基于Matlab的K-近邻算法(KNN)详解(附算法介绍及代码详解)
一、内容提要
今天笔者同样以测井岩性分类为实例,为大家分享一种被称为“最简单的机器学习算法之一”的K-近邻算法(K-Nearest Neighbor, KNN)。
K-近邻算法(KNN,K-Nearest Neighbor)可以用于分类和回归[1]。K-近邻算法,意思是每一个样本都可以用它最接近的K个邻居来代表,以大多数邻居的特征代表该样本的特征,据此分类[2]。它的优势非常突出:思路简单、易于理解、易于实现,无需参数估计[3]。
本期笔者将KNN算法应用在基于测井数据的岩性分类上。
下面分为算法简介、实例计算与代码解读三个部分进行讲解。(代码获取方式详见文末)
二、算法简介
K-近邻算法
K-近邻算法的计算过程是:一个未知分类的样本进入数据集、那么与它最相似(特征空间中最邻近)的K个样本的类别大多数是哪一类,那么它就是哪一类。K-近邻算法的主要流程如下:
1)存在一个训练样本集,训练集中每个样本都已知所属的分类,指定最近邻居数K。
2)输入没有分类的新样本后,将新样本的每个属性与训练集中的样本对应的属性进行比较,然后提取最相近的K个样本的分类;
3)这K个样本出现最多的分类就是新数据的分类。
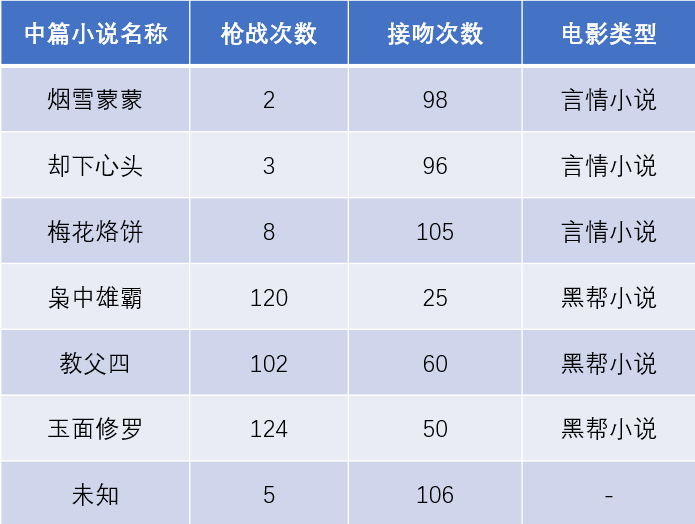
下面我们举一个对《未知》小说进行分类的例子,来解释K-临近算法的主要流程(见下表)。
有六篇中篇小说,根据小说中枪战次数和接吻次数(特征)(虚构数据)归类为言情小说或黑帮小说。由于《未知》的接吻片段次数多、枪战片段次数少,于是将《未知》与言情小说归为一类。通过这个例子我们可以发现,K-近邻算法是不需要训练过程的,而且是没有参数估计的。
在算法的实现中,我们使用matlab自带的“鸢尾花的分类”例子,来展示KNN算法是如何被实现的。如图所示,鸢尾花数据集每个样本有两个特征,可用散点的形式绘制在二维平面上;对应三种分类(setosa,versicolor和virginica)。现在插入三个新样本(使用▽标识),并根据KNN的方法对其进行分类。
 图1:鸢尾花数据集分类(matlab)
图1:鸢尾花数据集分类(matlab)
如算法简介中介绍,只需要计算3个新样本与全部训练集数据的距离,再进行类别统计即可,这样的做法在数据量极大的时候效率很低。这时,如果将所有数据点之间的位置关系建立联系——KD树(K-Dimensional Tree,KDTree),在搜索新样本的最邻近点时从树的根节点一步一步向叶节点搜索,就能以更高的效率搜索到最临近点。
对KDTree生成和查询的详细步骤不多做赘述,这里我们使用github上的matlab kdtree可视化库对KDTree进行可视化,给大家提供直观的认识,不做重点介绍。生成kdtree并可视化的代码如下:
function tree_output = kd_buildtree(X,plot_stuff,parent_number,split_dimension)在二维空间中,KDTree表示为如图2所示的,不断分割二维平面的模式。当有新样本加入集合中,就放入二维平面(多维数据为超平面)的对应区域中,通过搜索能很快搜索到K个近邻点。
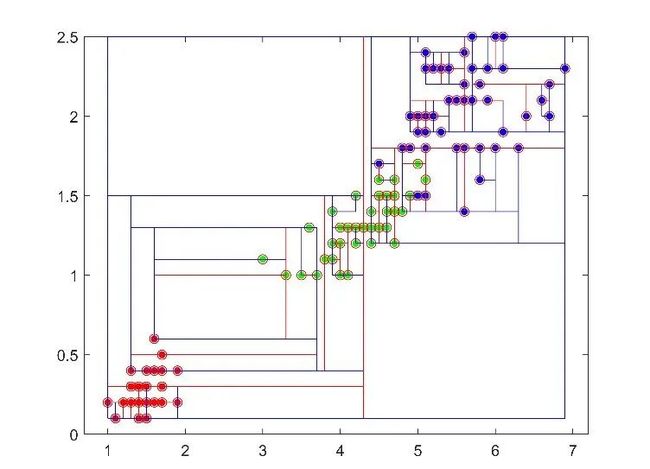 图2:KDTree
图2:KDTree
三、实例计算
实例:基于六条测井曲线,对岩性进行划分。训练集如图3所示。
数据:训练集由3300个深度的测井曲线以及对应的岩性分类组成。则每一个深度看作一个样本,测井曲线的数值作为属性、岩性作为分类结果。367个深度的测井曲线以及对应的岩性分类作为测试集,测试建立的模型性能。
目的:基于六条测井曲线数据构建一个KNN模型,用于岩性类型划分。
 图3:基于测井数据的岩性识别结果示意图
