python 期末复习笔记(持续更新)
文章目录
- 1、set
- 2、union
- 3、axis=0 与 axis=1
- 4、ascending=False 与 reverse=False
- 5、set_index和reset_index
- 6、json自定义函数提取数据
- 7、apply 与lambda
- 8、join
- 9、append
- 10、merge
- 11、combine_first
- 12、concatenate
- 13、concat
- 14、groupby
- 15、values()与itervalues()
- 16、value_counts
- 17、sort 与sort_values
- 18、open
- 19、read_cav与to_csv
- 20、remove
- 21、series
- 22、DF的表头columns和index
- 23、字典
- 24、字典函数values(),keys(),items()
- 25、切片loc和iloc
- 26、DataFrame
- 27、shape与reshape
- 28、替换函数strip(),replace(),sub()
- 29、toarray
- 30、unique
- 31、isnull和notnull
- 32、rename
- 33、linespace
- 34、日期转换
- 35、lambda 匿名函数
- 36、正则表达式
- 29、column_stack与hstack、vstack
- 30、contains
- 31、split
- 32、np.repeat
- 33、期末考会考题
- 34、Sklearn的train_test_split用法
- 34、过拟合与欠拟合
- 35、oversample 过采样和欠采样undersampling
- 36、分类阈值
- 37、超参数
- 38、随机森林
- 39、 cut和qcut的用法(分桶分箱)
- 40、随机森林 n_estimators参数 max_features参数
- 41、VarianceThreshold
- 42、fit_transform,fit,transform区别和作用
- 43、特征预处理的独热编码
- 44、ravel和flattern
1、set
set 是一个不允许内容重复的组合,而且set里的内容位置是随意的,所以不能用索引列出。可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。

创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。

2、union
union 取并集,效果等同于 | ,重复元素只会出现一次,但是括号里可以是 list,tuple, 甚至是 dict
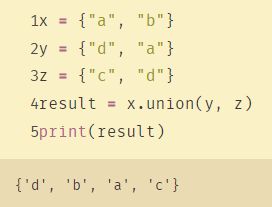
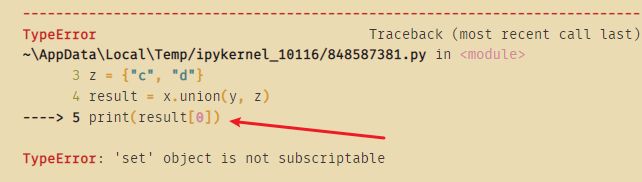
同样uninon也不能用索引列出:
#TypeError: 'set' object is not subscriptable
#表示把不具有下标操作的集合对象用成了对象[i]
genres_list=set() # 获取所有的电影风格
for i in moviesdf['genresls'].str.split(' '):
genres_list=set().union(i,genres_list)
# 集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合。
genres_list=list(genres_list)
genres_list
genres_list.remove('') # 去除空的元素
print(genres_list)
得到的结果:所有电影风格类型
['Movie', 'Documentary', 'Comedy', 'Crime', 'Fantasy', 'History', 'Drama', 'Horror', 'Action', 'War', 'Foreign', 'Thriller', 'Fiction', 'Animation', 'Science', 'Music', 'Western', 'Romance', 'Family', 'TV', 'Mystery', 'Adventure']
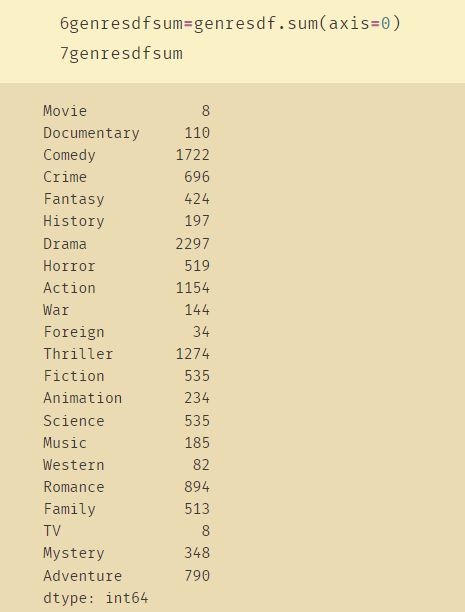
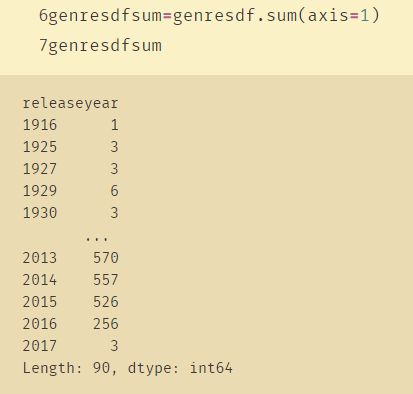
3、axis=0 与 axis=1
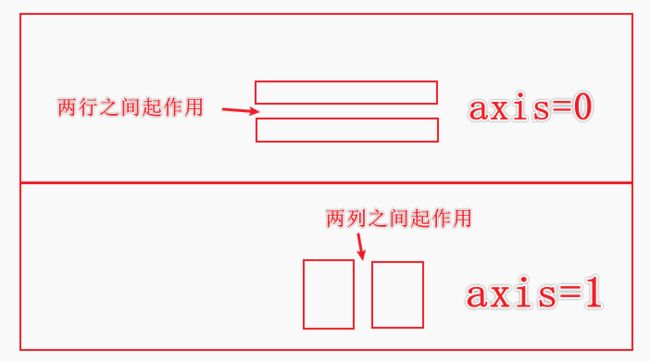
例子一:

例子二: 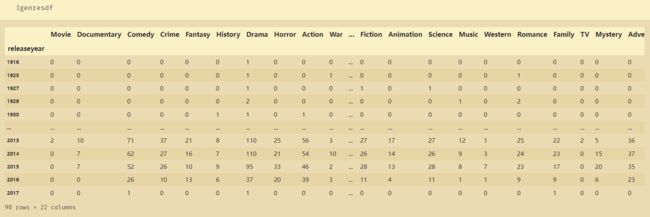
4、ascending=False 与 reverse=False
ascending与reverse刚好是相反的
ascending=False:降序
ascending=True:升序
reverse=False:升序
reverse=True:降序

