数据分析实战(四) 改进版RFM模型挖掘B站动画区优质UP主
前情回顾:Python分析5W+B站热门视频信息
在上次B站数据分析实战中,我们扒拉了一些最咕UP主。这次,我们再来扒扒一些优质UP主吧~
目录
-
-
- 一、数据介绍及处理
- 二、实战分析
-
- 2.1 改进版RFM模型介绍
- 2.2 分值计算
- 2.3 维度打分
- 2.4 UP主分层
- 参考文章
-
一、数据介绍及处理
本次案例数据共57407条bilibili动画区播放量破万视频信息,时间跨度为2020年1月1日~2020年12月31日,其主要字段如下:
| 字段名 | 含义 |
|---|---|
| Up_er | UP主名 |
| title | 视频名称 |
| pubdate | 视频发布时间 |
| video_time | 视频时长/秒 |
| likes | 点赞数 |
| coins | 硬币数 |
| favorites | 收藏数 |
| shares | 分享数 |
| views | 播放量 |
| comments | 评论数 |
| danmu | 弹幕数 |
| type | 所在分区(MAD-AMV、MMD、短片-手书-配音、手办-模玩) |
分区介绍
MAD是利用既存的素材(一般为动画或CG图),加以修改,剪接等“二次创作”并配乐而制作成的影片。
AMV为动画音乐视频(Anime Music Video,简称AMV)是由一个或几个动画组成,并搭配一首歌曲的短片
MMD全称为MikuMikuDance,是由樋口优开发的一款免费的3D动画制作软件,3D的二次元作品通常都是MMD
数据预览
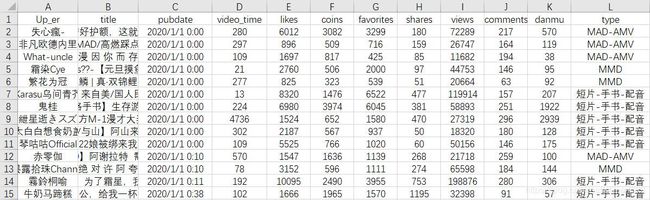
预处理部分与上篇博客基本相同,在此不再贴图展示,该部分代码如下:
import pandas as pd
import os
os.chdir('C:/users/dell/Desktop/')
data = pd.read_csv('bilibili.csv',parse_dates=['pubdate'],encoding='gb18030') #parse_dates将pubdate解析为日期格式
data1 = data.dropna() #删除缺失值
data1 = data1.drop_duplicates() #删除重复值
二、实战分析
2.1 改进版RFM模型介绍
RFM模型一种通过客户近期购买行为、购买频率及消费金额,来衡量客户价值及创利能力的模型。其简称基本含义为:
| 字母 | 含义 |
|---|---|
| Recency | 最近一次消费时间(最近一次消费时间到参考时间的间隔) |
| Frequency | 消费的频率 |
| Money | 消费的金额 |
显然RFM模型不能对视频质量进行评价,鉴此,本文参考博主数据不吹牛的做法,使用改进版RFM模型来对视频质量进行评估。
-
I(Interaction rate)
I值反映的是平均每个视频的互动率,互动率越高,表明其视频更能拉近与观众的距离。计算方式如下:
I = 总 弹 幕 数 + 总 评 论 数 总 播 放 量 × 统 计 范 围 内 视 频 数 量 I=\frac{总弹幕数+总评论数}{总播放量 \times 统计范围内视频数量} I=总播放量×统计范围内视频数量总弹幕数+总评论数 -
F(Frequence)
F值表示的是每个视频的平均发布周期,各视频之间的发布周期越短,则说明UP主创作活力与效率越高。计算方式如下:
F = 统 计 范 围 内 最 晚 发 布 的 视 频 时 间 − 最 早 视 频 发 布 时 间 该 段 时 间 内 发 布 视 频 的 数 量 F = \frac{统计范围内最晚发布的视频时间-最早视频发布时间}{该段时间内发布视频的数量} F=该段时间内发布视频的数量统计范围内最晚发布的视频时间−最早视频发布时间 -
L(Like_rate)
L值表示的是统计时间内发布视频的平均点赞率,越大表示视频质量越稳定,用户对UP主的认可度也就越高。计算方式如下:
L = 点 赞 数 × 1 + 投 币 数 × 2 + 收 藏 数 × 3 + 分 享 数 × 4 播 放 量 × 发 布 视 频 数 L=\frac{点赞数 \times 1 + 投币数 \times 2 + 收藏数 \times3+分享数\times4}{播放量\times发布视频数} L=播放量×发布视频数点赞数×1+投币数×2+收藏数×3+分享数×4
2.2 分值计算
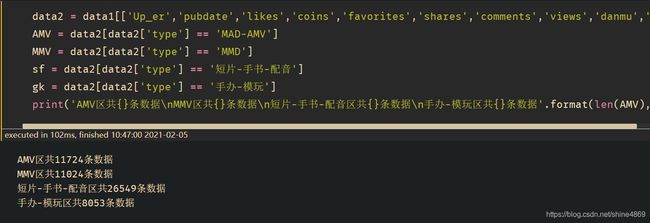
为后续分析方便,这里以动画区中的MAD-AMV分区为例,其余分区均可通过同样思路进行分析。首先,将各区UP主筛选出来:
data2 = data1[['Up_er','pubdate','likes','coins','favorites','shares','comments','views','danmu','type']]
AMV = data2[data2['type'] == 'MAD-AMV']
MMV = data2[data2['type'] == 'MMD']
sf = data2[data2['type'] == '短片-手书-配音']
gk = data2[data2['type'] == '手办-模玩']
print('AMV区共{}条数据\nMMV区共{}条数据\n短片-手书-配音区共{}条数据\n手办-模玩区共{}条数据'.format(len(AMV),len(MMV),len(sf),len(gk)))
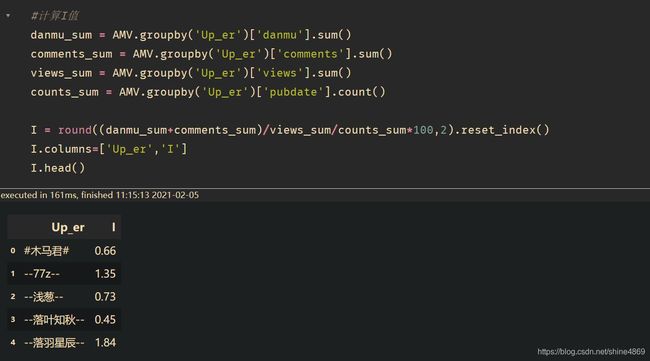
- I值计算
#计算I值
danmu_sum = AMV.groupby('Up_er')['danmu'].sum()
comments_sum = AMV.groupby('Up_er')['comments'].sum()
views_sum = AMV.groupby('Up_er')['views'].sum()
counts_sum = AMV.groupby('Up_er')['pubdate'].count()
