B站韩顺平java学习笔记(十三)-- 集合章节
目录
一 集合的理解和好处
1 数组
2 集合
二 集合的框架体系
三 Collection
1 Collection接口实现类的特点
2 Collection接口常用方法
3 Collection接口迭代器遍历
(1)Collection接口遍历元素方式1 -- 使用Iterator(迭代器)
(2)Collection接口遍历元素方式1 -- 使用for循环加强
4 List接口和常用方法
(1)List接口基本介绍
(2)List接口的常用方法
(3)List的三种遍历方式
5 ArrayList 的注意事项
6 ArrayList 底层结构和源码分析
(1)ArrayList 的底层操作机制源码分析
7 Vector底层结构和源码剖析
(1)Vector的基本介绍
(2)Vector 和 ArrayList 的比较
(3)Vector的底层扩容结构
(4)LinkedList 底层结构
(5)ArrayList 和 LinkedList 比较
8 Set 接口和常用方法
(1)Set 接口基本介绍
(2)Set 接口的常用方法
(3)Set 接口的遍历方式
(4)Set接口的常用方法举例
9 Set 接口实现类-HashSet
(1)HashSet的全面说明
(2)HashSet案例说明
(3)HashSet 底层机制说明
(4)HashSet 课堂练习
10 Set 接口实现类-LinkedHashSet
(1)LinkedHashSet 的全面说明
(2)LinkedHashSet练习题
四 Map
1 Map 接口和常用方法
(1)Map 接口实现类的特点 [很实用]
(2)Map接口常用方法
(3)Map接口遍历方法
(4)Map接口课堂练习
2 Map 接口实现类-HashMap
(1)HashMap小结
(2)HashMap 底层机制及源码剖析
3 Map 接口实现类-Hashtable
(1)HashTable 的基本介绍
(2)Hashtable 和 HashMap 对比
4 Map 接口实现类-Properties
(1)基本介绍
(2)基本使用(增删改查)
5 TreeSet源码分析
6 TreeMap源码分析
7 总结-开发中如何选择集合实现类
五 Collections
1 介绍
2 排序、查找、替换(static操作)
六 课后习题
1 HashSet和TreeSet去重机制的叙述
2 代码分析题
3 程序阅读题
知识点
1 快捷键
(1)快速遍历迭代器Iterator循环方式1
(2)快速遍历迭代器for循环方式2
(3)显示所以快捷键的快捷键
2 Debugger细节显示问题
一 集合的理解和好处
1 数组
(1)长度开始时必须指定,而且一旦指定,不能更改;
(2)保存的必须为同一类型的元素;
(3)使用数组进行增加/删除元素的代码比较麻烦。
Person的数组扩容代码:

增加新的Person对象:

2 集合
(1)可以动态保存任意多个对象,使用比较方便;
(2)提供了一系列方便的操作对象的方法:add,remove,set,get等;
(3)使用集合添加,删除新元素的代码简洁。
二 集合的框架体系
Java的集合类很多,主要分为两大类:
(1)集合主要是两组(单列集合 , 双列集合);
(2)Collection 接口有两个重要的子接口 List Set , 他们的实现子类都是单列集合;
(3)Map 接口的实现子类 是双列集合,存放的 K-V;
(4)梳理的两张图记住。


public static void main(String[] args) {
//Collection
//Map
ArrayList arrayList = new ArrayList();
arrayList.add("jack");
arrayList.add("tom");
HashMap hashMap = new HashMap();
hashMap.put("NO1", "北京");
hashMap.put("NO2", "上海");
}
}三 Collection
1 Collection接口实现类的特点
public interface Collection
(1)Collection实现子类可以存放多个元素,每个元素可以是Object;
(2)有些Collection的实现类,可以存放重复的元素,有些不可以;
(3)有些Collection的实现类,有些是有序的(List),有些不是有序(Set);
(4)Collection接口没有直接的实现子类,是通过它的子接口Set 和 List来实现的。
2 Collection接口常用方法
public static void main(String[] args) {
List list = new ArrayList();//接口可以指向实现该接口的类
//add:添加单个元素
list.add("lll");
list.add(1);//有自动装箱的过程 list.add(new Integer(1));
list.add(true);//有自动装箱的过程
System.out.println(list);//list里的元素都是对象
//remove:删除指定元素 【两种方式】
list.remove("111");//指定删除某个元素
list.remove(0);//按下标删除第一个元素
//contains:查找元素是否存在
System.out.println(list.contains("111"));
//有返回true,无返回false
//size:获取元素个数
System.out.println(list.size());
//isEmpty:判断是否为空
System.out.println(list.isEmpty());
//clear:清空
list.clear();
//addAll:添加多个元素
ArrayList list1 = new ArrayList();
list1.add("haha");
list1.add("3213");
list.addAll(list1);
System.out.println(list);
//containsAll:查找多个元素是否存在
System.out.println(list.containsAll(list1));//都存在返回true
//removeAll:删除多个元素
list.removeAll(list1);
}
}3 Collection接口迭代器遍历
(1)Collection接口遍历元素方式1 -- 使用Iterator(迭代器)
基本介绍:

① Iterator对象称为迭代器,主要用于遍历Collection集合中的元素;
② 所有实现了Collection接口的集合类都有一个iterator()方法,用于返回一个实现了Iterator接口的对象,即可以返回一个迭代器;
③ Iterator 的结构;

