GAN-生成对抗网络-生成手写数字(基于pytorch)
什么是GAN
GAN(Generative Adversarial Network),网络也如他的名字一样,有生成,有对抗,两个网络相互博弈。我们给两个网络起个名字,第一个网络用来生成数据命名为生成器(generator),另一个网络用来鉴别生成器生成的数据我们命名为鉴别器(discriminator)。
GAN的训练
标准GAN的训练有三步:
- 用真实的训练数据训练鉴别器
- 用生成的数据训练鉴别器
- 训练生成器生成数据,并使鉴别器以为是真实数据
数据集
经典mnist数据集,典中典了,不放了,网上很多。
代码
代码来自《Pytorch生成对抗网络编程》人民邮电出版社
写的不咋好,导致训练起来特别慢,后面有重构的代码,跑起来快多了
有些书上的方法我不是很习惯,也重构了很多,最后效果都差不多。
已修复模式崩坏等问题
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import torch.utils.data as Data
from sklearn.preprocessing import OneHotEncoder
import scipy.io as scio
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
mnist_dataset = pd.read_csv('mnist_train.csv', header=None).values
label = mnist_dataset[:, 0]
image_values = mnist_dataset[:, 1:] / 255.0
encoder = OneHotEncoder(sparse=False) # sparse默认为True,返回稀疏矩阵
label = encoder.fit_transform(label.reshape(-1, 1))
train_t = torch.from_numpy(image_values.astype(np.float32))
label = torch.from_numpy(label.astype(np.float32))
train_data = Data.TensorDataset(train_t, label)
train_loader = Data.DataLoader(dataset=train_data,
batch_size=1,
shuffle=True)
def plot_num_image(index):
plt.imshow(image_values[index].reshape(28, 28), cmap='gray')
plt.title('label=' + str(label[index]))
plt.show()
def generate_random(size):
random_data = torch.rand(size)
return random_data
def generate_random_seed(size):
random_data = torch.randn(size)
return random_data
# 构建分类器
class Discriminator(nn.Module):
def __init__(self):
# 初始化父类
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 300),
nn.LeakyReLU(0.02),
nn.LayerNorm(300),
nn.Linear(300, 30),
nn.LeakyReLU(0.02),
nn.LayerNorm(30),
nn.Linear(30, 1),
nn.Sigmoid(),
)
self.loss_function = nn.BCELoss()
# 创建优化器
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.01)
self.counter = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train(self, inputs, targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs, targets)
# 每训练10此增加计数器
self.counter += 1
if self.counter % 10 == 0:
self.progress.append(loss.item())
if self.counter % 10000 == 0:
print("counter = ", self.counter)
# 清楚梯度,反向传播, 更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
# 构建生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(100, 300),
nn.LeakyReLU(0.02),
nn.LayerNorm(300),
nn.Linear(300, 784),
nn.Sigmoid(),
)
# 创建优化器
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.01)
self.counter = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train(self, D, inputs, targets): # 用分类器的损失来训练生成
g_output = self.forward(inputs) # 生成器generator的输出
d_output = D.forward(g_output) # 分类器discriminator的输出
loss = D.loss_function(d_output, targets)
self.counter += 1
if self.counter % 10 == 0:
self.progress.append(loss.item())
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
D = Discriminator()
G = Generator()
'''
for step, (b_x, b_y) in enumerate(train_loader):
# 真实数据
D.train(b_x[0], torch.FloatTensor([1.0]))
# 生成数据
D.train(generate_random(784), torch.FloatTensor([0.0]))
plt.plot(D.progress) # loss很快就归0了
plt.show()
# 输出一个真是数据和生成数据
print('real_num:', D.forward(b_x[0]).item())
print('generate-num:', D.forward(generate_random(784)).item())
# 至此我们的鉴别器已经学会分类真实数据和我们随机生成的数据了
# 让生成器随机产生一个图像我们看看
output = G.forward(generate_random(1))
img = output.detach().numpy().reshape(28, 28)
plt.imshow(img, interpolation='none', cmap='gray') # interpolation 差值方法
plt.show()
'''
for epoch in range(10):
for step, (b_x, b_y) in enumerate(train_loader):
