机器学习笔记(一)——逻辑回归
逻辑回归
Hypothesis function 预测函数
h θ ( x ) = 1 1 + e − x ∗ θ T (1) h_{\theta}(x) = \frac{1}{1+e^{-\bold{x}*\theta^T}} \tag{1} hθ(x)=1+e−x∗θT1(1)
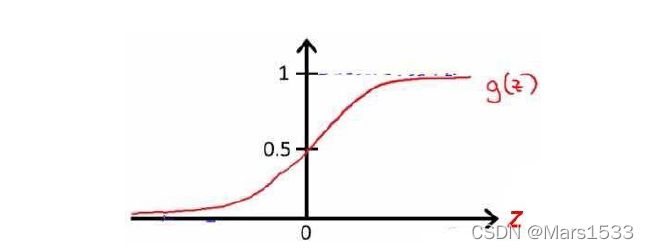
代价函数
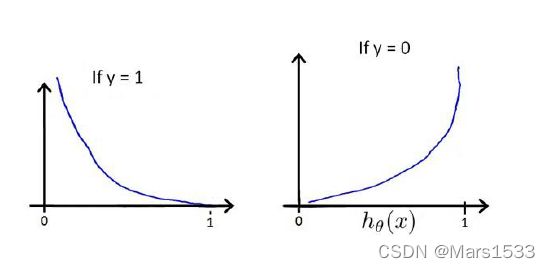
Cost ( h θ ( x ) , y ) = { − log ( h θ ( x ) ) if y = 1 − log ( 1 − h θ ( x ) ) if y = 0 (2) \operatorname{Cost}\left(h_{\theta}(x), y\right)=\left\{\begin{aligned} -\log \left(h_{\theta}(x)\right) & \text { if } y=1 \\ -\log \left(1-h_{\theta}(x)\right) & \text { if } y=0 \end{aligned}\right. \tag{2} Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x)) if y=1 if y=0(2)
Cost ( h θ ( x ) , y ) = − y × log ( h θ ( x ) ) − ( 1 − y ) × log ( 1 − h θ ( x ) ) (3) \operatorname{Cost}\left(h_{\theta}(x), y\right)=-y \times \log \left(h_{\theta}(x)\right)-(1-y) \times \log \left(1-h_{\theta}(x)\right) \tag{3} Cost(hθ(x),y)=−y×log(hθ(x))−(1−y)×log(1−hθ(x))(3)
\qquad 其图如下,也就是说当 y = 1 y=1 y=1时, h θ ( x ) h_{\theta}(x) hθ(x)越接近于1, C o s t Cost Cost越小。当 y = 0 y=0 y=0时, h θ ( x ) h_{\theta}(x) hθ(x)越接近于0, C o s t Cost Cost越小。换句话说,在使用这样的代价函数进行模型的训练时,会让 y = 0 y=0 y=0时的 h θ ( x ) h_\theta(x) hθ(x)趋于 0 0 0,会让 y = 1 y=1 y=1时的 h θ ( x ) h_\theta(x) hθ(x)趋于 1 1 1。也就是说,对于最终训练得到的模型, h θ ( x ) h_\theta(x) hθ(x)越大,表明它被判别为这一类的可能性越大。
\qquad 最终的代价函数定义为如下,其中m代表总的x的样本量。
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] (4) J(\theta)=\frac{1}{m} \sum_{i=1}^{m}\left[-y^{(i)} \log \left(h_{\theta}\left(x^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right] \tag{4} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))](4)
\qquad J ( θ ) J(\theta) J(θ)的偏导数的最终推导结果如下,其中i表示第i个数据,j表示该数据的第j维的值。
∂ ∂ θ j J ( θ ) = ∂ ∂ θ j [ − 1 m ∑ i = 1 m [ − y ( i ) log ( 1 + e − θ T x ( i ) ) − ( 1 − y ( i ) ) log ( 1 + e θ T x ( i ) ) ] ] = 1 m ∑ i = 1 m [ h θ ( x ( i ) ) − y ( i ) ] x j ( i ) (5) \begin{aligned} \frac{\partial}{\partial \theta_{j}} J(\theta)=&\frac{\partial}{\partial \theta_{j}}\left[-\frac{1}{m} \sum_{i=1}^{m}\left[-y^{(i)} \log \left(1+e^{-\theta^{T} x^{(i)}}\right)-\left(1-y^{(i)}\right) \log \left(1+e^{\theta^{T} x^{(i)}}\right)\right]\right]\\ =&\frac{1}{m} \sum_{i=1}^{m}\left[h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right] x_{j}^{(i)} \end{aligned} \tag{5} ∂θj∂J(θ)==∂θj∂[−m1i=1∑m[−y(i)log(1+e−θTx(i))−(1−y(i))log(1+eθTx(i))]]m1i=1∑m[hθ(x(i))−y(i)]xj(i)(5)