④ Iterator仅用于遍历集合, Iterator本身不存放对象。

实例:
public class CollectionIterator {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义", "罗贯中", 10.1));
col.add(new Book("小李飞刀", "古龙", 5.1));
col.add(new Book("红楼梦", "曹雪芹", 34.6));
//System.out.println("col=" + col);
//现在希望能够遍历 col集合
//1. 先得到 col 对应的 迭代器
Iterator iterator = col.iterator();
//2. 使用while循环遍历
// while (iterator.hasNext()) {//判断是否还有数据
// //返回下一个元素,类型是Object
// Object obj = iterator.next();
// System.out.println("obj=" + obj);
// }
//一个快捷键,快速生成 while => itit
//显示所有的快捷键的的快捷键 ctrl + j
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//3. 当退出while循环后 , 这时iterator迭代器,指向最后的元素
// iterator.next();//NoSuchElementException
//4. 如果希望再次遍历,需要重置我们的迭代器
iterator = col.iterator();
System.out.println("===第二次遍历===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
}
class Book {
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
(2)Collection接口遍历元素方式1 -- 使用for循环加强
增强for循环,可以代替iterator迭代器,特点:增强for就是简化本的iterator,本质一样。只能用于遍历集合或数组。
基本语法:
for(元素类型(先使用object) 元素名 :集合名或数组名){
访问元素
}
public class CollectionFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义", "罗贯中", 10.1));
col.add(new Book("小李飞刀", "古龙", 5.1));
col.add(new Book("红楼梦", "曹雪芹", 34.6));
//1. 使用增强for, 在Collection集合
//2. 增强for, 底层仍然是迭代器
//3. 增强for可以理解成就是简化版本的 迭代器遍历
//4. 快捷键方式 I
// for (Object book : col) {
// System.out.println("book=" + book);
// }
for (Object o : col) {
System.out.println("book=" + o);
}
//增强for,也可以直接在数组使用
// int[] nums = {1, 8, 10, 90};
// for (int i : nums) {
// System.out.println("i=" + i);
// }
}
}4 List接口和常用方法
(1)List接口基本介绍
① List集合类中元素有序(即添加顺序和取出顺序一致)、且可重复;
② List集合中的每个元素都有其对应的顺序索引(即一个整数型的序号记载其在容器中的文字hi,可以根据序号存取容器中的元素),即支持索引;
③ JDK API 中List接口的实现类:

常用的有 ArrayList、LinkedList、Vector。
public class List_ {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//1. List集合类中元素有序(即添加顺序和取出顺序一致)、且可重复 [案例]
List list = new ArrayList();
list.add("jack");
list.add("tom");
list.add("mary");
list.add("hsp");
list.add("tom");
System.out.println("list=" + list);
//2. List集合中的每个元素都有其对应的顺序索引(即一个整数型的序号记载
//其在容器中的文字hi,可以根据序号存取容器中的元素),即支持索引。
// 索引是从0开始的
System.out.println(list.get(3));//hsp
}
}
(2)List接口的常用方法
① void add(int index, Object ele):在index位置插入ele元素,没有index,默认在最后插入
② boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
③ Object get(int index):获取指定index位置的元素
④ int indexOf(Object obj):返回obj在集合中首次出现的位置
⑤ int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
⑥ Object remove(int index):移除指定index位置的元素,并返回此元素
⑦ Object set(int index, Object ele):设置指定index位置的元素为ele , 相当于是替换.
⑧ List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合,注意返回的子集合 fromIndex <= subList < toIndex
public class ListMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
// void add(int index, Object ele):在index位置插入ele元素
//在index = 1的位置插入一个对象
list.add(1, "韩顺平");
System.out.println("list=" + list);
// boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list=" + list);
// Object get(int index):获取指定index位置的元素
//说过
// int indexOf(Object obj):返回obj在集合中首次出现的位置
System.out.println(list.indexOf("tom"));//2
// int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
list.add("韩顺平");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("韩顺平"));
// Object remove(int index):移除指定index位置的元素,并返回此元素
list.remove(0);
System.out.println("list=" + list);
// Object set(int index, Object ele):设置指定index位置的元素为ele , 相当于是替换.
list.set(1, "玛丽");
System.out.println("list=" + list);
// List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
// 注意返回的子集合 fromIndex <= subList < toIndex
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
}
}
(3)List的三种遍历方式
ArrayList, LinkedList,Vector三种遍历使用的方式一致。
public class ListFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//List 接口的实现子类 Vector LinkedList
//List list = new ArrayList();
//List list = new Vector();
List list = new LinkedList();
list.add("jack");
list.add("tom");
list.add("鱼香肉丝");
list.add("北京烤鸭子");
//遍历
//1. 迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
}
System.out.println("=====增强for=====");
//2. 增强for
for (Object o : list) {
System.out.println("o=" + o);
}
System.out.println("=====普通for====");
//3. 使用普通for
for (int i = 0; i < list.size(); i++) {
System.out.println("对象=" + list.get(i));
}
}
}课堂练习:

@SuppressWarnings({"all"})
public class ListExercise02 {
public static void main(String[] args) {
//List list = new ArrayList();
List list = new LinkedList();
//List list = new Vector();
list.add(new Book("红楼梦", "曹雪芹", 100));
list.add(new Book("西游记", "吴承恩", 10));
list.add(new Book("水浒传", "施耐庵", 19));
list.add(new Book("三国", "罗贯中", 80));
//list.add(new Book("西游记", "吴承恩", 10));
//如何对集合进行排序
//遍历
for (Object o : list) {
System.out.println(o);
}
//冒泡排序
sort(list);
System.out.println("==排序后==");
for (Object o : list) {
System.out.println(o);
}
}
//静态方法
//价格要求是从小到大
public static void sort(List list) {
int listSize = list.size();
for (int i = 0; i < listSize - 1; i++) {
for (int j = 0; j < listSize - 1 - i; j++) {
//取出对象Book
Book book1 = (Book) list.get(j);//向下转型
Book book2 = (Book) list.get(j + 1);
if (book1.getPrice() > book2.getPrice()) {//交换
list.set(j, book2);
list.set(j + 1, book1);
}
}
}
}
}5 ArrayList 的注意事项
(1)permits all elements,including null,ArrayList可以加入null,并且可以有多个;
(2)ArrayList 是由数组来实现数据存储的;
(3)ArrayList 基本等同于Vector,除了ArrayList是线程不安全的(但执行效率高),在多线程情况下,不建议使用ArrayList。
6 ArrayList 底层结构和源码分析
(1)ArrayList 的底层操作机制源码分析
① ArrayList中维护了一个object类型的数组elementData;
transient Object[] elementData;//transient 表示瞬间,短暂的,表示该属性不能被序列号;
② 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第一次田间,则扩容elementData为10,如果需要再次扩容,则扩容elementData为1.5倍;
@SuppressWarnings({"all"})
public class ArrayListSource {
public static void main(String[] args) {
//解读源码
//注意,注意,注意,Idea 默认情况下,Debug 显示的数据是简化后的,如果希望看到完整的数据
//需要做设置.
//使用无参构造器创建ArrayList对象
ArrayList list = new ArrayList();
//ArrayList list = new ArrayList(8);
//使用for给list集合添加 1-10数据
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//使用for给list集合添加 11-15数据
for (int i = 11; i <= 15; i++) {
list.add(i);
}
list.add(100);
list.add(200);
list.add(null);
}
}


