PyTorch 实现CycleGAN 风格迁移
目录
一、前言
二、数据集
三、网络结构
四、代码
(一)net
(二)train
(三)test
五、结果
(一)loss
(二)训练可视化
(三)测试结果
六、完整代码
一、前言
pix2pix对训练样本要求较高,需要成对的数据集,而这种样本的获取往往需要耗费很大精力。CycleGAN恰巧解决了该问题,实现两个domain之间的转换,即只需要准备两种风格的数据集,让GAN去学习将domain X中的图片转换成domain Y的风格(不改变domain X原图中物体,仅仅实现风格转换)。
一种直观的思路是直接让G去学习domain X 到domain Y 以及domain Y 到domain X的映射关系,但这种方式会造成G生成图片的随机性太强,会使得生成的图片与输入的图片完全不相关,不仅违背了CycleGAN的目的,同时输出的结果也没有任何意义。
作者认为这种转换应该具有循环一致性,比如在语言翻译中,把一段话从中文翻译成英文,再从英文翻译回中文,意思应该是相近的,CycleGAN就是采用了这种思想。假设Ga表示Domain X到Domain Y的生成器,Gb表示Domain Y 到Domain X 的生成器,那么让Domain X中的图片real_A通过Ga后生成的图片fake_A再通过Gb生成的rec_A应该和A是高度相似的,Domain Y到Domain X同理。
CycleGAN中有两个生成器以及两个判别器,分别对应Domain X 到Domain Y 以及Domain Y到Domain X。
二、数据集
这里我采用的是monet2photo数据集(莫奈画->真实风景照片),部分数据如下图所示。
Domain X(monet):

Domain Y(photo):
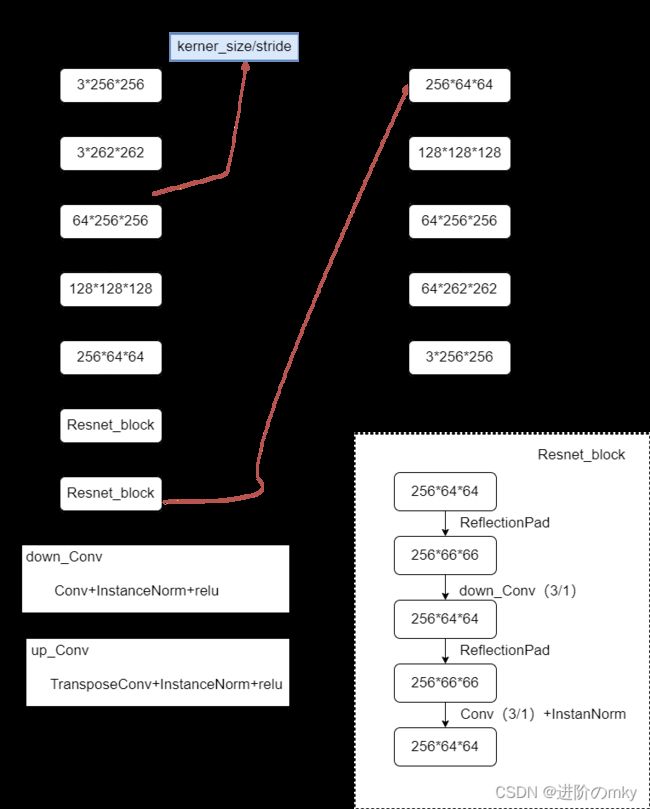
三、网络结构
生成器G的结构如下图所示,判别器D与pix2pix相同,网络结构pix2pix。
四、代码
(一)net
初始化方式与源码不同。
import torch.nn as nn
from torchsummary import summary
from collections import OrderedDict
# 定义残差块
class Resnet_block(nn.Module):
def __init__(self, in_channels):
super(Resnet_block, self).__init__()
block = []
for i in range(2):
block += [nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, 3, 1, 0),
nn.InstanceNorm2d(in_channels),
nn.ReLU(True) if i > 0 else nn.Identity()]
self.block = nn.Sequential(*block)
def forward(self, x):
out = x + self.block(x)
return out
class Cycle_Gan_G(nn.Module):
def __init__(self):
super(Cycle_Gan_G, self).__init__()
net_dic = OrderedDict()
# 三层卷积层
net_dic.update({'first layer': nn.Sequential(
nn.ReflectionPad2d(3), # [3,256,256] -> [3,262,262]
nn.Conv2d(3, 64, 7, 1), # [3,262,262] ->[64,256,256]
nn.InstanceNorm2d(64),
nn.ReLU(True)
)})
net_dic.update({'second_conv': nn.Sequential(
nn.Conv2d(64, 128, 3, 2, 1), # [128,128,128]
nn.InstanceNorm2d(128),
nn.ReLU(True)
)})
net_dic.update({'three_conv': nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1), # [256,64,64]
nn.InstanceNorm2d(256),
nn.ReLU(True)
)})
# 9层 resnet block
for i in range(6):
net_dic.update({'Resnet_block{}'.format(i + 1): Resnet_block(256)})
# up_sample
net_dic.update({'up_sample1': nn.Sequential(
nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(128), # [128,128,128]
nn.ReLU(True)
)})
net_dic.update({'up_sample2': nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(64), # [64,256,256]
nn.ReLU(True)
)})
net_dic.update({'last_layer': nn.Sequential(
nn.ReflectionPad2d(3),
nn.Conv2d(64, 3, 7, 1),
nn.Tanh()
)})
self.net_G = nn.Sequential(net_dic)
self.init_weight()
def init_weight(self):
for w in self.modules():
if isinstance(w, nn.Conv2d):