图3:基于测井数据的岩性识别结果示意图
四、代码解读
第一步 数据导入
%% 数据导入
load traindata.mat
load testdata.mat第二步 建立
使用训练数据集构造KDTree
x = traindata(:,1:6);
Mdl = KDTreeSearcher(x);第三步 寻找测试集K个邻居
使用KDTree 结构体MDI,得到n,n为样本数x邻居数的矩阵,每一行对应一个测试样本,这一行的所有元素代表最邻近的训练集样本点的索引
[n,~] = knnsearch(Mdl,testdata(:,1:6),'k',k);第四步 循环提取测试集样本对应邻居
循环提取测试样本的邻居,并统计众数进行投票,得到最终分类结果。使用validate计算最终的准确率分类。其中mode用于计算最近邻点分类向量tempClass中的众数。
for i = 1:size(n,1)
tempClass = traindata(n(i,:),7);
result = mode(tempClass);
resultClass(i,1) = result;
end
validate = sum( testdata(:,7) == resultClass )./ size(testdata,1) * 100;第五步 对K进行优化调参
将以上过程封装为函数myKNNCLass,将k作为参数进行调参,由于需要使用众数作为结果,因此邻居数应该选择为奇数。
for kValue = 1:2:15
validate = myKNNCLass(traindata,testdata,kValue);
disp(['取近邻数K = ' num2str(kValue),'; 此时的准确率为 ' num2str(validate) '%'])
end得到结果 >>
取近邻数K = 1; 此时的准确率为 90.9836%
取近邻数K = 3; 此时的准确率为 87.9781%
取近邻数K = 5; 此时的准确率为 84.153%
取近邻数K = 7; 此时的准确率为 84.9727%
取近邻数K = 9; 此时的准确率为 82.2404%
取近邻数K = 11; 此时的准确率为 80.0546%
取近邻数K = 13; 此时的准确率为 79.235%
取近邻数K = 15; 此时的准确率为 77.8689%
则最后使用取近邻数1为最好。
参考文献
[1] Altman, N. S. An introduction to kernel and nearest-neighbor nonparametric regression. The American Statistician. 1992, 46 (3): 175–185. doi:10.1080/00031305.1992.10475879.
[2] 田翠华著,基于GT4的物联网交通信息服务仿真研究,厦门大学出版社,2017.01,第225页
[3] 宋园,陈永平. 聚类分析中K-邻近算法的研究. 《 CNKI;WanFang 》 , 2013
【注】此文章版权归数字地学新视界账号所有,如需转载务必联系后台管理员。否则将维权到底。

代码获取方式 :
关注公众号并联系数字地学新视界微信后台管理员,可领取完整版带有详尽注释的示例代码!
[如何获取管理员联系方式]:菜单栏中的联系我们——>转载须知,扫码添加即可。
知识创作分享不易,希望与大家共同成长进步~ 【多见多闻】| 基于K-近邻算法(KNN)的岩性分类实战详解K-近邻算法;KDTree;测井数据;岩性识别 https://mp.weixin.qq.com/s/4R9mlSvnarw8kQa21NNhMQ
https://mp.weixin.qq.com/s/4R9mlSvnarw8kQa21NNhMQ