③ 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍。
@SuppressWarnings({"all"})
public class ArrayListSource {
public static void main(String[] args) {
//解读源码
//注意,注意,注意,Idea 默认情况下,Debug 显示的数据是简化后的,如果希望看到完整的数据
//需要做设置.
//使用无参构造器创建ArrayList对象
//ArrayList list = new ArrayList();
ArrayList list = new ArrayList(8);
//使用for给list集合添加 1-10数据
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//使用for给list集合添加 11-15数据
for (int i = 11; i <= 15; i++) {
list.add(i);
}
list.add(100);
list.add(200);
list.add(null);
}
}

7 Vector底层结构和源码剖析
(1)Vector的基本介绍
① 定义说明;

② Vector底层是一个对象数组,protected Object[] elementData;
③ Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized;
④ 开发中,需要线程同步安全时,考虑使用Vector。
(2)Vector 和 ArrayList 的比较

(3)Vector的底层扩容结构
@SuppressWarnings({"all"})
public class Vector_ {
public static void main(String[] args) {
//无参构造器
//有参数的构造
Vector vector = new Vector(8);
for (int i = 0; i < 10; i++) {
vector.add(i);
}
vector.add(100);
System.out.println("vector=" + vector);
//老韩解读源码
//1. new Vector() 底层
/*
public Vector() {
this(10);
}
补充:如果是 Vector vector = new Vector(8);
走的方法:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
2. vector.add(i)
2.1 //下面这个方法就添加数据到vector集合
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
2.2 //确定是否需要扩容 条件 : minCapacity - elementData.length>0
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
2.3 //如果 需要的数组大小 不够用,就扩容 , 扩容的算法
//newCapacity = oldCapacity + ((capacityIncrement > 0) ?
// capacityIncrement : oldCapacity);
//就是扩容两倍.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
*/
}
}
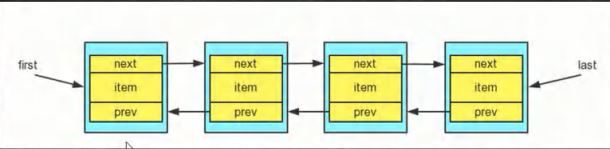
(4)LinkedList 底层结构
① LinkedList的说明
a LinkedList底层实现了双向链表和双端队列的特点;
b 可以添加任意元素(元素可以重复),包括null;
c 线程不安全,没有实现同步。
② LinkedList的底层操作机制
a LinkedList底层维护了一个双向链表;
b LinkedList中维护了两个属性first 和 last 分别指向首节点和尾节点;
c 每个节点(Node对象),里面又维护了prev、next、item三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表;
d 所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率比较高;
e 模拟一个简单的双向链表。
public class LinkedList01 {
public static void main(String[] args) {
//模拟一个简单的双向链表
Node jack = new Node("jack");
Node tom = new Node("tom");
Node hsp = new Node("老韩");
//连接三个结点,形成双向链表
//jack -> tom -> hsp
jack.next = tom;
tom.next = hsp;
//hsp -> tom -> jack
hsp.pre = tom;
tom.pre = jack;
Node first = jack;//让first引用指向jack,就是双向链表的头结点
Node last = hsp; //让last引用指向hsp,就是双向链表的尾结点
//演示,从头到尾进行遍历
System.out.println("===从头到尾进行遍历===");
while (true) {
if(first == null) {
break;
}
//输出first 信息
System.out.println(first);
first = first.next;
}
//演示,从尾到头的遍历
System.out.println("====从尾到头的遍历====");
while (true) {
if(last == null) {
break;
}
//输出last 信息
System.out.println(last);
last = last.pre;
}
//演示链表的添加对象/数据,是多么的方便
//要求,是在 tom --------- 老韩直接,插入一个对象 smith
//1. 先创建一个 Node 结点,name 就是 smith
Node smith = new Node("smith");
//下面就把 smith 加入到双向链表了
smith.next = hsp;
smith.pre = tom;
hsp.pre = smith;
tom.next = smith;
//让first 再次指向jack
first = jack;//让first引用指向jack,就是双向链表的头结点
System.out.println("===从头到尾进行遍历===");
while (true) {
if(first == null) {
break;
}
//输出first 信息
System.out.println(first);
first = first.next;
}
last = hsp; //让last 重新指向最后一个结点
//演示,从尾到头的遍历
System.out.println("====从尾到头的遍历====");
while (true) {
if(last == null) {
break;
}
//输出last 信息
System.out.println(last);
last = last.pre;
}
}
}
//定义一个Node 类,Node 对象 表示双向链表的一个结点
class Node {
public Object item; //真正存放数据
public Node next; //指向后一个结点
public Node pre; //指向前一个结点
public Node(Object name) {
this.item = name;
}
public String toString() {
return "Node name=" + item;
}
}
③ LinkedList 的增删改查和循环遍历案例
@SuppressWarnings({"all"})
public class LinkedListCRUD {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println("linkedList=" + linkedList);
//演示一个删除结点的
linkedList.remove(); // 这里默认删除的是第一个结点
//linkedList.remove(2);
System.out.println("linkedList=" + linkedList);
//修改某个结点对象
linkedList.set(1, 999);
System.out.println("linkedList=" + linkedList);
//得到某个结点对象
//get(1) 是得到双向链表的第二个对象
Object o = linkedList.get(1);
System.out.println(o);//999
//因为LinkedList 是 实现了List接口, 遍历方式
System.out.println("===LinkeList遍历迭代器====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList遍历增强for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList遍历普通for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
//源码阅读.
/* 1. LinkedList linkedList = new LinkedList();
public LinkedList() {}
2. 这时 linkeList 的属性 first = null last = null
3. 执行 添加
public boolean add(E e) {
linkLast(e);
return true;
}
4.将新的结点,加入到双向链表的最后
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
*/
/*
读源码 linkedList.remove(); // 这里默认删除的是第一个结点
1. 执行 removeFirst
public E remove() {
return removeFirst();
}
2. 执行
public E removeFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
3. 执行 unlinkFirst, 将 f 指向的双向链表的第一个结点拿掉
private E unlinkFirst(Node f) {
// assert f == first && f != null;
final E element = f.item;
final Node next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
*/
}
} (5)ArrayList 和 LinkedList 比较

