python数据分析项目--飞猪出行用户行为分析
python数据分析项目--飞猪出行用户行为分析
- 1.项目背景
- 2.分析思路
-
- 2.1 分析流程
- 2.2 分析指标
- 3.数据分析
-
- 3.1 查看数据
- 3.2 数据清洗
- 3.3 用户维度
-
- 3.3.1 统计用户数,行为总数,人均行为数
- 3.3.2 每月用户留存率
- 3.4 行为维度
-
- 3.4.1 漏斗分析
- 3.4.2 用户行为按照月份、时刻分布
- 3.4.3 复购率
- 3.5 产品维度
-
- 3.5.1. 商品总数
- 3.5.2 Top10点击商品
- 3.5.3 Top10收藏和购买商品
- 3.5.4 计算转化率
- 3.5.5 matplotlib可视化
- 4 结论
本项目仅用于数据分析项目练习。
1.项目背景
作为中国最受欢迎的在线旅游平台(OTP)之一,阿里巴巴集团旗下的飞猪通过提供百万规模的旅游相关产品(如机票、酒店、旅行团、等等)。凭借着平台上提供的多样性产品组合,平台沉淀了用户长期的在线行为数据。通过对用户行为数据的分析,探寻用户行为规律,找到用户感兴趣的产品,为营销活动提供参考依据。
数据来源阿里云天池:User Behavior Data from Fliggy Trip Platform for Recommendation
本项目数据为用户行为数据,筛选时间为2020/06/04-2021/06/03一年的用户行为数据,每一行表示一条用户行为。数据由由用户ID、商品ID、行为类型和时间戳组成,行为类型包括(‘clk’,‘cart’,‘fav’,‘pay’)分别表示(点击,加购,收藏,购买)。
2.分析思路
通过对数据的分析,试图解决以下几个问题:
1.留存及复购率情况,检验用户黏度
2.用户行为在时间上分布
3.各行为间转换率情况并分析
2.1 分析流程
2.2 分析指标
用户维度:UV,PV,人均行为数,留存率等
行为维度:漏斗分析,月度及时刻维度行为分布,复购率等
产品维度:受欢迎产品,转化率等
3.数据分析
3.1 查看数据
原始数据无列名,读取数据时,增加列名,分别为:
# 原始数据读取后取第一行为列名,headers和names重新设置列名
df = pd.read_csv(r'user_item_behavior_history.csv',header=None,names=['Userid','Itemid','Behavior','timestamp'])
| 列名 | 含义 |
|---|---|
| Userid | 用户id |
| Itemid | 商铺id |
| Behavior | 用户行为,分别为’clk’–点击,‘cart’–加购,‘fav’–收藏,‘pay’–购买 |
| Time’stamp | 时间戳 |
3.2 数据清洗
- 将时间戳转换为标准时间,筛选日期维度为2020/6/4-2021/6/3,拆分为日期b_date和时间b_time。
# 转换时间戳至标准时间格式
df['timestamp'] = pd.to_datetime((df['timestamp']),unit='s')
# 筛选日期范围为2020/06/04-2021/06/03之间的记录
s_date = datetime.datetime.strptime('20200603', '%Y%m%d').date()
v_date = datetime.datetime.strptime('20210604', '%Y%m%d').date()
df = df[(df['timestamp'].dt.date>s_date)&(df['timestamp'].dt.date<v_date)]
print('确定日期范围后数据形状:',df.shape)
# df = df.drop(df[df['b_date']>v_date].index)
# 增加日期列b_date和时间列b_time
df['b_date'] = df['timestamp'].dt.date
df['b_time'] = df['timestamp'].dt.time
df = df.drop('timestamp',axis=1)
print('增加日期及时间列:',df.head())
# 确认日期范围
max_date = df['b_date'].max()
min_date = df['b_date'].min()
print('最大及最小日期',max_date,min_date)

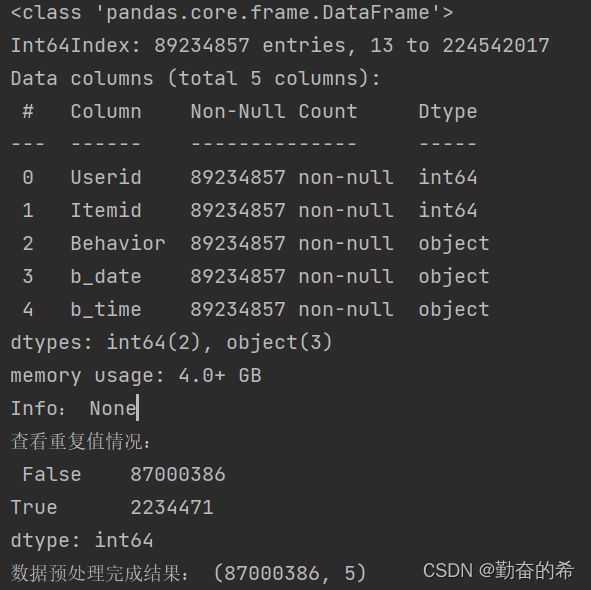
- 查看字段空值情况。注意此处用info时,由于记录条数太多,会导致无法显示空值情况,需增加参数verbose=True;
查看重复值情况,并删除重复值
# 查看空值情况
print('Info:',df.info(verbose=True,show_counts=True))
# 查看有无重复值,删除重复值
print('查看重复值情况:\n',df.duplicated().value_counts())
# False 87000405
# True 2234471
df.drop_duplicates(keep='first', inplace=True)