nn.init.kaiming_normal_(w.weight, mode='fan_out')
if w.bias is not None:
nn.init.zeros_(w.bias)
elif isinstance(w, nn.ConvTranspose2d):
nn.init.kaiming_normal_(w.weight, mode='fan_in')
elif isinstance(w, nn.BatchNorm2d):
nn.init.ones_(w.weight)
nn.init.zeros_(w.bias)
def forward(self, x):
out = self.net_G(x)
return out
class Cycle_Gan_D(nn.Module):
def __init__(self):
super(Cycle_Gan_D, self).__init__()
# 定义基本的卷积\bn\relu
def base_Conv_bn_lkrl(in_channels, out_channels, stride):
if in_channels == 3:
bn = nn.Identity
else:
bn = nn.InstanceNorm2d
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 4, stride, 1),
bn(out_channels),
nn.LeakyReLU(0.2, True)
)
D_dic = OrderedDict()
in_channels = 3
out_channels = 64
for i in range(4):
if i < 3:
D_dic.update({'layer_{}'.format(i + 1): base_Conv_bn_lkrl(in_channels, out_channels, 2)})
else:
D_dic.update({'layer_{}'.format(i + 1): base_Conv_bn_lkrl(in_channels, out_channels, 1)})
in_channels = out_channels
out_channels *= 2
D_dic.update({'last_layer': nn.Conv2d(512, 1, 4, 1, 1)}) # [batch,1,30,30]
self.D_model = nn.Sequential(D_dic)
def forward(self, x):
return self.D_model(x)
if __name__ == '__main__':
# G = Cycle_Gan_G().to('cuda')
# summary(G, (3, 256, 256))
D = Cycle_Gan_D().to('cuda')
summary(D, (3, 256, 256))
(二)train
训练过程中有一些小细节,为了减小模型振荡,提高训练的稳定性,论文中采用了buffer来暂存G生成的图片,用之前生成的图片来更新判别器。G共包含三种损失(两个方向共6部分),GAN_loss、Cycle_loss、id_loss。其中,GAN_loss就是传统GAN的loss,使得输出图片尽可能真,Cycle_loss是重建的图片与原始图片之间的L1损失,id_loss是为了保证G不去随意改变图片的色调(即便判别器告诉你另外一种色调也服从Domain Y的分布,但为了仅仅改变风格不改变别的因素,因此引入了该损失)。判别器D仍然采用了PatchGAN,训练过程与pix2pix类似。
import itertools
from image_pool import ImagePool
from torch.utils.tensorboard import SummaryWriter
from cyclegan import Cycle_Gan_G, Cycle_Gan_D
import argparse
from mydatasets import CreateDatasets
import os
from torch.utils.data.dataloader import DataLoader
import torch
import torch.optim as optim
import torch.nn as nn
from utils import train_one_epoch, val
def train(opt):
batch = opt.batch
data_path = opt.dataPath
print_every = opt.every
device = 'cuda' if torch.cuda.is_available() else 'cpu'
epochs = opt.epoch
img_size = opt.imgsize
if not os.path.exists(opt.savePath):
os.mkdir(opt.savePath)
# 加载数据集
train_datasets = CreateDatasets(data_path, img_size, mode='train')
val_datasets = CreateDatasets(data_path, img_size, mode='test')
train_loader = DataLoader(dataset=train_datasets, batch_size=batch, shuffle=True, num_workers=opt.numworker,
drop_last=True)
val_loader = DataLoader(dataset=val_datasets, batch_size=batch, shuffle=True, num_workers=opt.numworker,
drop_last=True)
# 实例化网络
Cycle_G_A = Cycle_Gan_G().to(device)