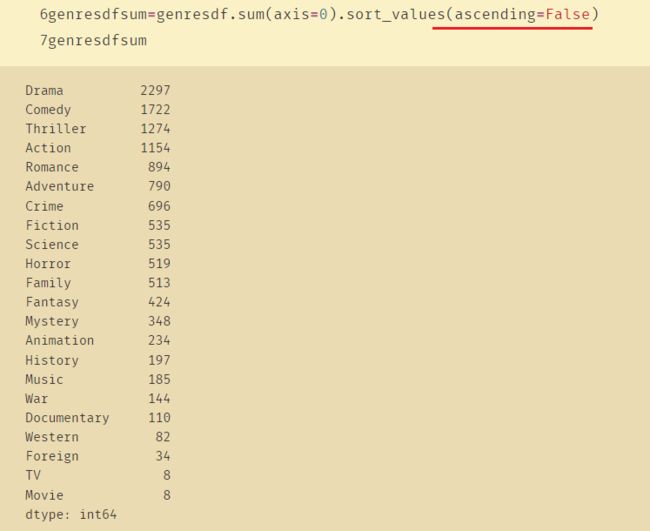


5、set_index和reset_index
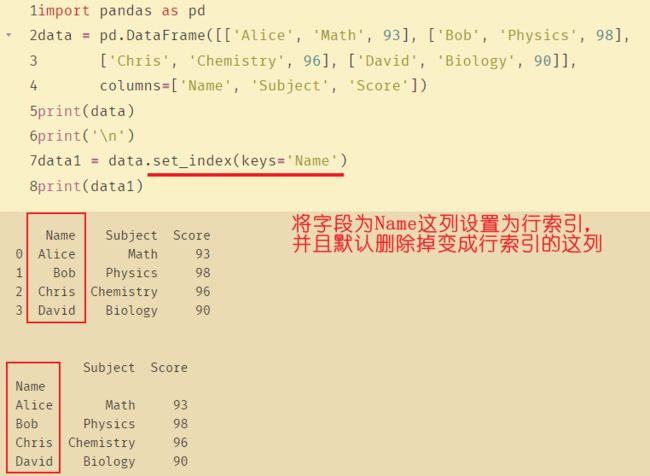
set_index( ) 将 DataFrame 中的指定的列转化为行索引。
- set_index( ) 将 DataFrame 中的列转化为行索引。
- keys : 要设置为索引的列名(如有多个应放在一个列表里)
- drop : 将设置为索引的列删除,默认为True
- append : 是否将新的索引追加到原索引后(即是否保留原索引),默认为False
- inplace : 是否在原DataFrame上修改,默认为False
- verify_integrity : 是否检查索引有无重复,默认为False
import pandas as pd
data = pd.DataFrame([['Alice', 'Math', 93], ['Bob', 'Physics', 98], ['Chris', 'Chemistry', 96], ['David', 'Biology', 90]],
columns=['Name', 'Subject', 'Score'])
print(data)
print('\n')
data1 = data.set_index(keys='Name')
print(data1)
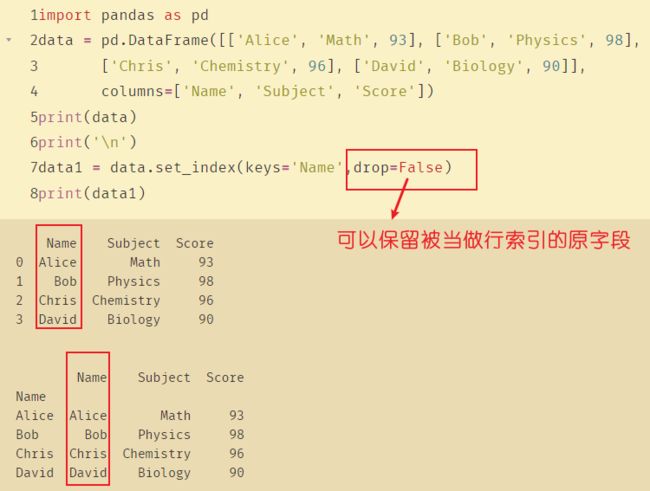
reset_index可以还原索引,从新变为默认的整型索引
6、json自定义函数提取数据
#对于json格式的数据进行分割提取,通过自定义函数
def decode(column):
z=[]
for i in column:
z.append(i['name'])
return ' '.join(z)
# 获取dict中第一个元素的name值
def decode1(column):
z=[]
for i in column:
z.append(i['name'])
return ''.join(z[0:1]) #切片,只输出第一个分隔
# 获取演员列表,中间使用逗号分隔
def decodeactors(column):
z=[]
for i in column:
z.append(i['name'])
return ','.join(z) #切片,只输出第一个分隔
# 获取演员列表的前两位
def decode2(column):
z=[]
for i in column:
z.append(i['name'])
return ','.join(z[0:2]) #切片,只输出第一个分隔
# 获取电影风格数据
moviesdf['genresls']=moviesdf['genreslist'].apply(decode)
# 获取演员列表
moviesdf['actorsls']=moviesdf['castlist'].apply(decodeactors)
# 获取前两位演员
moviesdf['actorsn0102']=moviesdf['castlist'].apply(decode2)
# 获取第一位演员
moviesdf['actorsn01']=moviesdf['castlist'].apply(decode1)
# 获取制片的第一个国家或者地区
moviesdf['region']=moviesdf['countries'].apply(decode1)
7、apply 与lambda
apply通常与lambda一起使用
lambda原型为:lambda 参数:操作(参数)
lambda函数也叫匿名函数,即没有具体名称的函数,它允许快速定义单行函数,可以用在任何需要函数的地方。这区别于def定义的函数。
lambda与def的区别:
1)def创建的方法是有名称的,而lambda没有。
2)lambda会返回一个函数对象,但这个对象不会赋给一个标识符,而def则会把函数对象赋值给一个变量(函数名)。
3)lambda只是一个表达式,而def则是一个语句。
4)lambda表达式后面,只能有一个表达式,def则可以有多个。
5)像if或for或print等语句不能用于lambda中,def可以。
6)lambda一般用来定义简单的函数,而def可以定义复杂的函数。
#单个参数的:
g = lambda x : x ** 2
print g(3)
"""
9
"""
#多个参数的:
g = lambda x, y, z : (x + y) ** z
print g(1,2,2)
"""
9
"""
例子二:
# 将一个 list 里的每个元素都平方:
map( lambda x: x*x, [y for y in range(10)] )
这个写法要好过:
def sq(x):
return x * x
map(sq, [y for y in range(10)])
8、join
9、append
10、merge
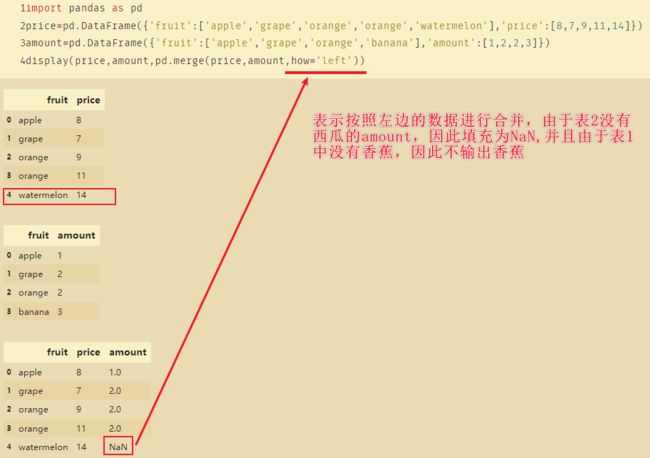
pandas.merge的报错:MergeError: No common columns to perform merge on.
原因:没有共同的列来进行融合,则会报错
因为merge函数默认需要提供相同的列来进行融合,如果没有的话可以通过设置left_index和right_index=True来融合所有的列
解决:指定让两个df的索引相同来进行融合df.merge(s,left_index=True,right_index=True)
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
left:拼接的左侧DataFrame对象right:拼接的右侧DataFrame对象on:用于连接的列名。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。left_on:左侧DataFrame中用于连接键的列。right_on:左侧DataFrame中用于连接键的列。left_index:左侧DataFrame中行索引作为连接键right_index:右侧DataFrame中行索引作为连接键how:有五种参数(inner,left,right,outer,cross) 默认inner。inner是取交集,outer取并集。left是包含左边的全部数据,如果右边没有相应的数据则使用NAN填充。right是包含右边的全部数据,如果左边没有则使用NAN值填充。cross表示将左右两个DataFrame进行笛卡尔积。两个数据框的数据交叉匹配,行数为两者相乘,列数为两者相加。sort:按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。suffixes:修改重复列名。(可指定我们自己想要的后缀)
import pandas as pd
price=pd.DataFrame({'fruit':['apple','grape','orange','orange'],'price':[8,7,9,11]})
amount=pd.DataFrame({'fruit':['apple','grape','orange','banana'],'amount':[1,2,2,3]})
display(price,amount,pd.merge(price,amount))

pd.merge(price,amount)等价于pd.merge(price,amount,on='fruit',how='inner')