print('数据预处理完成结果:',df.shape)
- 重新设置索引后,存入csv文件
df = df.reset_index(drop=True)
df.to_csv(r'behavior.csv',mode='w',index=None)
3.3 用户维度
3.3.1 统计用户数,行为总数,人均行为数
重新读取清洗后的csv文件,用户各指标统计
import pandas as pd
df = pd.read_csv('behavior.csv')
# 1.用户数量 UV
unique_visitor = df['Userid'].nunique()
# 2.用户行为总数
behavior_num = df['Behavior'].count()
# 3.用户平均访问量
avg_view = round(behavior_num/unique_visitor,1)
print('1.用户数量:{}\n'
'2.用户行为总数:{}\n'
'3.用户平均访问量:{}'.
format(unique_visitor,
behavior_num,
avg_view))

3.3.2 每月用户留存率
根据每月用户id计算用户留存率
import pandas as pd
df = pd.read_csv('behavior.csv')
df['b_date'] = pd.to_datetime((df['b_date']))
df['month'] = df['b_date'].dt.month
def cal_retention(data):
df_retentions = pd.DataFrame() # 留存率为空数组
for i in range(1,13,1):
# 第i个月的用户id存入new_user
new_user = set(data['Userid'].loc[data['month']==i].unique())
m=i-1 # 用于控制存储位置
for j in range(12):
if i+j<=12:
# 第i+j个月的用户id存入users
users = data['Userid'].loc[data['month']==i+j].unique()
a = 0
# 遍历users和new_user,重复使用用户数记为a
for user_id in users:
if user_id in new_user:
a += 1
rentention_rate = a/len(new_user)
df_retentions.loc[m,m+j] = rentention_rate
else:
continue
return df_retentions
user_retention = cal_retention(df)
print(user_retention)
user_retention.columns = ['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月']
user_retention.index = ['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月']
user_retention.to_csv('retention.csv',mode='w',,encoding='utf_8_sig')
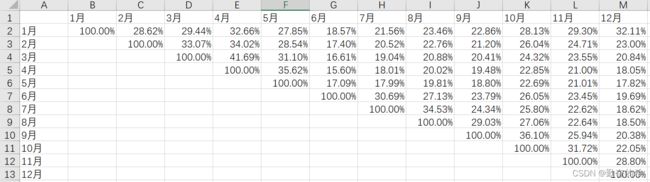
从留存率来看,6月的留存率与其他几个月相比较低,说明6月用户出行需要较低,可以加大活动优惠,增加推广渠道。
3.4 行为维度
3.4.1 漏斗分析
- 各行为数量
import pandas as pd
import time
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from matplotlib.collections import PatchCollection
import numpy as np
df = pd.read_csv(r'behavior.csv')
# 1.用户点击次数 PV
clk_num = df['Behavior'].loc[df['Behavior']=='clk'].count()
# 2.用户加购次数
cart_num = df['Behavior'].loc[df['Behavior']=='cart'].count()
# 3.用户收藏次数
fav_num = df['Behavior'].loc[df['Behavior']=='fav'].count()
# 4.用户购买次数
pay_num = df['Behavior'].loc[df['Behavior']=='pay'].count()
print('1.用户点击次数:{}\n'
'2.用户加购次数:{}\n'
'3.用户收藏次数:{}\n'
'4.用户购买次数:{}'.
format(clk_num,
cart_num,
fav_num,
pay_num))
- 漏斗图绘制
参考链接使用Python matplotlib库绘制漏斗图,介绍非常详细!