Cycle_D_A = Cycle_Gan_D().to(device)
Cycle_G_B = Cycle_Gan_G().to(device)
Cycle_D_B = Cycle_Gan_D().to(device)
# 定义优化器和损失函数
optim_G = optim.Adam(itertools.chain(Cycle_G_A.parameters(), Cycle_G_B.parameters()), lr=0.0002, betas=(0.5, 0.999))
optim_D = optim.Adam(itertools.chain(Cycle_D_A.parameters(), Cycle_D_B.parameters()), lr=0.0002, betas=(0.5, 0.999))
loss = nn.MSELoss()
l1_loss = nn.L1Loss()
start_epoch = 0
A_fake_pool = ImagePool(50)
B_fake_pool = ImagePool(50)
# 加载预训练权重
if opt.weight != '':
ckpt = torch.load(opt.weight)
Cycle_G_A.load_state_dict(ckpt['Ga_model'], strict=False)
Cycle_G_B.load_state_dict(ckpt['Gb_model'], strict=False)
Cycle_D_A.load_state_dict(ckpt['Da_model'], strict=False)
Cycle_D_B.load_state_dict(ckpt['Db_model'], strict=False)
start_epoch = ckpt['epoch'] + 1
writer = SummaryWriter('train_logs')
# 开始训练
for epoch in range(start_epoch, epochs):
loss_mG, loss_mD = train_one_epoch(Ga=Cycle_G_A, Da=Cycle_D_A, Gb=Cycle_G_B, Db=Cycle_D_B,
train_loader=train_loader,
optim_G=optim_G, optim_D=optim_D, writer=writer, loss=loss, device=device,
plot_every=print_every, epoch=epoch, l1_loss=l1_loss,
A_fake_pool=A_fake_pool, B_fake_pool=B_fake_pool)
writer.add_scalars(main_tag='train_loss', tag_scalar_dict={
'loss_G': loss_mG,
'loss_D': loss_mD
}, global_step=epoch)
# 保存模型
torch.save({
'Ga_model': Cycle_G_A.state_dict(),
'Gb_model': Cycle_G_B.state_dict(),
'Da_model': Cycle_D_A.state_dict(),
'Db_model': Cycle_D_B.state_dict(),
'epoch': epoch
}, './weights/cycle_monent2photo.pth')
# 验证集
val(Ga=Cycle_G_A, Da=Cycle_D_A, Gb=Cycle_G_B, Db=Cycle_D_B, val_loader=val_loader, loss=loss, l1_loss=l1_loss,
device=device, epoch=epoch)
def cfg():
parse = argparse.ArgumentParser()
parse.add_argument('--batch', type=int, default=1)
parse.add_argument('--epoch', type=int, default=100)
parse.add_argument('--imgsize', type=int, default=256)
parse.add_argument('--dataPath', type=str, default='../monet2photo', help='data root path')
parse.add_argument('--weight', type=str, default='', help='load pre train weight')
parse.add_argument('--savePath', type=str, default='./weights', help='weight save path')
parse.add_argument('--numworker', type=int, default=4)
parse.add_argument('--every', type=int, default=20, help='plot train result every * iters')
opt = parse.parse_args()
return opt
if __name__ == '__main__':
opt = cfg()
print(opt)
train(opt)
import torchvision
from tqdm import tqdm
import torch
import os
def train_one_epoch(Ga, Da, Gb, Db, train_loader, optim_G, optim_D, writer, loss, device, plot_every, epoch, l1_loss,