如何选择 ArrayList和ListedList:
① 如果我们改查的操作多,选择ArrayList;
② 如果我们增删的操作多,选择ListedList;
③ 一般来说,在程序中,80-90%都是查询,大部分情况下会选择ArrayList;
④ 在项目中,会根据业务灵活选择,可能一个模块用ArrayList,另一个用ListedList。
8 Set 接口和常用方法
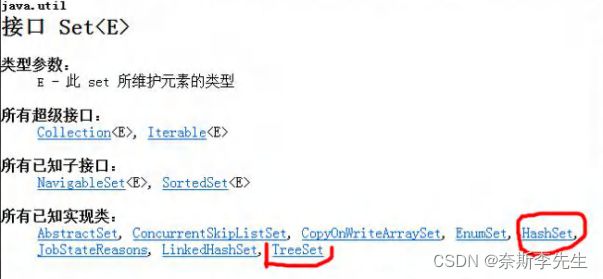
(1)Set 接口基本介绍
① 无序(添加和去除的顺序不一致),没有索引;
② 不允许重复元素,所以最多包含一个null;
③ JDK API中Set接口的实现类有:
(2)Set 接口的常用方法
和 List 接口一样, Set 接口也是 Collection 的子接口,因此,常用方法和 Collection 接口一样。
(3)Set 接口的遍历方式
同Collection的遍历方式一样,因为Set接口是Collection接口的子接口。
① 可以使用迭代器;
② 增强for;
③ 不能使用索引的方式来获取。
(4)Set接口的常用方法举例
@SuppressWarnings({"all"})
public class SetMethod {
public static void main(String[] args) {
//解读
//1. 以Set 接口的实现类 HashSet 来讲解Set 接口的方法
//2. set 接口的实现类的对象(Set接口对象), 不能存放重复的元素, 可以添加一个null
//3. set 接口对象存放数据是无序(即添加的顺序和取出的顺序不一致)
//4. 注意:取出的顺序的顺序虽然不是添加的顺序,但是他的固定.
Set set = new HashSet();
set.add("john");
set.add("lucy");
set.add("john");//重复
set.add("jack");
set.add("hsp");
set.add("mary");
set.add(null);//
set.add(null);//再次添加null
for(int i = 0; i <10;i ++) {
System.out.println("set=" + set);
}
//遍历
//方式1: 使用迭代器
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
set.remove(null);
//方式2: 增强for
System.out.println("=====增强for====");
for (Object o : set) {
System.out.println("o=" + o);
}
//set 接口对象,不能通过索引来获取
}
}9 Set 接口实现类-HashSet
(1)HashSet的全面说明
① HashSet实现了Set接口;
② HashSet实际上是HashMap;

③ 可以存放null值,但是只能有一个null;
④ HashSet不保证元素是有序的,取决于hash后,再确定索引的结果;(即,不保证存放元素的顺序和取出顺序一致)
⑤ 不能有重复元素/对象。
(2)HashSet案例说明
@SuppressWarnings({"all"})
public class HashSet01 {
public static void main(String[] args) {
HashSet set = new HashSet();
//说明
//1. 在执行add方法后,会返回一个boolean值
//2. 如果添加成功,返回 true, 否则返回false
//3. 可以通过 remove 指定删除哪个对象
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
set.remove("john");
System.out.println("set=" + set);//3个
//
set = new HashSet();
System.out.println("set=" + set);//0
//4 Hashset 不能添加相同的元素/数据?
set.add("lucy");//添加成功
set.add("lucy");//加入不了
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok
System.out.println("set=" + set);
//在加深一下. 非常经典的面试题.
//看源码,做分析, 先给小伙伴留一个坑,以后讲完源码,你就了然
//去看他的源码,即 add 到底发生了什么?=> 底层机制.
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//加入不了.
System.out.println("set=" + set);
}
}
class Dog { //定义了Dog类
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}