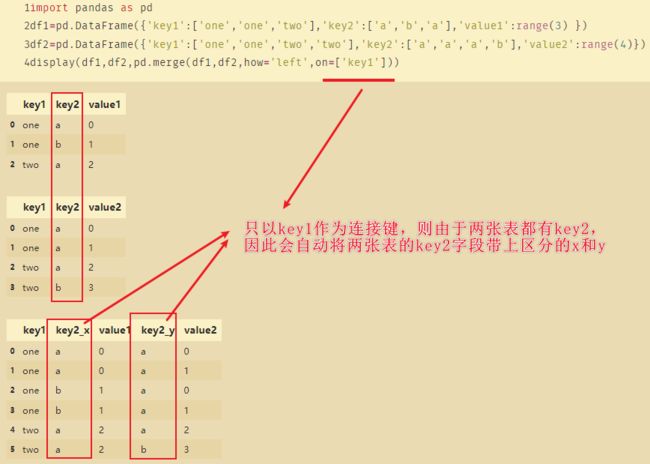
import pandas as pd
df1=pd.DataFrame({'name1':['小1','小2','小3','小4'],'age':[25,28,39,35]})
df2=pd.DataFrame({'name2':['小1','小2','小4'],'score':[70,60,90]})
display(df1,df2,pd.merge(df1,df2))
上面这段代码报错:
原因在于df1使用的是name1,df2使用的是name2。两张表当中没有相同的字段。这种情况下就必须指定left_on,和right_on。
MergeError: No common columns to perform merge on. Merge options: left_on=None, right_on=None, left_index=False, right_index=False




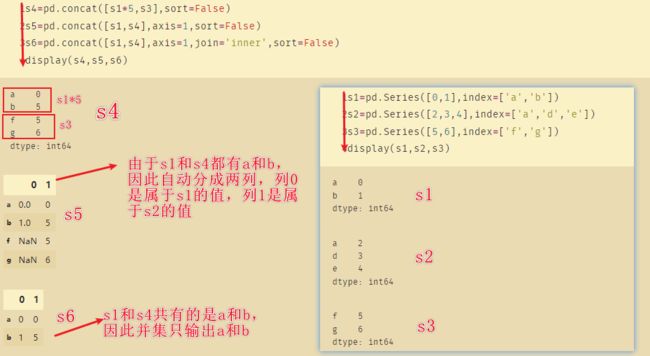
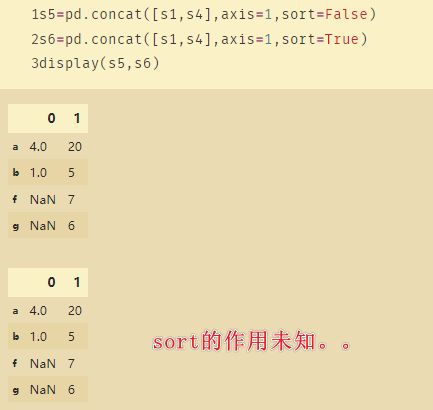
11、combine_first

如上图是S5和S6,两者存在重复的索引f和g,此时使用merge和concat都无法正确的合并,因此使用combine_first。


如上图combine_first可以去除重复的索引值,原因在于s5.combine_first(s6)表示的是使用s6去填充s5的缺失值。
12、concatenate
numpy提供了numpy.concatenate((a1,a2,…), axis=0)函数。能够一次完成多个数组的拼接。其中a1,a2,…是数组类型的参数
>>> a=np.array([1,2,3])
>>> b=np.array([11,22,33])
>>> c=np.array([44,55,66])
>>> np.concatenate((a,b,c),axis=0) # 默认情况下,axis=0可以不写
array([ 1, 2, 3, 11, 22, 33, 44, 55, 66]) #对于一维数组拼接,axis的值不影响最后的结果
>>> a=np.array([[1,2,3],[4,5,6]])
>>> b=np.array([[11,21,31],[7,8,9]])
>>> np.concatenate((a,b),axis=0)
array([[ 1, 2, 3],
[ 4, 5, 6],
[11, 21, 31],
[ 7, 8, 9]])
>>> np.concatenate((a,b),axis=1) #axis=1表示对应行的数组进行拼接
array([[ 1, 2, 3, 11, 21, 31],
[ 4, 5, 6, 7, 8, 9]])
numpy.append()和numpy.concatenate()相比,concatenate()效率更高,适合大规模的数据拼接
13、concat
如果要合并的DataFrame之间没有连接键,就无法使用merge方法,此时可以使用concat方法,把两个完全无关的数据拼起来。
concat方法相当于数据库中的全连接(UNION ALL),可以指定按某个轴进行连接,也可以指定连接的方式join(outer,inner 只有这两种)。
与数据库不同的是concat不会去重,要达到去重的效果可以使用drop_duplicates方法

concat(
objs, axis=0, join='outer', join_axes=None,
ignore_index=False, keys=None, levels=None, names=None,
verify_integrity=False, copy=True
)
df1 = DataFrame({'a1': ['Chicago', 'San Francisco', 'New York City'], 'rank': range(1, 4)})
df2 = DataFrame({'a2': ['Chicago', 'Boston', 'Los Angeles'], 'rank': [1, 4, 5]})
pd.concat([df1,df2])
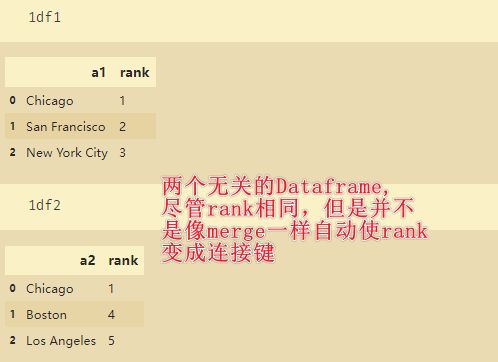

从上面的结果可以看出,concat的连接方式是外连接(并集),通过传入join=‘inner’可以实现内连接。

winedf=pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
14、groupby
groupby:可以根据索引或字段对数据进行分组。
DataFrame.groupby(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=False)
| by | 可以传入函数、字典、Series等,用于确定分组的依据 |
|---|---|
| axis | 接收int,表示操作的轴方向,默认为0 |
| level | 接收int或索引名,代表标签所在级别,默认为None |
| as_index | 接收boolean,表示聚合后的聚合标签是否以 DataFrame索引输出 |
| sort | 接收boolean,表示对分组依据和分组标签排序,默认为True |
| group_keys | 接收boolean,表示是否显示分组标签的名称,默认为True |
| squeeze | 接收boolean ,表示是否在允许情况下对返回数据降维,默认为False |
对于by,如果传入的是一个函数,则对索引进行计算并分组;如果传入的是字典或者Series,则用字典或者Series的值作为分组的依据;如果传入的是numpy数组,则用数据元素作为分组依据‘如果传入的是字符串或者字符串列表,则用这些字符串所代表的字段作为分组依据。


15、values()与itervalues()
1、values():
python内置的values()函数返回一个字典中所有的值。
即只返回{key0:value0,key1:value1}中的value0、value1……
并且重复值都会返回
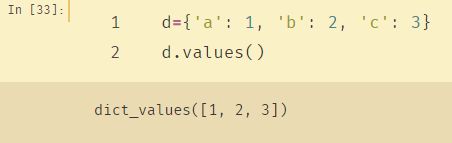
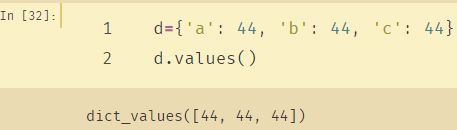
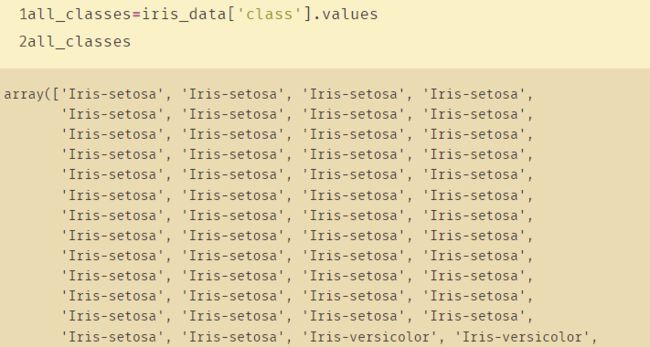
- values() 方法把一个 dict 转换成了包含 value 的list。
- itervalues() 方法不会转换,它会在迭代过程中依次从 dict 中取出 value,所以 itervalues() 方法比 values() 方法节省了生成 list 所需的内存。
- 打印 itervalues() 发现它返回一个对象,这说明在Python中,for 循环可作用的迭代对象远不止 list,tuple,str,unicode,dict等,任何可迭代对象都可以作用于for循环,而内部如何迭代我们通常并不用关心。

