Hive学习04-查询 分组 join 排序
文章目录
- 基本查询
-
- where语句
- 比较运算符
- Like和RLike
- 逻辑运算符
- 分组
-
- Group By语句
- Having语句
- join
基本查询
全表和特定列查询、列别名、算术运算符、常用函数、limit等上篇文章已经提过。这篇文章直接从where开始讲
where语句
create table test2(
stu_id int,
class_name string,
score int)
row format delimited fields terminated by ',';

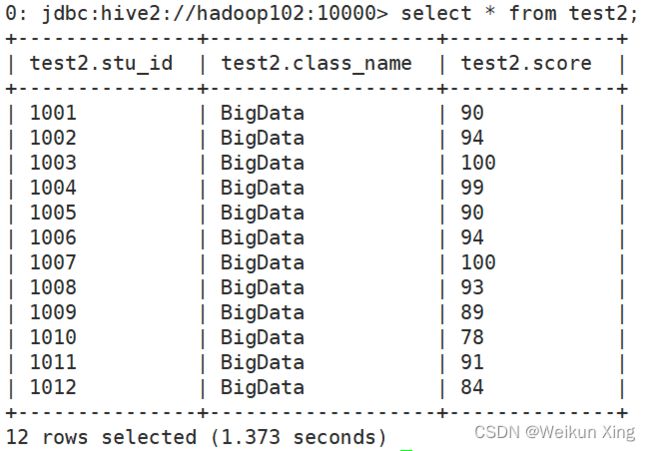
0: jdbc:hive2://hadoop102:10000> select * from test2;
比较运算符
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,如果一边为NULL,返回False |
| A<>B, A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
A| 基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
|
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B | STRING 类型 | B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
(1)查询出成绩等于90的所有学生
select * from test2 where score=90;
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1001 | BigData | 90 |
| 1005 | BigData | 90 |
+---------------+-------------------+--------------+
(2)查询成绩在80到90的学生信息
select * from test2 where score between 80 and 90;
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1001 | BigData | 90 |
| 1005 | BigData | 90 |
| 1009 | BigData | 89 |
| 1012 | BigData | 84 |
+---------------+-------------------+--------------+
(3)查询stu_id为空的所有学生信息
select * from test2 where stu_id is null;
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
+---------------+-------------------+--------------+
(4)查询成绩是90或100的学生信息
select * from test2 where score in (90,100);
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1001 | BigData | 90 |
| 1003 | BigData | 100 |
| 1005 | BigData | 90 |
| 1007 | BigData | 100 |
+---------------+-------------------+--------------+
Like和RLike
1)使用LIKE运算选择类似的值
2)选择条件可以包含字符或数字:
% 代表零个或多个字符(任意个字符)。
_ 代表一个字符。
3)RLIKE子句
RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
4)案例实操
(1)查找stu_id以101开头的学生信息
select * from test2 where stu_id like '101%';
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1010 | BigData | 78 |
| 1011 | BigData | 91 |
| 1012 | BigData | 84 |
+---------------+-------------------+--------------+
(2)查找stu_id中第4个数字为1的学生信息
select * from test2 where stu_id like '___1';
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1001 | BigData | 90 |
| 1011 | BigData | 91 |
+---------------+-------------------+--------------+
(3)查找class_name中带有B的学生信息
select * from test2 where class_name rlike '[B]';
这个数据自然是全部能匹配到
逻辑运算符
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
(1)查询成绩大于90,stu_id以101开头
select * from test2 where score>90 and stu_id like '101%';
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1011 | BigData | 91 |
+---------------+-------------------+--------------+
(2)查询成绩大于95,或者stu_id以101开头
select * from test2 where score>95 or stu_id like '101%';
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1003 | BigData | 100 |
| 1004 | BigData | 99 |
| 1007 | BigData | 100 |
| 1010 | BigData | 78 |
| 1011 | BigData | 91 |
| 1012 | BigData | 84 |
+---------------+-------------------+--------------+
(3)查询stu_id除了1001,1002,1003,1004,1005,1010以外的学生信息
select * from test2 where stu_id not in (1001,1002,1003,1004,1005,1010);
+---------------+-------------------+--------------+
| test2.stu_id | test2.class_name | test2.score |
+---------------+-------------------+--------------+
| 1006 | BigData | 94 |
| 1007 | BigData | 100 |
| 1008 | BigData | 93 |
| 1009 | BigData | 89 |
| 1011 | BigData | 91 |
| 1012 | BigData | 84 |
+---------------+-------------------+--------------+
分组
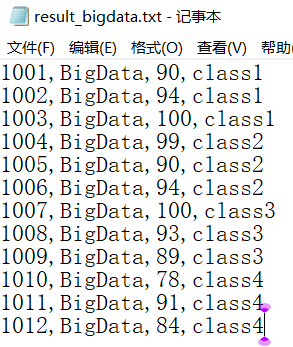
增加列-班级信息
ALTER TABLE test2 ADD COLUMNS(class_id STRING);

Group By语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
(1)计算test2表每个班的平均成绩
select class_id,avg(score) as avg_score from test2 group by class_id;
+-----------+--------------------+
| class_id | avg_score |
+-----------+--------------------+
| class1 | 94.66666666666667 |
| class2 | 94.33333333333333 |
| class3 | 94.0 |
| class4 | 84.33333333333333 |
+-----------+--------------------+
(2)计算test2表每个班的最高成绩
select class_id,max(score) as max_score from test2 group by class_id;
+-----------+------------+
| class_id | max_score |
+-----------+------------+
| class1 | 100 |
| class2 | 99 |
| class3 | 100 |
| class4 | 91 |
+-----------+------------+
Having语句
having与where不同点
(1)where后面不能写分组函数,而having后面可以使用分组函数。
(2)having只用于group by分组统计语句。
求平均分数大于94.5的班级
select class_id,avg(score) as avg_score from test2 group by class_id having avg_score>94.5;
+-----------+--------------------+
| class_id | avg_score |
+-----------+--------------------+
| class1 | 94.66666666666667 |
+-----------+--------------------+
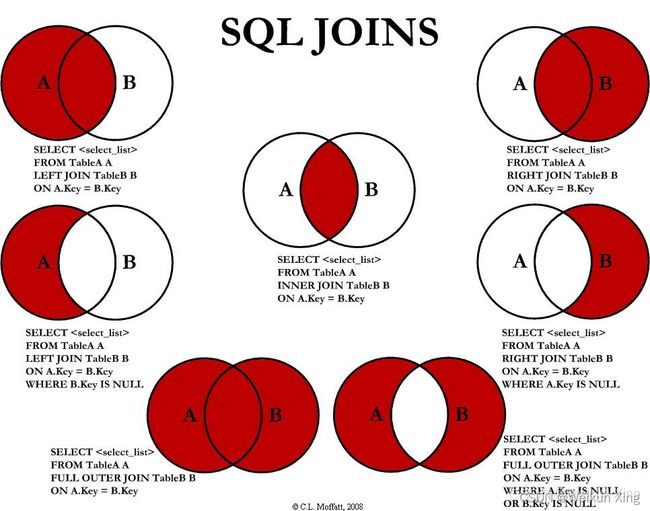
join