Hudi-湖仓一体
目录
- Hudi安装
- Hudi-Spark操作
-
- Spark-Shell启动
-
- 设置表名
- 插入数据
- 查询数据
- 修改数据
- 增量查询
- 时间点查询
- 删除数据
- 覆盖数据
- Hudi-Flink操作
-
- 安装Flink
- 插入数据
- 修改数据
Hudi安装
maven安装
官网地址https://maven.apache.org/index.html
# 解压maven
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
# 文件夹重命名
mv apache-maven-3.6.1/ maven
修改环境变量vim /etc/profile.d/my_env.sh
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven
export PATH=$PATH:$MAVEN_HOME/bin
测试环境变量
source /etc/profile
mvn -v

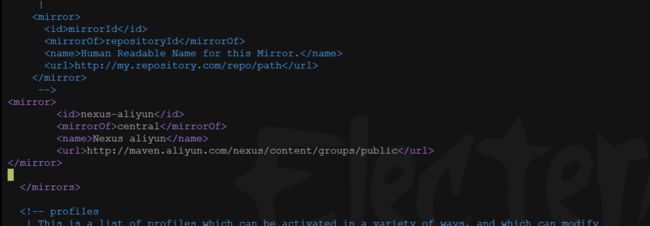
添加阿里云仓库镜像
<mirror>
<id>nexus-aliyunid>
<mirrorOf>centralmirrorOf>
<name>Nexus aliyunname>
<url>http://maven.aliyun.com/nexus/content/groups/publicurl>
mirror>
Git安装
# 安装git
yum install git
# 查看git版本
git --version

构建hudi
通过国内镜像拉取源码,或者本机下载后ftp到服务器
git clone --branch release-0.8.0 https://gitee.com/apache/Hudi.git
修改pom文件
<repository>
<id>nexus-aliyunid>
<name>nexus-aliyunname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
开始构建hudi
mvn clean package -DskipTests -Dspark3 -Dscala-2.12

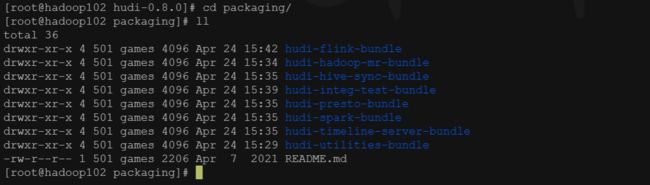
编译好之后文件目录对应Hudi下的packaging目录
解决依赖问题
如果编译报错则进入maven仓库路径下,去maven repository中央仓库中下载pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar,然后手动导入maven本地仓库
cd .m2/
cd repository/
cd org/
mkdir pentaho
mkdir pentaho-aggdesigner-algorithm
mkdir 5.1.5-jhyde
上传pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar

Hudi-Spark操作
Spark-Shell启动
spark-shell启动,需要指定spark-avro模块,因为默认环境里没有,spark-avro模块版本需要和spark版本对应,这里都是3.0.x,并且使用Hudi编译好的jar包。
spark-shell --jars /opt/module/hudi-0.8.0/packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.8.0.jar --packages org.apache.spark:spark-avro_2.12:3.0.1 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
设置表名
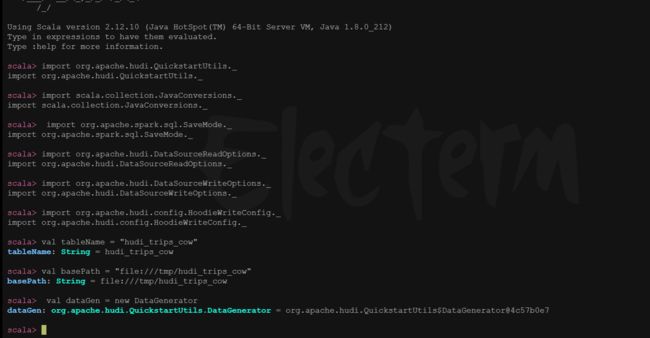
设置表名,基本路径和数据生成器
scala> import org.apache.hudi.QuickstartUtils._
scala> import scala.collection.JavaConversions._
scala> import org.apache.spark.sql.SaveMode._
scala> import org.apache.hudi.DataSourceReadOptions._
scala> import org.apache.hudi.DataSourceWriteOptions._
scala> import org.apache.hudi.config.HoodieWriteConfig._
scala> val tableName = "hudi_trips_cow"
tableName: String = hudi_trips_cow
scala> val basePath = "file:///tmp/hudi_trips_cow"
basePath: String = file:///tmp/hudi_trips_cow
scala> val dataGen = new DataGenerator
dataGen: org.apache.hudi.QuickstartUtils.DataGenerator = org.apache.hudi.QuickstartUtils$DataGenerator@5cdd5ff9