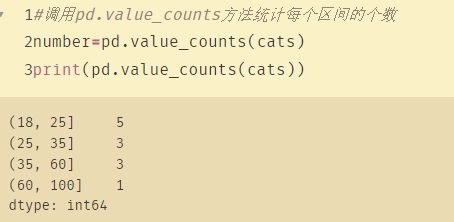
16、value_counts
pandas 的value_counts()函数可以对Series里面的每个值进行计数并且排序。
如果我们想知道,每个区域出现了多少次,可以简单如下:

每个区域都被计数,并且默认从最高到最低做降序排列。
如果想用升序排列,可以加参数ascending=True:

如果想得出的计数占比,可以加参数normalize=True:

空值是默认剔除掉的。value_counts()返回的结果是一个Series数组,可以跟别的数组进行运算。
例子二:结合分桶函数cut
ages = [20,22,25,27,21,23,37,31,61,45,41,32]
#将所有的ages进行分组
bins = [18,25,35,60,100]
#使用pandas中的cut对年龄数据进行分组
cats = pd.cut(ages,bins)
print(cats)

#调用pd.value_counts方法统计每个区间的个数
number=pd.value_counts(cats)
print(pd.value_counts(cats))

17、sort 与sort_values
sorted(iterable[, cmp[, key[, reverse]]])
iterable.sort(cmp[, key[, reverse]])
参数解释:
(1)iterable指定要排序的list或者iterable,不用多说;
(2)cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数,如:
students为类对象的list,每个成员有三个域,用sorted进行比较时可以自己定cmp函数,例如这里要通过比较第三个数据成员来排序,代码可以这样写:
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda student : student[2])

(3)key为函数,指定取待排序元素的哪一项进行排序,函数用上面的例子来说明,代码如下:
sorted(students, key=lambda student : student[2])
key指定的lambda函数功能是去元素student的第三个域(即:student[2]),因此sorted排序时,会以students所有元素的第三个域来进行排序。

18、open
open(file, mode='r')
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型


19、read_cav与to_csv
-
read_csv
-
to_csv
【1】获取当前工作路径
import os
os.getcwd() # 获取当前工作路径

【2】to_csv()是DataFrame类的方法,read_csv()是pandas的方法
dt.to_csv() #默认dt是DataFrame的一个实例,参数解释如下
【3】路径 path_or_buf: A string path to the file to write or a StringIO
dt.to_csv('Result.csv') #相对位置,保存在getwcd()获得的路径下
dt.to_csv('C:/Users/think/Desktop/Result.csv') #绝对位置
【4】分隔符 sep : Field delimiter for the output file (default ”,”)
dt.to_csv('C:/Users/think/Desktop/Result.csv',sep='?')#使用?分隔需要保存的数据,如果不写,默认是,
【5】替换空值 na_rep: A string representation of a missing value (default ‘’)
dt.to_csv('C:/Users/think/Desktop/Result1.csv',na_rep='NA') #缺失值保存为NA,如果不写,默认是空
【6】格式 float_format: Format string for floating point numbers
dt.to_csv('C:/Users/think/Desktop/Result1.csv',float_format='%.2f') #保留两位小数
【7】保存某列数据 cols: Columns to write (default None)
dt.to_csv('C:/Users/think/Desktop/Result.csv',columns=['name']) #保存索引列和name列
【8】是否保留列名 header: Whether to write out the column names (default True)
dt.to_csv('C:/Users/think/Desktop/Result.csv',header=0) #不保存列名
【9】是否保留行索引 index: whether to write row (index) names (default True)
dt.to_csv('C:/Users/think/Desktop/Result1.csv',index=0) #不保存行索引
20、remove
21、series
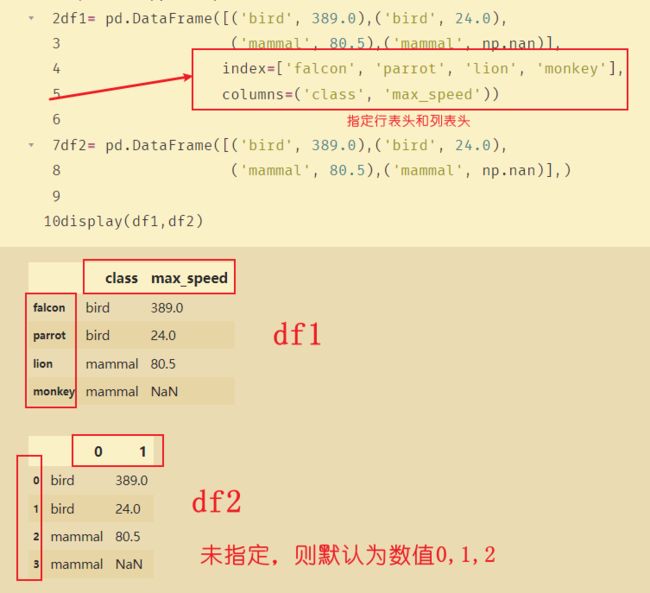
22、DF的表头columns和index
对于DataFrame表格来说,dataframe.columns返回的是横向的表头,dataframe.index返回的是纵向的表头
import numpy as np
df1= pd.DataFrame([('bird', 389.0),('bird', 24.0),
('mammal', 80.5),('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
df2= pd.DataFrame([('bird', 389.0),('bird', 24.0),
('mammal', 80.5),('mammal', np.nan)],)
display(df1,df2)
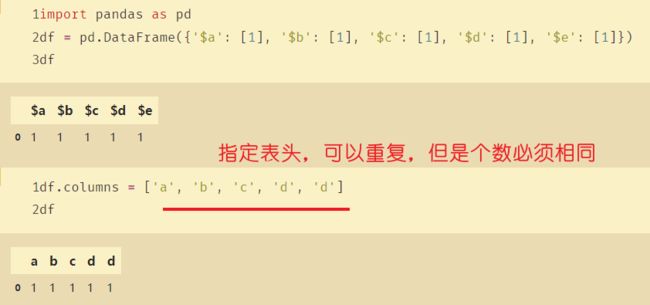
用columns修改列名:
import pandas as pd
df = pd.DataFrame({'$a': [1], '$b': [1], '$c': [1], '$d': [1], '$e': [1]})
df.columns = ['a', 'b', 'c', 'd', 'e']
改变Dataframe一列当中的列名:
# (作业:分类型数据类型转换成int型)
lidf23=lidf23.astype({'评价':'int'})