# 8.漏斗图--matplotlib--ok
plt.style.use('seaborn-dark') # 设置主题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data = [clk_num, cart_num, fav_num, pay_num]
phase = ['点击次数', '加购次数', '收藏次数', '购买次数']
data1 = [clk_num/2 - i/2 for i in data] # 用来覆盖柱形图左边
data2 = [i+j for i,j in zip(data, data1)] # 柱形图长度=data+覆盖柱形图长度
color_list = [ '#00685A', '#1E786C','#00A08A','#34D0BA'] # 柱子颜色
fig,ax = plt.subplots(figsize=(16, 9),facecolor='#f4f4f4')
ax.set_title('用户转化漏斗图',fontsize=18)
ax.barh(phase[::-1], data2[::-1], color = color_list, height=0.7) # 柱宽设置为0.7
ax.barh(phase[::-1], data1[::-1], color = '#f4f4f4', height=0.7) # 设置成背景同色,覆盖柱形图
ax.axis('off')
polygons = []
for i in range(len(data)):
# 阶段
ax.text(
0, # 坐标
i, # 高度
phase[::-1][i], # 文本,phase[::-1]表示将列表倒序排列
color='black', alpha=0.8, size=16, ha="right")
# 数量
if i < 3:
ax.text(
data2[0] / 2,
i,
str(data[::-1][i]) + '(' + str(round(data[::-1][i] / data[::-1][i+1] * 100, 1)) + '%)',
color='black', alpha=0.8, size=14, ha="center")
else:
ax.text(
data2[0] / 2,
i,
str(data[::-1][i]) ,
color='black', alpha=0.8, size=14, ha="center")
if i < 3:
# 绘制过渡多边形
polygons.append(Polygon(xy=np.array([(data1[i + 1], 2 + 0.35 - i), # 因为柱状图的宽度设置成了0.7,所以一半便是0.35
(data2[i + 1], 2 + 0.35 - i),
(data2[i], 3 - 0.35 - i),
(data1[i], 3 - 0.35 - i)])))
# 使用add_collection与PatchCollection来向Axes上添加多边形
ax.add_collection(PatchCollection(polygons,
facecolor='#F56E8D',
alpha=0.8));
plt.show()
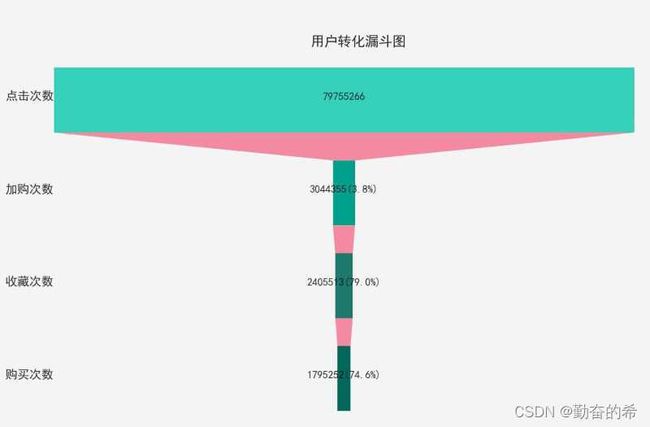
通过漏斗分析,发现点击后的收藏或加购极具减少,导致了购买量比例较低。
3.4.2 用户行为按照月份、时刻分布
- 按月份分布
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv(r'behavior.csv')
# 显示中文设置...
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 每月用户的点击量,访客数,收藏次数,加入购物车次数,购买次数--ok
# 通过比较每月的数据,对较低的数据进行具体分析
df['b_date'] = pd.to_datetime(df['b_date'])
df['month'] = df['b_date'].dt.month
# 每月用户点击量、收藏量、加购量、购买量
clk_month = df[['Userid', 'Behavior', 'month']].loc[df['Behavior']=='clk'].groupby('month').agg('count')
# print('clk_month',clk_month)
cart_month = df[['Userid', 'Behavior', 'month']].loc[df['Behavior']=='cart'].groupby('month').agg('count')
# print('cart_month',cart_month)
fav_month = df[['Userid', 'Behavior', 'month']].loc[df['Behavior']=='fav'].groupby('month').agg('count')
# print('fav_month',fav_month)
pay_month = df[['Userid', 'Behavior', 'month']].loc[df['Behavior']=='pay'].groupby('month').agg('count')
# print('pay_month', pay_month)
months = [1,2,3,4,5,6,7,8,9,10,11,12]
- 按时刻分布
# 按时段统计用户的点击量,访客数,收藏次数,加入购物车次数,购买次数--ok
df['b_time'] = pd.to_datetime(df['b_time'],format ='%H:%M:%S')
df['b_hour'] = df['b_time'].dt.hour
print(df.head())