@SuppressWarnings({"all"})
public class HashSetStructure {
public static void main(String[] args) {
//模拟一个HashSet的底层 (HashMap 的底层结构)
//1. 创建一个数组,数组的类型是 Node[]
//2. 有些人,直接把 Node[] 数组称为 表
Node[] table = new Node[16];
//3. 创建结点
Node john = new Node("john", null);
table[2] = john;
Node jack = new Node("jack", null);
john.next = jack;// 将jack 结点挂载到john
Node rose = new Node("Rose", null);
jack.next = rose;// 将rose 结点挂载到jack
Node lucy = new Node("lucy", null);
table[3] = lucy; // 把lucy 放到 table表的索引为3的位置.
System.out.println("table=" + table);
}
}
class Node { //结点, 存储数据, 可以指向下一个结点,从而形成链表
Object item; //存放数据
Node next; // 指向下一个结点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}(3)HashSet 底层机制说明
HashSet底层是HashMap,HashMap底层是(数组+链表+红黑树)。
分析HashSet的添加元素底层是如何实现(hash() + equals())
① HashSet 底层是 HashMap;
② 添加一个元素时,会得到hash值,会转成->索引值
③ 找到存储数据表table,看这个索引位置是否已经存放了元素;
④ 如果没有,直接加入;
⑤ 如果有,调用equals方法比较,如果相同,就放弃添加;如果不相同,则看链表的元素是否相同,如果相同,则放弃添加,否则添加到最后;
⑥ 在Java8中,如果一条链表的元素个数 >= TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
@SuppressWarnings({"all"})
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//到此位置,第1次add分析完毕.
hashSet.add("php");//到此位置,第2次add分析完毕
hashSet.add("java");
System.out.println("set=" + hashSet);
/*
对HashSet 的源码解读
1. 执行 HashSet()
public HashSet() {
map = new HashMap<>();
}
2. 执行 add()
public boolean add(E e) {//e = "java"
return map.put(e, PRESENT)==null;//(static) PRESENT = new Object();
}
3.执行 put() , 该方法会执行 hash(key) 得到key对应的hash值 算法h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//key = "java" value = PRESENT 共享
return putVal(hash(key), key, value, false, true);
}
4.执行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i; //定义了辅助变量
//table 就是 HashMap 的一个数组,类型是 Node[]
//if 语句表示如果当前table 是null, 或者 大小=0
//就是第一次扩容,到16个空间.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)根据key,得到hash 去计算该key应该存放到table表的哪个索引位置
//并把这个位置的对象,赋给 p
//(2)判断p 是否为null
//(2.1) 如果p 为null, 表示还没有存放元素, 就创建一个Node (key="java",value=PRESENT)
//(2.2) 就放在该位置 tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//一个开发技巧提示: 在需要局部变量(辅助变量)时候,在创建
Node e; K k; //
//如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
//并且满足 下面两个条件之一:
//(1) 准备加入的key 和 p 指向的Node 结点的 key 是同一个对象
//(2) p 指向的Node 结点的 key 的equals() 和准备加入的key比较后相同
//就不能加入
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//再判断 p 是不是一颗红黑树,
//如果是一颗红黑树,就调用 putTreeVal , 来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {//如果table对应索引位置,已经是一个链表, 就使用for循环比较
//(1) 依次和该链表的每一个元素比较后,都不相同, 则加入到该链表的最后
// 注意在把元素添加到链表后,立即判断 该链表是否已经达到8个结点
// , 就调用 treeifyBin() 对当前这个链表进行树化(转成红黑树)
// 注意,在转成红黑树时,要进行判断, 判断条件
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64))
// resize();
// 如果上面条件成立,先table扩容.
// 只有上面条件不成立时,才进行转成红黑树
//(2) 依次和该链表的每一个元素比较过程中,如果有相同情况,就直接break
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD(8) - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//size 就是我们每加入一个结点Node(k,v,h,next), size++
if (++size > threshold)
resize();//扩容
afterNodeInsertion(evict);
return null;
}
*/
}
} 分析HashSet的扩容和转为红黑树机制。
① HashSet底层是HashMap,第一次添加时,table数组扩容到16,临界值(threshold)是16*加载因子(loadFactor)是0.75 = 12
② 如果table数组使用到了临界值12,就会扩容到16*2 = 32,新的临界值就是32*0.75 = 24,以此类推;
③ 在Java8中,如果一条链表的元素个数 >= TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制。
@SuppressWarnings({"all"})
public class HashSetIncrement {
public static void main(String[] args) {
/*
HashSet底层是HashMap, 第一次添加时,table 数组扩容到 16,
临界值(threshold)是 16*加载因子(loadFactor)是0.75 = 12
如果table 数组使用到了临界值 12,就会扩容到 16 * 2 = 32,
新的临界值就是 32*0.75 = 24, 依次类推
*/
HashSet hashSet = new HashSet();
// for(int i = 1; i <= 100; i++) {
// hashSet.add(i);//1,2,3,4,5...100
// }
/*
在Java8中, 如果一条链表的元素个数到达 TREEIFY_THRESHOLD(默认是 8 ),
并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),
否则仍然采用数组扩容机制
*/
// for(int i = 1; i <= 12; i++) {
// hashSet.add(new A(i));//
// }
/*
当我们向hashset增加一个元素,-> Node -> 加入table , 就算是增加了一个size++
*/
for(int i = 1; i <= 7; i++) {//在table的某一条链表上添加了 7个A对象
hashSet.add(new A(i));//
}
for(int i = 1; i <= 7; i++) {//在table的另外一条链表上添加了 7个B对象
hashSet.add(new B(i));//
}
}
}
class B {
private int n;
public B(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 200;
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 100;
}
}(4)HashSet 课堂练习

@SuppressWarnings({"all"})
public class HashSetExercise {
public static void main(String[] args) {
/**
定义一个Employee类,该类包含:private成员属性name,age 要求:
创建3个Employee 对象放入 HashSet中
当 name和age的值相同时,认为是相同员工, 不能添加到HashSet集合中
*/
HashSet hashSet = new HashSet();
hashSet.add(new Employee("milan", 18));//ok
hashSet.add(new Employee("smith", 28));//ok
hashSet.add(new Employee("milan", 18));//加入不成功.
//回答,加入了几个? 3个
System.out.println("hashSet=" + hashSet);
}
}
//创建Employee
class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public void setAge(int age) {
this.age = age;
}
//如果name 和 age 值相同,则返回相同的hash值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age &&
Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}

@SuppressWarnings({"all"})
public class HashSetPractice01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee01("小李",30000,new MyDate(1999,6,14)));
hashSet.add(new Employee01("小李",30000,new MyDate(1999,6,14)));
for (Object o :hashSet) {
System.out.println(o);
}
}
}
@SuppressWarnings({"all"})
class Employee01{
private String name;
private double sal;
private MyDate birthday;
public Employee01(String name, double sal, MyDate birthday) {
this.name = name;
this.sal = sal;
this.birthday = birthday;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "Employee01{" +
"name='" + name + '\'' +
", sal=" + sal +
", birthday=" + birthday +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee01 that = (Employee01) o;
return Objects.equals(name, that.name) &&
Objects.equals(birthday, that.birthday);
}
@Override
public int hashCode() {
return Objects.hash(name, birthday);
}
}
@SuppressWarnings({"all"})
class MyDate{
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public String toString() {
return "MyDate{" +
"year=" + year +
", month=" + month +
", day=" + day +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDate myDate = (MyDate) o;
return year == myDate.year &&
month == myDate.month &&
day == myDate.day;
}
@Override
public int hashCode() {
return Objects.hash(year, month, day);
}
}10 Set 接口实现类-LinkedHashSet
(1)LinkedHashSet 的全面说明
① LinkedHashSet 是 HashSet 的子类;
② LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个数组+双向链表;
③ LinkedHashSet 根据元素 hashCode来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的;
④ LinkedHashSet 不允许添加重复元素。

@SuppressWarnings({"all"})
public class LinkedHashSetSource {
public static void main(String[] args) {
//分析一下LinkedHashSet的底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘", 1001));
set.add(123);
set.add("HSP");
System.out.println("set=" + set);
//解读
//1. LinkedHashSet 加入顺序和取出元素/数据的顺序一致
//2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
//3. LinkedHashSet 底层结构 (数组table+双向链表)
//4. 添加第一次时,直接将 数组table 扩容到 16 ,存放的结点类型是 LinkedHashMap$Entry
//5. 数组是 HashMap$Node[] 存放的元素/数据是 LinkedHashMap$Entry类型
/*
//继承关系是在内部类完成.
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
*/
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
} (2)LinkedHashSet练习题