插入数据
新增数据,生成一些数据,将其加载到DataFrame中,然后将DataFrame写入Hudi表
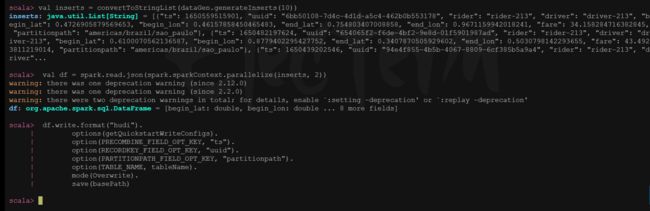
scala> val inserts = convertToStringList(dataGen.generateInserts(10))
scala> val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
scala> df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
mode(Overwrite).将覆盖重新创建表如果已存在。可以检查/tmp/hudi_trps_cow路径下是否有数据生成
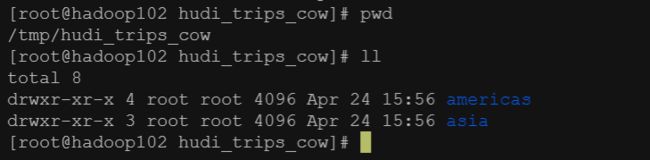
查询数据
// 由于测试数据分区是区域/国家/城市,所以.load(basePath + "/*/*/*/*")
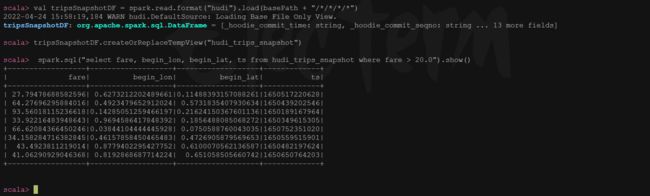
scala> val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
scala> tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
scala> spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
修改数据
类似于插入新数据,使用数据生成器生成新数据对历史数据进行更新。将数据加载到DataFrame中并将DataFrame写入Hudi表中
scala> val updates = convertToStringList(dataGen.generateUpdates(10))
scala> val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Append).
| save(basePath)
增量查询
Hudi还提供了获取自给定提交时间戳以来以更改记录流的功能。这可以通过使用Hudi的增量查询并提供开始流进行更改的开始时间来实现
scala>spark.read.format("hudi").load(basePath+"/*/*/*/*").createOrReplaceTempView("hudi_trips_snapshot")
scala> val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
scala> val beginTime = commits(commits.length - 2)
scala> val tripsIncrementalDF = spark.read.format("hudi").
| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
| load(basePath)
scala> tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
// 这将提供在beginTime提交后的数据,并且fare>20的数据
scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()
时间点查询
根据特定时间查询,可以将endTime指向特定时间,beginTime指向000(表示最早提交时间)
scala> val beginTime = "000"
scala> val endTime = commits(commits.length - 2)
scala> val tripsPointInTimeDF = spark.read.format("hudi").
| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
| option(END_INSTANTTIME_OPT_KEY, endTime).
| load(basePath)
scala> tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()
删除数据
只有append模式,才支持删除功能
scala> spark.sql("select uuid, partitionPath from hudi_trips_snapshot").count()
res12: Long = 10
scala> val ds = spark.sql("select uuid, partitionPath from hudi_trips_snapshot").limit(2)
scala> val deletes = dataGen.generateDeletes(ds.collectAsList())
scala> val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2));
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(OPERATION_OPT_KEY,"delete").