# 每小时点击量
clk_hour = df[['Userid','Behavior','b_hour']].loc[df['Behavior']=='clk'].groupby('b_hour').agg('count')
print(clk_hour)
# 每小时购买数
pay_hour = df[['Userid','Behavior','b_hour']].loc[df['Behavior']=='pay'].groupby('b_hour').agg('count')
print(pay_hour)
hours = range(24)
- 绘制图形
fig,ax = plt.subplots(4,1)
ax[0].plot(hours,clk_hour['Behavior'])
ax[0].set_title('每小时点击数')
ax[1].plot(hours,pay_hour['Behavior'])
ax[1].set_title('每小时购买数')
ax[2].plot(months,clk_month['Behavior'],'r-')
ax[2].set_title('每月点击数')
ax[3].plot(months,cart_month['Behavior'],'g--',
months,fav_month['Behavior'],'b-.',
months,pay_month['Behavior'],'k:')
ax[3].set_title('每月加购/收藏/购买数')
plt.show()

根据时刻分布,18-21点点击量较低,也导致购买数较低。此时间段大部分人处于夜间活动时间,对用户行为数据造成较大影响。上午到中午用户行为数较大,可以增加优惠活动推送。
根据月度分布,1、2月和6月数据较低。1、2月与春节有关,旅游需求降低。6月数据较低还需结合其他数据进一步分析,例如通过用户年龄及职业数据,分析是否由于学生毕业季前考试及就业压力,拉低整体活跃数据。
3.4.3 复购率
# 复购率
re_pay = df[['Userid','Behavior']].loc[df['Behavior']=='pay'].groupby('Userid').agg('count').sort_values(by='Behavior',ascending=False)
re_pay.rename(columns={'Behavior':'pay_times'},inplace=True)
re_pay.reset_index(inplace=True)
# print('re_pay:\n',re_pay)
re_pay2 = re_pay[re_pay['pay_times']>1]
re_pay2.reset_index(inplace=True)
# print(re_pay2.head(10))
m = re_pay2['Userid'].nunique()
n = re_pay['Userid'].nunique()
repay_rate = str(round(m/n*100,2))+'%'
print('复购率:{}'.format(repay_rate))
购买用户:610328
复购用户:354690
复购率:58.11%
复购率反映了商品对用户的黏度,复购率表示购买次数大于1的用户在所有购买用户中所占比例。
通过统计用户购买次数,复购率为58.11%。
3.5 产品维度
3.5.1. 商品总数
统计商品总数
import pandas as pd
df = pd.read_csv('behavior.csv')
# 商品总数
item_num = df['Itemid'].nunique()
print('商品总数:{}'.format(item_num))
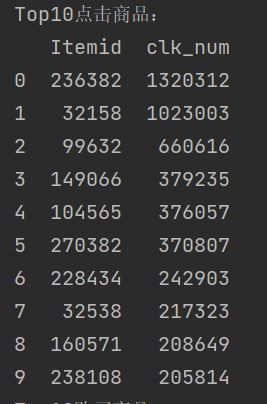
3.5.2 Top10点击商品
# 商品点击量统计
item_clk_num = df[['Itemid','Behavior']].loc[df['Behavior']=='clk'].groupby('Itemid').\
agg('count').sort_values(by='Behavior',ascending=False)
item_clk_num.reset_index(inplace=True)
item_clk_num.rename(columns={'Behavior':'clk_num'},inplace=True)
print('Top10点击商品:\n{}'.format(item_clk_num.head(10)))
3.5.3 Top10收藏和购买商品
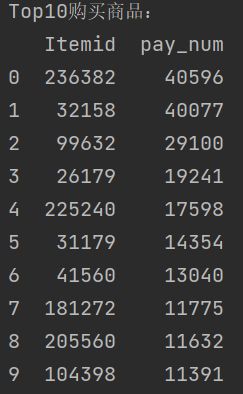
# 商品购买量统计
item_pay_num = df[['Itemid','Behavior']].loc[df['Behavior']=='pay'].groupby('Itemid').agg('count').sort_values(by='Behavior',ascending=False)
item_pay_num.reset_index(inplace=True)
item_pay_num.rename(columns={'Behavior':'pay_num'},inplace=True)
print('Top10购买商品:\n{}'.format(item_pay_num.head(10)))
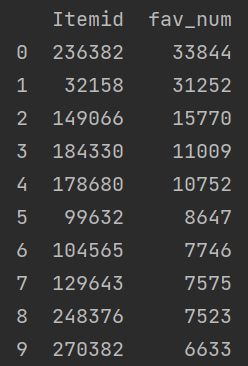
# 商品收藏量统计
item_fav_num = df[['Itemid','Behavior']].loc[df['Behavior']=='fav'].groupby('Itemid').agg('count').sort_values(by='Behavior',ascending=False)
item_fav_num.reset_index(inplace=True)