@SuppressWarnings({"all"})
public class LinkedHashSetExercise {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(new Car("奥拓", 1000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//OK
linkedHashSet.add(new Car("法拉利", 10000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
linkedHashSet.add(new Car("保时捷", 70000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
System.out.println("linkedHashSet=" + linkedHashSet);
}
}
/**
* Car 类(属性:name,price), 如果 name 和 price 一样,
* 则认为是相同元素,就不能添加。 5min
*/
class Car {
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "\nCar{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
//重写equals 方法 和 hashCode
//当 name 和 price 相同时, 就返回相同的 hashCode 值, equals返回t
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 &&
Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}四 Map
1 Map 接口和常用方法
(1)Map 接口实现类的特点 [很实用]
这里讲的是JDK8的Map接口特点:
① Map与Collection并列存在(即平行关系)。Map用于保存具有映射关系的数据:Key-Value;
② Map 中的 key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node对象中;
③ Map 中的 key 不允许重复,原因和HashSet 一样;
④ Map 中的 value 可以重复;
⑤ Map 的key 可以为 null, value 也可以为null ,注意 key 为null, 只能有一个,value 为null ,可以多个;
⑥ 常用String类作为Map的 key;
⑦ key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value。
@SuppressWarnings({"all"})
public class Map_ {
public static void main(String[] args) {
//解读Map 接口实现类的特点, 使用实现类HashMap
//1. Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)
//2. Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
//3. Map 中的 key 不允许重复,原因和HashSet 一样,前面分析过源码.
//4. Map 中的 value 可以重复
//5. Map 的key 可以为 null, value 也可以为null ,注意 key 为null,
// 只能有一个,value 为null ,可以多个
//6. 常用String类作为Map的 key
//7. key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put("no1", "张三丰");//当有相同的k , 就等价于替换.
map.put("no3", "张三丰");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等价替换
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "赵敏");//k-v
map.put(new Object(), "金毛狮王");//k-v
// 通过get 方法,传入 key ,会返回对应的value
System.out.println(map.get("no2"));//张无忌
System.out.println("map=" + map);
}
}⑧ Map存放数据的key-value示意图,一对 k-v 是放在一个Node中的,又因为Node 实现了 Entry 接口,有些书上也说一对k-v就是一个Entry。

@SuppressWarnings({"all"})
public class MapSource_ {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put(new Car(), new Person());//k-v
//解读
//1. k-v 最后是 HashMap$Node node = newNode(hash, key, value, null)
//2. k-v 为了方便程序员的遍历,还会 创建 EntrySet 集合 ,该集合存放的元素的类型 Entry, 而一个Entry
// 对象就有k,v EntrySet> 即: transient Set> entrySet;
//3. entrySet 中, 定义的类型是 Map.Entry ,但是实际上存放的还是 HashMap$Node
// 这时因为 static class Node implements Map.Entry,接口多态
//4. 当把 HashMap$Node 对象 存放到 entrySet 就方便我们的遍历, 因为 Map.Entry 提供了重要方法
// K getKey(); V getValue();
Set set = map.entrySet();
System.out.println(set.getClass());// HashMap$EntrySet
for (Object obj : set) {
//System.out.println(obj.getClass()); //HashMap$Node
//为了从 HashMap$Node 取出k-v
//1. 先做一个向下转型
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "-" + entry.getValue() );
}
Set set1 = map.keySet();
System.out.println(set1.getClass());
Collection values = map.values();
System.out.println(values.getClass());
}
}
class Car {
}
class Person{
} (2)Map接口常用方法
@SuppressWarnings({"all"})
public class MapMethod {
public static void main(String[] args) {
//演示map接口常用方法
Map map = new HashMap();
map.put("邓超", new Book("", 100));//OK
map.put("邓超", "孙俪");//替换-> 一会分析源码
map.put("王宝强", "马蓉");//OK
map.put("宋喆", "马蓉");//OK
map.put("刘令博", null);//OK
map.put(null, "刘亦菲");//OK
map.put("鹿晗", "关晓彤");//OK
map.put("hsp", "hsp的老婆");
System.out.println("map=" + map);
// remove:根据键删除映射关系
map.remove(null);
System.out.println("map=" + map);
// get:根据键获取值
Object val = map.get("鹿晗");
System.out.println("val=" + val);
// size:获取元素个数
System.out.println("k-v=" + map.size());
// isEmpty:判断个数是否为0
System.out.println(map.isEmpty());//F
// clear:清除k-v
//map.clear();
System.out.println("map=" + map);
// containsKey:查找键是否存在
System.out.println("结果=" + map.containsKey("hsp"));//T
}
}
class Book {
private String name;
private int num;
public Book(String name, int num) {
this.name = name;
this.num = num;
}
}
(3)Map接口遍历方法
① KeySet:获取所有的键;
② entrySet:获取所有的关系K-V;
③ values:获取所有的值。
@SuppressWarnings({"all"})
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//第一组: 先取出 所有的Key , 通过Key 取出对应的Value
Set keyset = map.keySet();
//(1) 增强for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二组: 把所有的values取出
Collection values = map.values();
//这里可以使用所有的Collections使用的遍历方法
//(1) 增强for
System.out.println("---取出所有的value 增强for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//第三组: 通过EntrySet 来获取 k-v
Set entrySet = map.entrySet();// EntrySet>
//(1) 增强for
System.out.println("----使用EntrySet 的 for增强(第3种)----");
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的 迭代器(第4种)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
}
}
(4)Map接口课堂练习

@SuppressWarnings({"all"})
public class MapForPractice {
public static void main(String[] args) {
Map map = new HashMap();
map.put(1,new Employee(1,"小时",3000));
// map.put(1,new Employee(1,"小时",3000));
map.put(2,new Employee(2,"小留",20000));
map.put(3,new Employee(3,"小杨",19000));
map.put(4,new Employee(4,"小照",18400));
System.out.println(map);
// 使用KeySet
Set set = map.keySet();
System.out.println("======使用增强for======");
for (Object key : set) {
if (((Employee)map.get(key)).getSal() > 18000){
System.out.println(key + "-" + map.get(key));
}
}
System.out.println("=====使用迭代器=====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
if (((Employee)map.get(key)).getSal() > 18000){
System.out.println(key + "-" + map.get(key));
}
}
//使用entrySet
Set entrySet = map.entrySet();
System.out.println("=====使用增强for=====");
for (Object obj :entrySet) {
Map.Entry entry = (Map.Entry) obj;
if (((Employee)entry.getValue()).getSal() > 18000){
System.out.println(entry.getKey() + "-" + entry.getValue());
}
}
System.out.println("=====使用迭代器=====");
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();
Map.Entry entry = (Map.Entry) next;
if (((Employee)entry.getValue()).getSal() > 18000){
System.out.println(entry.getKey() + "-" + entry.getValue());
}
}
}
}
@SuppressWarnings({"all"})
class Employee{
private int id;
private String name;
private double sal;
public Employee(int id, String name, double sal) {
this.id = id;
this.name = name;
this.sal = sal;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", name='" + name + '\'' +
", sal=" + sal +
'}';
}
}2 Map 接口实现类-HashMap
(1)HashMap小结