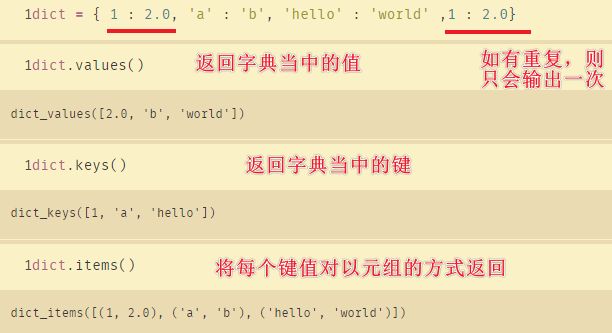
23、字典
24、字典函数values(),keys(),items()
- values()函数:返回一个字典中所有的值。即只返回{key0:value0,key1:value1}中的value0、value1。
- keys()函数:以列表形式(并非直接的列表,若要返回列表值还需调用list函数)返回字典中的所有的键。
- items()函数:是可以将字典中的所有项,以列表方式返回。因为字典是无序的,所以用items方法返回字典的所有项,也是没有顺序的。
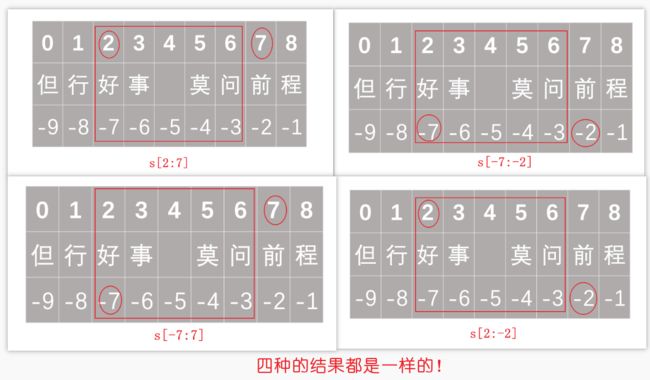
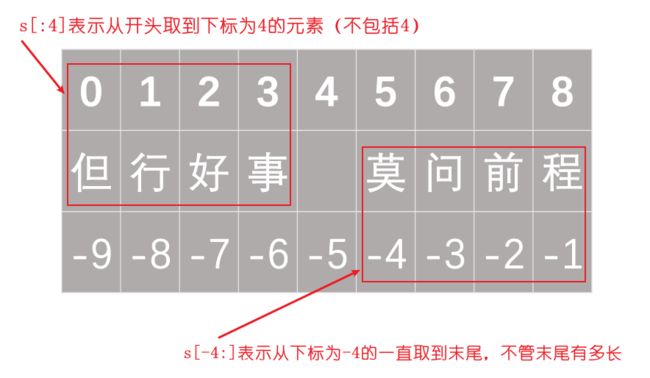
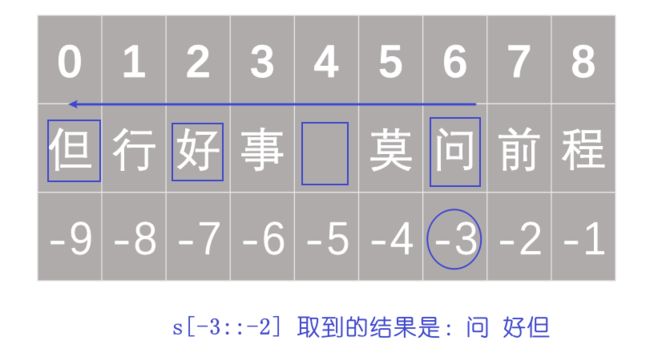
25、切片loc和iloc

正下标从0开始,负下标从-1开始1。切片的时候包括头不包括尾部。





lypdfdata=lypdf.iloc[:,1:-1].values
lypdftarget=lypdf.iloc[:,:-1].values
# 逗号前面是属于行,后面是属于列


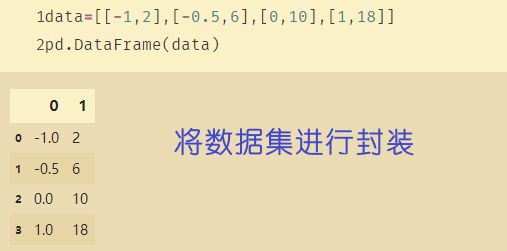
26、DataFrame
data=[[-1,2],[-0.5,6],[0,10],[1,18]]
python读取DataFrame的某几列(根据列名)
import pandas as pd
data=pd.read_csv("titanic.csv")
data1=data[['Age','Sex','Embarked','Survived']]
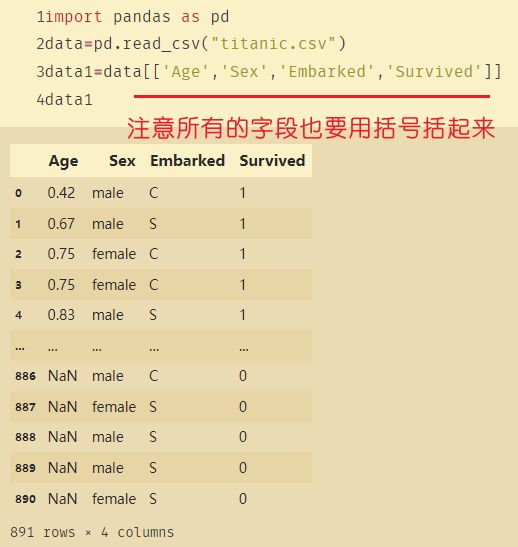
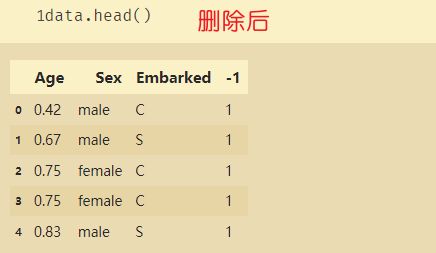
DF删除特定的一列:
data.loc[:,-1]=label
data.head()
data.drop(['Survived'],axis=1,inplace=True)

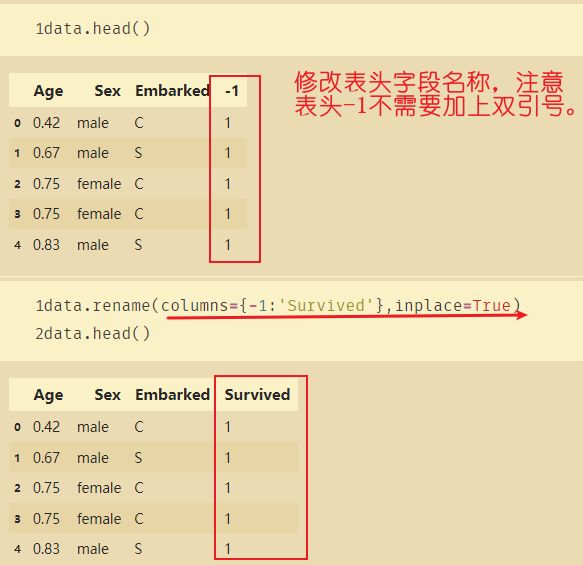
DF修改表头的名字,使用rename:
data.rename(columns={'-1':'Survived'})
27、shape与reshape
shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵或者数组的维数,比如shape[0]就是读取矩阵第一维度的长度。
例如:建立一个4×2的矩阵c, c.shape[0] 为第二维的长度,c.shape[1] 为第二维的长度。
c = array([[1,1],[1,2],[1,3],[1,4]])
c.shape

reshape()是数组对象中的方法,用于改变数组的形状。
# 使用众数填充Embarked,但是Embarked默认是字符型
Embarked=data.loc[:,'Embarked'].values.reshape(-1,1) # 变成二维矩阵
Embarked.shape

!!!!!!!!!!!!!!!
在机器学习中的reshape的作用:
sklearn不接受任何一维矩阵作为特征矩阵被输入。如果你的数据的确只有一个特征,那必须用reshape(-1,1)来给矩阵增维;如果你的数据只有一个特征和一个样本,使用reshape(1,-1)来给你的数据增维。
28、替换函数strip(),replace(),sub()
- replace是用在将查询到的数据替换为指定数据。
Python replace()方法把字符串Q中的old (l旧字符串)替换成new(新字符串),如果指定第三个参数max,则替换不超过max次。
语法:
str.replace(old, new, max)