A_fake_pool, B_fake_pool):
pd = tqdm(train_loader)
loss_D, loss_G = 0, 0
step = 0
Ga.train()
Da.train()
Gb.train()
Db.train()
for idx, data in enumerate(pd):
A_real = data[0].to(device)
B_real = data[1].to(device)
# 前向传递
B_fake = Ga(A_real) # Ga生成的假B
A_rec = Gb(B_fake) # Gb重构回的A
A_fake = Gb(B_real) # Gb生成的假A
B_rec = Ga(A_fake) # Ga重构回的B
# 训练G => G包含六部分损失
set_required_grad([Da, Db], requires_grad=False) # 不更新D
optim_G.zero_grad()
ls_G = train_G(Da=Da, Db=Db, B_fake=B_fake, loss=loss, A_fake=A_fake, l1_loss=l1_loss,
A_rec=A_rec,
A_real=A_real, B_rec=B_rec, B_real=B_real, Ga=Ga, Gb=Gb)
ls_G.backward()
optim_G.step()
# 训练D
set_required_grad([Da, Db], requires_grad=True)
optim_D.zero_grad()
A_fake_p = A_fake_pool.query(A_fake)
B_fake_p = B_fake_pool.query(B_fake)
ls_D = train_D(Da=Da, Db=Db, B_fake=B_fake_p, B_real=B_real, loss=loss, A_fake=A_fake_p, A_real=A_real)
ls_D.backward()
optim_D.step()
loss_D += ls_D
loss_G += ls_G
pd.desc = 'train_{} G_loss: {} D_loss: {}'.format(epoch, ls_G.item(), ls_D.item())
# 绘制训练结果
if idx % plot_every == 0:
writer.add_images(tag='epoch{}_Ga'.format(epoch), img_tensor=0.5 * (torch.cat([A_real, B_fake], 0) + 1),
global_step=step)
writer.add_images(tag='epoch{}_Gb'.format(epoch), img_tensor=0.5 * (torch.cat([B_real, A_fake], 0) + 1),
global_step=step)
step += 1
mean_lsG = loss_G / len(train_loader)
mean_lsD = loss_D / len(train_loader)
return mean_lsG, mean_lsD
@torch.no_grad()
def val(Ga, Da, Gb, Db, val_loader, loss, device, l1_loss, epoch):
pd = tqdm(val_loader)
loss_D, loss_G = 0, 0
Ga.eval()
Da.eval()
Gb.eval()
Db.eval()
all_loss = 10000
for idx, item in enumerate(pd):
A_real_img = item[0].to(device)
B_real_img = item[1].to(device)
B_fake_img = Ga(A_real_img)
A_fake_img = Gb(B_real_img)
A_rec = Gb(B_fake_img)
B_rec = Ga(A_fake_img)
# D的loss
ls_D = train_D(Da=Da, Db=Db, B_fake=B_fake_img, B_real=B_real_img, loss=loss, A_fake=A_fake_img,
A_real=A_real_img)
# G的loss
ls_G = train_G(Da=Da, Db=Db, B_fake=B_fake_img, loss=loss, A_fake=A_fake_img, l1_loss=l1_loss,
A_rec=A_rec,
A_real=A_real_img, B_rec=B_rec, B_real=B_real_img, Ga=Ga, Gb=Gb)
loss_G += ls_G
loss_D += ls_D
pd.desc = 'val_{}: G_loss:{} D_Loss:{}'.format(epoch, ls_G.item(), ls_D.item())
# 保存最好的结果
all_ls = ls_G + ls_D
if all_ls < all_loss:
all_loss = all_ls
best_image = torch.cat([A_real_img, B_fake_img, B_real_img, A_fake_img], 0)
result_img = (best_image + 1) * 0.5
if not os.path.exists('./results'):
os.mkdir('./results')
torchvision.utils.save_image(result_img, './results/val_epoch{}_cycle.jpg'.format(epoch))
def set_required_grad(nets, requires_grad=False):