(2)HashMap 底层机制及源码剖析

① HashMap底层维护了Node类型的数组table,默认为null;
② 当创建对象时,将加载因子(loadfactor)初始化为0.75;
③ 当添加key-val时,通过key的哈希值得到在table的索引,然后判断该索引处是否有元素,如果没有元素则直接添加。如果该索引处有元素,继续判断该元素的key和准备加入的key是否相等,如果相等,则直接替换val,如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时候发现容量不够,则需要扩容;
④ 第一次添加,则需要扩容table容量为16,临界值(threshold)为12(16*0.75);
⑤ 以后再扩容,则需要扩容table容量为原来的的2倍(32),临界值为原来的2倍,即24,以此类推;
⑥ 在Java 8中,如果一条链表的元素个数超过TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
@SuppressWarnings({"all"})
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//替换value
System.out.println("map=" + map);//
/*解读HashMap的源码+图解
1. 执行构造器 new HashMap()
初始化加载因子 loadfactor = 0.75
HashMap$Node[] table = null
2. 执行put 调用 hash方法,计算 key的 hash值 (h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//K = "java" value = 10
return putVal(hash(key), key, value, false, true);
}
3. 执行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;//辅助变量
//如果底层的table 数组为null, 或者 length =0 , 就扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值对应的table的索引位置的Node, 如果为null, 就直接把加入的k-v
//, 创建成一个 Node ,加入该位置即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;//辅助变量
// 如果table的索引位置的key的hash相同和新的key的hash值相同,
// 并 满足(table现有的结点的key和准备添加的key是同一个对象 || equals返回真)
// 就认为不能加入新的k-v
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果当前的table的已有的Node 是红黑树,就按照红黑树的方式处理
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//如果找到的结点,后面是链表,就循环比较
for (int binCount = 0; ; ++binCount) {//死循环
if ((e = p.next) == null) {//如果整个链表,没有和他相同,就加到该链表的最后
p.next = newNode(hash, key, value, null);
//加入后,判断当前链表的个数,是否已经到8个,到8个,后
//就调用 treeifyBin 方法进行红黑树的转换
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && //如果在循环比较过程中,发现有相同,就break,就只是替换value
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替换,key对应value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//每增加一个Node ,就size++
if (++size > threshold[12-24-48])//如size > 临界值,就扩容
resize();
afterNodeInsertion(evict);
return null;
}
5. 关于树化(转成红黑树)
//如果table 为null ,或者大小还没有到 64,暂时不树化,而是进行扩容.
//否则才会真正的树化 -> 剪枝
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
}
*/
}
} 模拟HashMap触发扩容、树化情况。
@SuppressWarnings({"all"})
public class HashMapSource2 {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
for(int i = 1; i <= 12; i++) {
hashMap.put(i, "hello");
}
hashMap.put("aaa", "bbb");
System.out.println("hashMap=" + hashMap);//12个 k-v
//布置一个任务,自己设计代码去验证,table 的扩容
//0 -> 16(12) -> 32(24) -> 64(64*0.75=48)-> 128 (96) ->
//自己设计程序,验证-》 增强自己阅读源码能力. 看别人代码.
}
}
class A {
private int num;
public A(int num) {
this.num = num;
}
//所有的A对象的hashCode都是100
// @Override
// public int hashCode() {
// return 100;
// }
@Override
public String toString() {
return "\nA{" +
"num=" + num +
'}';
}
}
3 Map 接口实现类-Hashtable
(1)HashTable 的基本介绍
① 存放的元素是键值对:即K-V;
② hashtable的键和值都不能为null,否则会抛出NullPointerException;
③ hashTable使用方法基本上和hashMap一样;
④ hashTable是线程安全的(synnchronized),hashMap是线程不安全的;
⑤ hashTable的应用实例(包括扩容)
@SuppressWarnings({"all"})
public class HashTableExercise {
public static void main(String[] args) {
Hashtable table = new Hashtable();//ok
table.put("john", 100); //ok
//table.put(null, 100); //异常 NullPointerException
//table.put("john", null);//异常 NullPointerException
table.put("lucy", 100);//ok
table.put("lic", 100);//ok
table.put("lic", 88);//替换
table.put("hello1", 1);
table.put("hello2", 1);
table.put("hello3", 1);
table.put("hello4", 1);
table.put("hello5", 1);
table.put("hello6", 1);
System.out.println(table);
//简单说明一下Hashtable的底层
//1. 底层有数组 Hashtable$Entry[] 初始化大小为 11
//2. 临界值 threshold 8 = 11 * 0.75
//3. 扩容: 按照自己的扩容机制来进行即可.
//4. 执行 方法 addEntry(hash, key, value, index); 添加K-V 封装到Entry
//5. 当 if (count >= threshold) 满足时,就进行扩容
//5. 按照 int newCapacity = (oldCapacity << 1) + 1; 的大小扩容.
}
}
(2)Hashtable 和 HashMap 对比

