要转化为左上角、右下角坐标
"iscrowd": 0 or 1, # 一个目标(0)还是多个目标(1)
}
annotations 中 segmentation 的格式取决于这个实例是单个对象还是一组对象。如果是单个对象,那么 iscrowd = 0,segmentation 使用 polygon 格式。但是这个对象可能被其他东西遮挡,导致分成了几个部分,此时需要用多个 polygon 来表示,所以 segmentation 其实是两层的列表。如果是一组对象,那么 iscrowd = 1,此时 semgentation 使用的就是 RLE 格式。
Polygon格式:
"segmentation": [ # 对象的轮廓点坐标
[
x1,y1,
x2,y2,
...
xn,yn
],
...
],
RLE格式
COCO数据集的RLE都是uncompressed RLE格式(与之相对的是compact RLE)。 RLE所占字节的大小和边界上的像素数量是正相关的。RLE格式带来的好处就是当基于RLE去计算目标区域的面积以及两个目标之间的unoin和intersection时会非常有效率。 上面的segmentation中的counts数组和size数组共同组成了这幅图片中的分割 mask。其中size是这幅图片的宽高,然后在这幅图像中,每一个像素点要么在被分割(标注)的目标区域中,要么在背景中。很明显这是一个bool量:如果该像素在目标区域中为true那么在背景中就是False;如果该像素在目标区域中为1那么在背景中就是0。对于一个240x320的图片来说,一共有76800个像素点,根据每一个像素点在不在目标区域中,我们就有了76800个bit,比如像这样(随便写的例子,和上文的数组没关系):00000111100111110…;但是这样写很明显浪费空间,我们直接写上0或者1的个数不就行了嘛(Run-length encoding),于是就成了54251…,这就是标注中的counts数组。
RLE计数位置上奇数位置总是0的个数,偶数位置总是1的个数。
segmentation :
{
u'counts': [272, 2, 4, 4, 4, 4, 2, 9, 1, 2, 16, 43, 143, 24......],
u'size': [240, 320]
}
Mask-R-CNN
Mask-RCNN采用同样的两阶段处理过程,第一个阶段同样是RPN(与Faster R-CNN 一致)。
第二个阶段除了预测分类和bounding box偏移量之外,mask rcnn为每一个RoI预测一个二进制掩码。这与最近流行的系统形成了对比,他们分类依据依赖于掩码的预测。作者的方法遵循Fast R-CNN的精神并行运行bounding-box分类和回归。
形式上,训练过程中,每个采样RoI上的多任务损失为: L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask,分类损失和回归损失与Fast R-CNN一致。每个RoI的mask分支有 K m 2 Km^2 Km2维输出,编码K(类别个数)个分辨率为 m ∗ m m*m m∗m(一张图像上逐像素用0、1标注出来物体还是背景)的二进制掩码,与K个类别一一对应。掩码损失 L m a s k L_{mask} Lmask是一个平均二元交叉熵,使用逐像素的sigmoid计算得到。