item_fav_num.rename(columns={'Behavior':'fav_num'},inplace=True)
print('Top10点击商品:\n{}'.format(item_fav_num.head(10)))
3.5.4 计算转化率
将点击量、收藏量、购买量合并,计算点击-购买转换率ctop_rate和收藏-购买转化率ftop_rate
df1 = item_clk_num.merge(item_pay_num,on='Itemid').merge(item_fav_num,on='Itemid')
df1 = df1.sort_values(by='clk_num',ascending=False)
df1['ctop_rate'] = round(df1['pay_num']/df1['clk_num'],4)
df1['ftop_rate'] = round(df1['pay_num']/df1['fav_num'],4)
ctop_avg_rate = round(df1['pay_num'].sum()/df1['clk_num'].sum(),2)
ftop_avg_rate = round(df1['pay_num'].sum()/df1['fav_num'].sum(),2)
3.5.5 matplotlib可视化
# 点击-购买转化率排行
df2 = df1[['Itemid','clk_num','ctop_rate']].loc[df1['clk_num']>100000].sort_values(by='ctop_rate',ascending=False)
# 收藏-购买转化率排行
df3 = df1[['Itemid','fav_num','ftop_rate']].loc[df1['fav_num']>3000].sort_values(by='ftop_rate',ascending=False)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
fig = plt.figure()
colors = ['#CC9999','#FFFF99','#666699','#FF9900','#0099CC',
'#CCCC99','#CC3399','#FF6666','#009999','#009966']
scale_ls = range(10)
# 点击-购买转化率
ax1 = fig.add_subplot(211)
ax1.set_title('点击Top10商品购买转化率',fontsize=14)
index_ls1 = df2.Itemid.iloc[0:10]
a1 = ax1.bar(scale_ls,df2.clk_num.iloc[0:10],color=colors,width=0.8) # 柱状图显示点击量
ax1.bar_label(a1)
ax1.set_xlabel('商品ID', size = 10)
ax1.set_ylabel('点击量', size = 10)
ax2 = ax1.twinx()
ax2.plot(scale_ls,df2.ctop_rate.iloc[0:10])
ax2.set_xticks(scale_ls,index_ls1) ## 可以设置坐标字
ax2.set_ylabel('点击-购买转化率', size = 10)
ax2.yaxis.set_major_formatter(ticker.PercentFormatter(xmax=1, decimals=1))
ax2.axhline(y=ctop_avg_rate,c='r',ls=':',label='平均点击-购买转换率') #添加水平直线
# 收藏-购买转化率
ax3 = fig.add_subplot(212)
ax3.set_title('收藏Top10商品购买转化率',fontsize=14)
index_ls2 = df3.Itemid.iloc[0:10]
a3 = ax3.bar(scale_ls,df3.fav_num.iloc[0:10],color=colors,width=0.8) # 柱状图显示点击量
ax3.bar_label(a3)
ax3.set_xticks(scale_ls,index_ls2) ## 可以设置坐标字
ax3.set_xlabel('商品ID', size = 10)
ax3.set_ylabel('收藏量', size = 10)
ax4 = ax3.twinx()
ax4.axhline(y=ftop_avg_rate,c='r',ls=':',label='平均点击-购买转换率') #添加水平直线
ax4.plot(scale_ls,df3.ftop_rate.iloc[0:10])
ax4.set_ylabel('收藏-购买转化率', size = 10)
ax4.yaxis.set_major_formatter(ticker.PercentFormatter(xmax=1, decimals=1))
plt.tight_layout() # 自动调整各子图间距
plt.show()

通过对商品的分析,点击量或收藏量高的商品,购买转化率不一定高,可以对点击量或收藏量高的商品增加关注。如商品ID为32158,点击量超过100万,但是转化率只有4%。
4 结论
- 用户留存率及复购率指标较好,反映了用户良好的黏度。但是从留存率分布来看,6月份用户留存下降明显;
- 用户行为将一年的数据按月度分布来看,6月用户行为最少,从每日时刻来看,18-21点用户行为数量较低;
- 用户各行为转化率问题较大,其中点击到加购的转化率只有3.8%。说明用户点击浏览过程中,感兴趣的商品较少。需进一步分析用户实际需求,针对性推送商品,提升相应转化率;
- 针对商品维度分析,高点击量未能带来高购买量。用户关注此类商品点击进入,但是未能发现吸引用户的优势,针对高点击量产品需重点优化。