if not isinstance(nets, list):
nets = [nets]
for net in nets:
if net is not None:
for params in net.parameters():
params.requires_grad = requires_grad
def train_G(Da, Db, B_fake, loss, A_fake, l1_loss, A_rec, A_real, B_rec, B_real, Ga, Gb):
# GAN loss
Da_out_fake = Da(B_fake)
Ga_gan_loss = loss(Da_out_fake, torch.ones(Da_out_fake.size()).cuda())
Db_out_fake = Db(A_fake)
Gb_gan_loss = loss(Db_out_fake, torch.ones(Db_out_fake.size()).cuda())
# Cycle loss
Cycle_A_loss = l1_loss(A_rec, A_real) * 10
Cycle_B_loss = l1_loss(B_rec, B_real) * 10
# identity loss
Ga_id_out = Ga(B_real)
Gb_id_out = Gb(A_real)
Ga_id_loss = l1_loss(Ga_id_out, B_real) * 10 * 0.5
Gb_id_loss = l1_loss(Gb_id_out, A_real) * 10 * 0.5
# G的总损失
ls_G = Ga_gan_loss + Gb_gan_loss + Cycle_A_loss + Cycle_B_loss + Ga_id_loss + Gb_id_loss
return ls_G
def train_D(Da, Db, B_fake, B_real, loss, A_fake, A_real):
# Da的loss
Da_fake_out = Da(B_fake.detach()).squeeze()
Da_real_out = Da(B_real).squeeze()
ls_Da1 = loss(Da_fake_out, torch.zeros(Da_fake_out.size()).cuda())
ls_Da2 = loss(Da_real_out, torch.ones(Da_real_out.size()).cuda())
ls_Da = (ls_Da1 + ls_Da2) * 0.5
# Db的loss
Db_fake_out = Db(A_fake.detach()).squeeze()
Db_real_out = Db(A_real.detach()).squeeze()
ls_Db1 = loss(Db_fake_out, torch.zeros(Db_fake_out.size()).cuda())
ls_Db2 = loss(Db_real_out, torch.ones(Db_real_out.size()).cuda())
ls_Db = (ls_Db1 + ls_Db2) * 0.5
# D的总损失
ls_D = ls_Da + ls_Db
return ls_D
(三)test
from cyclegan import Cycle_Gan_G
import torch
import torchvision.transforms as transform
import matplotlib.pyplot as plt
import cv2
from PIL import Image
def test(img_path):
if img_path.endswith('.png'):
img = cv2.imread(img_path)
img = img[:, :, ::-1]
else:
img = Image.open(img_path)
transforms = transform.Compose([
transform.ToTensor(),
transform.Resize((256, 256)),
transform.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
img = transforms(img.copy())
img = img[None].to('cuda') # [1,3,128,128]
# 实例化网络
Gb = Cycle_Gan_G().to('cuda')
# 加载预训练权重
ckpt = torch.load('weights/cycle_monent2photo.pth')
Gb.load_state_dict(ckpt['Gb_model'], strict=False)
Gb.eval()
out = Gb(img)[0]
out = out.permute(1, 2, 0)
out = (0.5 * (out + 1)).cpu().detach().numpy()
plt.figure()
plt.imshow(out)
plt.show()
if __name__ == '__main__':
test('123.jpg')
五、结果
(一)loss
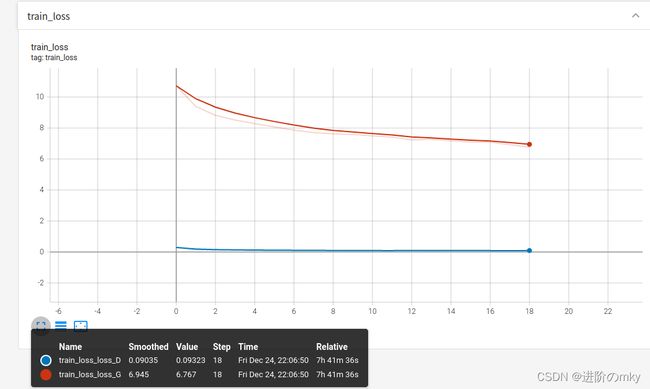
(二)训练可视化
这里我挑选了一部分训练结果和验证结果。
训练集上monet -> photo


训练集上photo-> monet
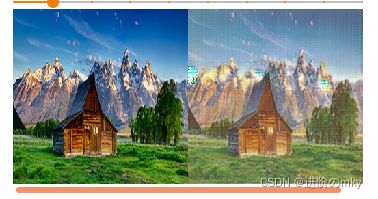

验证集上结果(左边为monet -> photo,右边为photo-> monet )


(三)测试结果
下图为photo转monet的结果


六、完整代码
数据集:百度网盘 请输入提取码 提取码:s3e3
代码:百度网盘 请输入提取码 提取码:t0d5