scrapy笔记
文章目录
-
- 1.scrapy组成
- 2.scrapy工作原理
- 3.小栗子-01
-
- 3.1后续request
- 4.CrawlSpider
-
- 4.1小栗子-02
- 4.数据入库
- 安装scrapy
在python文件的scripts目录下打开cmd
pip install scrapy
可能安装失败
1.scrapy是基于twisted,先下载twisted对应版本的whl文件
2.提示upgrade pip,那就python -m pip install --upgrade pip
3.或者直接安装anaconda,这是个重量级,里面啥都有,就是有点难下载
- 创建scrapy项目
1.在当前正在使用的python项目下,或者新建一个目录
2.从该目录进入cmd窗口
-创建项目:不允许数字开头,不允许包含中文及中文符号
scrapy startproject 项目名字
-创建文件:在spiders文件夹中创建爬虫文件
cd 项目名字\项目名字\spiders
scrapy genspider 爬虫文件名字 要爬取的网页(域名)
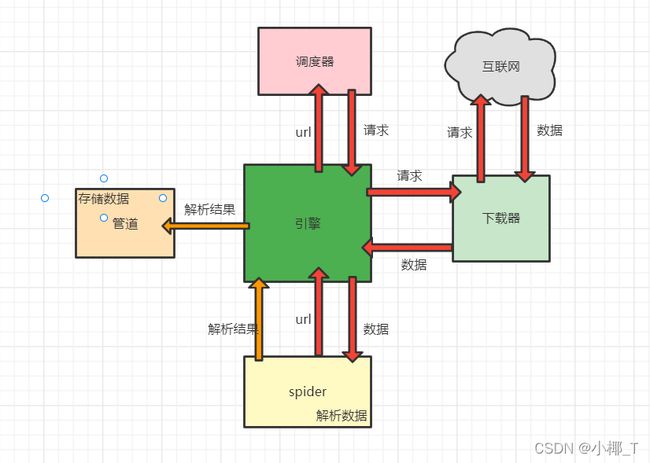
1.scrapy组成
基于Twisted的异步处理框架
- Engine:引擎;处理整个系统的数据流处理,触发事务,整个框架的核心
- Item:项目;定义爬取结果的数据结构,爬取的数据会被赋值成该item对象
- Scheduler:调度器;接受引擎发过来的请求,并将其加入队列中,在引擎再次请求的时候将请求提供给引擎
- Downloader:下载器;下载网页内容,并将网页内容返回给Spiders
- Spiders:定义爬取逻辑和网页的解析规则,主要负责解析响应并生成提取结果和新的请求
- Item Pipeline:管道;负责处理由Spiders从网页中抽取的项目,主要任务是清洗,验证和存储数据
2.scrapy工作原理
数据流:
3.小栗子-01
小介绍:
-name:每个项目唯一的名字,用来区分不同的Spider
-allowed_domains:允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉
-start_urls:包含Spider在启动时爬取的url列表,初始请求由他来定义
-parse:Spider的一个方法。默认情况下,被调用时start_urls里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。然后该方法解析返回的响应,提取数据或者进一步生成要处理的请求
- spider
import scrapy
from scr_piao_01.items import ScrPiao01Item
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['category.dangdang.com']
# 起始的url地址(第一次要访问的域名)
start_urls = ['http://category.dangdang.com/cp01.01.08.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
# 方法中的返回对象response相当于response=urllib.request.urlopen()
def parse(self, response):
# 所有的selector对象,都可以再次调用xpath方法,extract_first()获取selector列表的第一个元素
li_lst = response.xpath('//ul[@id="component_59"]/li')
for li in li_lst:
src = li.xpath('.//img/@data-original').extract_first()
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
alt = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrPiao01Item(src=src, name=alt, price=price)
yield book
if self.page < 100:
self.page += 1
url_next = self.base_url + str(self.page)+'-cp01.01.08.00.00.00.html'
yield scrapy.Request(url=url_next, callback=self.parse)
- items
item是保存爬取的容器,它的使用方法和字典类似。多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建item需要继承scrapy.Item类。并且定义类型为scrapy.Field的字段
class ScrPiao01Item(scrapy.Item):
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
- pipelines
通过管道存储数据到文件或数据库
class ScrPiao01Pipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# with open('book.json', 'a', encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
3.1后续request
上面这个只爬取了初始页面的60条数据,对于下一页或者后面的数据怎么获取呢?