# 真实数据
D.train(b_x[0], torch.FloatTensor([1.0]))
D.train(G.forward(generate_random_seed(100)).detach(), torch.FloatTensor([0.0]))
G.train(D, generate_random_seed(100), torch.FloatTensor([1.0]))
print('完成',epoch+1,'epoch','*************'*3)
# 我们看一下生成器和鉴别器的loss
plt.plot(D.progress, c='b', label='D-loss')
plt.plot(G.progress, c='r', label='G-loss')
plt.legend()
plt.savefig('loss.jpg')
plt.show()
# 此时的生成器已经经过训练,我们多生成几张看看
for i in range(6):
output = G.forward(generate_random_seed(100))
img = output.detach().numpy().reshape(28, 28)
plt.subplot(2, 3, i+1)
plt.imshow(img,cmap='gray')
plt.show()
我们生成几张图像看看:
for i in range(6):
output = G.forward(generate_random_seed(100))
img = output.detach().numpy().reshape(28, 28)
plt.subplot(2, 3, i+1)
plt.imshow(img, cmap='gray')
plt.show()
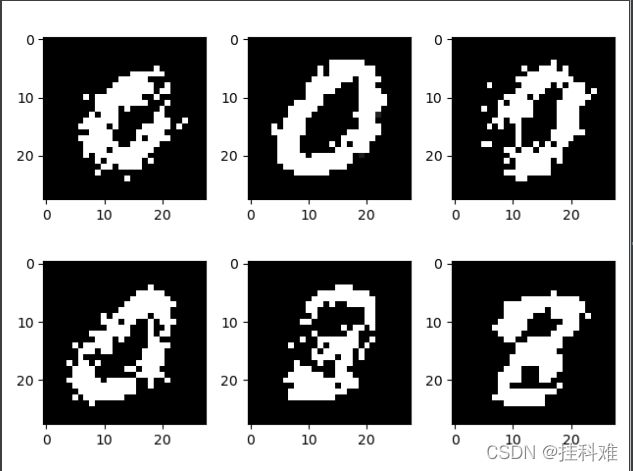
看着很像000038,非常好了,生成器并没有见过数字长什么样子,但是他学会了怎么写(生成)相似的图像。刚开始学GAN不久,至此我们的生成器也只是能随机生成图像,无法生成特定的数字。 还没想到怎么解决。(用条件GAN)
重构后:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
# 数据归一化(-1,1)
transform = transforms.Compose([
transforms.ToTensor(), # 0-1
transforms.Normalize(0.5, 0.5) # 均值0.5方差0.5
])
# 加载内置数据集
train_ds = torchvision.datasets.MNIST('data',
train=True,
transform=transform,
download=True)
dataloader = torch.utils.data.DataLoader(train_ds,
batch_size=64,
shuffle=True)
# 返回一个批次的数据
imgs, _ = next(iter(dataloader))
# 生成器,输入100噪声输出(1,28,28)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear = nn.Sequential(
nn.Linear(100, 256),
nn.Tanh(),
nn.Linear(256, 512),
nn.Tanh(),
nn.Linear(512, 28*28),
nn.Tanh()
)
def forward(self, x):
x = self.linear(x)
x = x.view(-1, 28, 28)
return x
# 辨别器,输入(1,28,28),输出真假,推荐使用LeakRelu
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.linear = nn.Sequential(
nn.Linear(28*28, 512),
nn.LeakyReLU(),
nn.Linear(512, 256),
nn.LeakyReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(-1, 28*28)
x = self.linear(x)
return x
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
print('using cuda:', torch.cuda.get_device_name(0))
Gen = Generator().to(device)
Dis = Discriminator().to(device)
d_optim = torch.optim.Adam(Dis.parameters(), lr=0.001)
g_optim = torch.optim.Adam(Gen.parameters(), lr=0.001)
# BCEWithLogisticLoss 未激活的输出
loss_function = torch.nn.BCELoss()
def gen_img_plot(model, test_input):
# squeeze 删除单维度
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
fig = plt.figure(figsize=(4, 4))
for i in range(prediction.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow((prediction[i]+1) / 2) # 生成-1,1,恢复到0,1
plt.axis('off')
plt.show()
test_input = torch.randn(16, 100, device=device)
D_loss = []
G_loss = []
for epoch in range(20):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader)
for step, (img, _) in enumerate(dataloader):
img = img.to(device)
size = img.size(0)
random_noise = torch.randn(size, 100, device=device)
d_optim.zero_grad()
real_output = Dis(img) # 判别器输入真实图片
# 判别器在真实图像上的损失
d_real_loss = loss_function(real_output,
torch.ones_like(real_output)
)
d_real_loss.backward()
gen_img = Gen(random_noise)
fake_output = Dis(gen_img.detach()) # 判别器输入生成图片,fake_output对生成图片的预测
# gen_img是由生成器得来的,但我们现在只对判别器更新,所以要截断对Gen的更新
# detach()得到了没有梯度的tensor,求导到这里就停止了,backward的时候就不会求导到Gen了
d_fake_loss = loss_function(fake_output,
torch.zeros_like(fake_output)
)
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optim.step()
# 更新生成器
g_optim.zero_grad()
fake_output = Dis(gen_img)
g_loss = loss_function(fake_output,
torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad(): # 之后的内容不进行梯度的计算(图的构建)
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch+1)
gen_img_plot(Gen, test_input)
训练20轮后:

当然我们也可以使用网络结构DCGAN:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
# 数据归一化(-1,1)
transform = transforms.Compose([
transforms.ToTensor(), # 0-1
transforms.Normalize(0.5, 0.5) # 均值0.5方差0.5
])
# 加载内置数据集
train_ds = torchvision.datasets.MNIST('data',
train=True,
transform=transform,
download=True)
dataloader = torch.utils.data.DataLoader(train_ds,
batch_size=64,
shuffle=True)
# 定义生成器,依然输入长度100的噪声
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = nn.Linear(100, 256*7*7)
self.bn1 = nn.BatchNorm1d(256*7*7)
self.deconv1 = nn.ConvTranspose2d(256, 128,
kernel_size=(3, 3),
stride=1,
padding=1
)
self.bn2 = nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128, 64,
kernel_size=(4, 4),
stride=2,
padding=1
)
self.bn3 = nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64, 1,
kernel_size=(4, 4),
stride=2,
padding=1
)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.bn1(x)
x = x.view(-1, 256, 7, 7)
x = F.relu(self.deconv1(x))
x = self.bn2(x)
x = F.relu(self.deconv2(x))
x = self.bn3(x)
x = torch.tanh(self.deconv3(x))
return x
# 判别器,输入(28,28)图片
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(64, 128, 3, 2)
self.bn = nn.BatchNorm2d(128)
self.fc = nn.Linear(128*6*6, 1)
def forward(self, x):
x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3)
x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3)
x = self.bn(x)
x = x.view(-1, 128*6*6)
x = torch.sigmoid(self.fc(x))
return x
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
print('using cuda:', torch.cuda.get_device_name(0))
Gen = Generator().to(device)
Dis = Discriminator().to(device)
loss_fun = nn.BCELoss()
d_optimizer = torch.optim.Adam(Dis.parameters(), lr=1e-5) # 小技巧
g_optimizer = torch.optim.Adam(Gen.parameters(), lr=1e-4)
def generate_and_save_image(model, test_input):
predictions = np.squeeze(model(test_input).cpu().numpy())
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow((predictions[i]+1) / 2, cmap='gray')
plt.axis('off')
plt.show()
test_input = torch.randn(16, 100, device=device)
D_loss = []
G_loss = []
for epoch in range(30):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader.dataset)
for step, (img, _) in enumerate(dataloader):
img = img.to(device)
size = img.size(0)
random_noise = torch.randn(size, 100, device=device)
d_optimizer.zero_grad()
real_output = Dis(img) # 判别器输入真实图片
# 判别器在真实图像上的损失
d_real_loss = loss_fun(real_output,
torch.ones_like(real_output)
)
d_real_loss.backward()
gen_img = Gen(random_noise)
fake_output = Dis(gen_img.detach()) # 判别器输入生成图片,fake_output对生成图片的预测
# gen_img是由生成器得来的,但我们现在只对判别器更新,所以要截断对Gen的更新
# detach()得到了没有梯度的tensor,求导到这里就停止了,backward的时候就不会求导到Gen了
d_fake_loss = loss_fun(fake_output,
torch.zeros_like(fake_output)
)
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optimizer.step()
# 更新生成器
g_optimizer.zero_grad()
fake_output = Dis(gen_img)
g_loss = loss_fun(fake_output,
torch.ones_like(fake_output))
g_loss.backward()
g_optimizer.step()
with torch.no_grad():
d_epoch_loss += d_loss.item()
g_epoch_loss += g_loss.item()
with torch.no_grad(): # 之后的内容不进行梯度的计算(图的构建)
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch+1)
generate_and_save_image(model=Gen, test_input=test_input)
plt.plot(D_loss, label='D_loss')
plt.plot(G_loss, label='G_loss')
plt.legend()
plt.show()

30轮效果