I = round((danmu_sum+comments_sum)/views_sum/counts_sum*100,2).reset_index()
I.columns=['author','I']
I.head()
- F值计算
#计算F值
earliest = AMV.groupby('Up_er')['pubdate'].min()
latest = AMV.groupby('Up_er')['pubdate'].max()
F = round((latest-earliest).dt.days/AMV.groupby('Up_er')['pubdate'].count()).reset_index()
counts_sum = AMV.groupby('Up_er')['pubdate'].count().reset_index()
counts_sum.columns = ['Up_er','pub_counts']
counts_sum1 = counts_sum[counts_sum['pub_counts']>5] #剔除发布视频数小于5的UP主
F = pd.merge(counts_sum1, F,on='Up_er', how='inner')
F.columns = ['Up_er','pub_counts','F']
F.head()

考虑到某些视频博主某天发布多条视频后就销声匿迹了,我们还需查看下F值的整体情况

F最小值为2,即不存在博主某天发布多条视频后销声匿迹的情况。
- L值计算
#计算L值
AMV['likes_rate']=(AMV['likes']*1+AMV['coins']*2+AMV['favorites']*3+AMV['shares']*4)/AMV['views']*100
L = round((AMV.groupby('Up_er')['likes_rate'].sum()/AMV.groupby('Up_er')['pubdate'].count()).reset_index(),2)
L.columns = ['Up_er', 'L']
L.head()

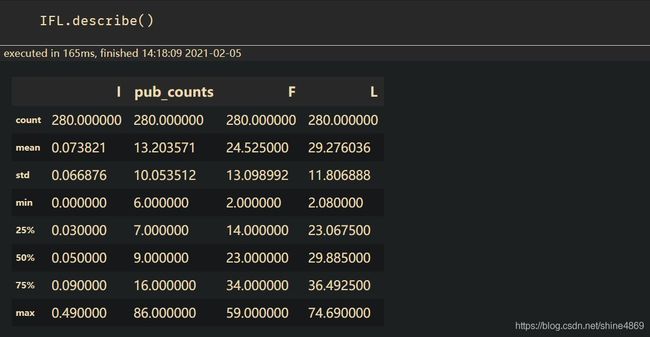
合并IFL值
#合并IFL值
IF = pd.merge(I,F,on = 'Up_er',how = 'inner')
IFL = pd.merge(IF,L,on = 'Up_er',how = 'inner')
IFL.head()

2.3 维度打分
对于F值,我们可以按照如下区间范围进行打分
| 分值 | F值所处区间 | 含义 |
|---|---|---|
| 1 | [ 90 , ∞ ] [90,\infty] [90,∞] | 超过三个月以上更新一次 |
| 2 | [ 30 , 90 ) [30,90) [30,90) | 平均三个月更新一次 |
| 3 | [ 15 , 30 ) [15,30) [15,30) | 平均一个月更新一次 |