作者定义 L m a s k L_{mask} Lmask允许网络为每个类生成掩码,而不会产生类内竞争。论文依靠专用的分类分支来为选择的输出mask预测类别标签。Mask R-CNN解耦了掩码和类预测:它独立地为每个类预测一个二进制掩码,类之间没有竞争,并且依靠网络的 RoI 分类分支来预测类别。相比之下,FCN通常执行逐像素多类分类,它将分割和分类结合起来。
Network architecture
作者使用了两种backbone用来测试,使用ResNet或者ResNeXt50/101,原始的Faster R-CNN使用ResNet实现从第四阶段的最终卷积提取特征,作者称为C4.因此使用Resnet50就用Resnet50-C4表示。
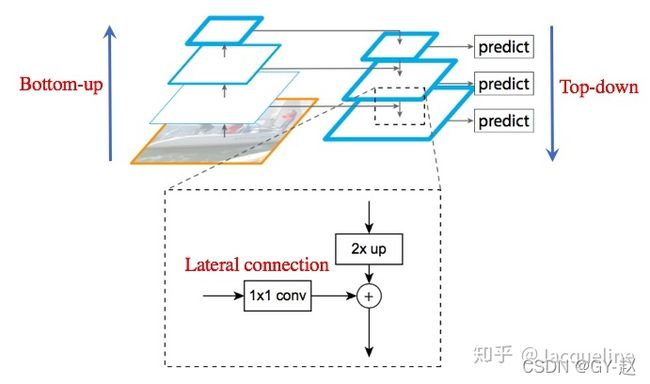
另一种就是使用FPN作为backbone,以FPN作为backbone的Faster R-CNN根据规模从不同层级的特征金字塔提取RoI特征。使用ResNet-FPN作为backbone的Mask R-CNN在精度和速度上都有了提升。
FPN就是在卷积的每一层得到的特征映射进行1X1将channel数变得与上层一样,然后逐元素相加进行特征融合,将底层特征与高层特征结合在一起。
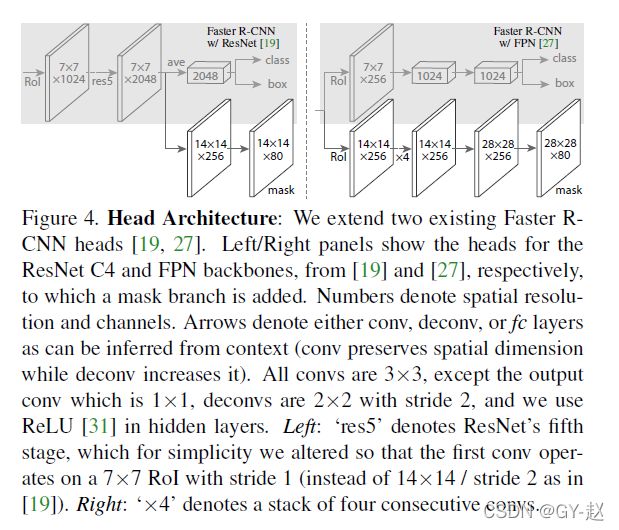
针对网络头,根据前边所述增加一个用于预测掩码的分支,如下图所示,扩展了两种heads,对应两种不同的backbone,图中数字表示空间分辨率与通道数,箭头表示卷积,反卷积、或全连接层(卷积保持空间维度,反卷积增加空间维度。)除了输出卷积是1X1,所有的卷积都是3X3,deconv是2X2,stride=2,隐藏层使用Relu。
左图中Res5表示ResNet第五阶段,为了简单起见,对其修改使第一个卷积操作在7X7的RoI上,stride=1. 右图中“X4”表示4个卷积层的堆叠。
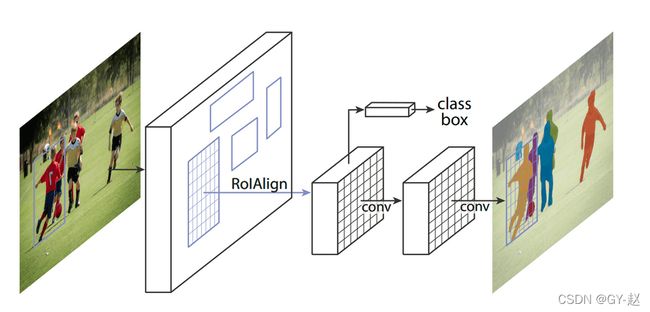
mask 表示
mask对目标得空间布局进行编码,不像class label 或box offsets 不可避免的被全连接层处理成简短的vectors。mask的空间结构可以使用pixel to pixel 对应关系(像素对齐)自然的使用掩码提取出来。Mask RCNN使用一个全卷积网络,对每个RoI预测K(类别数)个 m ∗ m m*m m∗m的掩码。这种像素到像素的操作,要求RoI特征(本身就是小尺寸特征图)很好的对齐,以显示的保持逐像素的空间对应关系。因此,作者提出了RoI Align层,在预测掩码的过程中起到重要作用。
RoI池化的作用是对每一个RoI提取小的特征映射,根据候选框的位置,将特征图中的对应区域池化为固定长度的特征图,以便进行后续的分类和box回归预测。由于候选框的位置通常是浮点数,而池化后的特征图要求尺寸固定,RoI池化这一操作存在两次量化的过程:一次是将候选框边界量化为整数点坐标(RoI池化操作时取整),还有一次把量化后的边界区域平均分割成KxK个单元,对每个单元的边界进行量化(获取固定尺寸特征映射,RoI等于只有一个空间池化的spp)。
经过两次量化操作,候选框的位置与开始有了一定偏移。这个偏移会影响检测或者分割的精度,称作“不对齐问题”
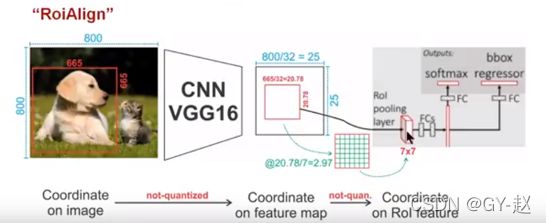