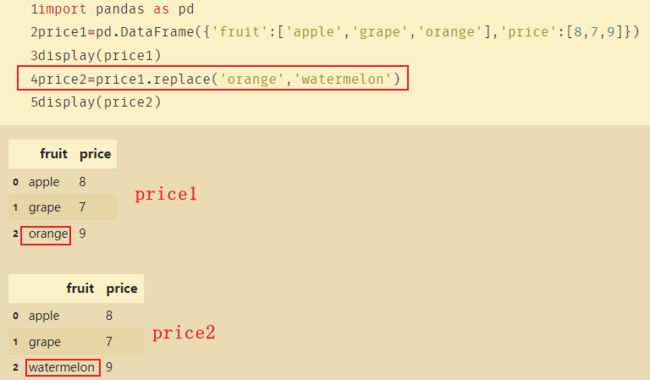
在DF中也可以使用:
import pandas as pd
price1=pd.DataFrame({'fruit':['apple','grape','orange'],'price':[8,7,9]})
display(price1)
price2=price1.replace('orange','watermelon')
display(price2)
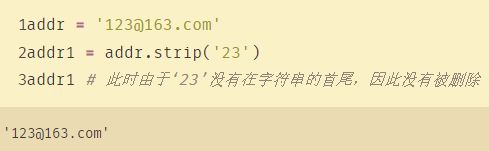
2. Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
str.strip([chars]);
参数:
chars – 移除字符串头尾指定的字符序列。
如果不带参数,默认是清除两边的空白符,例如:/n, /r, /t, ’ ’


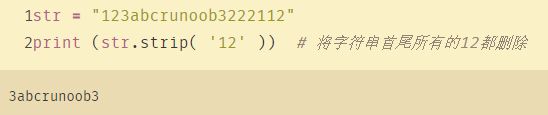
当你传的参数不管是“12”还是12的其他排列形式,这都不重要,重要的是函数只知道你要删除的字符是”1”,”2”。函数会把你传的参数拆解成一个个的字符,然后把头尾的这些字符去掉。
29、toarray
30、unique
31、isnull和notnull
32、rename
33、linespace
生成x1与x2之间的n维等距行向量,即将[x1,x2]进行n-1等分
b = linspace(0,10,4)
b =
0 3.3333 6.6667 10.0000
34、日期转换
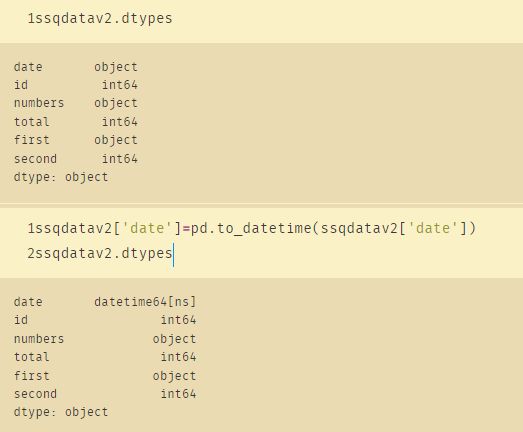
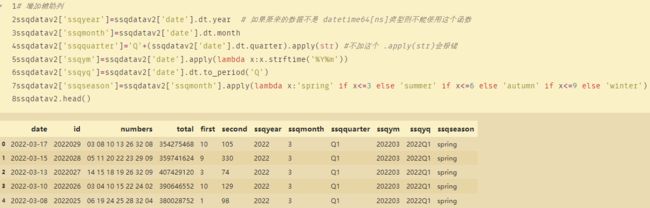
# 增加辅助列
ssqdatav2['ssqyear']=ssqdatav2['date'].dt.year # 如果原来的数据不是 datetime64[ns]类型则不能使用这个函数
ssqdatav2['ssqmonth']=ssqdatav2['date'].dt.month
ssqdatav2['ssqquarter']='Q'+(ssqdatav2['date'].dt.quarter).apply(str) #不加这个 .apply(str)会报错
ssqdatav2['ssqym']=ssqdatav2['date'].apply(lambda x:x.strftime('%Y%m'))
ssqdatav2['ssqyq']=ssqdatav2['date'].dt.to_period('Q')
ssqdatav2['ssqseason']=ssqdatav2['ssqmonth'].apply(lambda x:'spring' if x<=3 else 'summer' if x<=6 else 'autumn' if x<=9 else 'winter')
ssqdatav2.head()
35、lambda 匿名函数
36、正则表达式
1、findall:
含义: findall()是将所有匹配到的字符,以列表的形式返回。如果未匹配,则返回空列表。
语法: findall(string=None, pos=0, endpos=9223372036854775807, *, source=None)
函数作用:在string[pos,endpos]区间从pos下标开始查找所有满足pattern的子串,直到endpos位置结束,并以列表的形式返回查找的结果,如果未找到则返回一个空列表。
参数说明:
- string:被匹配的字符串
- pos: 匹配的起始位置,可选,默认为0
- endpos: 匹配的结束位置,可选,默认为len(string)。也就是说如果不指定pos和endpos的话,该方法会在整个字符串中查找满足条件的子串。

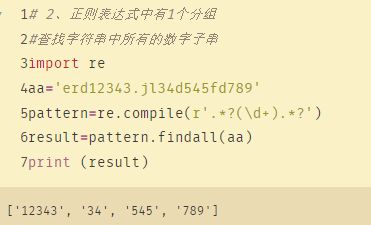

2、re.compile():
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
re.compile(pattern[, flag])
从compile()函数的定义中,可以看出返回的是一个匹配对象,它单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。 compile()与findall()一起使用,返回一个列表。
其中,pattern 是一个字符串形式的正则表达式,flag 是一个可选参数,表示匹配模式,比如忽略大小写,多行模式等。
29、column_stack与hstack、vstack
对于一维数组的堆叠:
(1)column_stack()会将一位数组转化成二维数组后再进行堆叠;
(2)hstack()不会进行转化,而是直接进行堆叠,所得到的堆叠后的数组还是一维数组。
另一方面,row_stack()和stack()不会产生这样的问题,他们的结果都是二维数组。

30、contains
cond=ssqdatav2['first'].str.contains('深圳')
ssqdatav2.loc[cond] # 查找出first字段下所有包含深圳的记录,并准备将深圳用深或圳进行替换
ssqdatav2['first']
31、split
String a="a:b:c:d"
split(" : “)[0]表示把指定的字符串按照”:"来拆分成字符串数组.结果是:{a,b,c,d}
[0]是拆分出来的数组第一个元素了。
ssqdatav3['p001']=ssqdatav3['fpprovince'].apply(lambda x:x if x.count(',')==0 else x.split(',')[0])
ssqdatav3['p002']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[1] if x.count(',')>=1 else '')
ssqdatav3['p003']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[2] if x.count(',')>=2 else '')
ssqdatav3['p004']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[3] if x.count(',')>=3 else '')
ssqdatav3['p005']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[4] if x.count(',')>=4 else '')