\qquad 对于正则化后的逻辑回归模型,定义公式如下。其中m仍然表示样本的总数,n表示 θ \theta θ的维度,需要注意的是 θ \bold{\theta} θ从 θ 1 \theta_1 θ1开始进行正则化。
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 (6) J(\theta)=\frac{1}{m} \sum_{i=1}^{m}\left[-y^{(i)} \log \left(h_{\theta}\left(x^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right]+\frac{\lambda}{2 m} \sum_{j=1}^{n} \theta_{j}^{2} \tag{6} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2(6)
梯度下降算法
\qquad 在编写代码时,提倡使用向量化的方法,将N个参数同时进行更新。要最小化代价函数,通过求导,得出的梯度下降算法如下,其中的i,j的定义与(6)式相同。
R e p e a t u n t i l c o n v e r g e n c e { θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x 0 ( i ) ) θ j : = θ j − α 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x j ( i ) + λ m θ j ) for j = 1 , 2 , … n } (7) \begin{aligned} Repeat \, until \, convergence\,\{ &\theta_{0}:=\theta_{0}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) \cdot x_{0}^{(i)}\right) \\ &\theta_{j}:=\theta_{j}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) \cdot x_{j}^{(i)}+\frac{\lambda}{m} \theta_{j}\right) \\ & \text { for } j=1,2, \ldots n \\ &\} \end{aligned} \tag{7} Repeatuntilconvergence{θ0:=θ0−αm1i=1∑m((hθ(x(i))−y(i))⋅x0(i))θj:=θj−αm1i=1∑m((hθ(x(i))−y(i))⋅xj(i)+mλθj) for j=1,2,…n}(7)
逻辑回归用于多分类问题
\qquad 对于逻辑回归用于多分类问题时,由于逻辑回归只能一次在2个类之间进行分类,因此我们需要多类分类的策略。每个分类器在“类别 i i i”和“不是 i i i”之间决定。我们将把分类器训练包含在一个函数中,该函数计算 N N N个分类器中的每个分类器的最终权重,得到最后的结果。
\qquad 例如:对于一个 N N N分类问题来说,我们要制定并训练出 N N N个分类器。也就是说,我们需要先将原样本的y标签变化为N份针对不同分类器的y标签。对于从 i = 1 , … , N i=1,\dots,N i=1,…,N类的y,我们都以 i i i为主体转化出N份的y标签,值只有1和0,他们分别对应是第 i i i类和不是第 i i i类。
\qquad 训练完成这 N N N个分类器,得到不同分类器下的 θ \theta θ值,并加他们都添加到 a l l _ t h e t a all\_theta all_theta当中。之后,我们就可以进行逻辑 N N N类回归预测。对于输入的样本值,我们要在 N N N个分类器中进行预测,最终最高 h θ ( x ) h_\theta(x) hθ(x)值对应的那一类就是我们最终预测的结果。
代码实例
\qquad 接下来,我将用逻辑回归来解决经典的MNIST手写数字识别问题,下面是它详细的代码介绍。
\qquad 首先载入数据集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
import numpy as np
# 逻辑回归做多类别预测
data = loadmat('ex3data1.mat')
print(data['X'].shape,data['y'].shape)
\qquad 定义sigmoid函数( h θ h_\theta hθ函数)和 C o s t Cost Cost函数:
#sigmoid 函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
#代价函数
def cost(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
#sigmoid函数里套 X * theta.T 就是 H函数 (5000,400) * (400,1)
#有关*的注释:
#a*b 如果a和b都是narray 且 规格相同,按普通乘法来,如果他们都是matrix,必须按矩阵乘法的规格来
#因此这里X是(5000,400) theta 则是(400,1) 相乘之后是 (5000,1)
#y标签里的值是1-10 10代表0
