数据挖掘经典算法之:C4.5算法
一.C4.5算法
C4.5算法是对ID3算法的一种改进,所以,首先我们来看ID3算法。
ID3算法是在决策树各个结点上应用信息增益准则来选择特征,递归地构建决策树。
决策树:是一种基本的分类与回归方法,一种分类决策模型,是一种树形结构,该模型具有可读性,分类速度快的优点。决策树由结点(内部结点、叶结点)和有向边组成。内部结点表示特征或属性,叶结点表示类或结论。决策树如下图所示:其中圆点表示特征/属性(内部结点),框框表示类/结论(叶结点),——>箭头表示条件。

决策树实质上是从给定的训练数据中归纳出一组分类规则,由训练数据集估计条件概率模型的一种学习模型。该学习模型用损失函数来表示这一目标,损失函数通常是正则化的极大似然函数。
信息增益:特征A对训练数据集D的信息增益g(D,A),定义的为集合D的经验嫡H(D)与特征A 给定条件下D的经验条件嫡H(D|A)之间的差。即:g(D,A)=H(D)-H(D|A)。
H(D)表示对数据集D进行分类的不确定性,H(D|A)表示特征A给定的条件下对数据集进行分类的不确定性,所以他们的差,即信息增益就表示了由于特征A而是的对数据集D的分类不确定性减少的程度了。显然,信息增益越大的特征越具有更强的分类能力。
经验嫡概率:
条件经验嫡概率:
现在假设训数据集为D,其中![]() ,其中,
,其中,![]() 为输入实例(特征向量),n为特征个数,
为输入实例(特征向量),n为特征个数,![]() 为类标记,即标记每个实例,i=1,2,...,N,N为样本容量。
为类标记,即标记每个实例,i=1,2,...,N,N为样本容量。
|D|为训练集的样本容量,即样本的个数(N)。现假设有K个类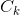 ,k=1,2,....,K,||为属于类的样本个数,
,k=1,2,....,K,||为属于类的样本个数, 。设特征A有n个不同的取值{a1,1a2,.....an},根据特征A的取值将D划分为n个子集
。设特征A有n个不同的取值{a1,1a2,.....an},根据特征A的取值将D划分为n个子集![]() ,
,
| |为 的样本个数,
|为 的样本个数,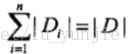 。记子集中属于类的样本集合为
。记子集中属于类的样本集合为![]() ,|
,|![]() |为
|为![]() 的样本个数。
的样本个数。
一.1信息增益公式:
输入:训练数据集D和特征A;
输出:特征A对数据训练集D的信息增益g(D,A)。
(1)计算数据集D的经验嫡H(D)

(2)计算特征A对数据集D的经验条件嫡H(D|A)

(3)计算信息增益
![]()
一.2ID3算法:
该算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归的构建决策树。具体方法为:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立的子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的
输入:训练数据集D,特征集A,阈值 ;
;
输出:决策树T。
(1)若D中所有实例属于同一类,,则T为单结点数,并将类作为该结点的类标记,返回T;
(2)若A=Ø,则T为单结点数,并将D中实例最大的类作为结点的类标记,返回T;
(3)否则,一.1中的信息增益计算方法来计算A中各特征对D的信息增益,选择信息增益最大的特征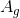 ;
;
(4)如果的信息增益小于阈值e,则置T为单结点树,并将D中实例数最大的类作为该结点的类标记,返回T;
(5)否则,对的每一个可能值 ,依=将D分割为若干非空子集,将中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
,依=将D分割为若干非空子集,将中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对第i个子结点,以为训练集,以A-{}为特征集,递归的调用步骤(1)~(5)得到子树 ,返回。
,返回。
一.3信息增益比公式:
以信息增益比作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正。这是特征选择的另一准则。
特征A对训练数据集D的信息增益比 (D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的嫡(D)之比,即
(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的嫡(D)之比,即

一.4C4.5算法:
C4.5算法是ID3算法的改进,其中C4.5算法再生成的过程中对,用信息增益比来选择特征。
输入:训练数据集D,特征A,阈值e;
输出:决策树T。
(1)如果D中所有实例属于同一类,,则T为单结点数,并将类作为该结点的类标记,返回T;
(2)如果A=Ø,则T为单结点数,并将D中实例最大的类作为结点的类,返回T;
(3)否则,按一.3中的信息增益比的计算方法来计算A中各特征对D的信息增益比,选择信息增益比最大的特征;
(4)如果的信息增益比小于阈值e,则置T为单结点树,并将D中实例数最大的类作为该结点的类,返回T;
(5)否则,对的每一个可能值,依=将D分割为若干非空子集,将中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对第i个子结点,以为训练集,以A-{}为特征集,递归的调用步骤(1)~(5)得到子树,返回。