32、np.repeat
np.repeat用于将numpy数组重复
一维数组重复三次
import numpy as np
# 随机生成[0,5)之间的数,形状为(1,4),将此数组重复3次
pop = np.random.randint(0, 5, size=(1, 4)).repeat(3, axis=0)
print("pop\n",pop)
# pop
# [[0 0 3 1]
# [0 0 3 1]
# [0 0 3 1]]
二维数组在第一维和第二维分别重复三次
pop_reshape=pop.reshape(2,6)
pop_reshape_repeataxis0=pop_reshape.repeat(3,axis=0)
pop_reshape_repeataxis1=pop_reshape.repeat(3,axis=1)
print("pop_reshape\n",pop_reshape)
print("pop_reshape_repeataxis0\n",pop_reshape_repeataxis0)
print("pop_reshape_repeataxis1\n",pop_reshape_repeataxis1)
# pop_reshape
# [[0 0 3 1 0 0]
# [3 1 0 0 3 1]]
# pop_reshape_repeataxis0
# [[0 0 3 1 0 0]
# [0 0 3 1 0 0]
# [0 0 3 1 0 0]
# [3 1 0 0 3 1]
# [3 1 0 0 3 1]
# [3 1 0 0 3 1]]
# pop_reshape_repeataxis1
# [[0 0 0 0 0 0 3 3 3 1 1 1 0 0 0 0 0 0]
# [3 3 3 1 1 1 0 0 0 0 0 0 3 3 3 1 1 1]]
33、期末考会考题
过滤法也是重点
简答题:特征工程主要的任务有哪些?
双色球是考试的重点,一定要把双色球所有的特征都跑一遍,期末一定有一道特征工程选择的题目(10分,代码填充),(特征工程选择的题目,代码填充)
这三句话相同,都是去除掉省份当中包含深的字
ssqdataprov=ssqdataprov[(ssqdataprov['PROVINCE']!='深')]
ssqdataprov=ssqdataprov[~(ssqdataprov['PROVINCE']=='深')]
ssqdataprov=ssqdataprov[~(ssqdataprov['PROVINCE'].str.contains('深'))]
【1】改变决策树的参数绘制学习曲线
# 使用学习曲线判断最佳的最小叶子节点样本个数
# 选取的最小样本从1到30
import matplotlib.pyplot as plt
plt.figure(figsize=(15,8))
test = []
for i in range(30):
clf = tree.DecisionTreeClassifier(min_samples_leaf=i+1 #1-10层
,criterion="entropy" # 使用gini系数
,random_state=30
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #分别计算测试集上的表现
test.append(score)
plt.plot(range(1,31),test,color="red",label="min_samples_leaf")
plt.legend()
plt.show()

【2】class_weight是权重:简答题
【3】min_weight_fraction_leaf:基于权重的剪枝参数
【4】数据模型有那四种?层次,网状,关系,面向对象
34、Sklearn的train_test_split用法
用途:
在机器学习中,该函数可按照用户设定的比例,随机将样本集合划分为训练集 和测试集,并返回划分好的训练集和测试集数据。
语法:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(X,y,test_size, random_state)
参数说明:
| Code | Text |
|---|---|
| X | 待划分的样本特征集合 |
| y | 待划分的样本标签 |
| test_size | 若在0~1之间,为测试集样本数目与原始样本数目之比;若为整数,则是测试集样本的数目。 |
| random_state | 随机数种子 |
| X_train | 划分出的训练集数据(返回值) |
| X_test | 划分出的测试集数据(返回值) |
| y_train | 划分出的训练集标签(返回值) |
| y_test | 划分出的测试集标签(返回值) |
| 例子: |
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
test_size=0.2:表示将20%的数据作为测试集,剩余的80%作为训练集
34、过拟合与欠拟合
无论在机器学习还是深度学习建模当中都可能会遇到两种最常见结果,一种叫过拟合(over-fitting )另外一种叫欠拟合(under-fitting)。

-
过拟合(over-fitting),其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。打个比喻就是当我需要建立好一个模型之后,比如是识别一只狗狗的模型,我需要对这个模型进行训练。恰好,我训练样本中的所有训练图片都是二哈,那么经过多次迭代训练之后,模型训练好了,并且在训练集中表现得很好。基本上二哈身上的所有特点都涵括进去,那么问题来了!假如我的测试样本是一只金毛呢?将一只金毛的测试样本放进这个识别狗狗的模型中,很有可能模型最后输出的结果就是金毛不是一条狗(因为这个模型基本上是按照二哈的特征去打造的)。所以这样就造成了模型过拟合,虽然在训练集上表现得很好,但是在测试集中表现得恰好相反,在性能的角度上讲就是协方差过大(variance is large),同样在测试集上的损失函数(cost function)会表现得很大。 -
欠拟合呢(under-fitting)相对过拟合欠拟合还是比较容易理解。还是拿刚才的模型来说,可能二哈被提取的特征比较少,导致训练出来的模型不能很好地匹配,表现得很差,甚至二哈都无法识别。
造成过拟合的原因有可以归结为:参数过多。增大训练样本规模同样也可以防止过拟合。
欠拟合基本上都会发生在训练刚开始的时候,经过不断训练之后欠拟合应该不怎么考虑了。但是如果真的还是存在的话,可以通过增加网络复杂度或者在模型中增加多点特征点,这些都是很好解决欠拟合的方法。
35、oversample 过采样和欠采样undersampling
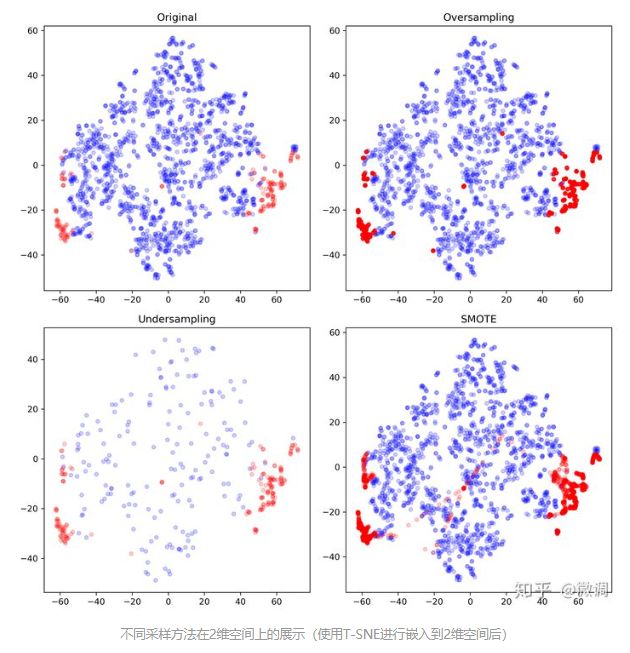
-
过采样(右上)只是单纯的重复了正例,因此会过分强调已有的正例。如果其中部分点标记错误或者是噪音,那么错误也容易被成倍的放大。因此最大的风险就是对正例过拟合。 -
欠采样(左下)抛弃了大部分反例数据,从而弱化了中间部分反例的影响,可能会造成偏差很大的模型。当然,如果数据不平衡但两个类别基数都很大,或许影响不大。同时,数据总是宝贵的,抛弃数据是很奢侈的,因此另一种常见的做法是反复做欠采样,生成1655/176约等于9个新的子样本。其中每个样本的正例都使用这176个数据,而反例则从1655个数据中不重复采样。最终对这9个样本分别训练,并集成结果。这样数据达到了有效利用,但也存在风险;
- 训练多个模型造成了过大的开销,合并模型结果需要额外步骤,有可能造成其他错误。
- 正例被反复使用,和过采样一样,很容易造成模型的过拟合
36、分类阈值
逻辑回归返回的是概率。可以“原样”使用返回的概率(例如,用户点击此广告的概率为 0.00023),也可以将返回的概率转换成二元值(例如,这封电子邮件是垃圾邮件)。
如果某个逻辑回归模型对某封电子邮件进行预测时返回的概率为 0.9995,则表示该模型预测这封邮件非常可能是垃圾邮件。相反,在同一个逻辑回归模型中预测分数为 0.0003 的另一封电子邮件很可能不是垃圾邮件。可如果某封电子邮件的预测分数为 0.6 呢?为了将逻辑回归值映射到二元类别,必须指定分类阈值(也称为判定阈值)。如果值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此必须对其进行调整。
我们将在后面的部分中详细介绍可用于对分类模型的预测进行评估的指标,以及更改分类阈值对这些预测的影响。
“调整”逻辑回归的阈值不同于调整学习速率等超参数。在选择阈值时,需要评估将因犯错而承担多大的后果。例如,将非垃圾邮件误标记为垃圾邮件会非常糟糕。
37、超参数
什么是超参数,参数和超参数的区别?
区分两者最大的一点就是是否通过数据来进行调整,模型参数通常是有数据来驱动调整,超参数则不需要数据来驱动,而是在训练前或者训练中人为的进行调整的参数。例如卷积核的具体核参数就是指模型参数,这是有数据驱动的。而学习率则是人为来进行调整的超参数。这里需要注意的是,通常情况下卷积核数量、卷积核尺寸这些也是超参数,注意与卷积核的核参数区分。
38、随机森林
随机森林是一个用随机方式建立的,包含多个决策树的分类器。其输出的类别是由各个树输出的类别的众数而定。
随机性主要体现在两个方面:
(1)训练每棵树时,从全部训练样本(样本数为N)中选取一个可能有重复的大小同样为N的数据集进行训练(即bootstrap取样);
(2)在每个节点,随机选取所有特征的一个子集,用来计算最佳分割方式。
优点
1、 在当前的很多数据集上,相对其他算法有着很大的优势,表现良好
2、它能够处理很高维度(feature很多)的数据,并且不用做特征选择(因为特征子集是随机选择的)
3、在训练完后,它能够给出哪些feature比较重要
4、在创建随机森林的时候,对generlization error使用的是无偏估计,模型泛化能力强
5、训练速度快,容易做成并行化方法(训练时树与树之间是相互独立的)
6、 在训练过程中,能够检测到feature间的互相影响
7、 实现比较简单
8、 对于不平衡的数据集来说,它可以平衡误差。
9、如果有很大一部分的特征遗失,仍可以维持准确度。
10、随机森林能够解决分类与回归两种类型的问题,并在这两方面都有相当好的估计表现。(虽然RF能做回归问题,但通常都用RF来解决分类问题)。
在创建随机森林时候,对generlization error(泛化误差)使用的是无偏估计模型,泛化能力强。
缺点:
随机森林在解决回归问题时,并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续的输出。当进行回归时,随机森林不能够做出超越训练集数据范围的预测,这可能导致在某些特定噪声的数据进行建模时出现过度拟合。(PS:随机森林已经被证明在某些噪音较大的分类或者回归问题上回过拟合)。
对于许多统计建模者来说,随机森林给人的感觉就像一个黑盒子,你无法控制模型内部的运行。只能在不同的参数和随机种子之间进行尝试。
可能有很多相似的决策树,掩盖了真实的结果。
对于小数据或者低维数据(特征较少的数据),可能不能产生很好的分类。(处理高维数据,处理特征遗失数据,处理不平衡数据是随机森林的长处)。
执行数据虽然比boosting等快(随机森林属于bagging),但比单只决策树慢多了。
39、 cut和qcut的用法(分桶分箱)
数据分箱:是指将值划分到离散区间。好比不同大小的苹果归类到几个事先布置的箱子中;不同年龄的人划分到几个年龄段中。
一丶cut qcut的区别
1.qcut:传入参数,要将数据分成多少组,即组的个数,具体的组距是由代码计算。
2,cut:传入参数,是分组依据。
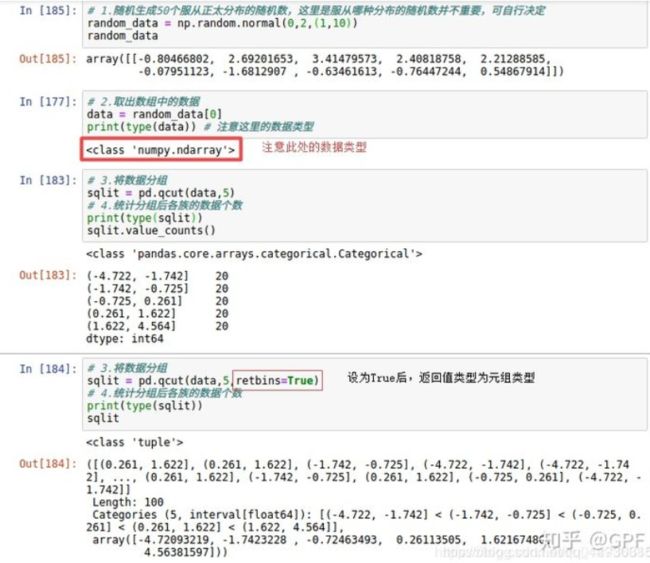
二丶qcut方法
(1)参数:
x :要进行分组的数据,数据类型为一维数组,或Series对象;
q :组数,即要将数据分成几组,后边举例说明;
labels :可以理解为组标签,这里注意标签个数要和组数相等;
retbins :默认为False,当为False时,返回值是Categorical类型(具有value_counts()方法),为True是返回值是元组。
(2)示例
三丶cut方法
(1)举例
ages = [20,22,25,27,21,23,37,31,61,45,41,32]
#将所有的ages进行分组
bins = [18,25,35,60,100] # 自定义分类数据,包括端点
#使用pandas中的cut对年龄数据进行分组
cats = pd.cut(ages,bins)
print(cats)