#np.multiply 两矩阵规格相同时,计算得到其内积
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
#len(X) 5000-也就是X的第一维的长度 这里表示5000 \theta 正则化前就是乘以1/2m
#theta[:,1:theta.shape[1]]表示从\theta1开始正则化, \theta0不参与正则化
reg = (learningRate / (2 * len(X))) * np.sum(np.power(theta[:,1:theta.shape[1]], 2))
return np.sum(first - second) / len(X) + reg #first - second 后要求sum
\qquad 举例非向量化用for循环求梯度:
def gradient_with_loop(theta, X, y, learningRate):
theta = np.matrix(theta)
#X 本身是(400,)的一个向量,我们要把它转为列向量(转换为矩阵,它就变成了(1,400)的列向量)
# 把一维的向量转换为列向量--->意味着把它转换为矩阵
X = np.matrix(X)
y = np.matrix(y)
#取[1] 也就是400
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
#(5000,400) * (400,1) ->(5000,1)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
# 在error外面乘x_j^i i是代表第几个X 因为这里是 np.multiply
# 这里 就是将上一步得到的error 每行和 X[,i]的每行相乘
# 与公式是一致的 至于这个代码里的i是指\theta 对应的i 也就是公式中的j 因为x是有400维的
# 公式当中x^(i)_{j} i 是指第几个数据 他都是400维 j是指400中的具体第几个维度
# 所以对于不同的\theta_{j} 它是对应不同维度(400)的x
# 这里的error (5000,1) X[:,i] 也是(5000,1) 它的每一行
# 5000行的每个值都是乘了5000个X的第i个 (5000,i) i代表\theta的下标
term = np.multiply(error, X[:, i])
if (i == 0):
grad[i] = np.sum(term) / len(X)
else:
grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[:, i])
return grad
\qquad 举例向量化的梯度函数:
\qquad 梯度函数是计算 θ \theta θ的梯度,它的大小与 θ \theta θ的大小是一样的(X的维度)。在进行梯度下降的时候是要把所有变量都要走一遍 所以要sum所有/m。我们看到动态的梯度/参数在变化是因为有大量的样本,一个样本是过一遍,而不是因为epoch的变化(不要混淆)。
#向量化的梯度函数
def gradient(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
# X * theta.T ->(5000,1) x^(i) 第 i个数据与 \theta向量相乘 theta.T是(400,1) \theta原来是(1,400)
error = sigmoid(X * theta.T) - y
#(400,5000) * (5000,1) -> (400,1) 第n个x 的error 乘以 第n个 x 的x_j^{i} 并加和 (1,400)
#X.T * error X是行向量,(400,5000) * (5000,1) -> (400,1) 转置 (1,400)
#grad也是(1,400)--->每个\theta的gradient嘛
grad = ((X.T * error) / len(X)).T + ((learningRate / len(X)) * theta)
#在进行梯度下降的时候是要把所有变量都要走一遍 所以要sum所有的/m
# intercept gradient is not regularized
# 特殊处理一下 拦截 (0,0) 也就是\theta 0
grad[0, 0] = np.sum(np.multiply(error, X[:, 0])) / len(X)
return np.array(grad).ravel()
\qquad 现在我们已经定义了代价函数和梯度函数,现在是构建分类器的时候了。对于这个任务,我们有 10 10 10个可能的类,并且由于逻辑回归只能一次在 2 2 2个类之间进行分类,我们需要多类分类的策略。在本练习中,我们的任务是实现一对一全分类方法,其中具有k个不同类的标签就有k个分类器,每个分类器在“类别 i i i”和“不是 i i i”之间决定。
\qquad 我们将把分类器训练包含在一个函数中,该函数计算 10 10 10个分类器中的每个分类器的最终权重,并将权重返回为 k ∗ ( n + 1 ) k*(n+1) k∗(n+1)数组,其中n是参数数量。 权重返回是 k ∗ ( n + 1 ) k*(n+1) k∗(n+1)规格。
\qquad 计算all_theta, 10 10 10个分类器的 θ \theta θ的结果如下:
\qquad 注意,minimize函数输入的参数,cost代价函数(要变小)和gradient(更新规则)都需要。
from scipy.optimize import minimize
def one_vs_all(X, y, num_labels, learning_rate):
rows = X.shape[0]
params = X.shape[1]
# k X (n + 1) array for the parameters of each of the k classifiers
# k个分类器 有k*(n+1)个权重
all_theta = np.zeros((num_labels, params + 1))
# insert a column of ones at the beginning for the intercept term
# 给X在最前面插入了一个 1 与 \theta_0相加->代表截距/常数项
X = np.insert(X, 0, values=np.ones(rows), axis=1)
# labels are 1-indexed instead of 0-indexed
# 1-10 对于5000个y里 如果它==i,就变1,!=i就变0
for i in range(1, num_labels + 1):
theta = np.zeros(params + 1)
# 意思就是:对于5000个不同类别的y 类别变成 第 i类和不是第i类
y_i = np.array([1 if label == i else 0 for label in y])
y_i = np.reshape(y_i, (rows, 1))
# minimize the objective function
fmin = minimize(fun=cost, x0=theta, args=(X, y_i, learning_rate), method='TNC', jac=gradient)
all_theta[i - 1, :] = fmin.x
# 第 i 种分类的 (n+1)个\theta值
return all_theta
\qquad 定义预测函数,对于这一步,我们将计算每个类的类概率,对于每个训练样本(使用当然的向量化代码),并将输出类标签为具有最高概率的类。
def predict_all(X, all_theta):
rows = X.shape[0]
params = X.shape[1]
num_labels = all_theta.shape[0]
# same as before, insert ones to match the shape
X = np.insert(X, 0, values=np.ones(rows), axis=1)
# convert to matrices
X = np.matrix(X)
all_theta = np.matrix(all_theta)
# compute the class probability for each class on each training instance
h = sigmoid(X * all_theta.T)
# 对于第i类来说,判断是第i类或者不是第i类,h(x)值越大,说明是第i类的可能性越大
# create array of the index with the maximum probability
h_argmax = np.argmax(h, axis=1)
# because our array was zero-indexed we need to add one for the true label prediction
h_argmax = h_argmax + 1
return h_argmax
\qquad 进行预测。这里需要注意的几点:首先,我们为 θ \theta θ添加了一个额外的参数(与训练数据一列),以计算截距项(常数项)。其次,我们将y从类标签转换为每个分类器的二进制值(要么是 i i i类,要么不是 i i i类)。最后,我们使用SciPy的较新优化API来最小化每个分类器的代价函数。 如果指定的话,API将采用目标函数,初始参数集,优化方法和jacobian(渐变)函数。然后将优化程序找到的参数分配给参数数组。
\qquad 实现向量化代码的一个更具挑战性的部分是正确地写入所有的矩阵,保证维度正确。注意, θ \theta θ是一维数组,因此当它被转换为计算梯度的代码中的矩阵时,它变为 ( 1 × 401 ) (1×401) (1×401)矩阵。我们还检查y中的类标签,以确保它们看起来与想象的一致。
all_theta = one_vs_all(data['X'], data['y'], 10, 1)
y_pred = predict_all(data['X'], all_theta)
correct = [1 if a == b else 0 for (a, b) in zip(y_pred, data['y'])]
accuracy = (sum(map(int, correct)) / float(len(correct)))
print ('accuracy = {0}%'.format(accuracy * 100))
\qquad 最终,使用逻辑回归完成MNIST分类达到的准确度为:94.46%。