如下图所示,这是一个Faster-RCNN检测框架。输入一张800800的图片,图片上有一个665665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化77的大小,因此将上述包围框平均分割成77个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如下图)。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作,。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如 图3所示:
遍历每一个候选区域,保持浮点数边界不做量化。
将候选区域分割成k x k个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
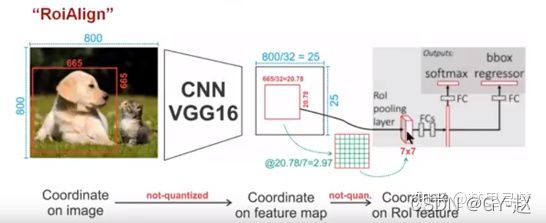
原图片中大小为665*665的候选区域映射到特征图中,大小为665/32X665/32=20.78X20.78.此时不需要像RoI池化那样进行取整操作,RoIAlign会保留20.78这个浮点数。同样采用7X7的特征图,将大小为20.78X20.78 的映射区域划分为49个相同大小的bin,每个bin的大小为20.78/7X20.78/7=2.97X2.97(这里同样不进行取整)。设置一个采样点数,对每个滨采用双线性插值法计算其中采样点的像素值,再进行最大池化操作,即可得到该单元的最终值。

这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点(如上图)。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。
RoI Align操作很大程度上解决了仅通过池化操作直接采样带来的对齐问题,也因此保留了大致的空间位置。使用RoIAlign层能够提高10%-50%的掩码精确度(accuracy),这种改进在更严格的定位度量指标下会有更好的结果。

训练
采用与Fast/Faster R-CNN 一致的超参数设置,如果RoI与gt-box的IoU大于等于0.5则认为是正样,否则为负样。mask 损失函数 L m a s k L_{mask} Lmask仅仅定义在正样本上,掩码目标是RoI与其关联的Ground Truth mask之间的交集。
采用以图像为中心的训练,图像调整短边大小为800pixels,每个GPU上每个mini_batch有2张图片,每张图片抽样N个RoIs,正负样本比例为1:3.对于C4 backbone来说N=64.在8张GPU上训练迭代160K次,学习率初始化为0.02在120K的时候减少10倍。使用Weight decay=0.0001,momentum=0.9。
RPN锚横跨5个尺寸和3个纵横比,为了简单,单独训练。
Reference
-
RoI Align https://blog.csdn.net/sxlsxl119/article/details/103433120
-
插值算法:https://zhuanlan.zhihu.com/p/110754637
-
https://zhuanlan.zhihu.com/p/73113289