#调用pd.value_counts方法统计每个区间的个数
number=pd.value_counts(cats)
print(pd.value_counts(cats))
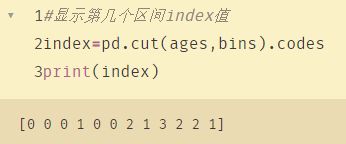
#显示第几个区间index值
index=pd.cut(ages,bins).codes
print(index)
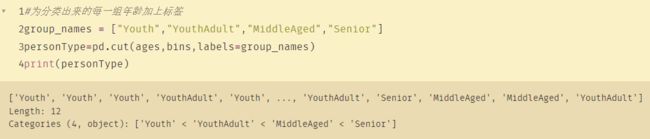
#为分类出来的每一组年龄加上标签
group_names = ["Youth","YouthAdult","MiddleAged","Senior"]
personType=pd.cut(ages,bins,labels=group_names)
print(personType)
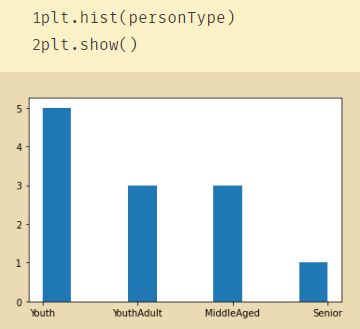
plt.hist(personType)
plt.show()

四丶总结
1,cut: 按连续数据的大小分到各个桶里,每个桶里样本量可能不同,但是,每个桶相当于一个等长的区间,即:以数据的最大和最小为边界,等分成p个桶。
2,qcut: 与cut主要的区别就是每个桶里的样本数量是一定的。

40、随机森林 n_estimators参数 max_features参数
要构造一个随机森林模型,第一步是确定森林中树的数目,通过模型的 进行调节。n_estimators越大越好,但占用的内存与训练和预测的时间也会相应增长,且边际效益是递减的,所以要在可承受的内存/时间内选取尽可能大的n_estimators。而在sklearn中,n_estimators默认为10。
第二步是对数据进行自助采样,也就是说,从n_sample个数据点中有放回地重复随机抽取一个样本,共抽取n_sample次。新数据集的容量与原数据集相等,但抽取的采样往往与原数据集不同。注意,构建的n_estimators棵树采用的数据集都是独立自助采样的,这样才能保证所有树都互不相同。
第三步就是基于这个新数据集来构造决策树。由于加入了随机性,故构造时与一般的决策树不同。构造时,在每个结点处选取特征的一个子集,并对其中一个特征寻找最佳测试。选取的特征子集中特征的个数通过max_features参数来控制,max_features越小,随机森林中的树就越不相同,但过小(取1时)会导致在划分时无法选择对哪个特征进行测试。而在sklearn中,max_features有以下几种选取方法:“auto”, “sqrt”, “log2”, None。auto与sqrt都是取特征总数的开方,log2取特征总数的对数,None则是令max_features直接等于特征总数,而max_features的默认值是"auto"。
随机森林还有一个重要参数是n_jobs,决定了使用的CPU内核个数,使用更多的内核能使速度增快,而令n_jobs=-1可以调用所有内核。当然,构造时同样可以使用max_depth,min_samples_leaf和max_leaf_nodes来进行预剪枝,以减小内存占用与时间消耗。