4 Map 接口实现类-Properties
(1)基本介绍
① Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据;
② 它的使用特点和Hashtable类似;
③ Properties 还可以用于 从xxx.properties 文件中,加载数据到Properties类对象,并进行读取和修改;
④ 工作中,xxx.properties 文件通常为配置文件,在IO流举例。
(2)基本使用(增删改查)
@SuppressWarnings({"all"})
public class Properties_ {
public static void main(String[] args) {
//解读
//1. Properties 继承 Hashtable
//2. 可以通过 k-v 存放数据,当然key 和 value 不能为 null
//增加
Properties properties = new Properties();
//properties.put(null, "abc");//抛出 空指针异常
//properties.put("abc", null); //抛出 空指针异常
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//如果有相同的key , value被替换
System.out.println("properties=" + properties);
//查找,通过k 获取对应值
System.out.println(properties.get("lic"));//88
System.out.println(properties.getProperty("lic"));//88
//删除
properties.remove("lic");
System.out.println("properties=" + properties);
//修改
properties.put("john", "约翰");
System.out.println("properties=" + properties);
}
}
5 TreeSet源码分析
@SuppressWarnings({"all"})
public class TreeSet_ {
public static void main(String[] args) {
//解读
//1. 当我们使用无参构造器,创建TreeSet时,仍然是无序的
//2. 老师希望添加的元素,按照字符串大小来排序
//3. 使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定排序规则
//4. 简单看看源码
//老韩解读
/*
1. 构造器把传入的比较器对象,赋给了 TreeSet的底层的 TreeMap的属性this.comparator
public TreeMap(Comparator comparator) {
this.comparator = comparator;
}
2. 在 调用 treeSet.add("tom"), 在底层会执行到
if (cpr != null) {//cpr 就是我们的匿名内部类(对象)
do {
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个Key就没有加入
return t.setValue(value);
} while (t != null);
}
*/
// TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面 调用String的 compareTo方法进行字符串大小比较,若字符串内容完全相同,则不再添加
//如果老韩要求加入的元素,按照长度大小排序,若长度相同则不再添加
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//添加数据.
treeSet.add("jack");
treeSet.add("tom");//3
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");//3
System.out.println("treeSet=" + treeSet);
}
}6 TreeMap源码分析
@SuppressWarnings({"all"})
public class TreeMap_ {
public static void main(String[] args) {
//使用默认的构造器,创建TreeMap, 是无序的(也没有排序)
/*
要求:按照传入的 k(String) 的大小进行排序
*/
// TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照传入的 k(String) 的大小进行排序
//按照K(String) 的长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o2).length() - ((String) o1).length();
}
});
treeMap.put("jack", "杰克");
treeMap.put("tom", "汤姆");
treeMap.put("kristina", "克瑞斯提诺");
treeMap.put("smith", "斯密斯");
treeMap.put("hsp", "韩顺平");//加入不了
System.out.println("treemap=" + treeMap);
/*
老韩解读源码:
1. 构造器. 把传入的实现了 Comparator接口的匿名内部类(对象),传给给TreeMap的comparator
public TreeMap(Comparator comparator) {
this.comparator = comparator;
}
2. 调用put方法
2.1 第一次添加, 把k-v 封装到 Entry对象,放入root
Entry t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 以后添加
Comparator cpr = comparator;
if (cpr != null) {
do { //遍历所有的key , 给当前key找到适当位置
parent = t;
cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类的compare
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果遍历过程中,发现准备添加Key 和当前已有的Key 相等,就不添加
return t.setValue(value);
} while (t != null);
}
*/
}
}
7 总结-开发中如何选择集合实现类

五 Collections
1 介绍
![]()
2 排序、查找、替换(static操作)


应用案例
@SuppressWarnings({"all"})
public class Collections_ {
public static void main(String[] args) {
//创建ArrayList 集合,用于测试.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
// reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
System.out.println("list=" + list);
// shuffle(List):对 List 集合元素进行随机排序
// for (int i = 0; i < 5; i++) {
// Collections.shuffle(list);
// System.out.println("list=" + list);
// }
// sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后");
System.out.println("list=" + list);
// sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//我们希望按照 字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码.
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("字符串长度大小排序=" + list);
// swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
//比如
Collections.swap(list, 0, 1);
System.out.println("交换后的情况");
System.out.println("list=" + list);
//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
//Object min(Collection)
//Object min(Collection,Comparator)
//上面的两个方法,参考max即可
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom出现的次数=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):将src中的内容复制到dest中
ArrayList dest = new ArrayList();
//为了完成一个完整拷贝,我们需要先给dest 赋值,大小和list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
//如果list中,有tom 就替换成 汤姆
Collections.replaceAll(list, "tom", "汤姆");
System.out.println("list替换后=" + list);
}
}
六 课后习题
1 HashSet和TreeSet去重机制的叙述

即如果天添加的对象是字符串,则以字符串实现的Compareable接口的compareTo去重
2 代码分析题
 会抛出ClassCastException异常,因为Person类没有实现Compareable接口。
会抛出ClassCastException异常,因为Person类没有实现Compareable接口。
3 程序阅读题
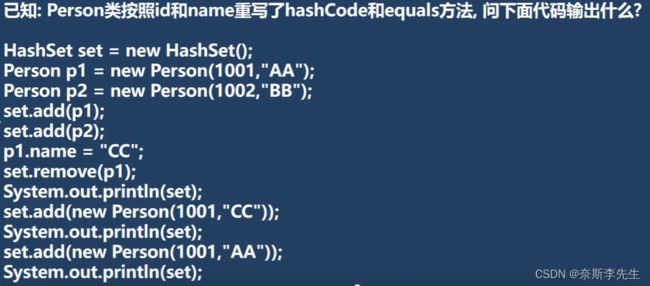
@SuppressWarnings({"all"})
public class Homework06 {
public static void main(String[] args) {
HashSet set = new HashSet();//ok
Person p1 = new Person(1001,"AA");//ok
Person p2 = new Person(1002,"BB");//ok
set.add(p1);//ok
set.add(p2);//ok
p1.name = "CC";
set.remove(p1);
System.out.println(set);//2
set.add(new Person(1001,"CC"));
System.out.println(set);//3
set.add(new Person(1001,"AA"));
System.out.println(set);//4
}
}
class Person {
public String name;
public int id;
public Person(int id, String name) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
① 在set.remove(p1)时候,因为p1的name已经改变了,remove时会根据p1此时的name和id来计算hash值,索引,计算出的位置与添加进去时候的位置不同,没找到,所以删除失败;
② set.add(new Person(1001,"CC"))时候,虽然与此时的p1的name和id一样,但是p1的hash值和索引已经在改变p1name前就确定了,所有在添加这个新对象时候检测的hash值和索引值与p1的不一样,可以加入;
③ set.add(new Person(1001,"AA"))时候,虽然此时新对象的hash值和索引值与p1的一样,但是
它们的name不一样,就equals不同,所以它加在p1的链表后面,可以加入。
知识点
1 快捷键
(1)快速遍历迭代器Iterator循环方式1
输入itit回车即可。
(2)快速遍历迭代器for循环方式2
输入大写I即可。
(3)显示所以快捷键的快捷键
按ctrl + j 即可。
2 Debugger细节显示问题

取消勾选即可。