| 4 | [ 7 , 15 ) [7,15) [7,15) | 平均两周更新一次 |
| 5 | [ 1 , 7 ) [1,7) [1,7) | 平均一周更新一次 |
而对于I值和L值,我们可以根据其四位分位数对其进行打分
I值打分区间如下:
| 分值 | F值所处区间 | 含义 |
|---|---|---|
| 1 | [ 0 , 0.03 ] [0,0.03] [0,0.03] | 互动率大于0 |
| 2 | [ 0.03 , 0.05 ) [0.03,0.05) [0.03,0.05) | 互动率大于0.03% |
| 3 | [ 0.05 , 0.09 ) [0.05,0.09) [0.05,0.09) | 互动率大于0.05% |
| 4 | [ 0.09 , ∞ ) [0.09,\infty) [0.09,∞) | 互动率大于0.09 |
L值打分区间如下:
| 分值 | F值所处区间 | 含义 |
|---|---|---|
| 1 | [ 2.08 , 23.07 ) [2.08,23.07) [2.08,23.07) | 点赞率大于2.08% |
| 2 | [ 23.07 , 29.89 ) [23.07,29.89) [23.07,29.89) | 点赞率大于23.07% |
| 3 | [ 29.89 , 36.49 ) [29.89,36.49) [29.89,36.49) | 点赞率大于29.89% |
| 4 | [ 36.49 , ∞ ) [36.49,\infty) [36.49,∞) | 点赞率大于36.49% |
#AMV区打分,500即代表无穷大,right=False表示为划分区间格式为左闭右开
IFL['I_score'] = pd.cut(IFL['I'], bins=[0,0.03,0.05,0.09,500],
labels=[1,2,3,4], right=False).astype(float)
IFL['F_score'] = pd.cut(IFL['F'], bins=[0,7,15,30,90,500],
labels=[5,4,3,2,1], right=False).astype(float)
IFL['L_score'] = pd.cut(IFL['L'], bins=[2.08,23.07,29.89,36.49,500],
labels=[1,2,3,4], right=False).astype(float)
#与各自均值比较
IFL['I值是否大于均值'] = (IFL['I_score']>IFL['I_score'].mean())*1 #布尔值与数字运算规则:True则返回数字;False返回0
IFL['F值是否大于均值'] = (IFL['F_score']>IFL['F_score'].mean())*1
IFL['L值是否大于均值'] = (IFL['L_score']>IFL['L_score'].mean())*1
IFL.head()
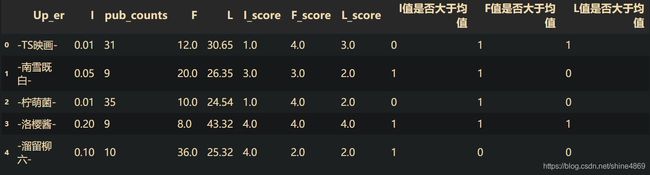