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Append).
| save(basePath)
scala> val roAfterDeleteViewDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*")
scala> roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
scala> spark.sql("select uuid, partitionPath from hudi_trips_snapshot").count()
res15: Long = 8
覆盖数据
对于一些批量etl操作,overwrite覆盖分区内的数据这种操作可能会比upsert操作效率更高,即一次重新计算目标分区内的数据。因为overwrite操作可以绕过upsert操作总需要的索引、预聚合步骤
scala>spark.read.format("hudi").load(basePath+"/*/*/*/*").select("uuid","partitionpath").sort("partitionpath","uuid"). show(100, false)
scala> val inserts = convertToStringList(dataGen.generateInserts(10))
scala> val df = spark.
| read.json(spark.sparkContext.parallelize(inserts, 2)).
| filter("partitionpath = 'americas/united_states/san_francisco'")
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(OPERATION_OPT_KEY,"insert_overwrite").
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Append).
| save(basePath)
scala> spark.
| read.format("hudi").
| load(basePath + "/*/*/*/*").
| select("uuid","partitionpath").
| sort("partitionpath","uuid").
| show(100, false)
Hudi-Flink操作
安装Flink
官网下载地址https://archive.apache.org/dist/flink/
hudi(0.8)适用于Flink-11.x版本,scala使用2.12
tar -zxvf flink-1.11.3-bin-scala_2.12.tgz -C /opt/module/
添加hadoop环境变量vim /opt/module/flink-1.11.3/bin/config.sh
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_HDFS_HOME=/opt/module/hadoop-3.1.3
export HADOOP_YARN_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HADOOP_CLASSPATH=`hadoop classpath`
启动flink集群
bin/start-cluster.sh
启动flink sql client,并关联编译好的hudi依赖包
bin/sql-client.sh embedded -j /opt/module/hudi-0.8.0/packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.12-0.8.0.jar
插入数据
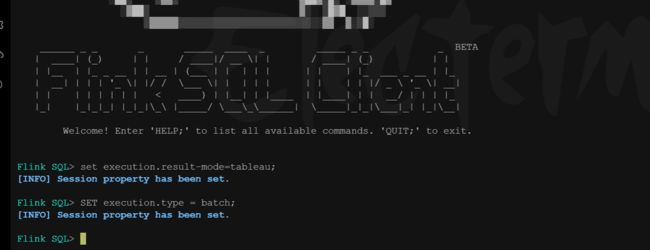
设置返回结果模式为tableau,让结果直接显示,设置处理模式为批处理
Flink SQL> set execution.result-mode=tableau;
Flink SQL> SET execution.type = batch;
创建一张Merge on Read的表,如果不指定默认为copy on write表
CREATE TABLE t1
( uuid VARCHAR(20),
name VARCHAR(10),
age INT, ts TIMESTAMP(3),
`partition` VARCHAR(20)
)PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hadoop102/flink-hudi/t1',
'table.type' = 'MERGE_ON_READ');
插入数据
INSERT INTO t1 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), ('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), ('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), ('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
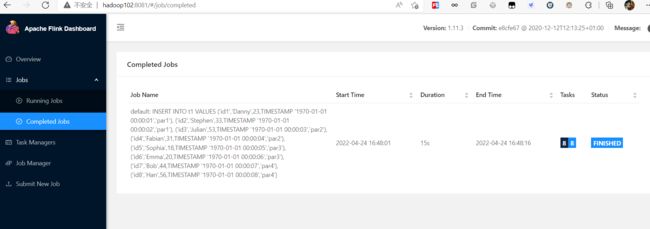
查询表数据
Flink SQL> select *from t1;
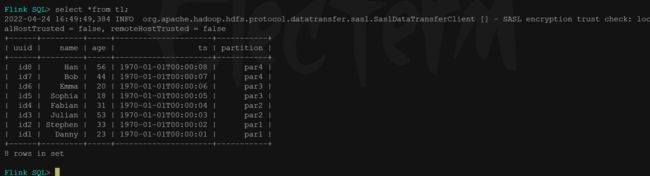
修改数据
flink sql操作hudi时很多参数不像spark需要设置,但是都有default默认值,比如上方建了t1表,插入数据时没有像spark一样指定唯一键,但是不代表flink的表就没有。参照官网参数可以看到flink表中唯一键的默认值为uuid
# 修改uuid为id1的数据,将原来年龄23岁改为27岁,
# flink sql除非第一次建表插入数据模式为overwrite,后续操作都是默认为append模式,可以直接触发修改操作
Flink SQL> insert into t1 values ('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1');