首先从当前页面中找到下一页的请求信息,然后在下一个请求的页面里找到信息再构造下下一个请求,一直迭代下去,就实现整站的爬取啦!
先瞅瞅那个每页的url
构造请求时要用到scrapy.Request
构造请求时要用到scrapy.Request,传递的参数
-url:请求链接
-callback:回调函数,当指定了该回调函数的请求完成==>获取到响应==>引擎再将该响应传递给这个回调函数
要注意allowed_domains
4.CrawlSpider
crawlspider为全站爬取而生的。CrawlSpider可以定义规则,在解析HTML内容的时候,根据规则提取指定的链接,然后再向这些链接发送请求。
- 链接提取
from scrapy.linkextractors import LinkExtractor
常用:
1.正则表达式,提取符合的链接;为空就全部匹配:allow=()
2.xpath,提取符合xpath规则的链接:restrict_xpaths=()
3.提取符合css规则的链接:restrict_css=()
其他:
4.与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取:deny=()
5.会被提取的链接的domains: allow_domains=()
6.一定不会被提取链接的domains: deny_domains=()
# 模拟用法
link01 = LinkExtractor(allow=r'**************')
link02 = LinkExtractor(restrict_xpaths=r'**************')
link02 = LinkExtractor(restrict_css=r'**************')
# 提取链接
link.extract_links(response)
4.1小栗子-02
创建项目及文件
-scrapy startproject dushuproject
-cd dushuproject\dushuproject\spiders
-scrapy genspider -t crawl xiaoye https://www.dushu.com/book/1617.html
- spiders
这里有个不大不小的大坑~~
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from dushuproject.items import DushuprojectItem
class XiaoyeSpider(CrawlSpider):
name = 'xiaoye'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1617.html']
# 把follow改成True,会按照链接提取的规则自动跟进。把所有页面的数据都给他薅下来
rules = (
Rule(LinkExtractor(allow=r'/book/1617_\d+\.html'),
callback='parse_item',
follow=False),
)
def parse_item(self, response):
img_lst = response.xpath('//div[@class="bookslist"]//img')
for img in img_lst:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = DushuprojectItem(name=name, src=src)
yield book
- items
class DushuprojectItem(scrapy.Item):
name = scrapy.Field()
src = scrapy.Field()
- pipelines
class DushuprojectPipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
那个不大不小的大坑在这里~
start_urls = ['https://www.dushu.com/book/1617.html']
那个规则rules里面的LinkExtractor(allow=r'/book/1617_\d+\.html')的正则表达式是从第2页开始的,那么首页start_urls不在规则里面可不就获取不到了么
-> start_urls = ['https://www.dushu.com/book/1617_1.html']
注意
- crawlspider中callback只能写函数名字字符串,callback=‘parse_item’
- 在一般的spider中,比如小栗子-01中,callback=self.parse
4.数据入库
/*先进入MySQL创建数据库和要用的表*/
create database spider01 charset=utf8;
use spider01;
create table book(
id int primary key auto_increment,
name varchar(128),
src varchar(128));
- settings
DB_HOST = 'localhost'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = 'xiaoye777'
DB_NAME = 'spider01'
DB_CHARSET = 'utf8'
# 给入库加条管道
ITEM_PIPELINES = {
'dushuproject.pipelines.DushuprojectPipeline': 300,
# MysqlPipeline
'dushuproject.pipelines.MysqlPipeline': 301
}
- 再开一条管道将数据放入mysql
# 导入settings中的数据
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
self.cursor.execute(sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()