2.4 UP主分层
参考RFM模型对客户分层的做法,利用IFL模型可将UP主分为如下8类(1代表是,0代表否):
| 用户分类 | I是否高于均值 | F是否高于均值 | L是否高于均值 | 含义 |
|---|---|---|---|---|
| 高价值UP主 | 1 | 1 | 1 | 用户活跃高,更新周期短,视频质量高 |
| 高价值拖更UP主 | 1 | 0 | 1 | 用户活跃高,更新周期长,视频质量高 |
| 高质量UP主 | 0 | 1 | 1 | 用户活跃低,更新周期短,视频质量高 |
| 接地气活跃UP主 | 1 | 1 | 0 | 用户活跃高,更新周期短,视频质量低 |
| 高质量拖更UP主 | 0 | 0 | 1 | 用户活跃低,更新周期长,视频质量高 |
| 活跃UP主 | 0 | 1 | 0 | 用户活跃低,更新周期短,视频质量低 |
| 接地气UP主 | 1 | 0 | 0 | 用户活跃高,更新周期长,视频质量低 |
| 萌新UP主 | 0 | 0 | 0 | 用户活跃低,更新周期长,视频质量低 |
IFL['value'] = (IFL['I值是否大于均值'])*100+(IFL['F值是否大于均值'])*10+(IFL['L值是否大于均值'])*1
label_dict = {
111:'高价值UP主',
101:'高价值拖更UP主',
11:'高质量UP主',
110:'接地气活跃UP主',
1:'高质量拖更UP主',
10:'活跃UP主',
100:'接地气UP主',
0:'萌新UP主',
}
IFL['label'] = IFL['value'].map(label_dict)
IFL.head()

按照相同的思路,对其余分区进行分析,最终以可视化的方式,呈现下图:
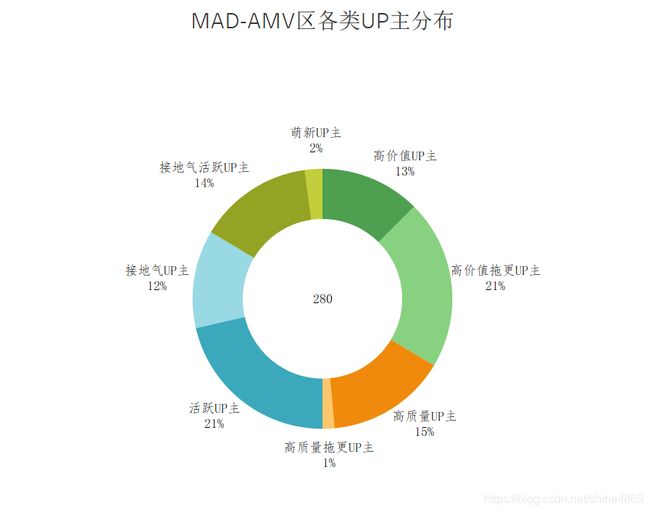
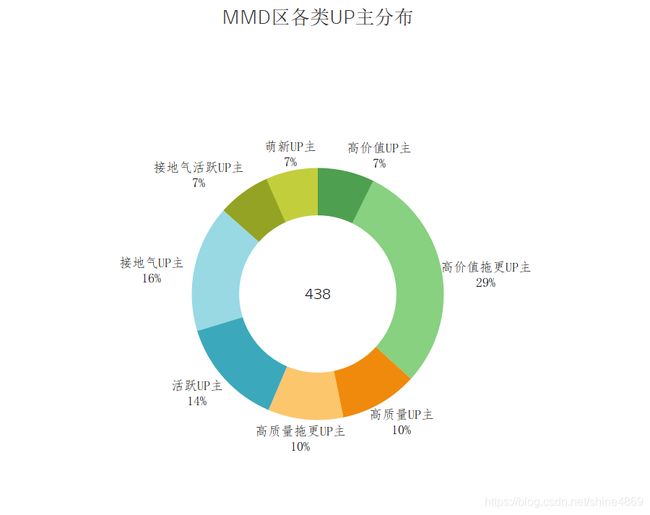
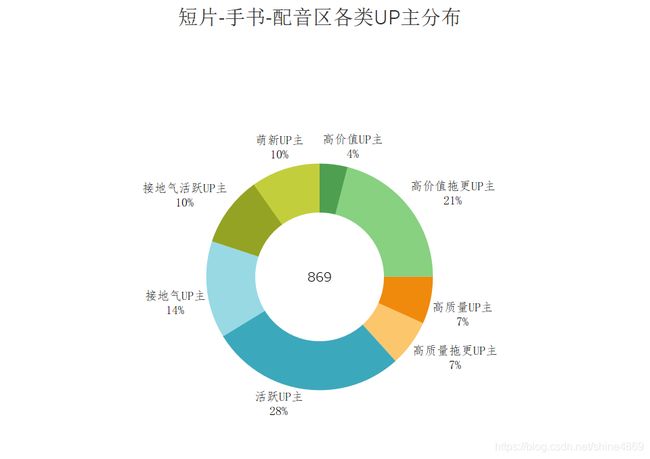
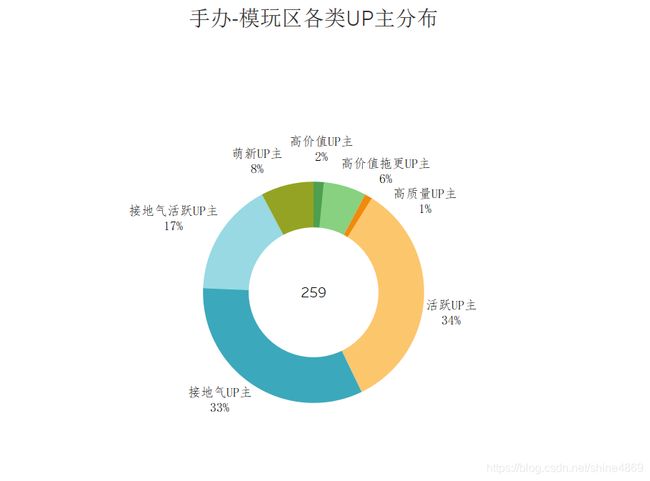
从上图简要分析可知:
MAD-AMV区的UP主呈现出高质量高价值特征,高质量与高价值类型UP主占比50%,但由于高质量视频制作难度大的原因,导致不少UP主低于平均更新周期,这与我们上篇博客的分析是保持一致的。
MMD区的UP主呈现出高质量、高价值但拖更严重特征,高质量与高价值类型UP主占比56%,拖更UP主所占比例达到了39%,是所有分区中最高的!
短片-手书-配音区的UP主呈现出接地气、有活力、更新快特征,接地气、有活力的UP主共占比52%。此外,萌新UP主占比是四个分区中最高的,但高质量高价值UP主占比相对较少,这也反映出该区容易水视频~
手办-模玩区UP主比短片-手书-配音区UP主表现出更为尤胜的活力特征,接地气、有活力的UP主共占比84%由此看来,手办-模玩区的视频质量不高,但能吸引观众。
以上就是本次分享的全部内容~
参考文章
数据不吹牛——加强版RFM模型挖掘B站优质UP主